Command Palette
Search for a command to run...
Meta Audiobox 评估美学:面向语音、音乐和声音的统一自动质量评估
Meta Audiobox 评估美学:面向语音、音乐和声音的统一自动质量评估
摘要
音频美学的量化在音频处理领域仍面临复杂挑战,其主要原因是美学评价具有强烈的主观性,深受人类感知与文化背景的影响。传统方法通常依赖人工听觉评估,导致结果不一致且资源消耗巨大。本文针对日益增长的自动化音频美学预测需求,提出无需人工干预的智能评估系统。此类系统在数据筛选、大规模数据集伪标签生成以及生成式音频模型评估等应用场景中至关重要,尤其随着生成模型日趋复杂,其重要性愈发凸显。本研究提出一种全新的音频美学评估方法,通过制定新的标注指南,将人类听觉感知视角分解为四个独立维度,从而实现更精细的评估。在此基础上,我们构建并训练了无参考(no-reference)、面向单个音频项目的预测模型,能够提供更为细致的音频质量判断。实验结果表明,我们的模型在与人类平均意见得分(Mean Opinion Score, MOS)及其他现有方法的对比中,表现出相当或更优的性能。本研究不仅推动了音频美学评估领域的发展,还开源了相关模型与数据集,以促进后续研究与基准测试的开展。相关代码与预训练模型已发布于:https://github.com/facebookresearch/audiobox-aesthetics
一句话总结
Meta的FAIR与Reality Labs团队提出Audiobox-Aesthetics,一种新颖的无参考、逐项预测框架,通过基于Transformer的架构将音频美学质量分解为四个独立维度——制作质量、制作复杂度、内容愉悦度和内容实用性,并在多样化的开源数据集上进行训练。通过解耦主观与技术维度,该模型实现了比传统MOS方法更细致、更具领域泛化能力的评估,在语音和跨模态场景中均优于现有预测器,支持数据过滤、伪标签生成和生成式音频评估等应用。
主要贡献
-
本文针对主观且不一致的音频质量评估挑战,提出一种新的标注框架,将人类听觉视角分解为四个独立且可解释的维度:制作质量、制作复杂度、内容愉悦度和美学吸引力,从而实现对多种音频类型更细致、更可靠的评估。
-
提出一种统一的无参考、逐项预测模型(Audiobox-Aesthetics),在涵盖语音、音乐和声音的多样化数据集上进行训练,利用自监督表示实现鲁棒、领域无关的音频美学评估,推理阶段无需参考音频或人工标注。
-
