Command Palette
Search for a command to run...
Long-VITA: 将 Large Multi-modal Models 扩展至 100 万 tokens 并保持领先的短上下文准确率
Long-VITA: 将 Large Multi-modal Models 扩展至 100 万 tokens 并保持领先的短上下文准确率
摘要
我们推出了 Long-VITA,这是一种简单且高效的大型多模态模型(large multi-modal model),旨在处理长上下文(long-context)视觉语言理解任务。该模型能够同时处理并分析图像、视频及文本等多种模态,支持超过 4K 帧或 1M tokens 的长度,同时在短上下文多模态任务中表现出卓越的性能。我们提出了一种高效的多模态训练方案,该方案以 large language models 为起点,依次经过视觉-语言对齐(vision-language alignment)、通用知识学习,以及两个连续阶段的长序列微调(long-sequence fine-tuning)。此外,我们还实现了上下文并行分布式推理(context-parallelism distributed inference)和 logit-masked language modeling head,从而使 Long-VITA 在模型推理过程中能够扩展至无限长的图像与文本输入。在训练数据方面,Long-VITA 仅基于来自公开数据集的 17M 混合样本构建;与近期使用内部数据训练的最前沿模型相比,Long-VITA 在各类多模态 benchmark 上均展现出了 state-of-the-art 的性能。Long-VITA 已完全开源并可实现复现。通过利用我们的推理设计,Long-VITA 模型在单节点 8 GPU 的配置下,实现了高达 2 倍的 prefill 加速以及 4 倍的上下文长度扩展。我们希望 Long-VITA 能够作为一个具有竞争力的 baseline,并为开源社区推动长上下文多模态理解的发展提供有价值的见解。
