Command Palette
Search for a command to run...
VideoLLaMA 3:面向图像与视频理解的前沿多模态基础模型
VideoLLaMA 3:面向图像与视频理解的前沿多模态基础模型
摘要
在本文中,我们提出 VideoLLaMA3,一种面向图像与视频理解的更先进的多模态基础模型。VideoLLaMA3 的核心设计理念是“以视觉为中心”。“以视觉为中心”具有双重含义:一是以视觉为中心的训练范式,二是以视觉为中心的框架设计。我们提出的以视觉为中心的训练范式的关键洞察在于:高质量的图文数据对于图像与视频的理解均至关重要。因此,我们并未致力于构建大规模的视频-文本数据集,而是聚焦于构建大规模且高质量的图像-文本数据集。VideoLLaMA3 的训练过程包含四个阶段:1)视觉编码器适配(Vision Encoder Adaptation):使视觉编码器能够接收不同分辨率的图像作为输入;2)视觉-语言对齐(Vision-Language Alignment):利用涵盖多种类型(包括场景图像、文档、图表等)的大规模图像-文本数据,以及纯文本数据,联合微调视觉编码器、投影模块与大语言模型(LLM);3)多任务微调(Multi-task Fine-tuning):引入图像-文本监督微调(SFT)数据以支持下游任务,并结合视频-文本数据为视频理解建立基础;4)以视频为中心的微调(Video-centric Fine-tuning):进一步提升模型在视频理解方面的性能。在框架设计方面,为更有效地捕捉图像中的细粒度信息,预训练的视觉编码器被调整为能够将不同尺寸的图像编码为对应数量的视觉标记(vision tokens),而非固定数量的标记。对于视频输入,我们根据帧间相似性动态减少视觉标记的数量,从而使视频表征更加精确且紧凑。得益于以视觉为中心的设计理念,VideoLLaMA3 在图像与视频理解的各项基准测试中均取得了出色的性能表现。
