Command Palette
Search for a command to run...
Vchitect-2.0:用于扩展视频扩散模型的并行Transformer
Vchitect-2.0:用于扩展视频扩散模型的并行Transformer
摘要
我们提出Vchitect-2.0,一种并行化的Transformer架构,旨在扩展视频扩散模型,以支持大规模文本到视频生成任务。整个Vchitect-2.0系统包含若干关键设计:(1)通过引入一种新型的多模态扩散模块(Multimodal Diffusion Block),我们的方法实现了文本描述与生成视频帧之间的一致性对齐,同时保持了视频序列间的时序连贯性;(2)为克服内存与计算瓶颈,我们提出了一种高效的训练框架(Memory-efficient Training framework),融合混合并行策略及其他内存优化技术,从而在分布式系统上实现对长视频序列的高效训练;(3)此外,我们优化了数据处理流程,构建了Vchitect T2V DataVerse——一个经过严格标注与美学评估的百万级高质量训练数据集。大量基准测试表明,Vchitect-2.0在视频质量、训练效率与可扩展性方面均优于现有方法,可作为高保真视频生成任务的可靠基础模型。
一句话总结
来自南洋理工大学、上海人工智能实验室和香港中文大学的研究人员提出了 Vchitect-2.0,一种并行 Transformer 架构,通过引入多模态扩散模块以增强文本-视频对齐与时间连贯性,并结合融合序列并行与数据并行的混合并行框架及内存优化技术(如重计算和卸载),显著提升了长时长、高分辨率视频生成的训练效率与可扩展性,其背后依托于一个经过严格标注与美学评估的百万级高质量数据集。
主要贡献
- Vchitect-2.0 引入了一种新颖的多模态扩散模块,确保文本提示与生成视频帧之间具有强对齐性,同时在长视频序列中保持时间连贯性,有效解决了文本到视频生成中的关键挑战。
- 该架构采用融合数据并行与序列并行的混合并行框架,并结合重计算、卸载等内存节省技术,实现了在分布式系统上对大规模视频扩散模型的高效训练。
- Vchitect T2V DataVerse 是一个百万级高质量数据集,经过严格标注与美学评估,支持多样且复杂的文本到视频任务,广泛基准测试表明其在视频质量、时间一致性及训练效率方面均表现卓越。
引言
