Command Palette
Search for a command to run...
Hunyuan3D 2.0:面向高分辨率纹理3D资产生成的扩散模型扩展
Hunyuan3D 2.0:面向高分辨率纹理3D资产生成的扩散模型扩展
摘要
我们提出 Hunyuan3D 2.0,这是一个先进的大规模三维合成系统,用于生成高分辨率带纹理的三维资产。该系统包含两个基础组件:大规模形状生成模型——Hunyuan3D-DiT,以及大规模纹理合成模型——Hunyuan3D-Paint。其中,基于可扩展流式扩散Transformer架构的形状生成模型,旨在生成与给定条件图像精准对齐的几何结构,为下游应用奠定坚实基础。纹理合成模型则得益于强大的几何先验与扩散先验,能够为自动生成或手工制作的网格生成高分辨率、色彩鲜活的纹理贴图。此外,我们构建了 Hunyuan3D-Studio——一个功能多样、操作友好的生产级平台,显著简化了三维资产的重制流程,使专业用户与普通用户均可高效地对网格进行编辑甚至动画制作。我们对模型进行了系统性评估,结果表明,Hunyuan3D 2.0 在几何细节、条件对齐、纹理质量等多个方面均优于此前的最先进模型,涵盖开源与闭源模型。为填补开源三维社区在大规模基础生成模型方面的空白,Hunyuan3D 2.0 已面向公众发布。相关代码及预训练权重已开源,地址为:https://github.com/Tencent/Hunyuan3D-2
一句话总结
Hunyuan3D 团队推出 Hunyuan3D 2.0,这是一个大规模 3D 合成系统,包含基于流模型的扩散 Transformer Hunyuan3D-DiT,用于通过条件对齐生成形状,以及用于高保真纹理合成的 Hunyuan3D-Paint,结合 Hunyuan3D-Studio 实现高质量、用户友好的 3D 资产创建与动画,现已开源,旨在推动 3D 生成建模社区的发展。
主要贡献
-
Hunyuan3D 2.0 通过引入可扩展的两阶段流程,解决了高成本、高专业门槛的 3D 资产创建难题,该流程将形状生成与纹理生成解耦,能够从条件图像或草图高效且高保真地合成细节丰富的 3D 资产。