一句话总结
Long-VITA 是一个大型多模态模型,通过采用多阶段训练方案和上下文并行分布式推理,能够处理图像、视频和文本中多达 100 万个 tokens,在各种基准测试中实现了最先进的性能,同时保持了领先的短上下文准确率和 2 倍的 prefill 加速。
核心贡献
- 本文介绍了 Long-VITA,这是一个大型多模态模型,能够处理多达 4K 个视频帧或 1M 个文本 tokens,同时在短上下文图像理解和长上下文视频理解任务中均保持高性能。
- 提出了一种多模态训练方案,该方案从大型语言模型开始,通过视觉语言对齐和通用知识学习,过渡到两个连续的长序列微调阶段。
- 该工作实现了上下文并行分布式推理和 logit-masked 语言模型头,以扩展到无限长的输入,在单个配备 8 个 GPU 的节点上实现了 2 倍的 prefill 加速和 4 倍的上下文长度扩展。
引言
大型多模态模型对于处理涉及图像、视频和文本的复杂现实世界数据至关重要。虽然专有模型可以处理海量输入,但现有的开源替代方案往往难以在短上下文准确率与长上下文能力之间取得平衡。以往的研究通常通过压缩视觉 tokens 来专注于长视频理解,这往往会导致性能下降,或者忽视了有效处理静态图像的能力。本文利用分阶段训练方案和上下文并行分布式推理推出了 Long-VITA,这是一种能够扩展到 100 万个 tokens 的开源模型。这种方法能够在不牺牲短上下文精度的前提下,实现对图像、短视频和长篇内容的各种高性能理解。
数据集
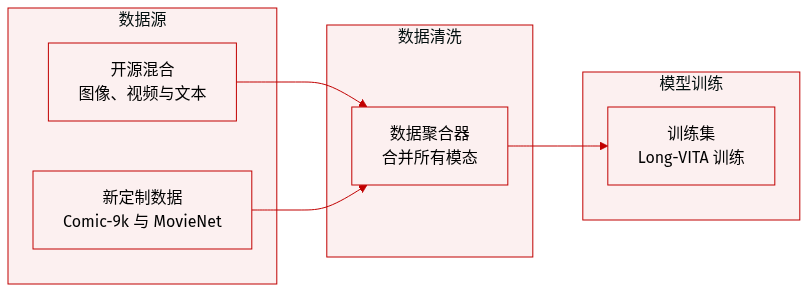
Long-VITA 训练集完全使用开源数据构建,分为以下类别:
- 图像-文本数据: 该子集分为三个功能组:
