Command Palette
Search for a command to run...
MonSter:将单目深度估计与立体视觉相结合释放强大潜能
MonSter:将单目深度估计与立体视觉相结合释放强大潜能
摘要
我们提出MonSter++,一种用于多视角深度估计的几何基础模型,统一了校正立体匹配与非校正多视角立体视觉任务。这两项任务均通过对应点搜索恢复度量深度,因而面临相同的困境:在匹配线索有限的病态区域难以有效处理。为解决这一问题,我们提出MonSter++,一种创新方法,将单目深度先验融入多视角深度估计中,从而有效结合单视角与多视角线索的互补优势。MonSter++采用双分支架构,融合单目深度与多视角深度信息。基于置信度的引导机制可自适应地选择可靠的多视角线索,用于校正单目深度中的尺度模糊问题;而经过优化的单目预测结果又能有效指导多视角估计在病态区域的推理。这种迭代式的相互增强机制使MonSter++能够将粗粒度的物体级单目先验逐步演化为精细的像素级几何结构,充分释放多视角深度估计的潜力。MonSter++在立体匹配与多视角立体视觉任务上均取得了新的最先进性能。通过我们提出的级联搜索与多尺度深度融合策略,有效整合单目先验信息,其实时版本RT-MonSter++也大幅超越了以往所有实时方法。如图1所示,MonSter++在来自三个任务(立体匹配、实时立体匹配与多视角立体视觉)的八个基准测试中均实现了显著提升,充分展现了该框架的强大泛化能力。除高精度外,MonSter++还展现出卓越的零样本泛化性能。我们计划开源大型模型与实时模型,以促进该技术在开源社区中的广泛应用。
一句话总结
华中科技大学、Meta 和 Autel Robotics 的研究人员提出 MonSter++,一种统一的几何基础模型,用于多视角深度估计。该模型通过双分支架构融合单目深度先验,并采用置信度引导的迭代优化,联合解决尺度模糊性并增强病态区域,从而在立体匹配、多视角立体视觉和实时推理任务中达到最先进性能,适用于自动驾驶和机器人领域。
主要贡献
-
MonSter++ 通过新颖地整合单目深度先验,统一立体匹配与多视角立体视觉,解决了多视角深度估计中的病态区域(如无纹理区域、遮挡和细长结构)这一根本挑战,使传统基于对应关系的方法失效时仍能实现鲁棒的深度恢复。
-