研究人员利用扩散模型在文本到视频(T2V)生成领域的最新进展,其目标是从文本提示生成具有时间连贯性与高保真度的视频。尽管先前工作已通过时空注意力或3D卷积等时间模块扩展了文本到图像的扩散模型,但这些方法在处理长视频序列时仍面临时间不一致(如闪烁、运动不连续)和高计算开销的问题。此外,高质量、标注完善的视频数据集稀缺进一步限制了模型的泛化能力。为应对这些挑战,研究人员提出 Vchitect-2.0,一种具备新型多模态扩散模块的并行 Transformer 架构,确保强文本-视频对齐与时间连贯性。系统采用融合数据并行与序列并行的混合并行框架,并结合重计算、卸载等内存优化技术,实现分布式系统上长视频的高效训练。此外,他们还推出了 Vchitect T2V DataVerse,一个通过严格标注与美学评估构建的百万级数据集,以提升训练质量与多样性。大量实验表明,Vchitect-2.0 在视频质量、时间一致性与训练效率方面均达到当前最优水平,为未来视频生成研究奠定了可扩展的基础。
数据集
-
Vchitect-2.0 的数据集整合了公开来源(WebVid10M、Panda70M、Vimeo25M、InternVid)与内部采集的100万条视频,均经过严格的过滤与重标注流程以提升质量与可控性。
-
公开数据集提供跨领域的多样化视频内容,而内部数据包含最高达4K分辨率、更长时长与更详细标注的视频,显著提升了视觉保真度与语义丰富性。
-
数据处理流程首先使用 PySceneDetect 配合 AdaptiveDetector(阈值21.0)进行镜头分割,随后通过 ViCLIP 特征对比(相似度阈值0.6)进行事件拼接,合并属于同一语义事件的片段。
-
静态视频过滤通过比较连续帧间灰度像素强度差异(阈值0.9)剔除静态帧占比超过30%的片段,确保仅保留动态内容。
-
美学评估采用基于 CLIP 特征的预训练预测器对视频帧进行1至10分评分;仅保留高美学得分片段,显著提升视觉质量。
-
动态性估计通过在下采样至128x128的帧上使用 RAFT(2次迭代)测量运动强度,用于识别并剔除存在过度抖动或运动极少的视频。
-
视频字幕生成采用 LLaVA-Next-Video 与微调后的 VideoChat 模型,每模型处理16帧,提示聚焦于主体、动作与背景。字幕平均长度为200词元,并通过重生成提升细节与动态描述。
-
水印检测使用基于 EfficientNet 的分类器(在 LAION 上训练)评估关键帧中的水印存在性;水印概率高的视频被排除。
-
文本定位采用 EasyOCR,检测得分阈值为0.4,最小文本长度为4;若帧中文本区域超过总面积的2%,则标记,视频中若超过一个此类帧则被丢弃。
-
最终数据集相比 Vchitect 具有更长的平均视频时长,重生成的描述平均达100词元,美学评分显著提升——内部视频中近半数得分高于6分,较前代版本的16.89%大幅提升。
-
训练时,数据按调整比例划分为多个子集,以平衡领域覆盖与质量,内部数据贡献更高分辨率、更长时长与更详细内容,从而增强模型性能。
-
所有视频片段均处理以保持叙事连贯性,元数据(包括美学评分、动态程度、水印标志、文本定位信息)嵌入其中,供后续训练与评估使用。