- 图像描述 (Image Captioning): 由 LLaVA-ReCap、ALLaVA-4V、ShareGPT4V 和 LLaVA-OneVision-Mid 组成。
- 视觉问答 (VQA): 结合了来自 LVIS-Instruct4V、the-cauldron、Docmatix 和 LLaVA-OneVision 的通用 VQA 数据。
- 交错式图像-文本: 包括用于多图像能力的 M4-Instruct 以及新创建的 Comic-9k 数据集。Comic-9k 数据集包含来自 9,000 本漫画书的 200,000 幅图像,并配有手动标注的梗概,以增强对超过 10 幅图像序列的理解。
- 视频-文本数据: 利用 VideoGPT-plus、ShareGemini 和 LLaVA-Video-178K 进行通用视频理解。为了支持电影级的长上下文能力,利用来自 MovieNet 的配对电影和梗概构建了 MovieNet-Summary 数据集。
- 短文本数据: 纯文本数据来源于多种集合,包括 OpenHermes-2.5、LIMA、databricks-dolly-15k,以及多个数学数据集,如 MetaMathQA、MathInstruct、Orca-Math、atlas-math-sets、goat 和 camel-ai-math。
- 长文本数据: 为了将长上下文能力迁移到多模态模型,从 Long-Instruction-with-Paraphrasing、LongForm、LongAlign-10k、LongCite-45k、LongWriter-6k、LongQLoRA、LongAlpaca 和 Long-Data-Collections 中收集数据。
需要注意的是,虽然 Comic-9k 和 MovieNet-Summary 是本工作的原创贡献,但整个训练流水线依赖于开源数据,并未采用数据过滤方法。