该方法引入双分支架构,包含立体引导对齐(SGA)和单目引导精炼(MGR)模块,通过可靠的多视角线索迭代修正单目深度的尺度与偏移,同时利用精炼后的单目先验自适应引导多视角深度估计,提升病态区域的性能。
-
MonSter++ 在涵盖立体匹配、多视角立体视觉和实时立体任务的八个基准上均达到最先进水平,其中实时版本 RT-MonSter++ 推理时间仅 47 毫秒,优于此前以精度为导向的方法 IGEV++(280 毫秒),并在未见数据集上展现出强大的零样本泛化能力。
引言
研究人员针对准确的多视角深度估计这一关键挑战展开研究——该技术在自动驾驶和机器人等领域至关重要。传统立体匹配与多视角立体方法在无纹理区域、遮挡和细长结构等病态区域中表现不佳,主要由于对应关系不可靠。先前方法尝试通过增强特征表示或引入粗略结构先验来提升鲁棒性,但往往无法解决单目深度估计中的尺度与偏移模糊性,导致与多视角数据融合时效果受限。为此,研究人员提出 MonSter++,一种统一框架,将单目深度先验融入双分支架构,并通过迭代相互精炼实现优化。通过置信度引导的自适应融合机制,结合立体引导对齐(SGA)与单目引导精炼(MGR)模块,MonSter++ 修正单目深度中的尺度与偏移误差,同时利用精炼后的先验指导多视角深度估计在困难区域的推断。这种协同设计使模型能够将粗粒度单目先验逐步演化为精细的像素级几何结构,在立体匹配、多视角立体视觉和实时推理基准上均达到最先进性能。实时版本 RT-MonSter++ 进一步实现了优异的速度-精度权衡,在 KITTI 上相比先前实时方法性能提升高达 20%,同时保持强大的零样本泛化能力。
方法
研究人员提出 MonSter++,一种适用于立体匹配与多视角立体视觉的统一框架,用于精确的度量深度估计。其架构如框架图所示,包含三个主要组件:单目深度估计分支、立体匹配分支和相互精炼模块。两个分支并行运行,生成相对单目深度和立体视差的初始估计,随后通过相互反馈进行迭代精炼。
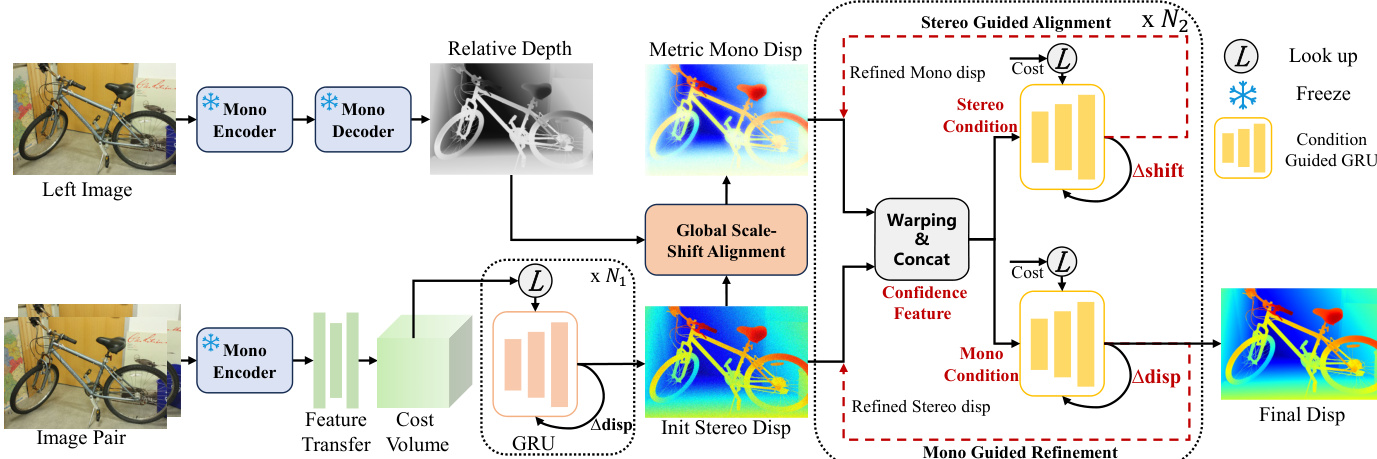
单目深度分支采用预训练模型 DepthAnythingV2,其编码器为 DINOv2,解码器为 DPT。为高效利用该预训练模型,立体匹配分支共享 DINOv2 ViT 编码器,其参数被冻结以保留单目模型的泛化能力。ViT 编码器生成单分辨率特征图,随后通过一个由 2D 卷积层堆叠而成的特征转移网络,生成多尺度特征金字塔 F={F0,F1,F2,F3},其中 Fk∈R25−kH×25−kW×ck。该金字塔用于构建几何编码体,初始立体视差通过与 IGEV 相同的迭代优化过程获得,涉及 ConvGRU,但为效率限制为 N1 次迭代。