在公开发布的AES-Natural数据集上,与人类平均意见分(MOS)及现有方法对比,模型表现出相当或更优的性能,大量消融实验验证了多轴标注方案在降低偏差和提升可解释性方面优于传统单分值度量。
引言
作者针对自动化音频美学评估的挑战展开研究,该任务对数据过滤、伪标签生成以及生成式音频模型评估等应用至关重要——尤其随着这些模型日益复杂且缺乏真实参考。以往方法严重依赖人工判断或特定领域指标(如PESQ、POLQA或FAD),存在标注成本高、泛化能力有限或无法捕捉精细感知维度的问题。此外,传统平均意见分(MOS)将多个主观维度混杂在一起,导致评估结果模糊且存在偏差。为克服这些局限,作者提出基于四个独立美学维度的统一框架:制作质量(技术保真度)、制作复杂度(音频场景丰富度)、内容愉悦度(情感与艺术影响)和内容实用性(对创作者的实际价值)。他们基于这些维度构建的标注体系,在多样化数据集(AES-Natural)上训练了无参考、逐项预测模型,其性能可媲美甚至超越人类评分。该方法实现了更可解释、可扩展且跨领域的音频质量评估,相关开源模型与数据已发布,以推动未来研究。
数据集
- 数据集包含约97,000个音频样本,涵盖语音、音效和音乐三种模态,数据来源于经过筛选的开源与授权数据集的超集,以确保真实世界代表性。
- 音频样本在语音与音乐之间均匀分布,多数时长介于10至30秒之间。数据来源多样:
- 语音:VMC22(Huang等,2022)的主测试集与跨域测试集,包括BVCC中的英语语句(自然、TTS及语音转换样本)以及Blizzard Challenge 2019中的中文TTS与自然语音。
- 音效与音乐:来自PAM数据集(Deshmukh等,2023)的500个音效与500个音乐样本,包含100个自然生成样本与400个由不同模型生成的文本到音效/音乐样本。
- 为确保平衡表示,采用基于说话人ID、流派和人口统计学等元数据的分层采样策略。标注过程中对音频模态进行打乱,以实现跨领域的统一评分。
- 所有音频均经过响度归一化,以减少音量相关偏差。
- 每个音频样本由三位独立的人工标注者进行评分,以降低方差。
- 标注者通过专家标注的黄金集进行资格筛选。仅保留与客观维度(制作质量与复杂度)真实值的皮尔逊相关系数 > 0.7 的标注者,最终获得158名多样化的标注者。
- 标注聚焦于四个美学维度:感知质量(PQ)、复杂度(CE)、实用性(CU)和制作复杂度(PC),评分采用1–10分制。提供详细的标注指南与带评分基准的音频示例,以标准化评估流程。
- 作者利用该数据集训练多轴美学评分预测器,训练数据在模态间划分,并在四个维度上保持平衡。混合比例经过调整,以确保在语音、音效与音乐上的鲁棒性。
