Command Palette
Search for a command to run...
DeepSeek-R1:通过强化学习激励LLM的推理能力
DeepSeek-R1:通过强化学习激励LLM的推理能力
摘要
我们推出了首代推理模型——DeepSeek-R1-Zero 与 DeepSeek-R1。DeepSeek-R1-Zero 是通过大规模强化学习(Reinforcement Learning, RL)训练而成,未经过监督微调(Supervised Fine-Tuning, SFT)的预处理步骤,展现出卓越的推理能力。在强化学习的驱动下,DeepSeek-R1-Zero 自然涌现出多种强大且引人注目的推理行为。然而,该模型在实际应用中仍面临可读性较差、语言混杂等问题。 为解决上述挑战并进一步提升推理性能,我们推出了 DeepSeek-R1,该模型引入了多阶段训练策略,并在强化学习前加入冷启动数据(cold-start data)。得益于这一改进,DeepSeek-R1 在推理任务上的表现已达到与 OpenAI-o1-1217 相当的水平。 为支持学术界的研究工作,我们开源了 DeepSeek-R1-Zero、DeepSeek-R1 以及基于 Qwen 和 Llama 架构蒸馏得到的六款密集模型(1.5B、7B、8B、14B、32B 和 70B),以促进推理模型领域的开放协作与持续创新。
一句话总结
DeepSeek-AI 的研究者提出了 DeepSeek-R1,一种通过多阶段训练和强化学习前的冷启动数据增强的推理模型,性能与 OpenAI-o1-1217 相当;与缺乏监督微调且存在可读性问题的前代模型 DeepSeek-R1-Zero 不同,DeepSeek-R1 提升了连贯性和推理准确性,并开源了六个不同规模的版本供社区使用。
主要贡献
-
本工作首次提出一种纯强化学习(RL)方法,在无需任何监督微调(SFT)的情况下,为大语言模型构建强大的推理能力,证明了像 DeepSeek-R1-Zero 这样的模型可通过大规模 RL 自我演化出高级推理行为,在 AIIME 2024 上通过多数投票实现 86.7% 的 pass@1 分数。
