Command Palette
Search for a command to run...
UI-TARS:开创基于 Native Agent 的自动化 GUI 交互研究
UI-TARS:开创基于 Native Agent 的自动化 GUI 交互研究
摘要
本文介绍了 UI-TARS,这是一种原生 GUI agent 模型,它仅将截图作为输入,并能执行类人交互(如键盘和鼠标操作)。与目前依赖于经过专家精心设计的 prompt 和工作流、且高度封装商业模型(如 GPT-4o)的主流 agent 框架不同,UI-TARS 是一种端到端(end-to-end)模型,其表现优于这些复杂的框架。实验证明了其卓越的性能:UI-TARS 在 10 多个评估感知(perception)、定位(grounding)及 GUI 任务执行能力的 GUI agent benchmark 中均达到了 SOTA 性能。值得注意的是,在 OSWorld benchmark 中,UI-TARS 在 50 步操作下取得了 24.6 分,在 15 步操作下取得了 22.7 分,分别超过了 Claude 的 22.0 分和 14.9 分。在 AndroidWorld 中,UI-TARS 取得了 46.6 分,超越了 GPT-4o 的 34.5 分。
一句话总结
作者提出了 UI-TARS,这是一种端到端的原生 GUI Agent,通过直接感知截图来执行类人的键盘和鼠标操作。该模型在包括 OSWorld(表现优于 Claude)和 AndroidWorld(表现优于 GPT-4o)在内的十多个基准测试中实现了最先进的性能。
核心贡献
- 本文介绍了 UI-TARS,这是一种原生 GUI Agent 模型,通过直接感知截图来执行类人的键盘和鼠标交互,作为一个端到端系统运行。
- 该模型结合了多项创新的技术,包括增强感知、统一动作建模、System-2 推理,以及通过使用在线轨迹(online traces)进行迭代优化。