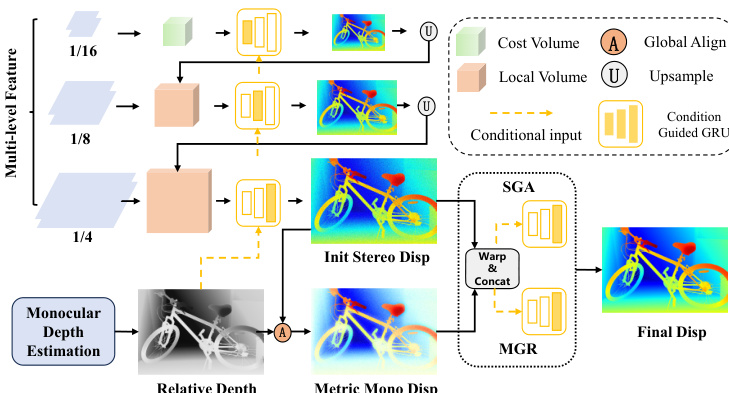
相互精炼模块是框架的核心,旨在迭代优化单目深度与立体视差估计。过程始于全局尺度-偏移对齐,将逆单目深度转换为视差图,并与初始立体视差进行粗略对齐。通过求解最小二乘优化问题,找到全局尺度 sG 和偏移 tG,使对齐后的单目深度与初始立体视差在可靠区域 Ω 上的平方差最小。
对齐后,精炼过程分为两个双分支阶段。第一阶段为立体引导对齐(SGA),利用立体线索精炼单目视差。它从当前立体视差 DSj 计算基于置信度的光流残差图 FSj,并结合几何特征 GSj 与视差本身,形成立体条件 xSj。该条件输入条件引导的 ConvGRU,更新单目分支的隐藏状态,从中解码出残差偏移 Δt 并应用于更新单目视差。
第二阶段为单目引导精炼(MGR),对称地利用对齐后的单目先验精炼立体视差。它为单目与立体分支分别计算光流残差图与几何特征,形成完整的单目条件 xMj。该条件用于更新立体分支 ConvGRU 的隐藏状态,从中解码出残差视差 Δd 并应用于精炼立体视差。该双分支精炼过程重复 N2 次迭代,最终输出立体视差。
在多视角立体任务中,框架结构保持不变,主要区别在于代价体构建方式。与立体匹配中使用的几何编码体不同,此处采用基于方差的代价度量来衡量多个未校正视角间的特征相似性,并将其聚合为相同维度的代价体。后续处理阶段(包括相互精炼)与立体匹配流程完全一致。
实验
- MonSter++ 使用 PyTorch 实现,基于 NVIDIA RTX 4090 GPU 训练,采用 AdamW 优化器,一循环学习率调度(2e-4),批量大小为 8,训练 200k 步。单目分支使用冻结的 ViT-large DepthAnythingV2 模型。采用两阶段训练策略,使用基础训练集(BTS)和扩展全训练集(FTS),包含来自 14 个公开数据集的超过 200 万张图像对。