一句话总结
达摩院与湖畔实验室的作者提出 VideoLLaMA3,这是一种以视觉为中心的多模态基础模型,通过利用大规模高质量图文数据和四阶段训练范式,在图像与视频理解任务中均达到最先进性能。该模型引入任意分辨率视觉分词(Any-resolution Vision Tokenization)与差分帧剪枝(Differential Frame Pruning),实现灵活、高保真的视觉表征与高效的视频处理,显著提升了文档理解、数学推理和长视频分析能力。
主要贡献
- VideoLLaMA3 提出以视觉为中心的训练范式,优先强化图像理解以提升视频理解能力,利用高质量图文数据增强视觉编码器的鲁棒性,再聚焦于视频任务中的时序建模。
- 模型包含两项关键的视觉中心框架创新:通过旋转位置编码(Rotary Position Embedding)支持动态分辨率输入,以处理不同宽高比和高分辨率图像;以及视频 token 压缩技术,减少冗余并提升计算效率。
- VideoLLaMA3 在多样化的基准测试中均达到最先进水平,无论在图像理解(如图表与数学推理)还是视频任务(如长视频、时间定位)方面均表现卓越,多项指标超越先前模型。
引言
作者借鉴以图像为中心的多模态大语言模型(MLLM)的成功经验,应对视频理解中的挑战——时序动态性以及低质量、稀疏的视频-文本数据集限制了进展。以往工作常面临 token 处理效率低、输入表示僵化、泛化能力受限等问题,主要源于对稀缺且噪声较多的视频数据的依赖。