Command Palette
Search for a command to run...
无需数据或优化实现最大脑损伤:通过 Sign-Bit Flips 破坏 Neural Networks
无需数据或优化实现最大脑损伤:通过 Sign-Bit Flips 破坏 Neural Networks
Ido Galil Moshe Kimhi Ran El-Yaniv
摘要
仅需翻转极少数的参数位(parameter bits),深度神经网络(Deep Neural Networks, DNNs)就可能遭受灾难性的破坏。我们提出了 Deep Neural Lesion (DNL),这是一种无需数据(data-free)且无需优化(optimization-free)的方法,用于定位关键参数;此外,我们还提出了一种增强型的单次迭代变体 1P-DNL,通过在随机输入上进行一次前向和反向传播(forward and backward pass),即可精炼参数的选择。研究表明,这种脆弱性跨越了多个领域,包括图像分类、目标检测、实例分割以及推理型大语言模型(reasoning large language models)。在图像分类任务中,仅需翻转 ImageNet 上 ResNet-50 的两个符号位(sign bits),其准确率就会下降 99.8%。在目标检测和实例分割任务中,Backbone 网络中一个或两个符号位的翻转,就会导致 Mask R-CNN 和 YOLOv8-seg 模型在 COCO 数据集上的检测精度(detection)和掩码平均精度(mask AP)发生崩溃。