- 在立体匹配基准上,MonSter++ 达到最先进结果:Scene Flow 上 EPE 为 0.37(比基线 [6] 提升 21.28%,比 SOTA [5] 提升 15.91%),ETH3D 排名第一(RMSE Noc 相比 IGEV 提升 77.68%),Middlebury 排名第一(RMSE Noc 相比 FoundationStereo 提升 6.94%)。在 KITTI 2012 和 2015 上,D1-all 指标分别超越 CREStereo 和 Selective-IGEV 18.93% 和 11.61%;在 Out-2 和 Out-3 指标上,相比 IGEV++ 和 NMRF-Stereo 分别提升 16.26% 和 20.74%。
- 在多视角立体任务中,MonSter++ 在 DDAD 上达到 SOTA(AbsRel 相比 [13] 提升 14.8%),在 KITTI Eigen 分割上分别提升 18.11% 和 21.21%(相比 [15] 和 [13])。
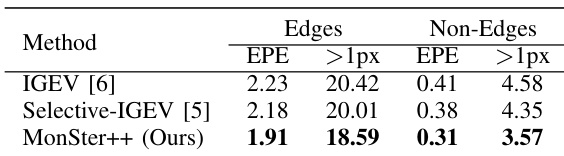
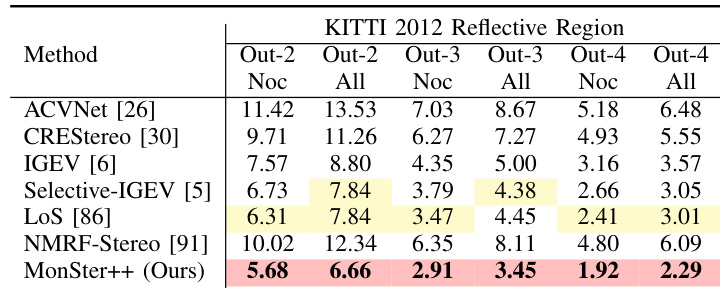
- MonSter++ 在病态区域表现优异:在 KITTI 2012 的反光区域,Out-3 和 Out-4 指标分别比 NMRF-Stereo 提升 57.46% 和 62.40%;在 Scene Flow 的边缘与非边缘区域,分别比基线提升 14.35% 和 24.39%;在 KITTI 2015 的远距离背景区域,D1-bg 指标提升 18.84%。
- 实时版本 RT-MonSter++ 在 1K 分辨率下运行速度超过 20 FPS,KITTI 2012 和 2015 上达到 SOTA 准确率(Out-4 和 Out-5 指标分别比 RT-IGEV++ 提升 19.23% 和 20.75%),并展现出卓越的零样本泛化能力——尤其在 Middlebury(2 像素异常率降低 34.1%)和 ETH3D(相比 RT-IGEV++ 提升 32.0%),推理成本仅为 IGEV 的三分之一。
- MonSter++ 展现出强大的零样本泛化能力:在 Scene Flow 上训练后,KITTI、Middlebury 和 ETH3D 的平均误差从 5.03 降至 3.70(相比 IGEV 提升 26.4%);在 FTS 上训练后,Middlebury 和 ETH3D 分别提升 39.5% 和 60.0%;在 DrivingStereo 上,雨天条件下性能提升 49.3%,平均误差比 FoundationStereo 降低 45.4%。