为克服这些局限,作者提出 VideoLLaMA3,一种以视觉为中心的 MLLM,首先通过四阶段训练范式——视觉编码器适配、视觉-语言对齐、多任务微调、视频中心微调——利用高质量图文数据强化图像理解能力。模型引入两项关键技术:通过旋转位置编码实现动态分辨率输入,以处理可变宽高比和高分辨率图像;以及视频 token 压缩,以减少冗余并提升计算效率。这些设计使 VideoLLaMA3 在图像与视频基准测试中均达到最先进水平,涵盖文档理解、数学推理、长视频理解与时间定位任务,同时在跨模态间保持强泛化能力。
数据集
- 用于训练 VideoLLaMA3 的 VL3-Syn7M 数据集包含 700 万张图像-标题对,数据源自 COYO-700M,并经过多阶段清洗流程处理。
- 关键过滤步骤包括:宽高比过滤以去除极端图像形状,使用专用模型进行美学评分过滤以剔除低质量视觉内容,通过 BLIP2 与 CLIP 进行图文相似性评分以保留可描述内容,以及利用 CLIP 特征与 k-NN 进行视觉特征聚类,确保语义多样性与类别覆盖均衡。
- 过滤后,图像进行重新标注:使用 InternVL2-8B 生成简短标题,使用 InternVL2-26B 生成详细标题,形成两个不同子集——VL3-Syn7M-short 与 VL3-Syn7M-detailed,分别用于不同训练阶段。
- 该数据集被整合进多阶段训练框架:
- 在视觉编码器适配阶段,VL3-Syn7M-short 与 LLaVA-Pretrain-558K、Object365、SA-1B 结合,以增强场景理解与细粒度特征提取能力。
- 在视觉-语言对齐阶段,VL3-Syn7M 与 COCO-2017、ShareGPT4o、ShareGPT4V、DenseFusion、LLaVA-Recap 联合使用,并应用重新标注以提升标题质量。