- 实验结果表明,该模型在超过 10 个 GUI Agent 基准测试中达到了最先进的性能,特别是在 OSWorld 和 AndroidWorld 数据集上优于 Claude 和 GPT-4o。
引言
自动化图形用户界面 (GUI) 交互对于简化复杂的数字工作流和提高生产力至关重要。虽然现有的 Agent 框架依赖于模块化设计和专家编写的提示词来封装 GPT-4o 等商业模型,但这些系统通常较为脆弱,难以维护,且缺乏从新经验中学习的能力。作者引入了 UI-TARS,这是一种端到端的原生 Agent 模型,能够直接感知截图并执行类人交互,无需手动进行工作流工程。为了实现这一目标,作者利用增强的视觉感知、统一的动作建模空间和 System-2 推理来支持深思熟虑的多步决策。此外,通过使用反思性在线轨迹实现迭代训练过程,使模型能够从错误中不断学习。
数据集
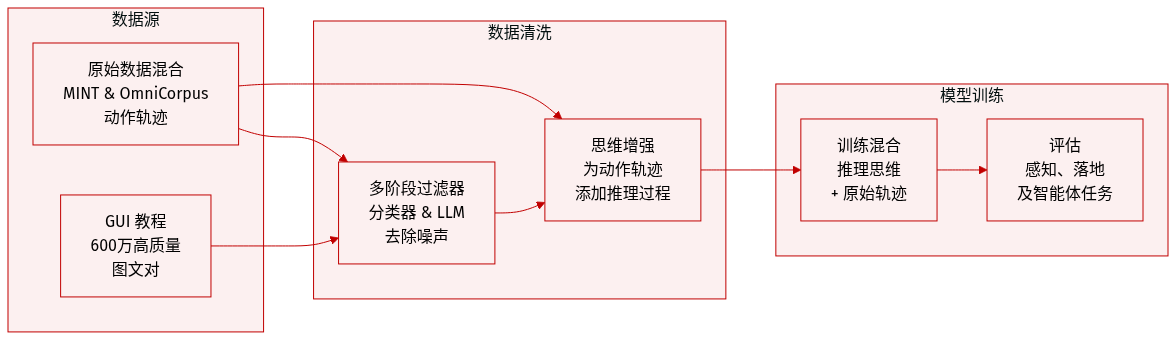
作者开发了一个多维数据集,旨在增强 GUI Agent 的感知、落地(grounding)和推理能力。数据集的构成和处理过程总结如下:
-
数据集构成与来源
- GUI 教程: 从 MINT 和 OmniCorpus 图像-文本交错数据集中策划了约 6M 高质量教程。平均每个教程包含 3.3 张图像和 510 个文本 token。
- 动作轨迹: 数据集包括以动作为核心的轨迹,由观察和动作序列组成。
-
数据处理与过滤
- 多阶段教程过滤: 为了从噪声源中提取高质量的 GUI 教程,作者采用了三步流水线:
- 粗粒度过滤: 使用在人工策划的教程和随机样本上训练的 fastText 分类器进行初步筛选。
- 细粒度过滤: 使用 LLM 移除误报,以确保样本严格符合 GUI 教程特征。
- 去重与精炼: 使用基于 URL 和局部敏感哈希 (LSH) 的方法去除重复项,随后使用基于 LLM 的改写来消除低质量或无关文本。
- 思维增强: 为了超越简单的动作跟随,通过在观察和动作之间标注“思维” (t),将动作轨迹转换为推理增强序列。