-
该系统引入了 Hunyuan3D-DiT,一个基于向量集表示的大型流模型扩散 Transformer,其通过专用 VAE 对 3D 形状进行建模;以及 Hunyuan3D-Paint,一种基于网格条件的多视角扩散模型,能够生成高分辨率、多视角一致的纹理图,并具备强几何先验。
-
在多个基准测试和 50 名参与者的用户研究中进行的广泛评估表明,Hunyuan3D 2.0 在几何细节、条件对齐、纹理质量及用户偏好方面均优于当前最先进的开源与闭源模型,完整代码与预训练模型已公开发布。
引言
数字 3D 资产创建在游戏、影视和具身人工智能等行业中至关重要,但由于涉及建模、贴图和仿真等复杂流程,仍高度依赖人力与专业知识。尽管扩散模型在图像与视频生成方面取得了快速进展,3D 生成仍相对滞后,主要受限于缺乏可扩展的开源基础模型以及 3D 几何表示的固有挑战。以往方法要么依赖小规模模型且泛化能力有限,要么在多视角一致性与几何对齐方面表现不佳,尤其在纹理合成中尤为明显。本文提出 Hunyuan3D 2.0,一个两阶段开源系统,包含 Hunyuan3D-DiT——一种基于向量集表示的大型流模型扩散模型,实现高效高保真的形状生成;以及 Hunyuan3D-Paint——一种基于网格条件的多视角扩散模型,采用新颖的多任务注意力机制,确保高分辨率、细节保留的纹理合成并强对齐输入图像。本工作通过支持大规模 3D 数据集与灵活架构,实现了端到端、高质量的 3D 资产生成,具备强语义与几何保真度,适用于生成与手工制作的网格。
方法
Hunyuan3D 2.0 系统围绕两个核心基础模型构建:形状生成模型 Hunyuan3D-DiT 与纹理合成模型 Hunyuan3D-Paint,二者共同构成从单张输入图像生成高分辨率纹理 3D 资产的流程。整体框架如图所示,首先由形状生成模型生成裸网格,随后纹理合成模型处理该网格以生成高保真纹理图,再将其烘焙至几何体上。系统还由 Hunyuan3D-Studio 支持,这是一个生产级平台,提供下游应用工具,如低多边形风格化与角色动画。