在语言建模任务中,对不同专家(experts)进行两次符号位翻转,会将 Qwen3-30B-A3B-Thinking 的准确率从 78% 降至 0%。此外,我们还证明,通过有选择性地保护极小比例的易损符号位,可以为抵御此类攻击提供一种切实可行的防御手段。
一句话总结
通过引入 Deep Neural Lesion (DNL) 及其单次 pass 变体 1P-DNL,作者提出了一种无需数据且无需优化的方法,通过翻转符号位来破坏神经网络,在图像分类、目标检测和大语言模型中实现了灾难性的失败,同时通过选择性的位保护提供了一种实用的防御手段。
核心贡献
- 本文引入了 Deep Neural Lesion (DNL),这是一种无需数据且无需优化的定位关键参数的方法,以及一种增强的单次 pass 变体 1P-DNL,该变体通过在随机输入上进行一次前向和后向 pass 来优化参数选择。
- 这项工作证明,翻转极少量的符号位就可以灾难性地破坏多种架构,包括 ImageNet 上的 ResNet-50、COCO 上的 Mask R-CNN 和 YOLOv8-seg,以及像 Qwen3-30B-A3B-Thinking 这样的推理型大语言模型。
- 作者提出了一种针对性的防御机制,通过选择性地保护一小部分易受攻击的符号位,从而显著提高模型针对此类位翻转攻击的鲁棒性。
引言
随着深度神经网络 (DNNs) 越来越多地部署在自动驾驶和大语言模型等安全至关重要的系统中,了解它们对硬件和软件漏洞的脆弱性至关重要。虽然现有的权重空间攻击可以破坏模型,但它们通常需要巨大的计算开销、迭代优化或访问大型数据集来计算梯度。