- 多阶段教程过滤: 为了从噪声源中提取高质量的 GUI 教程,作者采用了三步流水线:
-
推理构建策略
- ActRe(迭代标注): VLM 通过查看前文语境和目标动作为每一步生成思维。这一过程鼓励特定的推理模式,包括任务分解、长期一致性、里程碑识别、试错和反思。
- 思维引导(Thought Bootstrapping): 为了防止模型仅仅是为预定动作寻找理由,作者采用了引导方法。通过采样多个“思维-动作”对,仅选择在因果上导向正确 ground-truth 动作的思维。
-
模型使用与训练细节
- 语言多样性: 推理思维以中文和英文两种方式进行标注。
- 训练混合: 虽然作者通过推理思维增强了所有轨迹以激发 System-2 推理,但在训练过程中也包含了原始动作轨迹(仅包含观察和动作的序列)。
方法
作者提出了 UI-TARS,这是一种旨在无需手动规则或级联模块即可运行的原生 GUI Agent 模型。UI-TARS 不依赖于独立的感知和动作模块,而是直接感知截图,应用推理并自主生成动作。
如框架图所示:
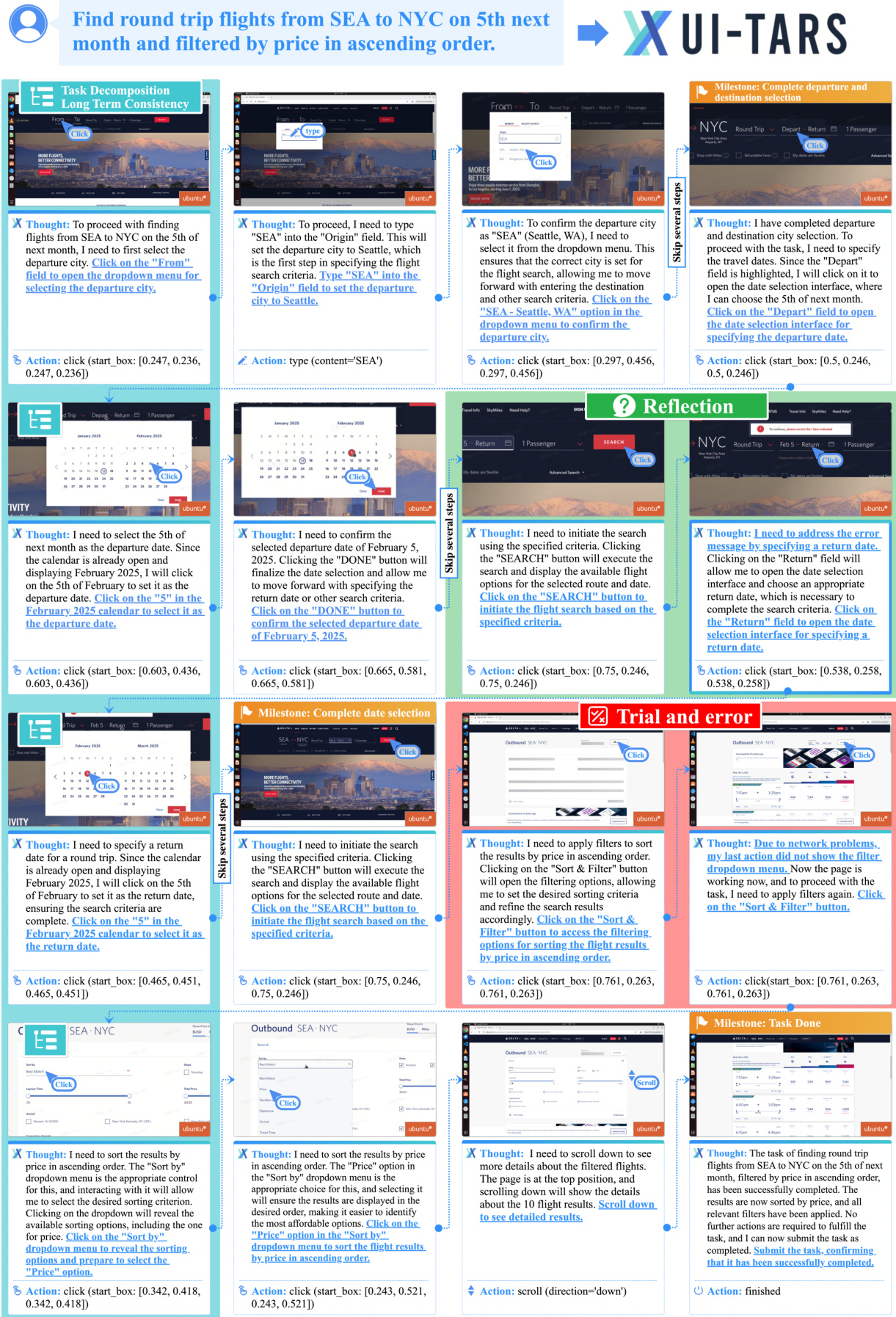
整体架构遵循一个迭代过程:给定初始任务指令,Agent 从设备接收观察结果并执行相应的动作。这一序列过程可以正式表示为:
(instruction,(o1,a1),(o2,a2),…,(on,an))
其中 oi 表示时间步 i 的观察结果(设备截图),ai 表示 Agent 执行的动作。为了增强推理,作者以在每个动作 ai 之前生成的思维 ti 的形式集成了“System 2”推理组件。这些思维作为中间步骤,引导 Agent 进行结构化的、目标导向的深思熟虑。形式化的过程变为:
(instruction,(o1,t1,a1),(o2,t2,a2),…,(on,tn,an))