- 在多任务微调阶段,VL3-Syn7M 支持通用图像、文档、OCR、定位与多图像任务,额外引入 Pixmo、Cambrian-10M 及专用数据集如 Demon-Full 与 Contrastive-Caption。
- 在视频中心微调阶段,VL3-Syn7M 用于通用图像理解,同时结合 LLaVA-Video、ShareGPT-4o 以及由 Qwen2-VL-72B 生成的合成密集标题(来自 Panda-70M)数据,以强化时空推理能力。
- 数据格式为 token 序列:图像使用 “\n” 分隔 token,视频在每帧前添加 “Time: xxs” 时间戳并用逗号分隔帧,流式视频则采用帧、时间戳与回答 token 交错排列(如 “GPT: xxx”)以模拟实时交互。
- 视频训练中,长视频按密集标题间隔分割为两分钟片段,构建合成流式对话以支持多轮理解。
- 时间定位数据转换为文本格式(如 “1.0-2.0 s”),并与 ActivityNet、YouCook2、Charades-STA 等数据集结合,用于训练模型实现精确事件定位。
方法
作者采用以视觉为中心的方法设计 VideoLLaMA3,一种用于图像与视频理解的多模态基础模型。模型核心架构包括视觉编码器、视频压缩器、投影器与大语言模型(LLM)。视觉编码器初始化为预训练的 SigLIP,用于提取视觉特征,投影器则弥合视觉编码器与 LLM 之间的表征差距。所用 LLM 基于 Qwen2.5 架构。为处理不同分辨率输入,模型采用任意分辨率视觉分词(AVT),通过动态生成对应数量的视觉 token,使视觉编码器可处理任意尺寸的图像与视频。该方法通过将视觉 Transformer(ViT)中的绝对位置嵌入替换为 2D-RoPE 实现,使编码器在不同分辨率下仍能保持空间关系。对于视频输入,模型进一步通过视频压缩器减少 token 数量,以消除冗余信息。