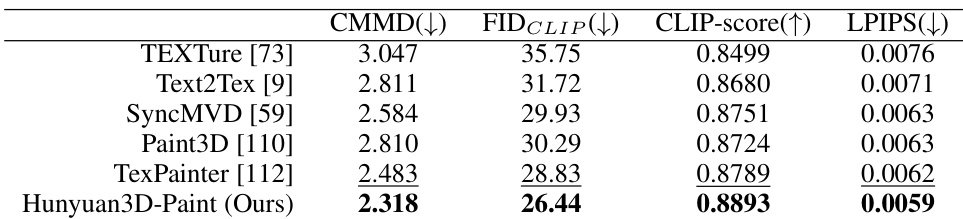
形状生成模型 Hunyuan3D-DiT 基于潜在扩散框架,包含两个关键组件:Hunyuan3D-ShapeVAE 与扩散 Transformer 本身。ShapeVAE 作为压缩器,将 3D 多边形网格转换为连续潜在标记序列。该过程从输入网格开始,提取均匀采样与重要性采样的点云。重要性采样策略聚焦于捕捉高频细节(如边缘与角点),通过在这些复杂区域集中采样实现。这些点云随后通过基于 Transformer 的架构编码为潜在标记,该架构采用交叉注意力与自注意力层。编码器输出为潜在形状嵌入,由变分解码器解码以重建 3D 形状为有符号距离函数(SDF)。该 SDF 再通过 Marching Cubes 算法转换为三角网格。ShapeVAE 的训练由重建损失(衡量预测与真实 SDF 之间的均方误差)与 KL 散度损失联合监督,以确保潜在空间紧凑且连续。
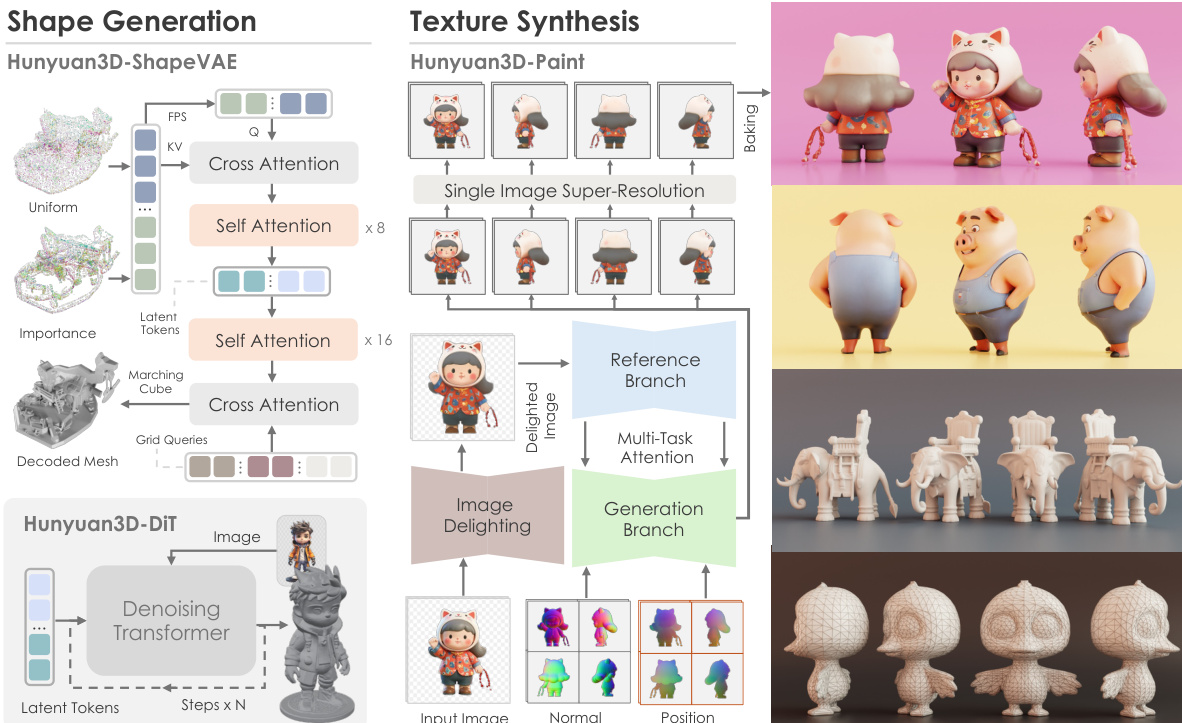
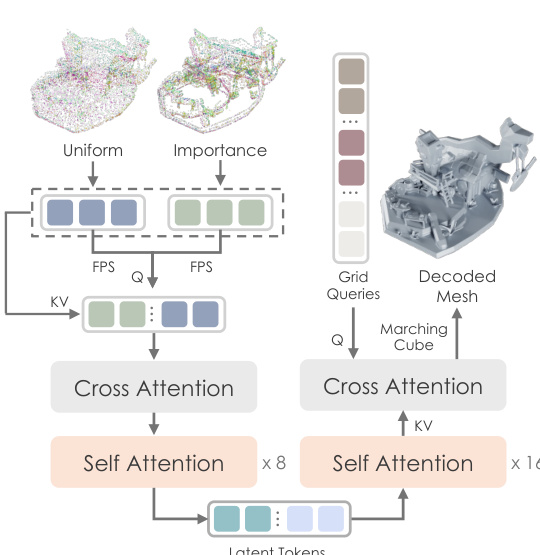
Hunyuan3D-DiT 模型在 ShapeVAE 定义的潜在空间上运行,是一种基于流的扩散 Transformer,用于根据输入图像生成高保真 3D 形状。其架构如图所示,采用双流与单流网络结构。双流模块分别处理潜在标记(代表 3D 形状)与条件标记(代表输入图像),并通过注意力机制实现交互。单流模块并行处理拼接后的潜在与条件标记,使用空间与通道注意力。模型由预训练图像编码器 DINOv2 条件化,从输入图像提取高分辨率图像标记。为确保模型聚焦于目标物体,输入图像经过背景去除、缩放与居中预处理。训练目标基于流匹配,模型学习预测引导样本从高斯分布到数据分布的速度场。推理阶段,模型使用一阶欧拉 ODE 求解器生成最终形状。