- 训练过程中,音频采用一致的预处理(如响度归一化),对于文本到音频生成任务,音频被切分为10秒片段。
- 标注期间构建元数据,包括模态分类(语音、音乐、音效、环境声)和制作复杂度评分。
- 数据集支持域内与域外评估,在主要基于英语数据训练的情况下,对VMC22的跨域中文语音测试集仍表现出优异性能。
- 相关性分析(图2)显示各轴间相关性较低,证实了解耦美学维度的价值。
- 该数据集支持通过人工标注真实值与预测得分评估模型生成音频,人类与模型预测在相关轴上表现出高度一致性。
方法
作者采用基于Transformer的架构构建美学评分预测模型Audiobox-Aesthetics,该模型处理音频输入,预测四个独立维度的得分:制作质量、制作复杂度、内容愉悦度和内容实用性。模型以16kHz采样的输入波形为起点,首先通过CNN编码器提取初始特征。这些特征随后输入Transformer编码器,该编码器基于WavLM架构,包含12层,隐藏维度为768。编码器生成一系列隐藏状态 hl,t∈Rd,其中 d 为隐藏大小,L 为层数,T 为时间步数。为获得统一的音频嵌入 e∈Rd,模型对各层与时间步的隐藏状态进行加权平均,使用可学习权重 wl。嵌入计算如下:
zl=∑l=1Lwlwl e^=t=1∑Tl=1∑LThl,tzl e=∥e^∥2e^该归一化嵌入 e 随后输入多个多层感知机(MLP)模块,每个模块由线性层、层归一化和GeLU激活函数构成。最终输出为四个维度的预测美学得分 Y^={y^PQ,y^PC,y^CE,y^CU}。模型通过最小化包含平均绝对误差(MAE)与均方误差(MSE)的联合损失函数进行训练:
L=a∈{PQ,PC,CE,CU}∑(ya−y^a)2+∣ya−y^a∣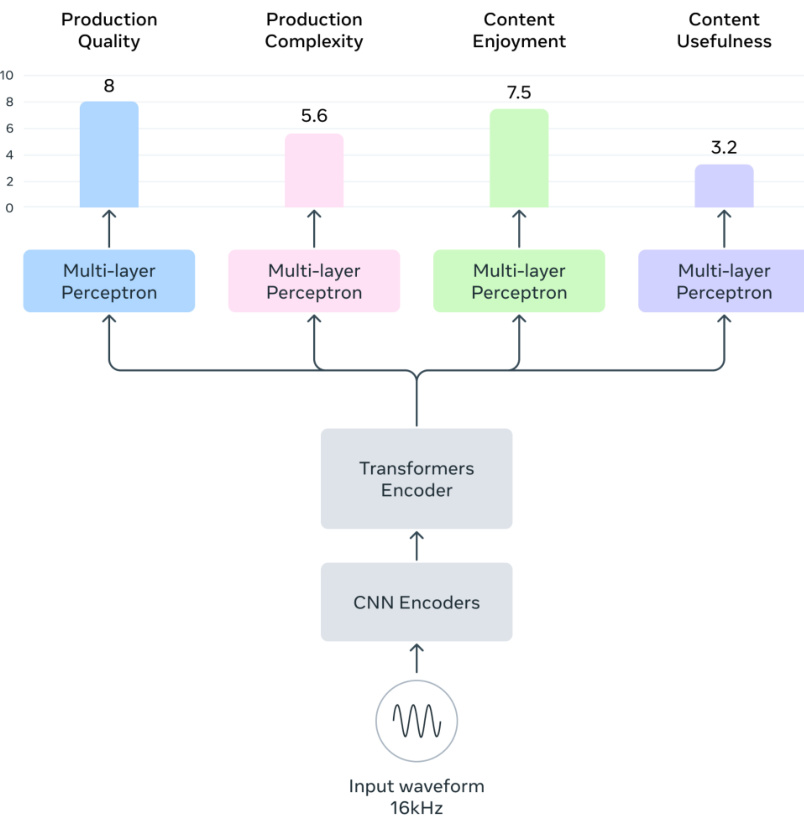
实验
- 在语音与通用音频质量上评估四种AES预测器(Audiobox-Aesthetics-PQ、PC、CE、CU),以P.808 MOS(DNSMOS)、SQUIM-PESQ、UTMOSv2和PAM为基线;Audiobox-Aesthetics-PQ在语音测试集上达到0.91的逐句级皮尔逊相关系数,优于UTMOSv2与SQUIM-PESQ。
- 在下游任务(TTS、TTM、TTA)中应用美学预测器,采用两种策略:过滤(移除低于p百分位的音频,p=25,50)与提示(添加“Audio quality: y”前缀,y=round(score)/r,r=2,5)。