方法
Long-VITA 架构旨在通过避免 token 压缩和稀疏局部注意力来促进长上下文视觉理解。该多模态框架围绕三个主要组件构建:视觉编码器 (Vision Encoder)、投影器 (Projector) 和大型语言模型 (LLM)。
在主干网络方面,使用 Qwen2.5-14B-Instruct 作为 LLM。视觉组件基于 InternViT-300M 视觉编码器构建。为了处理具有不同长宽比的高分辨率图像,引入了动态分块视觉编码策略。为了弥合视觉和语言模态之间的差距,采用 2 层 MLP 作为视觉语言投影器,将图像特征映射到词嵌入空间。此外,对视觉 tokens 应用了 pixel shuffle 操作,将视觉 tokens 的总数减少到四分之一。
Long-VITA 的训练过程分为四个不同的阶段,其特点是序列长度不断增加,以逐步扩展模型的上下文窗口。
在第一阶段,重点是视觉语言对齐。目标是建立视觉特征与语言特征之间的初步联系。在此阶段,LLM 和视觉编码器被冻结,仅训练视觉投影器。主要利用描述数据,并结合 Docmatix 以增强基于文档的视觉问答 (VQA) 能力。
第二阶段过渡到通用知识的学习。一旦在嵌入空间中建立了对齐,模型将使用多样化的图像-文本数据进行广泛训练,执行图像描述、通用 VQA、OCR 和多模态对话等任务。还整合了纯文本通用指令、数学问题和算术计算。对于视频理解,包含了 VideoGPT-plus 和 ShareGemini-cap。为了管理大型数据集,采用了打包策略,将数据项拼接成固定长度的序列,第一阶段为 32K,第二阶段为 16K。在这前两个阶段中,每个打包样本的位置嵌入和注意力掩码都会重置,以确保每个文本-视觉对仅关注自身内容。
第三阶段复杂度增加,重点是长序列微调。上下文长度扩展到 128K。将第二阶段数据的采样率降低至 0.1,并引入额外的长上下文文本指令、漫画书摘要和视频理解数据集。