为了在 token 限制内保持效率,模型将其输入限制在最后 N 个观察结果,同时保留完整的动作和思维历史作为短期记忆。模型按如下方式迭代预测思维和动作:
P(tn,an∣instruction,t1,a1,…,(on−i,tn−i,an−i)i=1N,on)
为了改进 GUI 感知,作者采用了自底向上的数据构建方法。策划了五种核心任务类型来训练模型,如下方数据示例所示:
这些任务包括:元素描述(Element Description),模型学习描述元素类型、视觉外观、位置和功能;密集描述(Dense Captioning)以捕捉整个界面布局;状态转换描述(State Transition Captioning)以识别截图之间细微的视觉变化;问答(QA)用于关系推理;以及标记集(Set-of-Mark, SoM)以增强视觉标记与元素之间的关联。
该模型还通过长期记忆引入了从先前经验中学习的机制。这是通过在线轨迹引导(Online Trace Bootstrapping)实现的,即 Agent 在虚拟环境中执行指令以产生原始轨迹。这些轨迹经过多级过滤(包括基于规则的奖励、VLM 评分和人工审核),以产生用于自我改进的高质量数据。
为了解决 Agent 陷入错误循环的问题,作者引入了反思微调(Reflection Tuning)。该协议使模型接触到现实世界的错误及其随后的修正。通过在错误修正轨迹对上进行训练,模型学习如何识别错误并重新调整进度。此外,作者采用直接偏好优化 (DPO),通过对修正动作相对于错误动作的偏好进行编码,显式引导 Agent 远离次优动作。
训练过程采用基于 Qwen-2-VL 主干的三阶段方法:
- 持续预训练:模型学习基础的 GUI 交互知识,包括感知和动作轨迹。
- 退火阶段:使用高质量的数据子集来优化决策策略,从而得到 UI-TARS-SFT 模型。
- DPO 阶段:模型使用标注的反思对进行 DPO 训练以强化最优动作,最终得到 UI-TARS-DPO 模型。
实验