-
为提升可读性和通用性能,DeepSeek-R1 引入了包含冷启动数据和迭代强化学习的多阶段训练流程,结合拒绝采样和额外的 SFT,使模型在多种推理基准测试中达到与 OpenAI-o1-1217 相当的性能。
-
DeepSeek-R1 的推理能力成功地被蒸馏到更小的密集模型(1.5B 到 70B)中,以 Qwen 和 Llama 为基底模型,其中蒸馏后的 14B 模型超越了 QwQ-32B-Preview,而 32B 和 70B 版本在开源密集模型中创下新纪录。
引言
研究者利用强化学习(RL)提升大语言模型(LLMs)的推理能力,以应对在数学、编程和科学问题求解等任务中对复杂、分步推理能力日益增长的需求。以往方法严重依赖大量人工标注的思维链(CoT)数据进行监督微调(SFT),成本高且耗时,或使用推理时缩放技术,但缺乏泛化能力。本工作的关键贡献是开发了 DeepSeek-R1-Zero,一种纯强化学习方法,使基础模型无需任何监督数据即可自我演化推理技能,在 AIIME 2024 等基准测试中表现强劲。为提升连贯性和泛化能力,研究者进一步提出 DeepSeek-R1,结合少量冷启动 CoT 数据与包含 RL、拒绝采样和监督微调的多阶段流程,最终模型性能达到与 OpenAI 的 o1-1217 相当水平。最后,他们证明推理能力可有效蒸馏至小型密集模型,其蒸馏后的 14B 模型在推理基准测试中超越了当前最先进的开源模型。
方法
研究者采用多阶段训练流程开发 DeepSeek-R1,建立在 DeepSeek-R1-Zero 的基础之上,后者通过强化学习(RL)直接训练,无需监督微调(SFT)。该方法使模型自然发展出自我验证、反思以及生成长思维链(CoT)响应等推理行为。该训练过程的框架如以下示意图所示。
DeepSeek-R1-Zero 使用组相对策略优化(GRPO)进行训练,GRPO 是一种策略优化的变体,通过组内评分估计基线,无需独立的评判模型。对于每个输入问题 q,GRPO 从当前策略 πθold 中采样一组输出 {o1,o2,⋯,oG},并通过最大化以下目标函数来优化策略模型 πθ:
IGRPO(θ)=E[q∼P(Q),{oi}i=1G∼πθold(O∣q)]G1∑i=1G(min(πθold(oi∣q)πθ(oi∣q)Ai,clip(πθold(oi∣q)πθ(oi∣q),1−ε,1+ε)Ai)−βDKL(πθ∣∣πref)),其中 Ai 为优势值,计算方式为奖励 ri 与组均值和标准差的归一化差值:
Ai=std({r1,r2,⋯,rG})ri−mean({r1,r2,⋯,rG}).KL 散度项 DKL(πθ∣∣πref) 用于正则化策略更新,πref 通常为上一阶段的策略。超参数 ε 和 β 分别控制裁剪范围和 KL 惩罚强度。
为训练 DeepSeek-R1-Zero,研究者采用基于规则的奖励系统,包含两个部分:准确率奖励和格式奖励。准确率奖励来自确定性验证机制,例如检查数学答案的正确性或根据测试用例编译代码。格式奖励强制模型将推理过程用 <tool_call> 和 </tool_call> 标签包裹,最终答案置于 <answer> 标签内,确保输出格式一致。研究者避免使用神经网络奖励模型,因其易受奖励黑客攻击,并引入额外复杂性和资源开销。
DeepSeek-R1-Zero 的训练模板旨在引导模型生成推理过程后接最终答案,如表 1 所示。该模板设计极为简洁,避免内容特定约束,以允许模型在强化学习过程中自然发展推理行为。
对于 DeepSeek-R1,研究者引入冷启动阶段以缓解早期强化学习训练的不稳定性。该阶段通过收集少量高质量、可读性强的长思维链响应数据集,用于在强化学习前对基础模型进行微调。冷启动数据通过少量样本提示、带反思的直接生成以及人工标注者的后处理进行构建。所得数据结构包含推理过程和摘要,确保可读性和连贯性。此步骤解决了 DeepSeek-R1-Zero 中出现的可读性差和语言混杂问题。