- 提示策略在客观与主观评估中均优于过滤策略:在保持音频对齐(WER、CLAP相似度)的同时提升质量,95%置信区间显示在所有任务的成对比较中均持续胜出。
- 在自然音效与音乐数据集上,Audiobox-Aesthetics-PQ分别达到0.87与0.85的逐句级皮尔逊相关系数,表明其在语音之外也具备强大泛化能力。
作者使用表格对比多种音频质量预测器(包括其提出的Audiobox-Aesthetics模型)与人工标注得分在四个质量维度上的表现。结果显示,Audiobox-Aesthetics-PQ、-PC、-CE与-CU在多数类别中相关性高于基线模型,其中Audiobox-Aesthetics-CU在GT-CU上达到最高相关性。
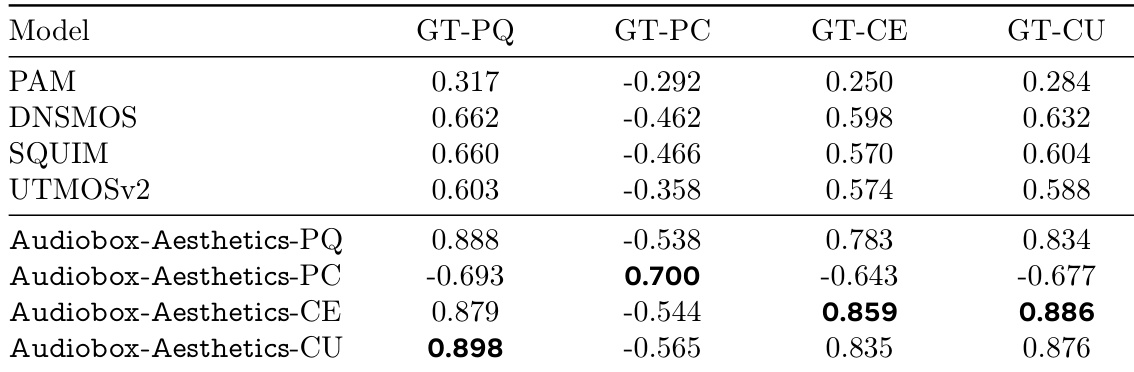
作者使用表格对比不同模型在预测音频质量各指标上的表现。结果显示,PAM在多数类别中与人工标注得分的相关性最高,而Audiobox-Aesthetics-PC在GT-PC指标上表现最佳,表明其在预测制作复杂度方面具有优势。
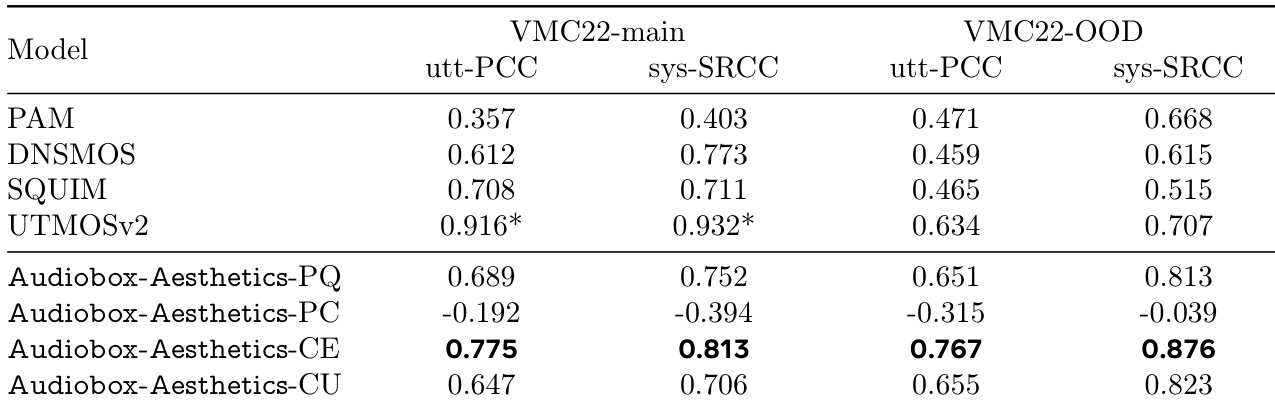
作者使用一系列已建立的音频质量预测器及其提出的Audiobox-Aesthetics模型,评估其在语音质量任务上的表现。结果显示,Audiobox-Aesthetics-CE在逐句与系统级指标上均达到最高相关性,尤其在VMC22-OOD数据集上全面超越所有基线模型。
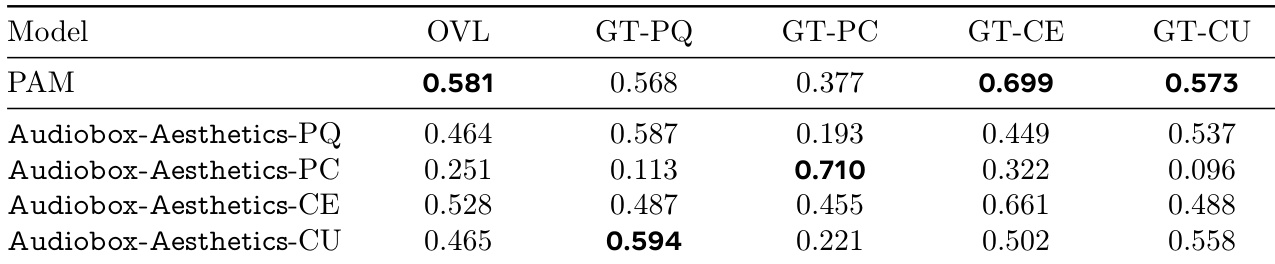
作者使用表格对比其提出的Audiobox-Aesthetics模型与PAM基线在五个不同质量维度上的表现。结果显示,Audiobox-Aesthetics-PQ在整体质量(OVL)与GT-PQ上与人工标注得分相关性最高,Audiobox-Aesthetics-CE在GT-CE上表现最佳,Audiobox-Aesthetics-PC在GT-PC上得分最高。
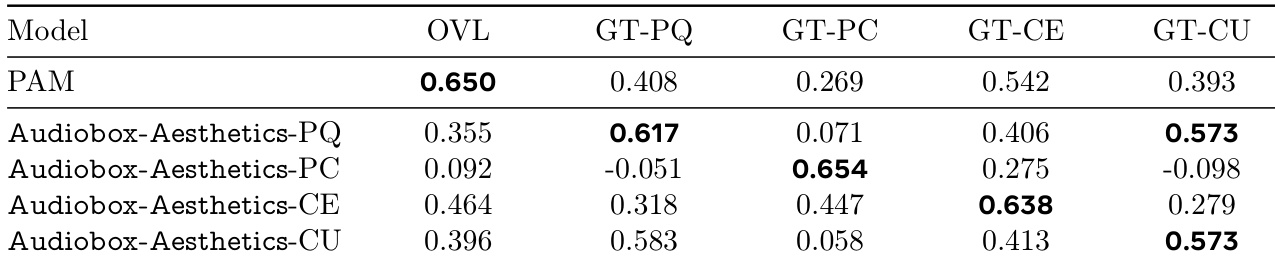
作者使用表格对比其提出的Audiobox-Aesthetics模型与PAM基线在四个质量维度(制作质量PQ、制作复杂度PC、内容愉悦度CE、内容实用性CU)上的表现。结果显示,Audiobox-Aesthetics-PQ在GT-PQ上相关性最高,Audiobox-Aesthetics-PC在GT-PC上最高,Audiobox-Aesthetics-CE在GT-CE上最高,Audiobox-Aesthetics-CU在GT-CU上最高,表明所提模型在预测各音频质量方面均优于PAM。