作者引入了 Deep Neural Lesion (DNL),这是一种轻量级、与数据无关且无需优化的方法,通过识别并翻转关键符号位来诱导灾难性的模型失败。通过利用基于幅度的启发式方法和增强的单次 pass 变体 (1P-DNL),作者证明,仅翻转一个或两个符号位就可以将 ResNet-50、YOLOv8 和 Mixture-of-Experts 语言模型的准确率降低到接近于零。这种方法绕过了对训练数据或连续推理的需求,使其在实际部署场景中成为一种具有高度隐蔽性和威力的威胁。
方法
作者利用一种被称为 DNL (Deep Neural Lesion) 的针对性符号位翻转攻击,通过证明翻转少量特定符号位可以灾难性地降低模型性能,从而揭示深度神经网络 (DNNs) 中的关键漏洞。该攻击完全与数据无关,不需要任何关于训练数据、领域特定输入或合成数据的知识。该框架旨在识别并操纵模型权重空间中最关键的参数,重点关注浮点表示的符号位 (MSB),这会引起参数值的立即且通常是剧烈的变化。这种方法的动机源于一种观察:虽然随机的符号位翻转对性能的影响微乎其微,但经过策略性选择的翻转会导致准确率大幅下降。
DNL 攻击的核心涉及两种主要策略:“无 Pass”变体和“1-Pass”变体。无 Pass 攻击在模型的前向计算之外不需要任何额外的计算 pass。它依赖于一种简单的、基于启发式的参数翻转选择。作者首先发现,具有大幅度的参数对符号翻转异常敏感,这借鉴了文献中基于幅度的剪枝方法。这引出了一种基于幅度的策略,即选择绝对值最大的前-k个参数进行翻转。此外,对于卷积神经网络 (CNNs),攻击被限制为每个卷积核最多翻转一个符号位。这一约束至关重要,因为在同一个卷积核内翻转多个位往往会导致扰动的部分抵消,从而降低整体影响。如下图所示,Sobel 滤波器中的单个符号翻转会严重破坏其边缘检测能力,而两个符号翻转可能会部分抵消损伤,使滤波器保留一定的功能。