纹理合成模型 Hunyuan3D-Paint 是一种多视角图像生成框架,为给定 3D 网格生成高分辨率、自一致的纹理图。该过程分为三个阶段:预处理、多视角图像合成与纹理烘焙。预处理阶段包含图像去光模块,将输入图像转换为无光照状态,消除光照与阴影,确保纹理图与光照无关。采用几何感知的视角选择策略,确定推理时最优视角数量,以高效覆盖网格表面。模型核心为多视角图像合成阶段,采用扩散模型从多个视角生成图像。该模型使用双流图像条件参考网络,忠实捕捉输入图像细节,固定权重参考分支以防止风格漂移。为确保所有生成视角的一致性,采用多任务注意力机制,平行集成参考注意力模块与多视角注意力模块。模型还基于网格几何条件化,使用规范法线与位置图,并通过可学习相机嵌入提供视角信息。训练与推理流程如图所示,涉及密集视角推理,训练中使用视角丢弃策略以增强模型的 3D 感知能力。生成多视角图像后,应用单图像超分辨率模型提升纹理质量,并使用纹理修复方法填充 UV 图中未覆盖区域。
实验
- Hunyuan3D-ShapeVAE 在 3D 形状重建方面表现卓越,优于基线模型(3DShape2VecSet、Michelangelo、Direct3D)在 V-IoU 与 S-IoU 指标上的表现,实现细粒度细节恢复且无漂浮伪影。
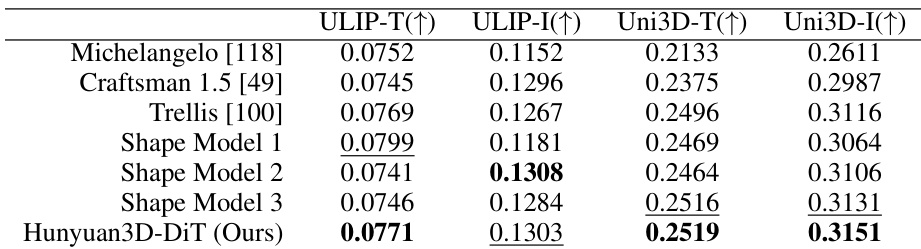
- Hunyuan3D-DiT 生成高保真 3D 形状,具备强条件跟随能力,超越开源(Michelangelo、Craftsman 1.5、Trellis)与闭源基线在 ULIP-T/I 与 Uni3D-T/I 指标上的表现,生成无孔洞、表面特征丰富的网格。
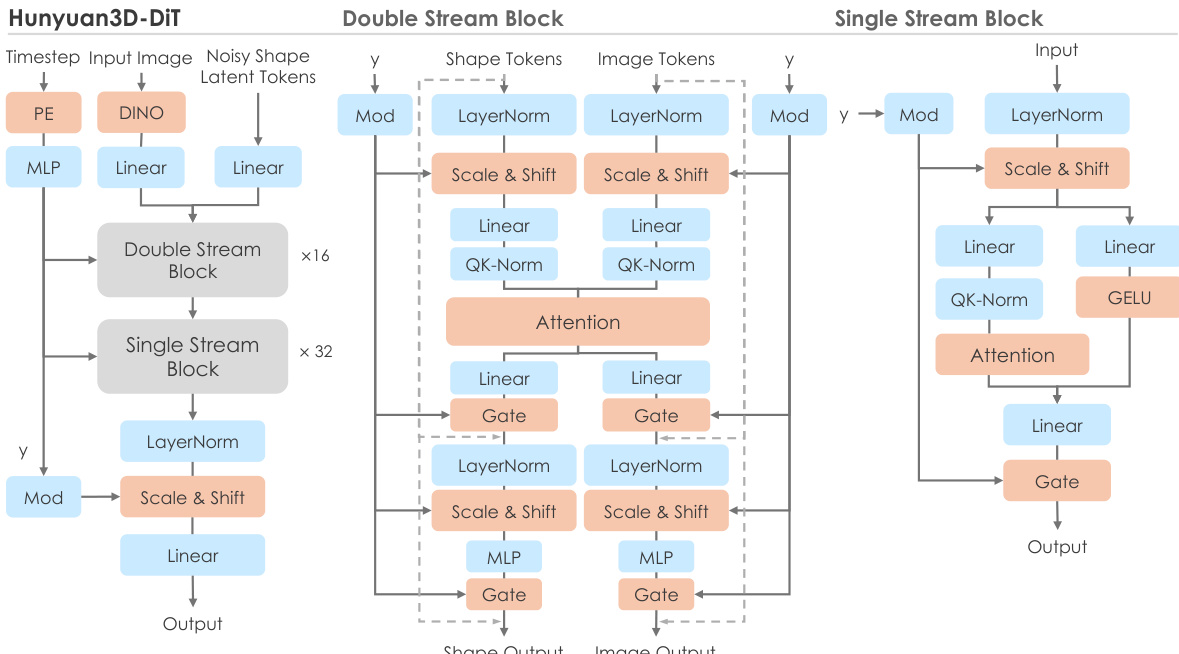
- Hunyuan3D-Paint 生成高质量、条件一致的纹理图,在 FID_CLIP、CMMD、CLIP-score 与 LPIPS 指标上优于 TEXture、Text2Tex、SyncMVD、Paint3D 与 TexPainter,结果无缝、光照不变,细节合成丰富。