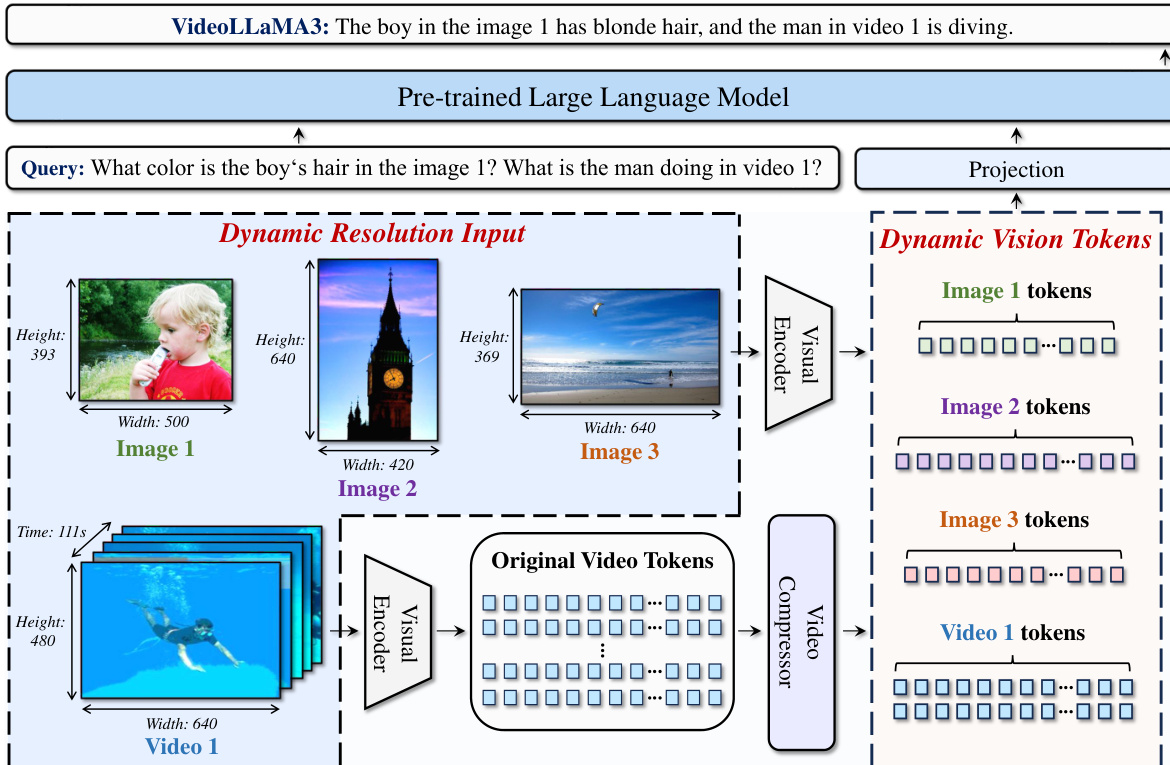
如图所示,模型架构支持动态分辨率输入,不同尺寸的图像被处理为长度可变的视觉 token 序列。这种灵活性对于保留图像中的细粒度细节至关重要。对于视频,模型首先通过双线性插值对每帧进行 2×2 空间下采样,以限制上下文长度。为进一步减少冗余,引入差分帧剪枝(DiffFP)组件。该组件在像素空间中计算连续帧间 patch 的 1-范数距离,并将距离低于阈值的 patch 剪枝,有效去除内容变化极小的帧。该过程生成更紧凑且精确的视频输入表征。
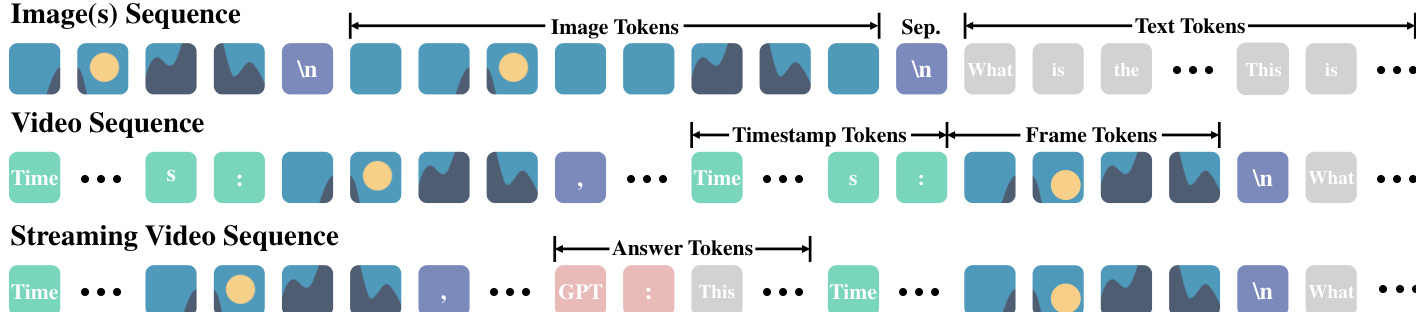
VideoLLaMA3 的训练分为四个阶段。第一阶段为视觉编码器适配,使用大规模图像数据集对视觉编码器与投影器进行微调,使编码器转变为动态分辨率处理器。第二阶段为视觉-语言对齐,联合微调视觉编码器、投影器与 LLM,使用多样化的图文与纯文本数据,实现多模态知识融合。第三阶段为多任务微调,在图像与视频问答数据组合上进行指令微调,提升模型指令遵循能力,为视频理解奠定基础。第四阶段为视频中心微调,通过视频-文本数据、纯图像数据与纯文本数据训练,全面优化视频理解能力,所有模型参数均未冻结。该分阶段训练流程确保模型先建立强大的图像理解能力,再以此为基础提升视频理解性能。
实验
- 对 VideoLLaMA3-2B 与 VideoLLaMA3-7B 在图像与视频基准测试中进行评估,验证其多模态理解能力。
- 在图像基准测试中,VideoLLaMA3-2B 在 InfoVQA 上达到 69.4%,超越此前最佳水平 3.9%;在 MathVista 上得分为 59.2%,领先先前方法 7.9%;在 RealWorldQA 上得分为 67.3%,超过此前最先进水平 4.4%。