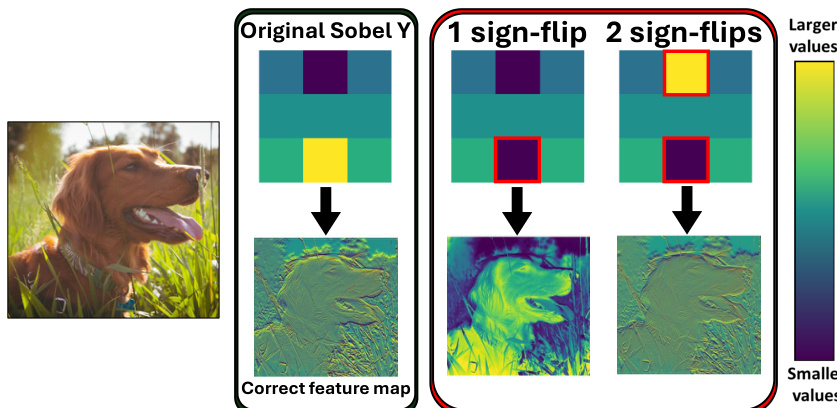
通过针对网络早期层的参数,攻击的有效性得到了进一步提升。作者认为,早期层参数(特别是在 CNNs 中)对于提取边缘和纹理等基础特征至关重要。这些层中的扰动会通过整个网络传播,导致复合误差,从而引起严重的性能下降。这类似于视觉系统早期的病变会导致全盲。下图提供了该概念的视觉演示,展示了翻转 DNN 第一个卷积核中权重的符号位如何导致学习到的特征图发生巨大破坏,使网络无法正确检测边缘。

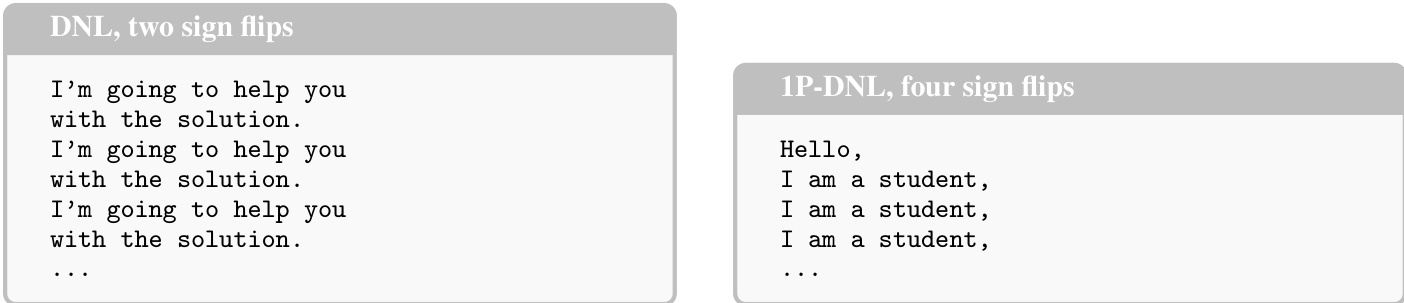
为了在有限的计算预算下优化攻击,作者提出了 1P-DNL (1-Pass DNL) 变体,该变体使用随机输入的单次前向和后向 pass 来为每个参数计算更复杂的重要性评分。这种评分被称为混合重要性评分,它结合了基于幅度的显著性与源自模型梯度和 Hessian 的二阶信息。该评分的公式定义为 S(θi)=α∣θi∣+β∂θi∂Rθi+21Hiiθi2+∑j=iHijθiθj,其中 R 是模型在随机输入上的损失或输出。在实践中,为了计算效率,Hessian 被近似为对角矩阵,且 Hii 被替换为 (∂θi∂R)2。这种方法允许攻击识别出对扰动最敏感的参数,而不仅仅是那些幅度最大的参数。如下图所示的可视化结果表明,这种增强方法比无 Pass 版本强大得多,DNL 和 1P-DNL 都能在极少量的翻转下导致大多数模型崩溃。
实验