最后,第四阶段通过添加电影摘要数据,将长序列微调扩展到 1,024K 的上下文长度。与之前的阶段不同,第三阶段和第四阶段的训练数据被打包成固定长度的序列,而不重置位置嵌入或注意力掩码。这一特定的设计选择迫使模型在极长的上下文信息中捕捉两种模态之间的相关性。
各阶段使用的数据集组成详见下表:
实验
研究人员通过基础设施测试以及在图像和视频理解方面的全面基准测试,评估了 Long-VITA 的效率和性能。实验验证了所提出的 logits-masked 语言模型头在推理过程中显著降低了内存消耗并增加了序列长度容量。结果表明,Long-VITA 在 20B 参数以下的开源模型中达到了最先进的性能,仅使用公开数据就在多图像任务和长篇视频理解方面展示了卓越的能力。
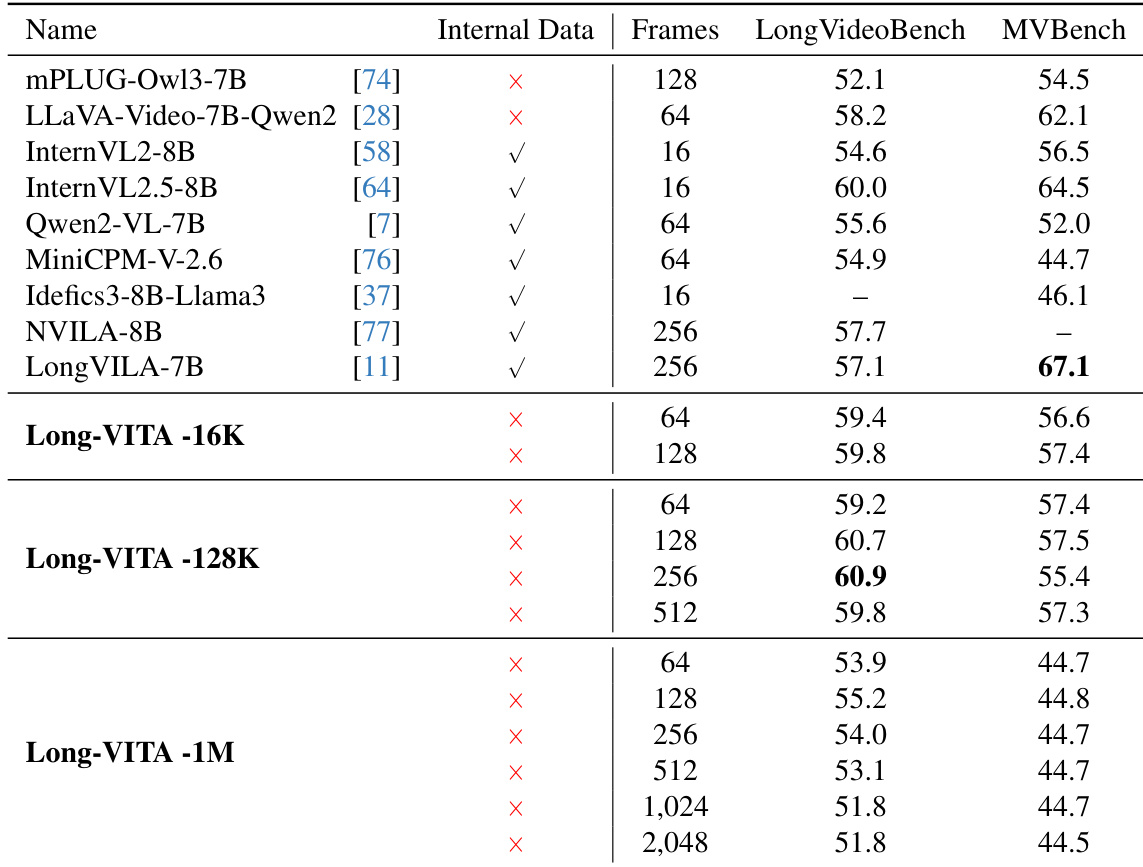
通过 LongVideoBench 和 MVBench 评估了 Long-VITA 模型在不同序列长度下的性能。结果显示,该模型在各种帧数和时间长度下均保持了强大的视频理解能力。Long-VITA-128K 在 LongVideoBench 上取得了领先性能,尤其是在较高的帧数下。Long-VITA 系列在 MVBench 的多种帧配置下均表现出竞争力的结果。即使在处理显著更多的帧时,Long-VITA-1M 也能保持一致的性能。
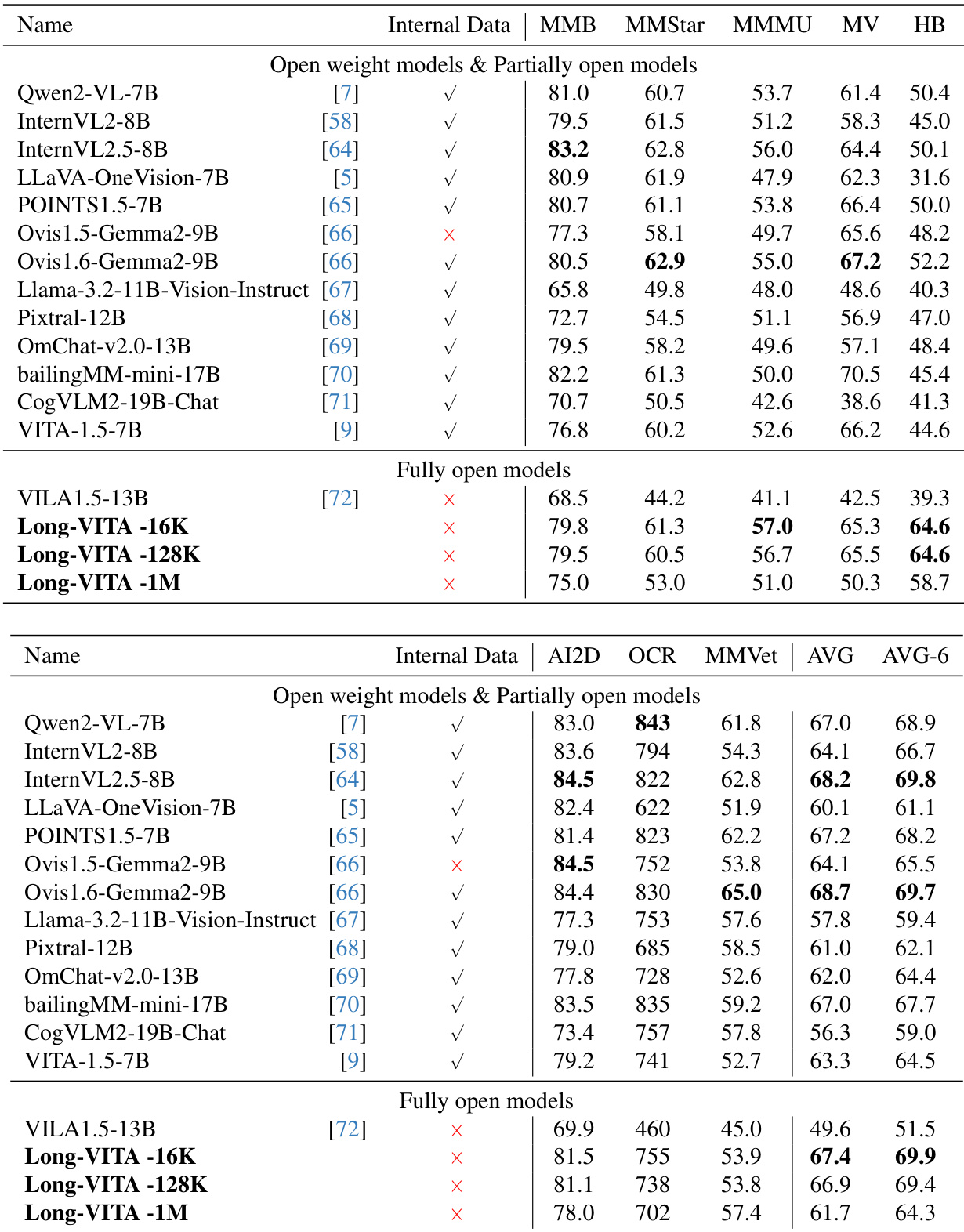
Long-VITA 模型在多个多模态基准测试中与各种开源权重和部分开源模型进行了对比。结果显示,Long-VITA 模型仅使用开源数据就在图像和视频理解任务上取得了具有竞争力的性能。与同参数范围内的其他模型相比,Long-VITA-16K 在多个图像基准测试中表现出更优越的性能。Long-VITA 模型系列在客观和通用多模态评估集合中均获得了较高的平均分。Long-VITA 模型在涉及视觉推理和 OCR 的任务中保持了强大的能力。