冷启动之后,DeepSeek-R1 进入面向推理的强化学习阶段。沿用相同的 GRPO 框架,但增加语言一致性奖励,通过测量思维链中目标语言词汇的比例来惩罚语言混杂。该奖励与准确率奖励结合,形成最终奖励信号。训练聚焦于数学、编程和逻辑等推理密集型任务,目标是在提升可读性的同时增强推理能力。
随后进行第二阶段强化学习,以对齐人类偏好,重点关注有用性和无害性。对于推理任务,使用基于规则的奖励;对于通用场景,使用奖励模型捕捉细微的人类偏好。有用性奖励评估最终摘要的实用性与相关性,而无害性奖励则评估整个响应(包括推理过程),以检测并缓解有害内容。
最后,研究者执行蒸馏,将推理能力迁移到更小的模型中。他们使用从 DeepSeek-R1 收集的 80 万样本,对 Qwen 和 Llama 等开源模型进行微调。该蒸馏过程仅通过监督微调完成,不包含强化学习阶段,以证明该技术的有效性。所得蒸馏模型展现出增强的推理能力,使更多用户能够访问具备推理能力的模型。
实验
-
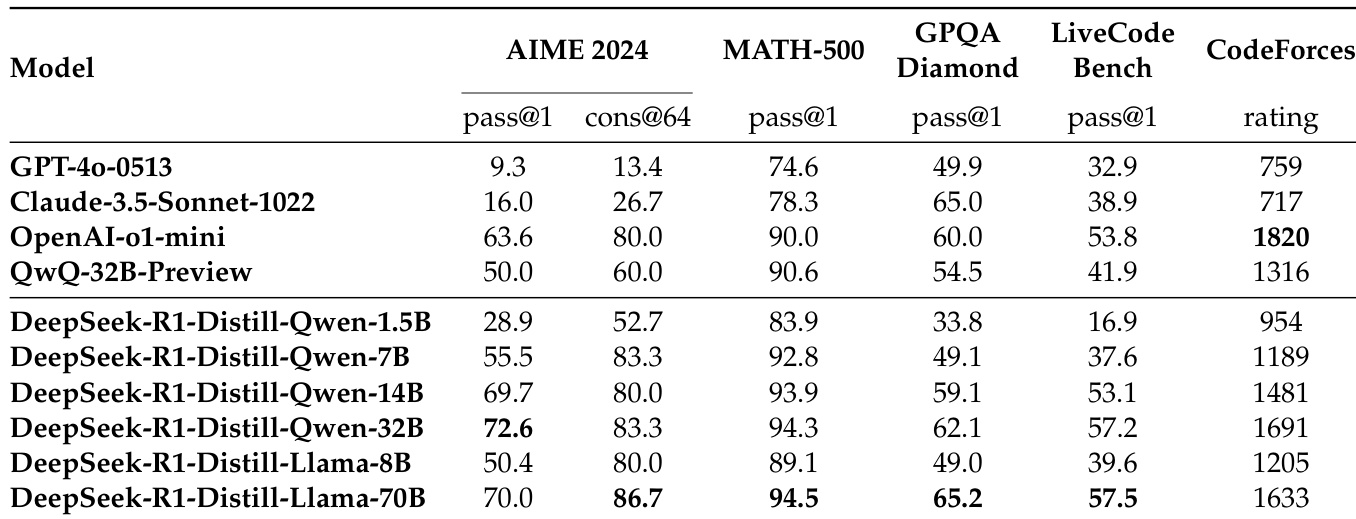
蒸馏实验表明,大型模型(如 DeepSeek-R1)中的推理模式可有效迁移到小型模型中,性能优于通过强化学习训练的小模型。DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上达到 55.5%,超越 QwQ-32B-Preview;DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 上得分为 72.6%,MATH-500 为 94.3%,LiveCodeBench 为 57.2%,优于以往开源模型,接近 o1-mini 水平。开源的蒸馏模型包括基于 Qwen2.5 和 Llama3 的 1.5B、7B、8B、14B、32B 和 70B 六个版本。
-
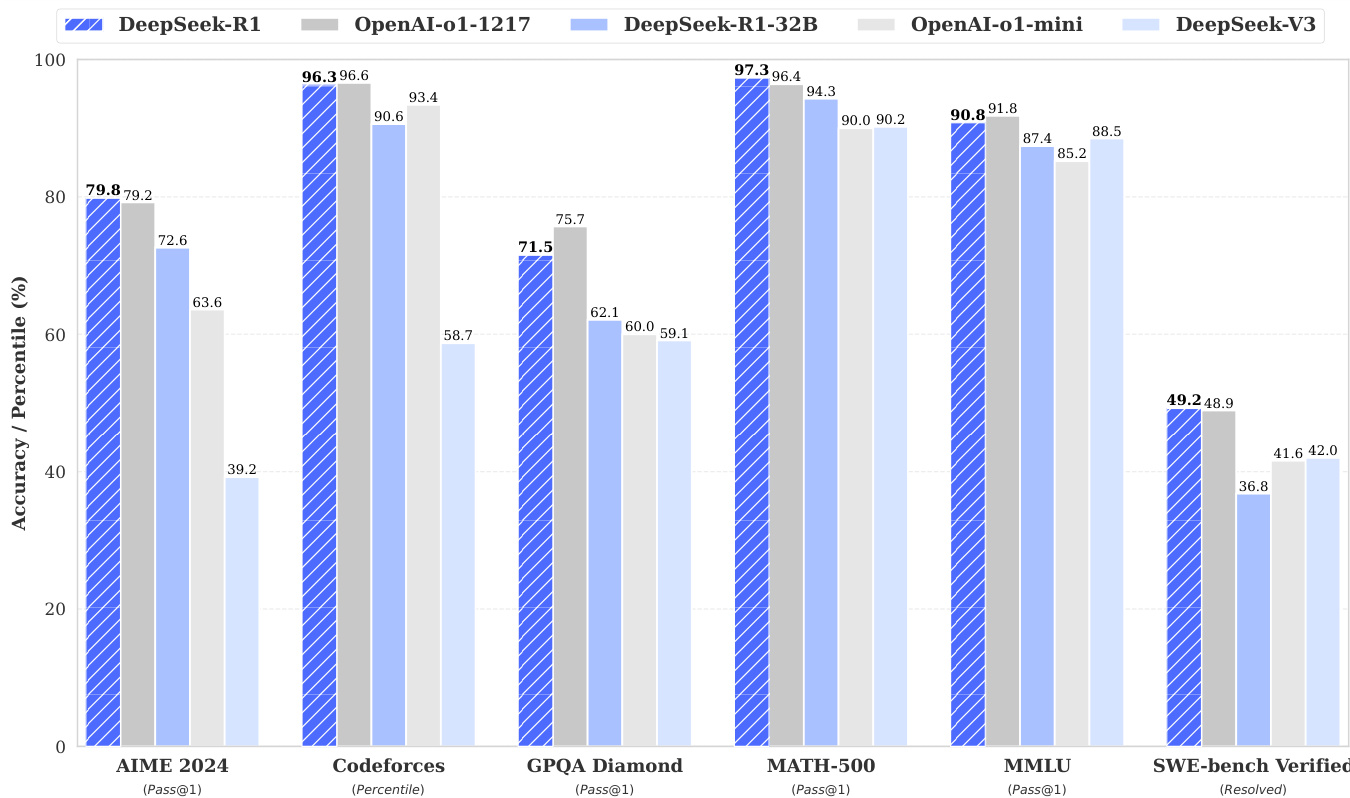
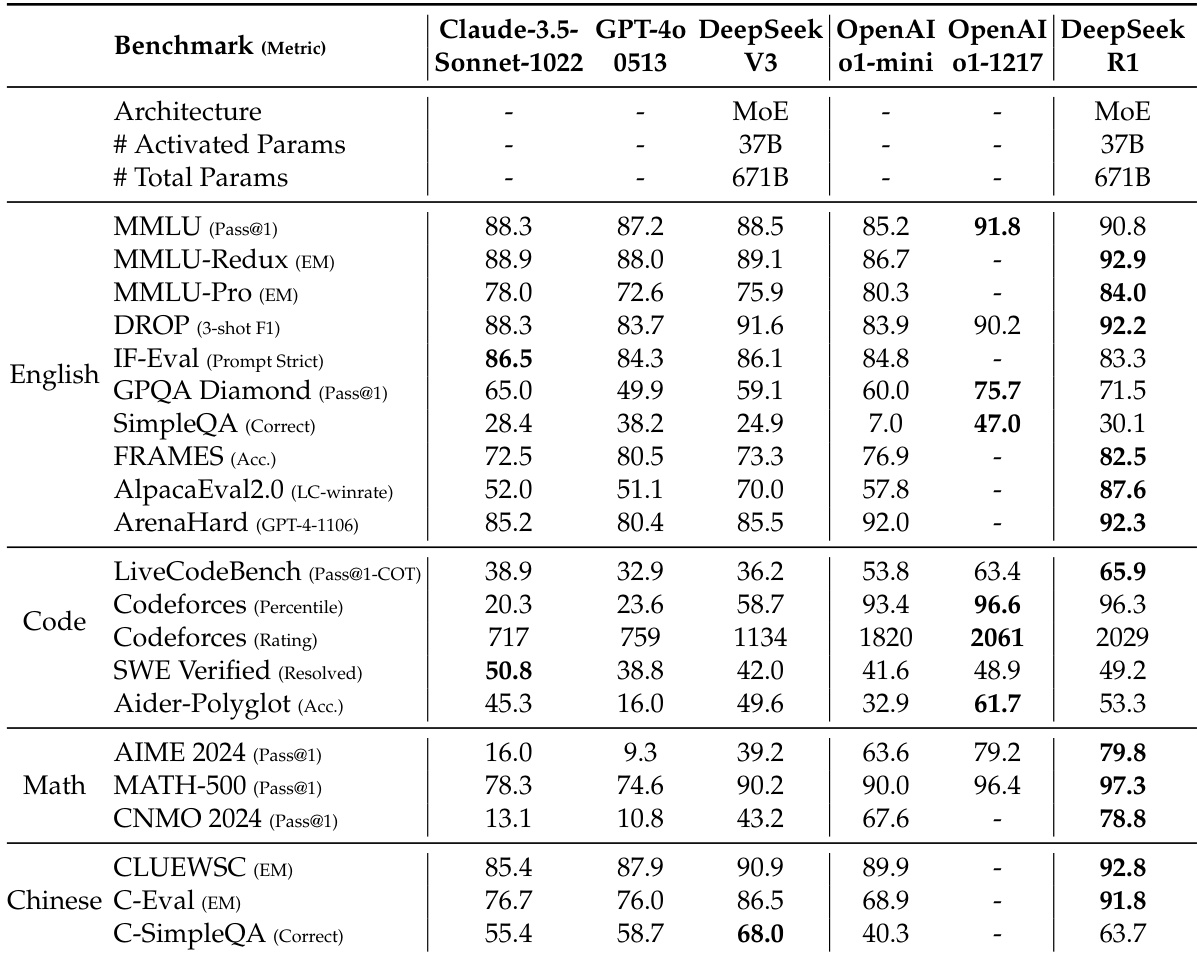