研究人员在包括推理语言模型、文本编码器、图像分类和目标检测在内的多个领域评估了 DNL 和 1P-DNL 位翻转攻击的有效性。实验表明,针对性的符号位翻转会导致模型快速崩溃,通常只需几次扰动即可将性能降低到接近于零。这些发现揭示了神经网络表示中一种基本的脆弱性,这种脆弱性不随模型规模或架构而改变,同时也表明选择性地保护高影响参数可以作为一种有效的防御手段。
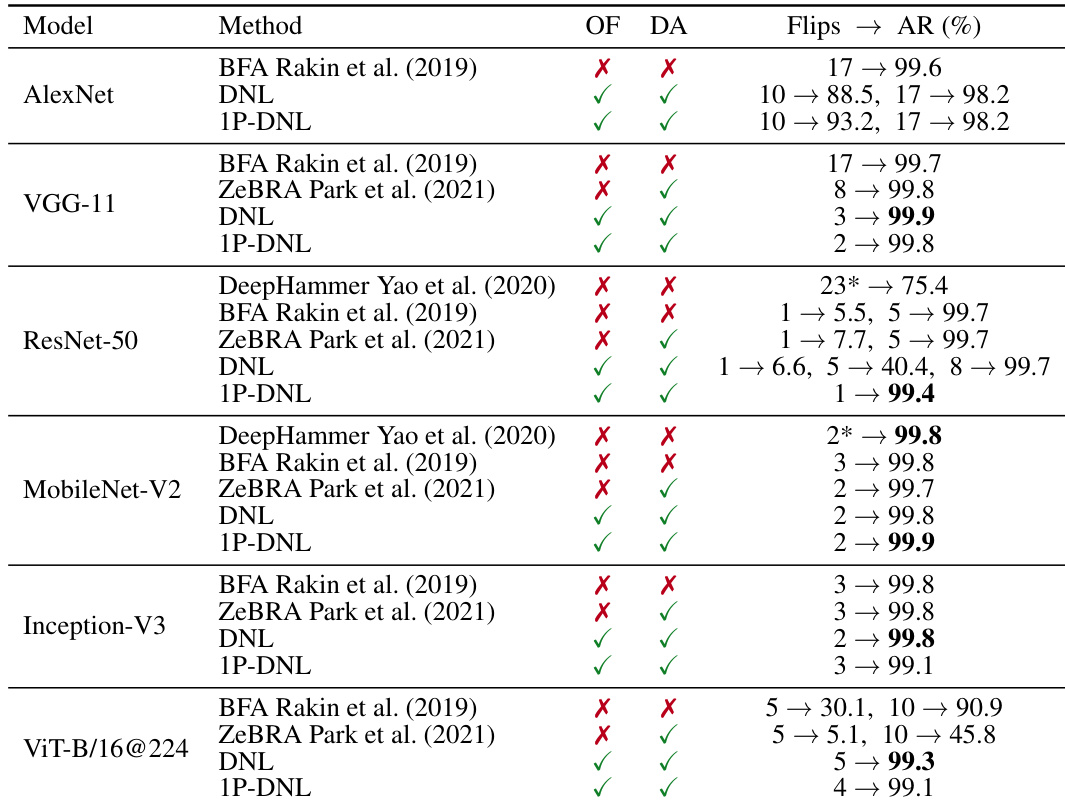
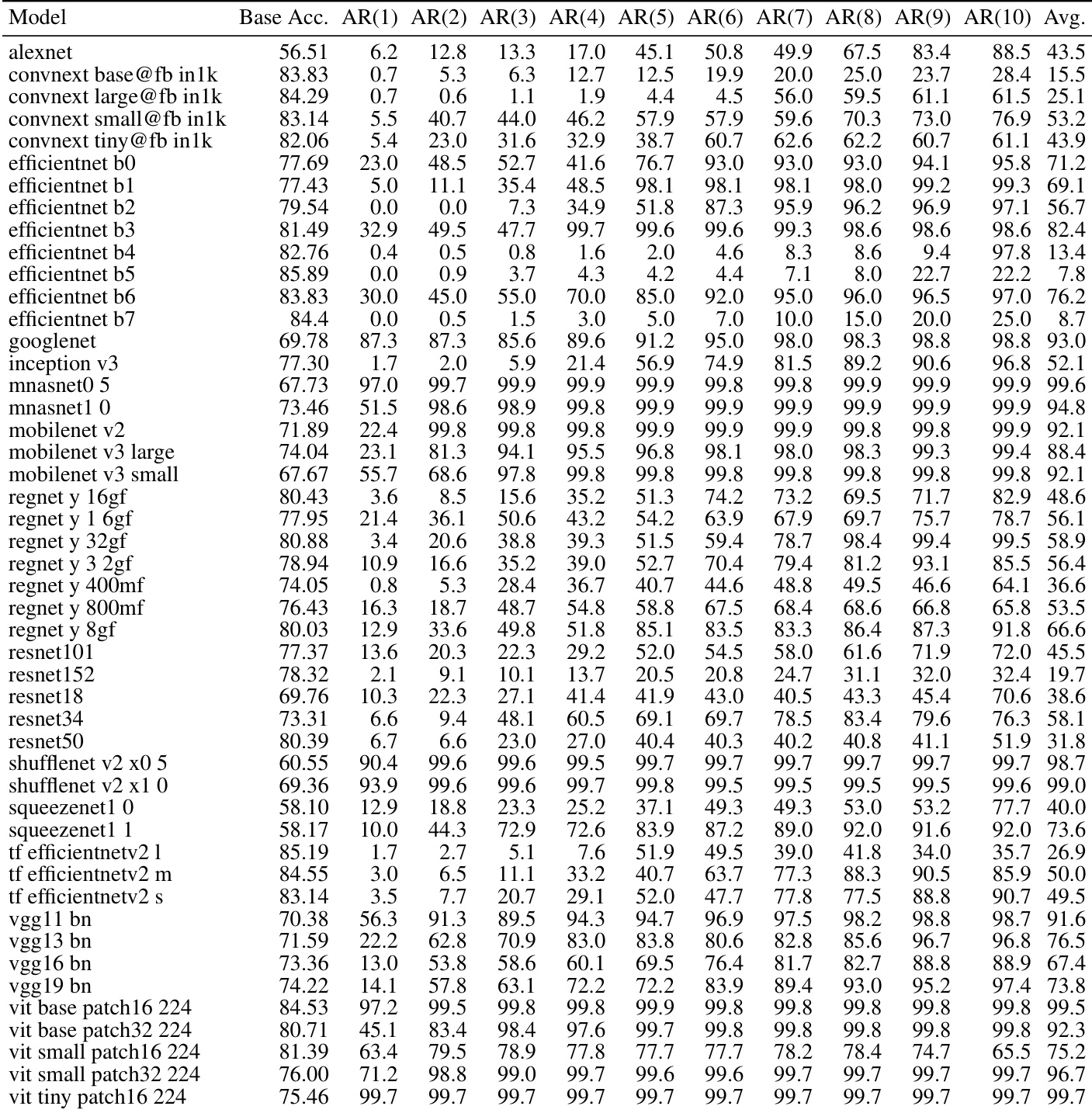
该表比较了多种模型下的不同位翻转攻击方法,显示 DNL 和 1P-DNL 在极少翻转的情况下即可实现极高的准确率降幅。这些方法无需优化且与数据无关,在有效性和效率上优于其他方法。DNL 和 1P-DNL 在各种模型中都能以极少的翻转实现高准确率降幅。这些攻击无需优化且与数据无关,使其比其他方法更高效。1P-DNL 一致优于 DNL,能以更少的翻转实现近乎完全的崩溃。
作者在多个数据集和架构上评估了针对图像分类模型的符号位攻击。结果显示,少量精心选择的位翻转会导致准确率迅速且严重下降,大多数模型在几次翻转后准确率就会崩溃至接近于零。该攻击在不同模型类型和数据集上均有效,表明深度神经网络表示中存在根本性的脆弱性。单个针对性的符号位翻转会导致图像模型的准确率显著下降。大多数模型在仅进行几次符号位翻转后就会崩溃至接近零的准确率。该攻击在多种架构和数据集上均有效,表明存在普遍的脆弱性。