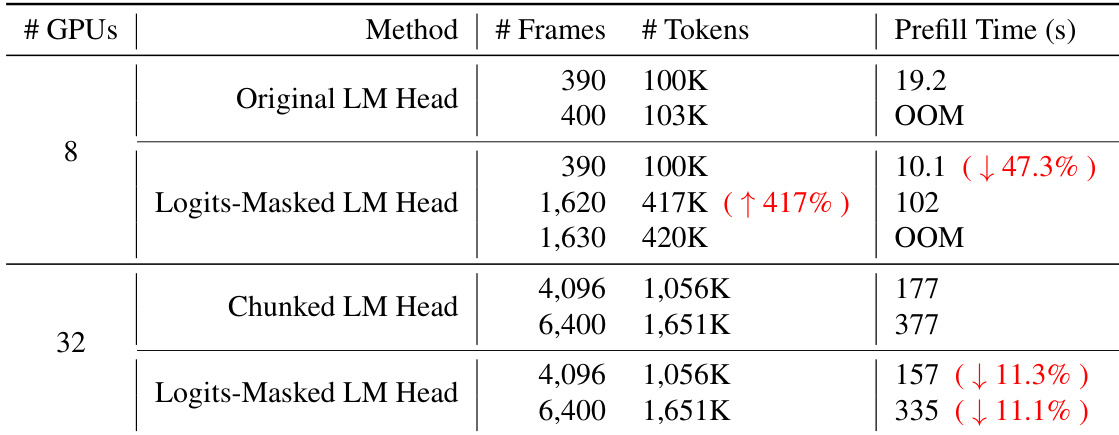
对比了不同的语言模型头设计,以评估其对序列长度容量和推理速度的影响。结果表明,与原始方法相比,logits-masked LM 头显著提高了最大支持的 tokens 数量并减少了 prefill 时间。与原始 LM 头相比,logits-masked LM 头在遇到显存溢出错误前能够支持多得多的 tokens。与原始 LM head 相比,logits-masked LM head 缩短了 prefill 时间。在较高的 token 计数下,与分块 (chunked) LM head 相比,logits-masked LM head 提供了 prefill 时间的加速。
在 LongVideoBench 基准测试上,将 Long-VITA 模型与各种开源权重、部分开源和完全开源模型进行了性能对比。结果表明,Long-VITA 模型在不同的时间长度下,特别是在短、中、长上下文类别中,均保持了强大的视频理解能力。与同参数级别的其他模型相比,Long-VITA-128K 在中长上下文视频理解方面取得了具有竞争力或更优越的性能。Long-VITA 系列在从短到长的不同视频序列帧数下均表现出稳健的性能。Long-VITA 模型在长篇视频任务上表现强劲,且不依赖于内部或专有训练数据。
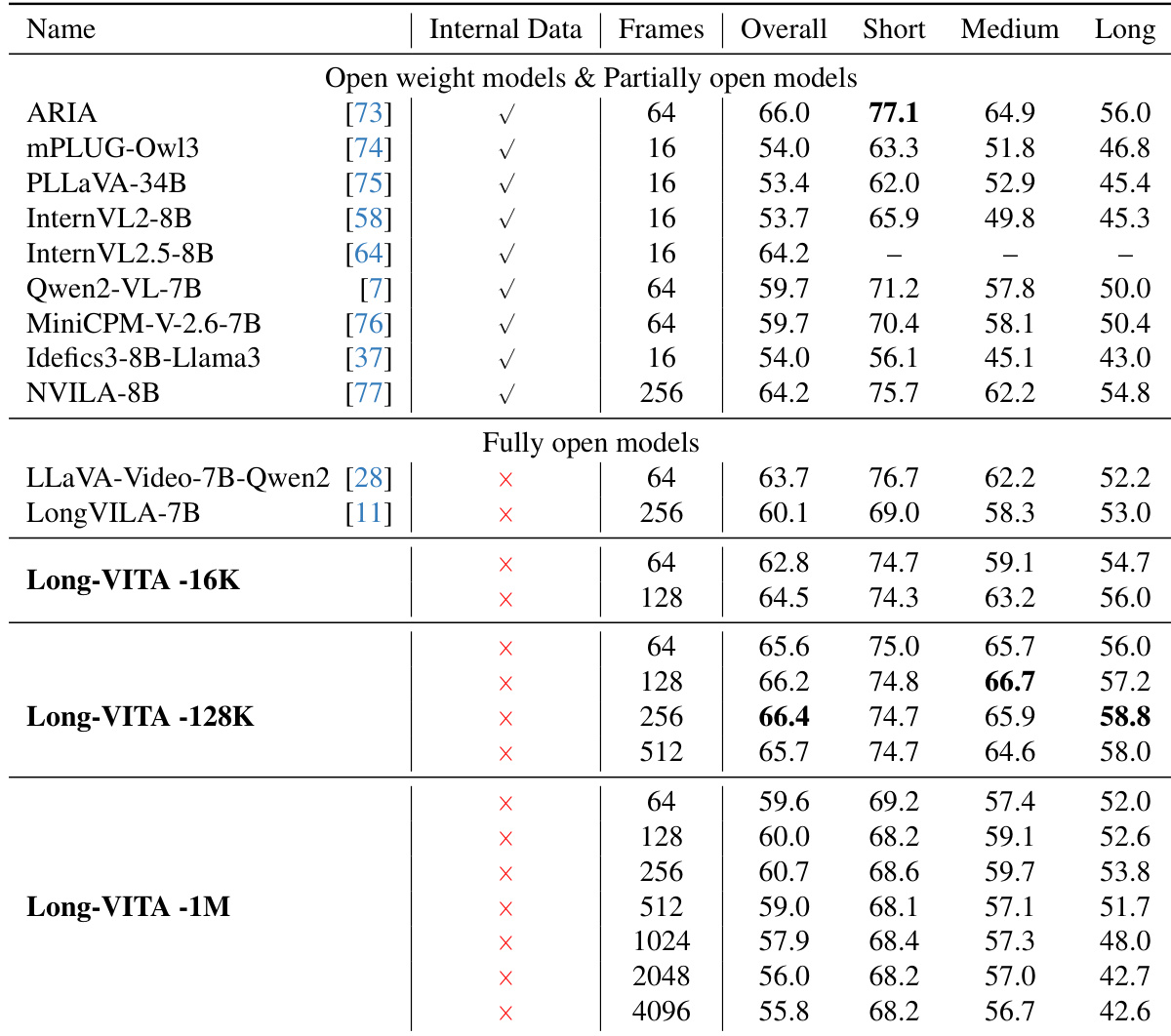
Long-VITA 模型在各种多模态基准测试和架构配置下进行了评估,以衡量视频理解、图像推理和序列容量。结果表明,模型在不同的时间长度和帧数下均保持了稳健的性能,仅使用开源数据就在视觉推理和 OCR 方面取得了具有竞争力的结果。此外,与标准架构设计相比,logits-masked LM 头的实现显著增强了序列长度容量和推理速度。