方法
研究人员采用一种并行 Transformer 架构,旨在解决大规模视频扩散模型训练中的挑战。模型核心基于 Stable Diffusion 3,引入统一的多模态扩散块,并通过可学习的上下文潜在变量增强文本-帧的一致性。为将该能力扩展至文本到视频生成,同时保持文本-图像与文本-视频的一致性,研究人员提出一种并行多模态扩散块。该模块保留文本-图像生成能力,同时支持通用的文本-视频合成。架构处理文本与视觉嵌入,以棋盘式交错方式组织,实现全序列交叉注意力,锚定于首帧的文本嵌入。输入序列结构为 [B, F, L, H, W],分别进行空间与时间注意力变换:空间注意力将其重塑为 [B×F, L, H, W],时间注意力重塑为 [B × L, F, H, W]。空间、时间与全序列交叉注意力分支的输出通过逐元素相加聚合,生成最终特征表示。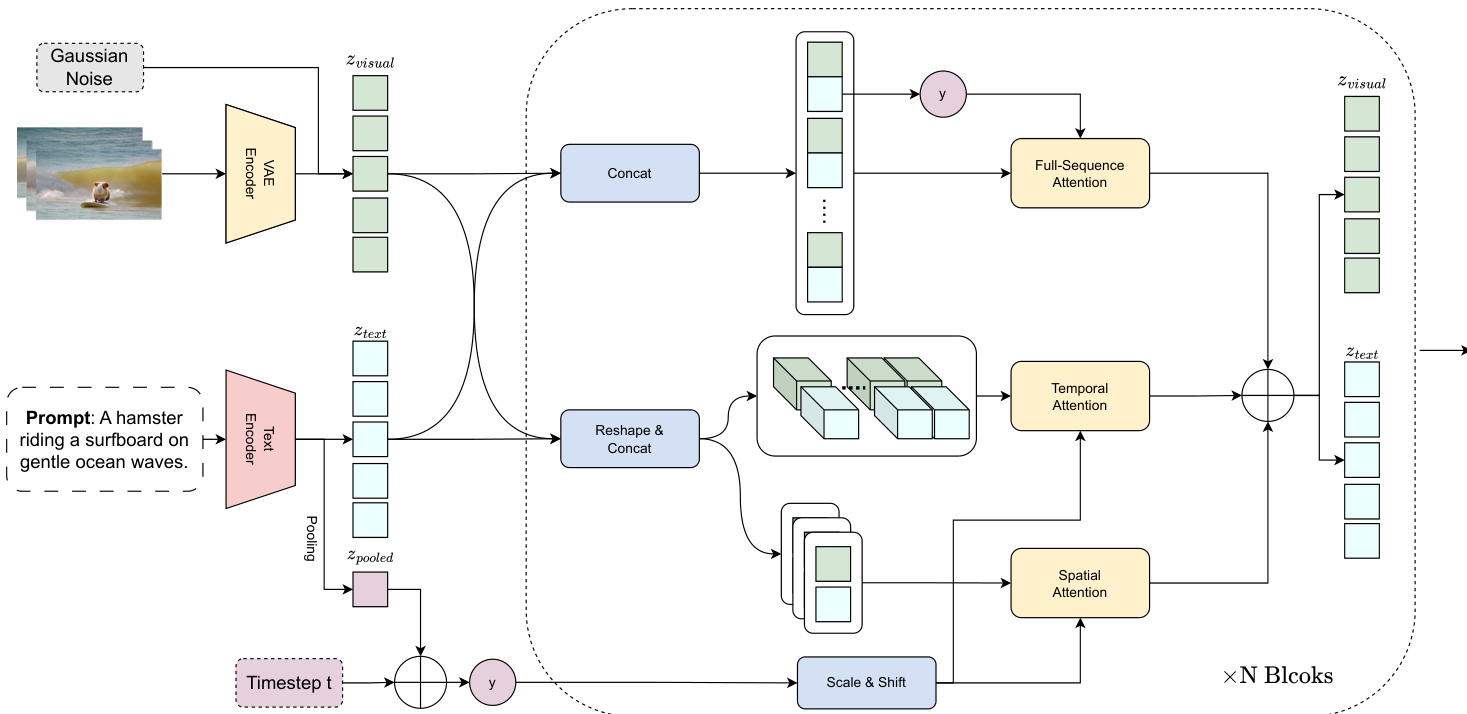
训练系统结合多种内存高效策略,以应对长上下文视频训练中前向激活带来的巨大内存开销。研究人员分析现有框架的局限性,提出一种集成多种内存节省技术的训练系统。关键决策是将序列并行(SP)组限制在单个训练节点内,利用其他内存优化技术,并在节点间采用数据并行。该策略避免了节点间 SP 带来的效率低下与可扩展性问题,尤其考虑到节点间带宽低于节点内连接。系统结合节点内 SP 与节点间数据并行,集成激活卸载、重计算与全分片数据并行(FSDP),在最小化开销的同时有效缓解内存压力。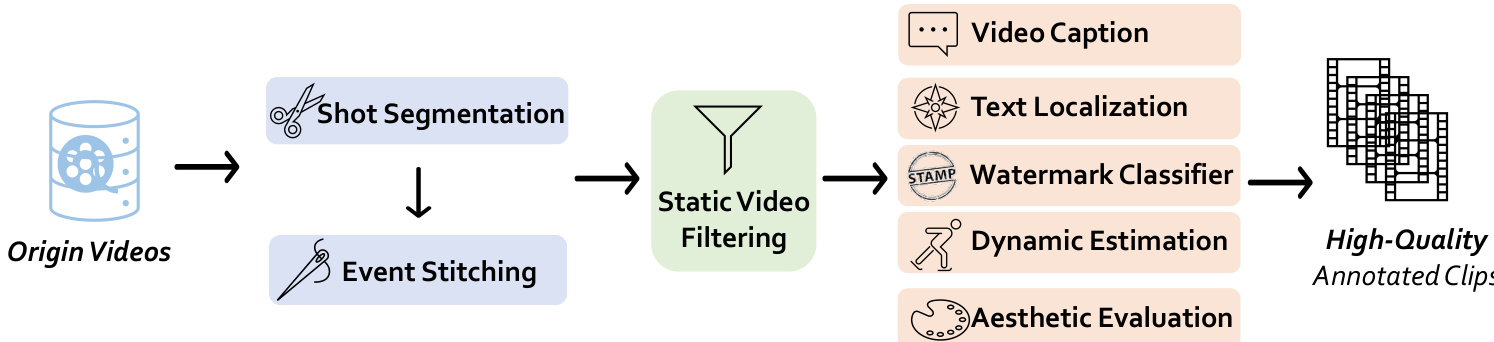
为进一步优化内存使用,研究人员设计了一种专用于其3D与多模态特性的节点内 SP 工作流。他们选择在 Transformer 主干中对空间序列进行切分,因其通常长于时间序列,从而最小化对计算核效率的影响。对于空间注意力核,采用头并行,因节点内 SP 不受注意力头数量限制。文本标记与视觉标记一样,在 SP 组内跨所有设备分片,确保 Transformer 主干与文本编码器的负载均衡。VAE 推理阶段计算密集且内存占用高,通过将输入视频视为帧的批量,采用帧级数据并行进行并行化。散列的帧批量被切分为更小的 mini-batch 进行迭代编码,帧级 DP 并行进一步扩展至潜在块化与位置嵌入计算。在 Transformer 块前引入全对全重分片步骤,替代 VAE 编码后的全聚集操作,提升并行性并减少通信开销。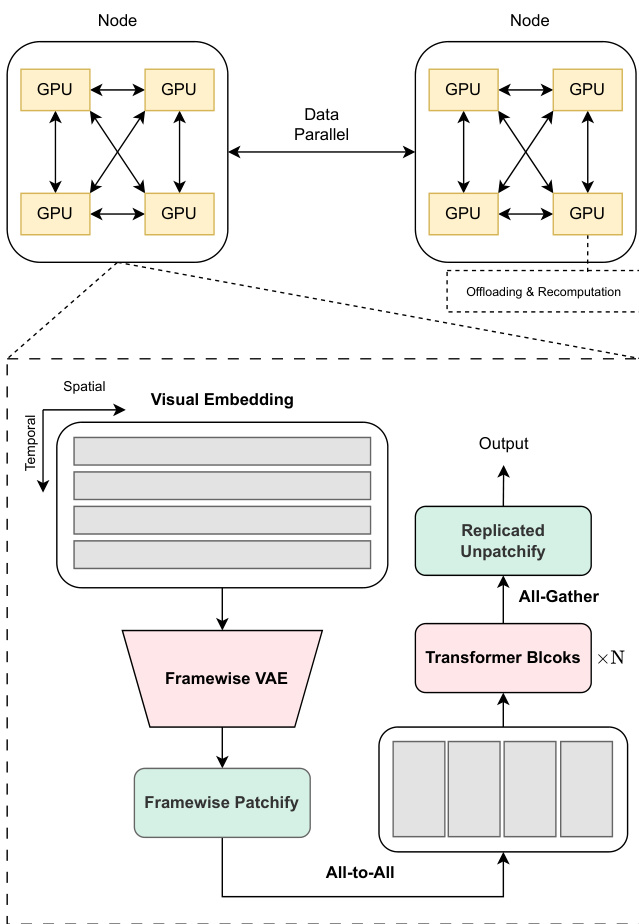
实验
- 在 WebVid-10M、Panda-70M、InternVid-18M-aes、Vimeo 与内部数据上进行多阶段训练,以扩展分辨率与视频长度,实现720p、5秒视频的生成,具备高时间连贯性与视觉保真度。