- VideoLLaMA3-7B 在 MathVision 上得分为 65.7%,超越此前最佳水平 6.5%;在 RealWorldQA 上得分为 67.3%,较先前模型提升 2.0%。
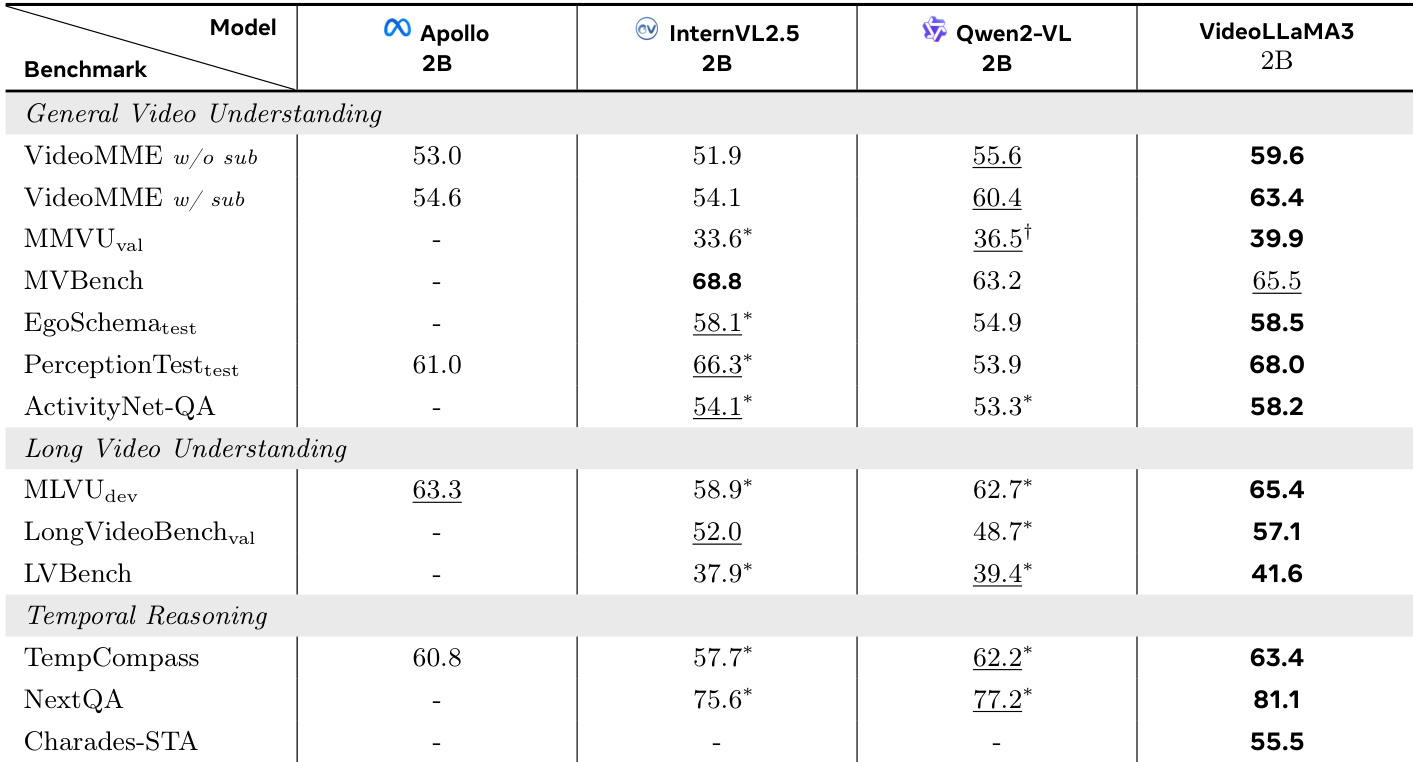
- 在视频基准测试中,VideoLLaMA3-2B 在 VideoMME w/o sub(59.6%)、VideoMME w/ sub(63.4%)、ActivityNet-QA(58.2%)、PerceptionTest-test(68.0%)与 MVBench(65.5%)中均取得最高分,并在所有长视频基准测试中领先:MLVU-dev(65.4%)、LongVideoBench-val(57.1%)、LVBench(40.4%)。
- VideoLLaMA3-7B 在 7 个通用视频理解基准中的 5 个中领先,且在 MLVU-dev 上表现最佳,在 LongVideoBench-val 与 LVBench 上也取得优异成绩。
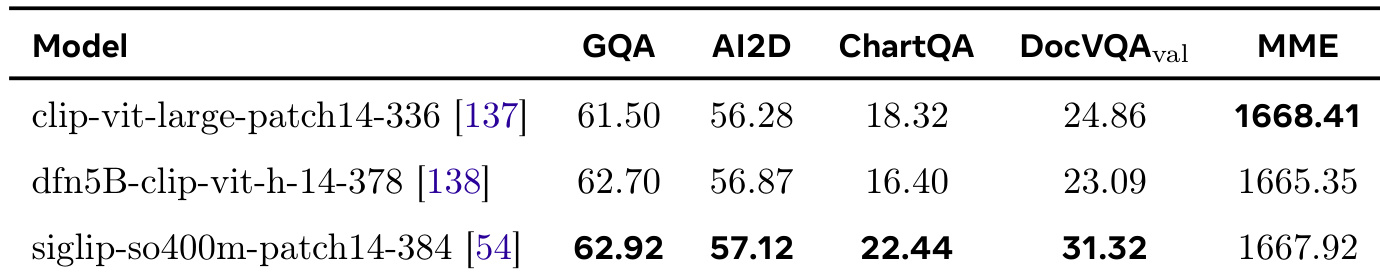
- 消融实验确认 SigLIP 为最优视觉编码器,其在文本丰富与细粒度理解任务中表现优于 CLIP 与 DFN。
作者使用 VideoLLaMA3-7B 在视频基准测试中评估其性能,并与多个最先进模型进行对比。结果表明,VideoLLaMA3-7B 在多项任务中取得最高分,包括 MLVU-dev(73.0%)、LongVideoBench-val(59.8%)与 NextQA(84.5%),展现出强大的长视频理解与时间推理能力。