DeepSeek-R1 在 AIME 2024 上实现 79.8% 的 Pass@1 分数,略高于 OpenAI-o1-1217,在 MATH-500 上达到 97.3%,与 o1-1217 相当。在编程任务中,其 Codeforces Elo 评分为 2,029,超过 96.3% 的人类参赛者。在知识基准测试中表现优异:MMLU 为 90.8%,MMLU-Pro 为 84.0%,GPQA Diamond 为 71.5%,显著优于 DeepSeek-V3。在 AlpacaEval 2.0 上实现 87.6% 的长度控制胜率,在 ArenaHard 上达到 92.3%,展现出在创造性、事实性和长上下文任务中的强大泛化能力。
-
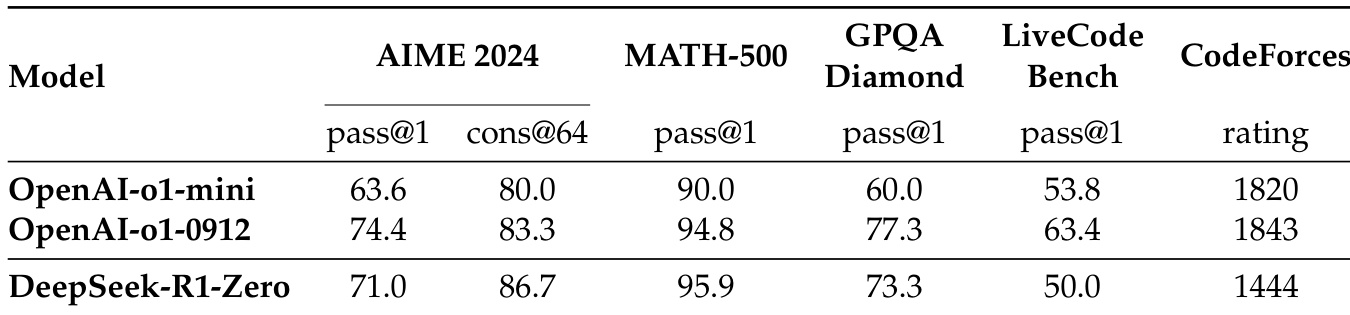
DeepSeek-R1-Zero 通过无监督微调的强化学习训练,AIME 2024 分数从 15.6% 提升至 71.0%,达到与 OpenAI-o1-0912 相当的水平。通过多数投票,其得分达到 86.7%,超过 o1-0912。模型通过增加推理时计算量,自主发展出反思和探索替代方法等高级推理行为。观察到“顿悟时刻”——模型重新评估初始方法,展现出通过强化学习涌现的智能。
-
监督微调(SFT)通过拒绝采样和生成式奖励模型引入 60 万条推理样本,以及来自 DeepSeek-V3 流程的 20 万条非推理样本,对最终模型进行 80 万条精选样本的微调,显著提升指令遵循能力和整体性能。
-
蒸馏在小型模型上优于直接强化学习:DeepSeek-R1-Distill-Qwen-32B 显著超越 DeepSeek-R1-Zero-Qwen-32B(经 10K 步强化学习训练),表明蒸馏比大规模强化学习在小型模型上更高效、更有效,尽管大规模强化学习仍是推动智能边界的关键。
实验结果表明,DeepSeek-R1-Zero 在 AIME 2024 上实现 71.0% 的 pass@1 分数和 86.7% 的 cons@64 分数,优于 OpenAI-o1-mini,接近 OpenAI-o1-0912 水平。在 MATH-500 上,DeepSeek-R1-Zero 的 pass@1 得分为 95.9%,超越两个 OpenAI 模型,在 GPQA Diamond 上实现 73.3% 的 pass@1,Codeforces 得分为 1444,表明其具备强大的推理与编程能力。