作者评估了针对各种图像分类模型的符号位攻击,表明少量精心选择的参数翻转会导致多种架构的准确率迅速崩溃。结果证明,无论模型大小或类型如何,都存在一致的脆弱性,大多数模型在仅几次翻转后就会经历严重的性能退化。少量针对性的符号位翻转会导致多种图像分类模型准确率迅速崩溃。攻击的有效性在不同的模型架构和规模上保持一致。大多数模型在仅几次翻转后就表现出严重的退化,表明存在根本性的脆弱性。
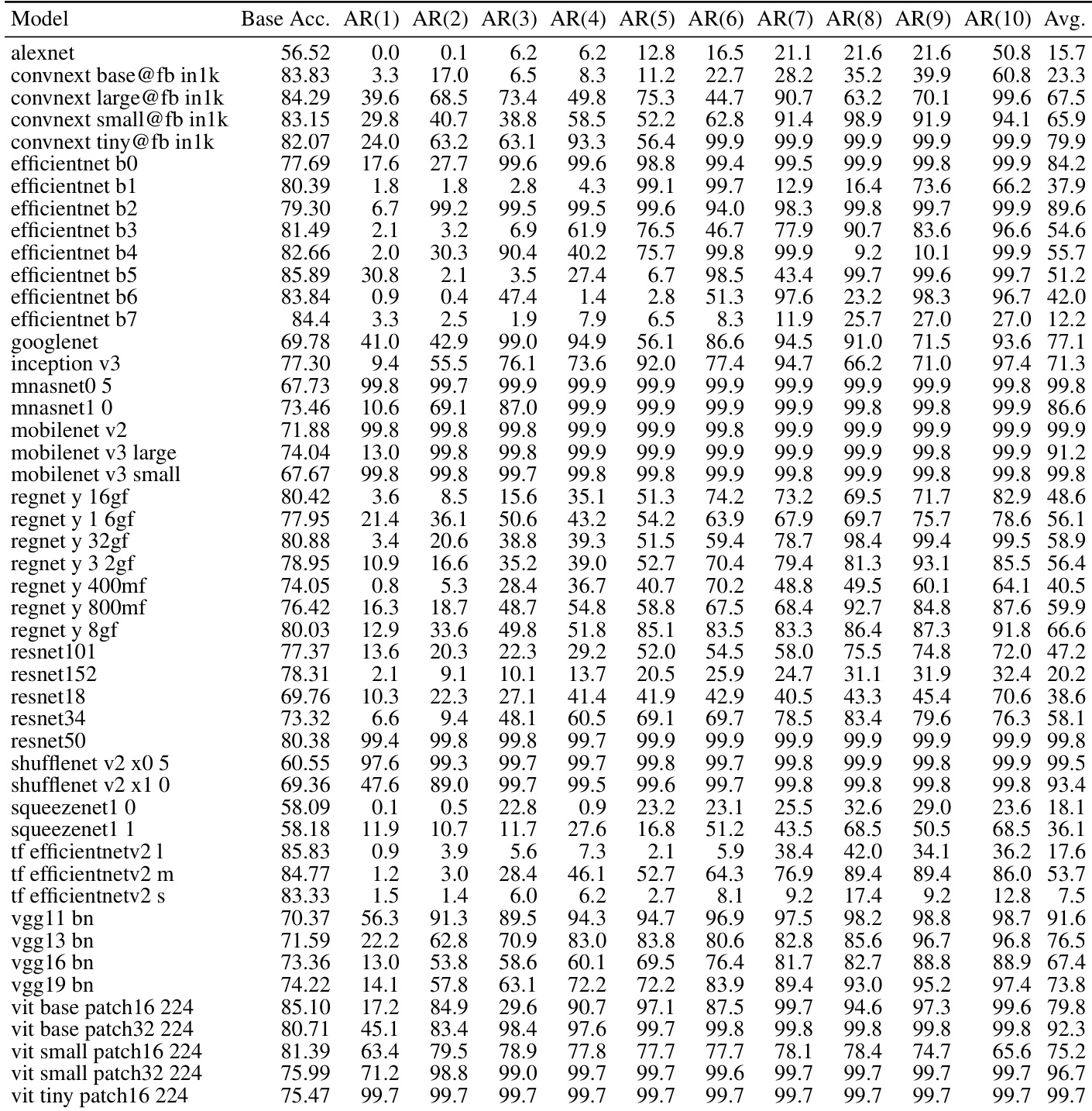
作者评估了一系列图像分类模型的针对性符号位攻击,表明少量精心选择的参数翻转会导致准确率严重下降。结果证明,在多种架构中都存在一致的脆弱性,大多数模型在仅几次翻转后准确率就会崩溃至接近于零。针对性符号位攻击会导致多种图像模型的准确率迅速且严重下降。大多数模型在少于 10 次参数翻转时就表现出近乎完全的崩溃。无论模型架构、大小或设计选择如何,该攻击都是有效的。
作者在多个数据集上评估了图像分类模型的针对性符号位攻击,显示少量精心选择的位翻转会导致准确率迅速且严重下降。该攻击在不同模型和数据集上均有效,性能在仅几次翻转后就会急剧崩溃。在多个数据集上,少量的针对性符号位翻转会导致图像分类准确率迅速崩溃。该攻击在各种模型上均有效,性能在仅几次翻转后就会大幅下降。不同的数据集显示出类似的脆弱性模式,表明模型表示中存在普遍的弱点。
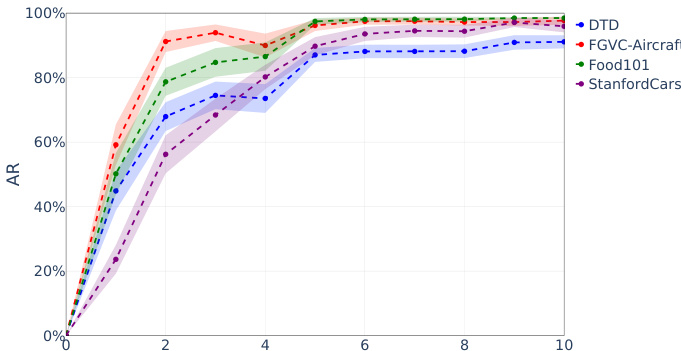
实验评估了各种位翻转攻击方法,特别侧重于针对性符号位攻击,涵盖了多种图像分类架构和数据集。结果表明,像 1P-DNL 这样无需优化且与数据无关的方法,仅需极少量的翻转就能导致准确率迅速且严重地崩溃。这种在不同模型规模和设计中表现出的持续脆弱性,表明了深度神经网络表示中存在根本性的弱点。