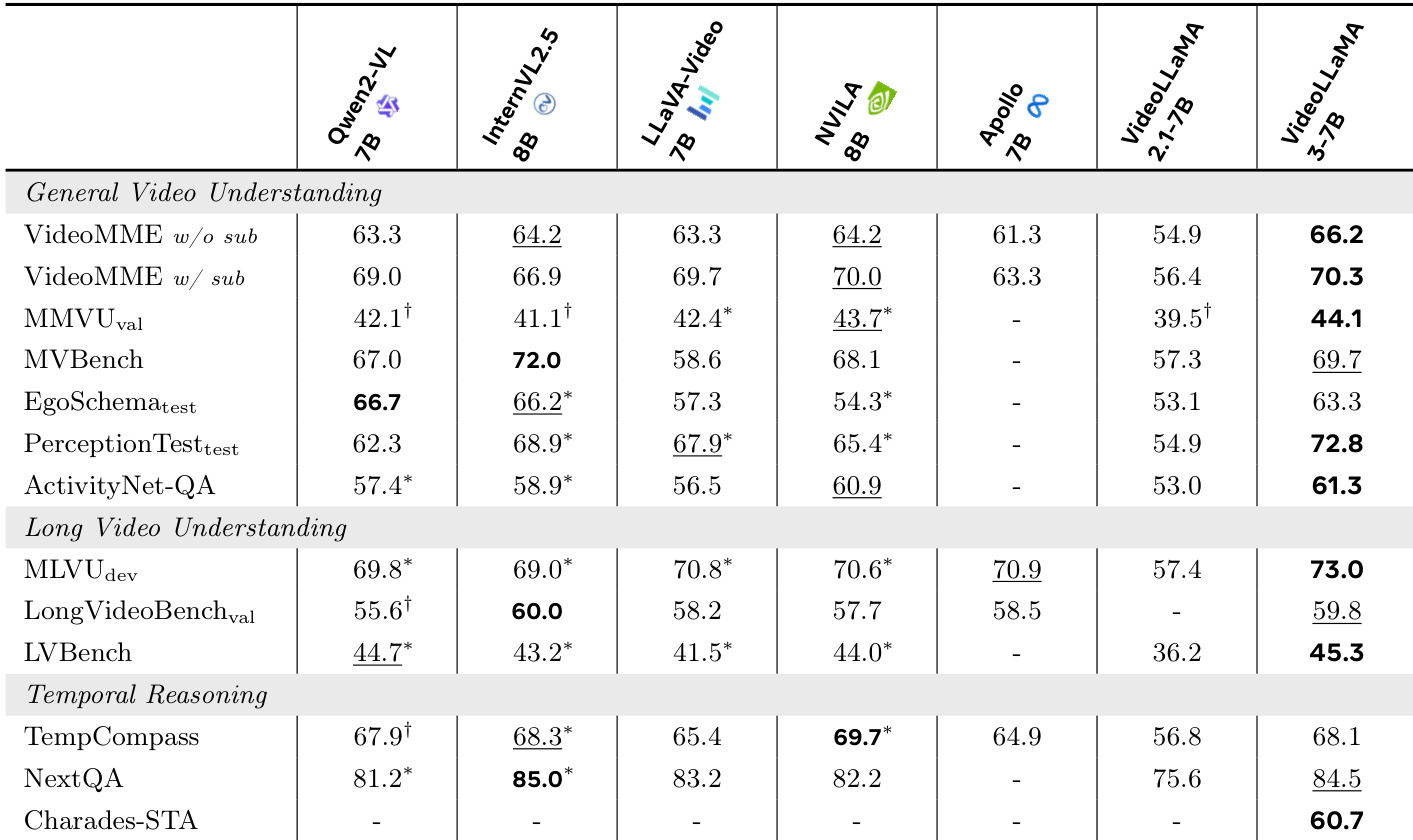
结果表明,与其它模型相比,VideoLLaMA3 在多数基准测试中均取得最高分。其在通用视频理解、长视频理解与时间推理任务中均超越 Qwen2-VL、LLaVA-Video 与 InternVL2.5 等基线模型,展现出在短视频与长视频分析中的强大性能。
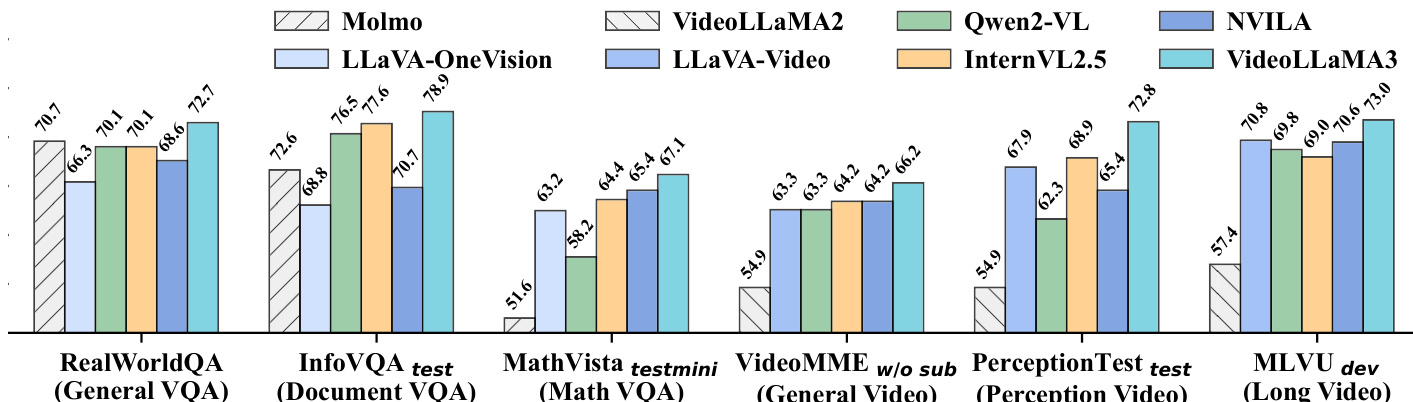
作者对 CLIP、DFN 与 SigLIP 三种视觉编码器在数据集子集上进行消融比较,评估其在多个基准上的表现。结果表明,SigLIP 显著优于其他两种编码器,尤其在细粒度文本理解任务中表现突出,因此作者选定其作为后续开发的基线视觉编码器。
作者使用表格对比 VideoLLaMA3-2B 与多个基线模型在视频理解基准上的性能。结果表明,VideoLLaMA3-2B 在多项任务中取得最高分,包括 VideoMME w/o sub(59.6%)、VideoMME w/ sub(63.4%)与 PerceptionTest-test(68.0%)。其在长视频理解与时间推理任务中同样领先,MLVU-dev 得分为 65.4%,NextQA 得分为 81.1%,展现出在多样化视频理解任务中的优异表现。
作者使用表 5 评估 2B 模型变体在图像基准上的表现,重点关注文档/图表/场景文本理解、数学推理、多图像理解与通用知识问答。结果表明,VideoLLaMA3-2B 在多个关键任务中取得最高分,包括 DocVQA test(91.9)、OCRBench(779)与 RealWorldQA(67.3),全面超越所列基线模型。其在数学推理方面表现尤为突出,在 MathVista 上得分为 59.2,显著高于第二名模型。