- 消融实验验证了关键组件的有效性:MGR 融合相比卷积融合使 EPE 提升 6.52%;SGA 精炼使 EPE 提升 9.30%,1 像素误差提升 10.69%;特征共享使 EPE 提升 5.13%;MonSter++ 在使用不同单目模型(如 MiDaS, [66])时仍有效;仅需 4 次推理迭代即可达到 SOTA 准确率,提供更优的精度-速度权衡。
研究人员使用 RT-MonSter++ 模型在 KITTI 2012 和 KITTI 2015 基准上评估实时立体匹配性能,结果在所有实时方法中最佳。结果显示,RT-MonSter++ 显著优于先前最先进实时方法,KITTI 2015 的 D1-fg (Noc) 指标提升高达 21.45%,同时在 1K 分辨率下保持超过 20 FPS 的推理速度。
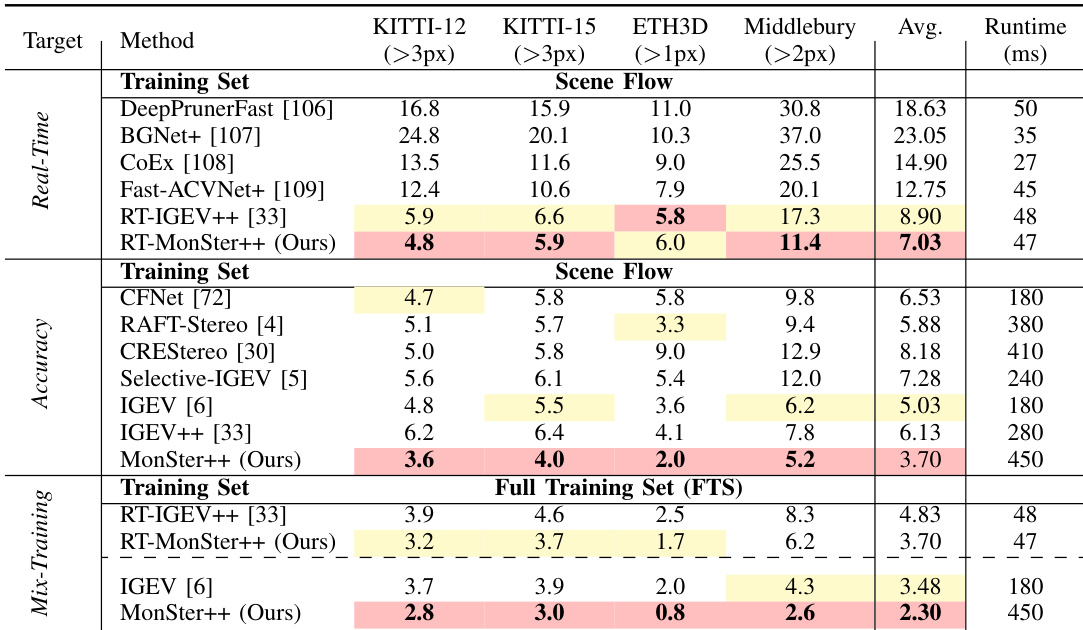
结果表明,MonSter++ 在 Scene Flow 基准上达到最低 EPE 指标 0.37,显著优于所有对比方法,相比前 SOTA 方法提升 15.91%。

研究人员使用 MonSter++ 在多个立体匹配基准上实现最先进性能,方法在 ETH3D、Middlebury、KITTI 2012 和 KITTI 2015 上均排名第一。结果显示,MonSter++ 显著优于现有方法,在 ETH3D 上 Bad1.0 (Noc) 指标提升高达 77.68%,在 KITTI 2015 上 D1-all 指标提升 18.93%,同时在实时应用中展现出强大的泛化能力与效率。
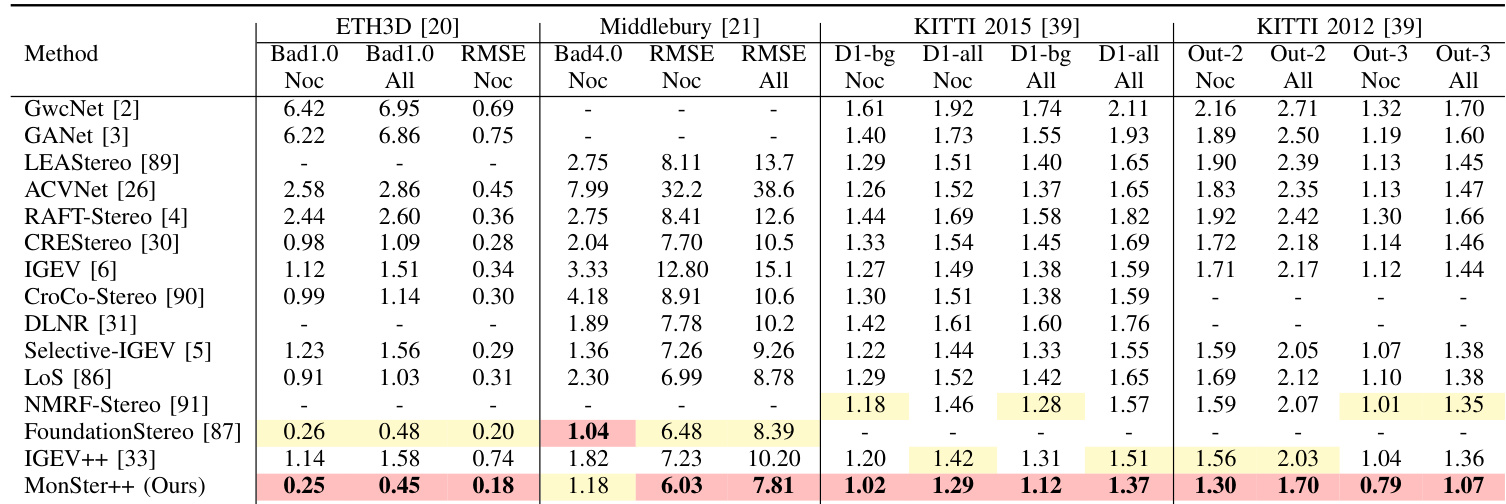
研究人员在 KITTI 2012 基准的反光区域评估 MonSter++,在所有报告指标上均取得最佳表现。MonSter++ 在 Out-3 (All) 和 Out-4 (All) 指标上分别超越前 SOTA 方法 NMRF-Stereo 57.46% 和 62.40%,充分展示了在处理挑战性反光区域方面的显著优势。
结果表明,MonSter++ 在 Scene Flow 测试集的边缘与非边缘区域均优于 IGEV 和 Selective-IGEV。在边缘区域,MonSter++ 的 EPE 提升 14.35%,>1px 误差指标提升 24.39%;在非边缘区域,EPE 提升 12.39%,>1px 误差提升 18.42%。