- 在 VBench 上取得具有竞争力的结果:Vchitect-2.0-2B 在 Overall Consistency 上优于 CogVideoX-2B 1.35%,Aesthetic Quality 提升0.65%,Imaging Quality 提升3.92%;增强版本(Vchitect-2.0-2B [E])在 Total Score 上超越商业模型 Kling 0.39%。
- 人工评估显示,在视频-文本对齐、帧级质量与时间质量三个维度上胜率均超过60%,表明 Vchitect-2.0-2B 在与 Mira、OpenSora-v1.2、CogVideoX-2B、OpenSoraPlan-v1.1 的对比中具有明显偏好。
- 消融实验验证了全序列交叉注意力的有效性,显著提升 Total Score、Overall Consistency、Aesthetic Quality 与 Imaging Quality。
- 内存高效训练策略(重计算、卸载、SP 工作流)使模型在长序列长度(最高达1.16M词元)下实现稳定训练,表现出近线性可扩展性,迭代时间显著低于基线与跨节点方法。
结果表明,Vchitect-2.0-2B [E] 的 Total Score 达到82.24%,在多数指标上超越 Kling 与其他模型,尤其在 Overall Consistency、Aesthetic Quality 与 Imaging Quality 上表现突出。增强版本展现出竞争力,Total Score 超过 Kling 0.39%,凸显所提训练策略与 VEnhancer 后处理的有效性。

研究人员评估了视频生成模型的内存高效训练策略,对比基线、重计算、卸载及组合方法在不同输入形状下的表现。结果表明,组合策略在内存效率与迭代时间之间取得最佳平衡,即使在其他方法因内存溢出或性能下降而失败的大输入形状下仍能实现稳定训练。

研究人员使用 VBench 提供的自动化评估指标评估 Vchitect-2.0-2B 的性能,结果显示其 Total Score 达79.33%,在 Overall Consistency、Aesthetic Quality 与 Imaging Quality 上优于基线及其他模型。结果表明,该模型在生成视觉连贯、高质量视频方面表现优异,尤其在视觉保真度与一致性相关指标上突出,但在人像内容与空间理解方面仍面临挑战。

研究人员开展人工评估,将 Vchitect-2.0-2B 与四种其他模型在三个指标上进行对比:视频-文本对齐、帧级质量与时间质量。结果显示,Vchitect-2.0-2B 在视频-文本对齐上平均胜率为74.59%,帧级质量为71.62%,时间质量为66.01%,在所有评估维度上均表现出明显偏好。