- Hunyuan3D 2.0 在端到端纹理 3D 资产生成方面表现优异,优于 Trellis 与闭源模型在 FID_CLIP、CMMD、CLIP-score 与 LPIPS 指标上的表现,生成高分辨率、高保真资产,纹理与表面凹凸映射准确。
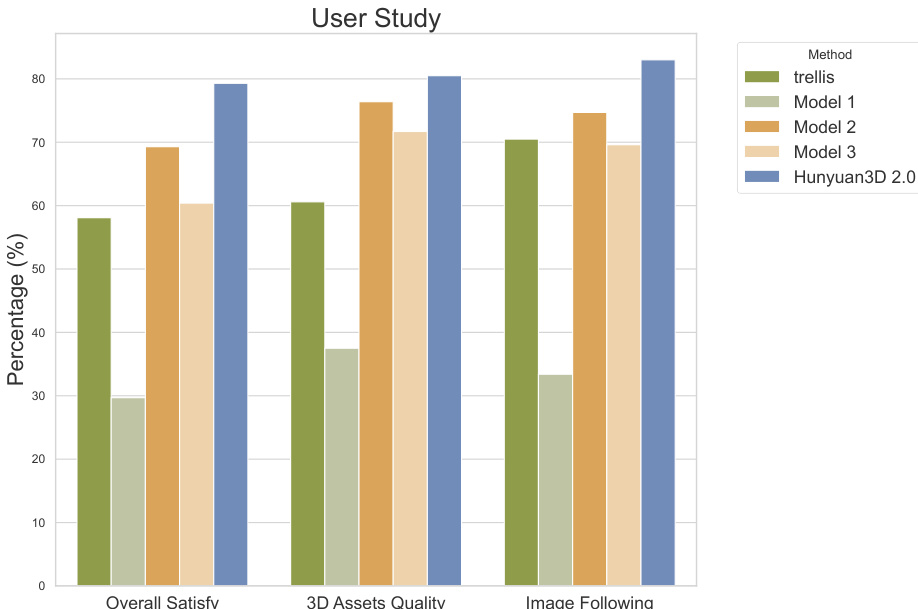
- 50 名参与者的用户研究表明,Hunyuan3D 2.0 在图像条件遵循与整体视觉质量方面表现强劲,主观评价显著优于基线模型。
作者使用 Hunyuan3D 2.0 生成纹理 3D 资产,并与多个基线模型在 CMMD、FIDCLIP、FIDIncept 与 CLIP-score 等指标上进行对比。结果表明,Hunyuan3D 2.0 在所有指标上均优于所有基线,尤其在语义对齐与细节保留方面表现最佳。

作者开展一项包含 50 名志愿者的用户研究,评估 Hunyuan3D 2.0 生成的纹理 3D 资产质量,并与基线模型进行比较。结果表明,Hunyuan3D 2.0 在所有评估标准(包括总体满意度、3D 资产质量与图像跟随)上均取得最高分,显著优于所有对比方法。
作者使用表 1 评估 Hunyuan3D-ShapeVAE 与多个基线模型在体积交并比(V-IoU)与表面交并比(S-IoU)指标上的重建性能。结果表明,Hunyuan3D-ShapeVAE 优于所有对比方法,在 V-IoU 与 S-IoU 上均取得最高分,表明其具有更优的形状重建质量。
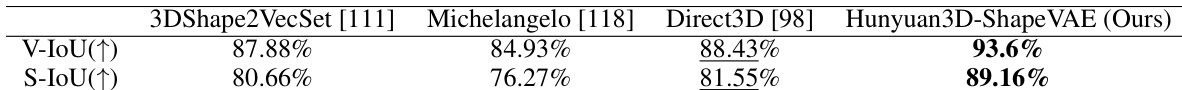
作者使用表 2 评估 Hunyuan3D-DiT 与多个基线模型在 ULIP-T/I 与 Uni3D-T/I 指标上的形状生成性能。结果表明,Hunyuan3D-DiT 在所有指标上均取得最高分,表明其生成结果最符合输入条件。
结果表明,Hunyuan3D-Paint 在多个指标上均优于所有基线,实现最低的 CMMD 与 FIDCLIP 值,以及最高的 CLIP-score 与 LPIPS 值,表明其在纹理图生成中具备更优的生成质量、语义对齐与细节保留能力。