实验通过离线基准测试和动态在线模拟,从感知、落地和 Agent 能力三个关键维度评估了 UI-TARS 模型。结果表明,UI-TARS 达到了最先进的性能,特别是在 Web、移动端和桌面环境中的推理密集型和多步任务方面表现出色。此外,研究验证了扩大模型规模和采用 System-2 推理可以显著增强 Agent 泛化到复杂的、领域外场景的能力。
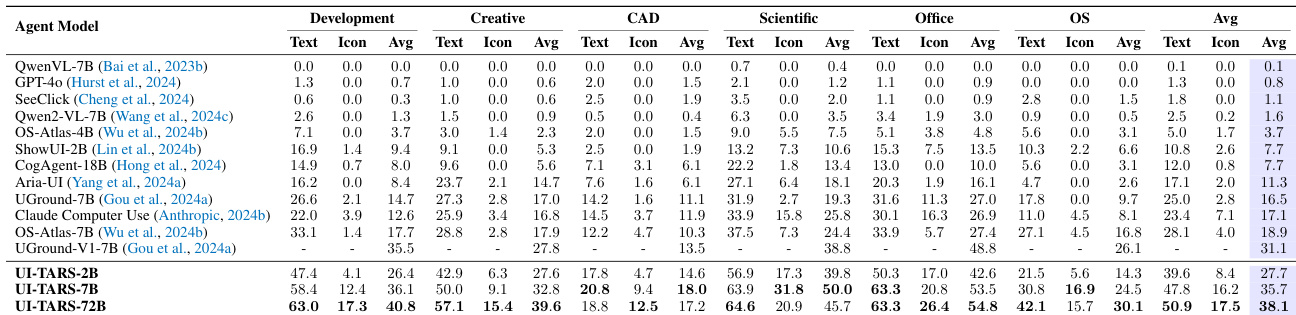
作者在多个专业领域评估了 UI-TARS 模型变体的性能,包括创意、CAD、科学、办公和 OS 任务。结果显示,与现有基准相比,UI-TARS 模型(特别是较大的 72B 版本)在大多数类别中始终获得更高的平均分。UI-TARS-72B 在 OS 和科学领域的表现优于以往模型。模型变体在办公和 CAD 任务中表现出强大的能力,优于已有的基准。将模型规模从 2B 扩大到 72B 使得所有评估类别的平均性能显著提升。
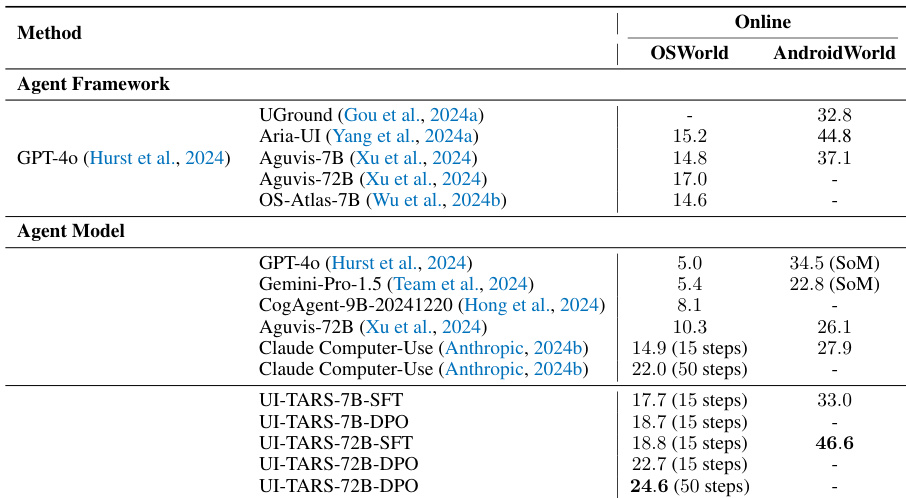
作者在在线动态环境中,将 UI-TARS Agent 模型与各种 Agent 框架及商业模型进行了对比。在 OSWorld 和 AndroidWorld 基准测试中的结果显示,UI-TARS 模型通常比现有基准获得更高的分数。与已有的 Agent 框架和商业模型相比,UI-TARS 模型在推理密集型的在线任务中表现出更优越的性能。UI-TARS 的 72B 变体在桌面和移动环境中的得分均高于以往的最先进方法。对 UI-TARS 模型应用直接偏好优化 (DPO) 可以在在线基准设置中获得更好的结果。
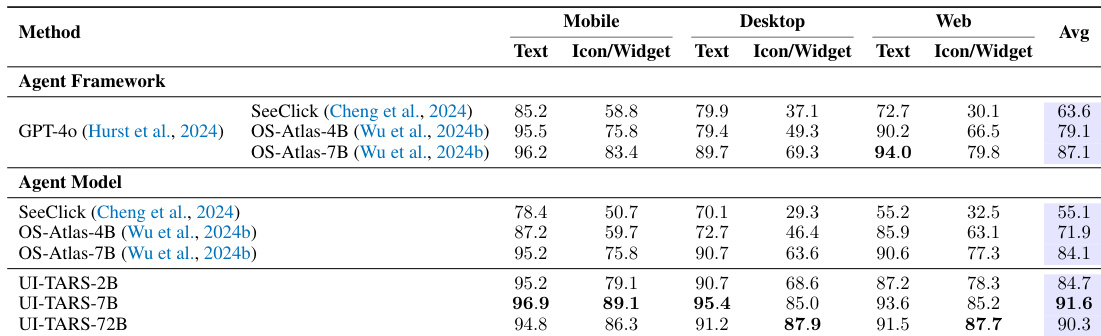
该表通过基于文本和基于图标/组件的方法,比较了各种 Agent 框架和 Agent 模型在移动端、桌面端和 Web 平台上的表现。结果显示,与列出的 Agent 框架和其他 Agent 模型相比,UI-TARS Agent 模型通常获得更高的平均性能。在所有三个平台上,UI-TARS 模型在基于图标和组件的任务中表现优于基准框架。较大的 UI-TARS 模型变体在所有对比方法中获得了最高的整体平均性能。与 OS-Atlas 等以往的 Agent 模型相比,UI-TARS 模型在图标和组件的识别及交互能力方面表现出显著提升。