研究者使用表格比较 DeepSeek-R1 与其他模型在多个基准测试中的表现。结果表明,DeepSeek-R1 达到顶级性能,在 AIME 2024 上得分为 79.8%,MATH-500 上为 97.3%,优于 OpenAI-o1-1217 和 DeepSeek-V3。在 MMLU 上得分为 90.8%,Codeforces 上达到 90.8 百分位,展现出强大的推理与编程能力。
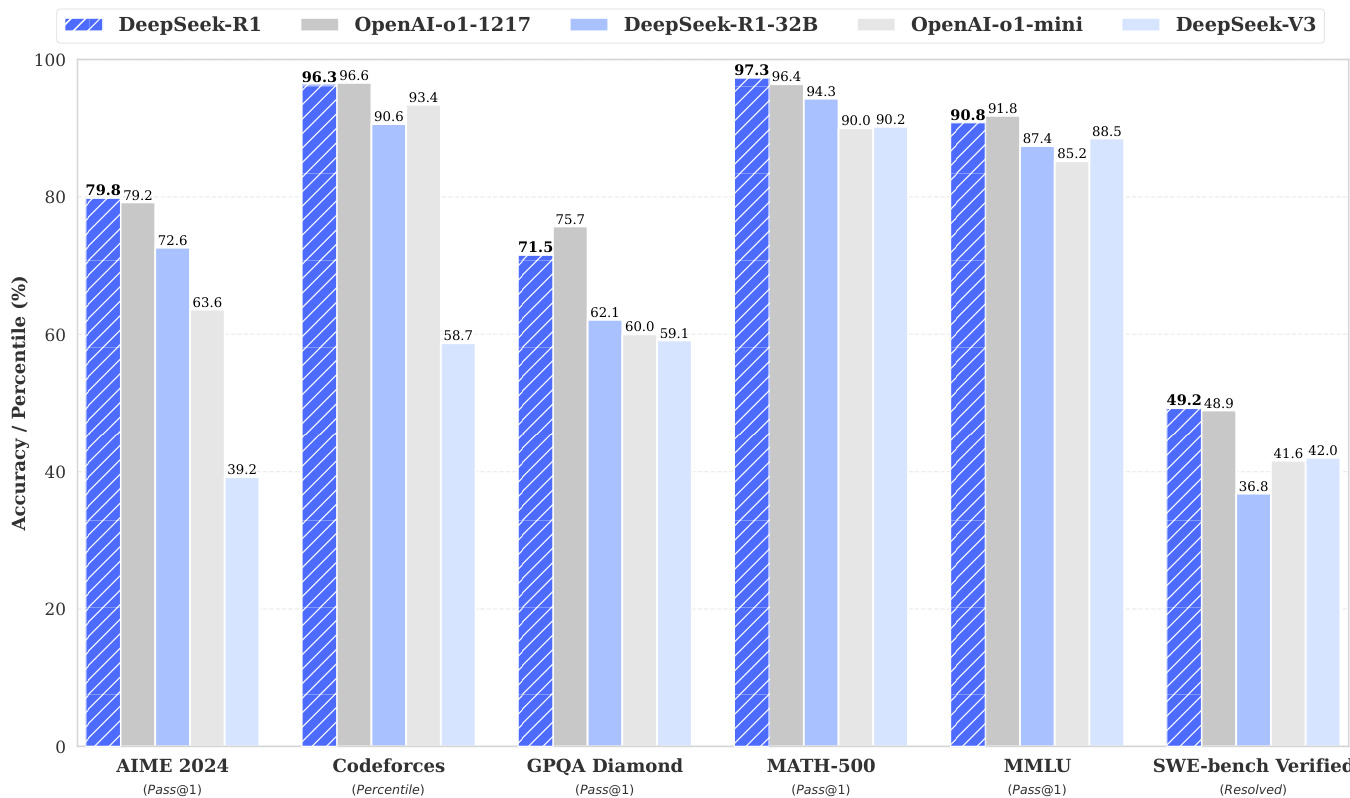
研究者使用表格比较 DeepSeek-R1 与多个强基线模型在多个基准测试中的表现。结果表明,DeepSeek-R1 在大多数任务上达到最先进水平,尤其在数学和编程基准测试中表现突出,超越 GPT-4o 和 OpenAI-o1-mini 等模型。其在知识与推理任务中也表现出色,优于 DeepSeek-V3,并在关键指标上达到或超过 OpenAI-o1-1217 水平。
研究者比较蒸馏模型与强化学习训练模型在推理基准测试中的表现,结果显示 DeepSeek-R1-Distill-Qwen-32B 在所有评估任务中均优于 DeepSeek-R1-Zero-Qwen-32B 和 QwQ-32B-Preview。结果表明,从强大模型中蒸馏知识,性能优于在小型基底模型上进行大规模强化学习训练,凸显知识迁移的有效性。

研究者使用表格比较基于 DeepSeek-R1 的蒸馏模型与多个强基线模型在多个基准测试中的表现。结果表明,DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 上得分为 72.6%,MATH-500 上为 94.3%,优于 OpenAI-o1-mini 和 QwQ-32B-Preview,同时 Codeforces 评分为 1691,超越大多数其他模型。