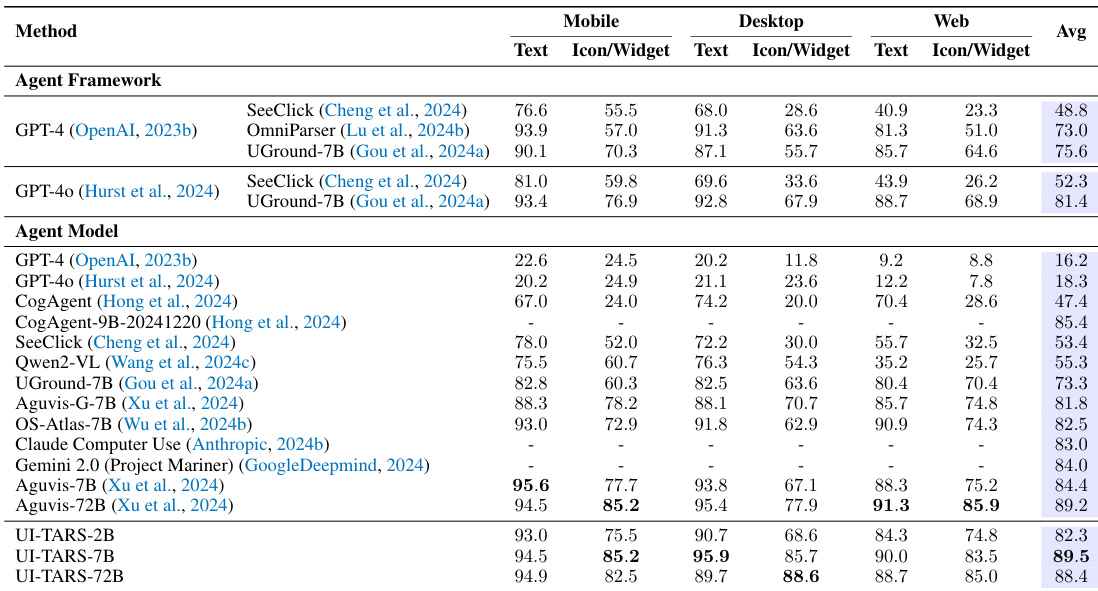
该表比较了各种 Agent 框架和 Agent 模型在移动端、桌面端和 Web 平台上的表现。结果显示,与现有框架和模型相比,UI-TARS 模型(特别是较大的变体)在大多数类别中都取得了优越的性能。UI-TARS-72B 模型在所有评估方法中获得了最高的平均性能。UI-TARS 模型在移动端、桌面端和 Web 环境中展现出强大的能力,通常优于商业和学术基准。在许多类别中,UI-TARS-72B 模型相对于模块化 Agent 框架和端到端 Agent 模型都有显著改进。
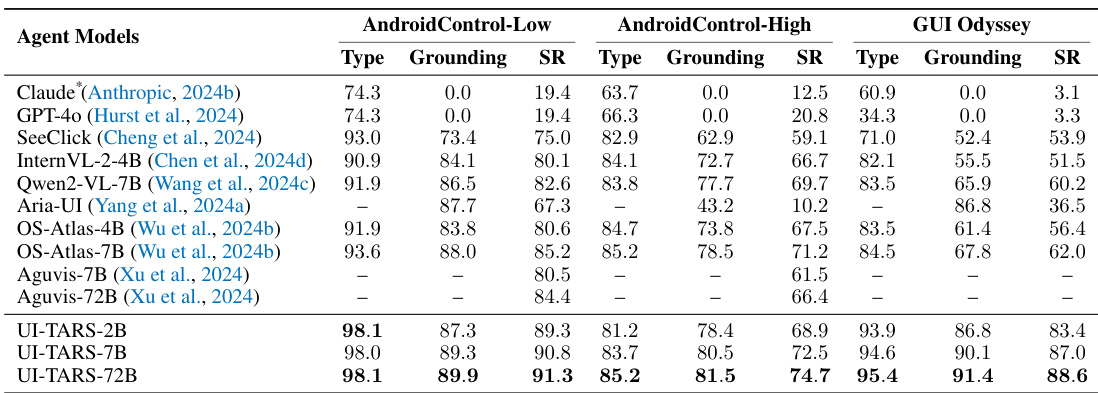
作者在包括 AndroidControl 和 GUI Odyssey 在内的移动端基准测试中评估了多个 Agent 模型。结果显示,与现有基准相比,UI-TARS 模型在落地和成功率方面始终获得更高的性能。UI-TARS-72B 在低复杂度和高复杂度的 AndroidControl 任务中均取得了优越的性能。与以往的最先进方法相比,UI-TARS 模型在 GUI Odyssey 中展现了改进的落地和成功率。从 2B 变体扩展到 72B 变体带来了任务执行和落地精度方面的可衡量改进。
作者在不同的专业领域、动态在线环境以及包括移动端、桌面端和 Web 在内的多个平台中评估了 UI-TARS 模型变体。实验验证了模型执行复杂推理和基于图标交互的能力,证明了从 2B 扩展到 72B 可以显著增强任务执行和落地精度。最终,UI-TARS 模型(特别是 72B 版本)在各种基准测试中始终优于现有的 Agent 框架和商业模型。