Command Palette
Search for a command to run...
Sa2VA:将SAM2与LLaVA融合以实现图像与视频的密集定位理解
Sa2VA:将SAM2与LLaVA融合以实现图像与视频的密集定位理解
Haobo Yuan Xiangtai Li Tao Zhang Zilong Huang Shilin Xu Shunping Ji Yunhai Tong Lu Qi Jiashi Feng Ming-Hsuan Yang
摘要
本文提出了Sa2VA,这是首个面向图像与视频密集基础理解的综合性统一模型。与现有大多局限于特定模态或任务的多模态大语言模型不同,Sa2VA能够支持广泛的图像与视频任务,包括指代分割(referring segmentation)与多轮对话,且仅需极少的“一次指令微调”(one-shot instruction tuning)即可实现高效适配。Sa2VA将SAM-2——一种基础视频分割模型——与先进的视觉-语言模型(MLLM)相结合,将文本、图像与视频统一映射至共享的大语言模型(LLM)token空间。通过LLM生成的指令token,Sa2VA可精准引导SAM-2生成高质量掩码,从而实现对静态与动态视觉内容的 grounded(具身化)多模态理解。此外,本文还提出了Ref-SAV,一个自动标注的视频数据集,包含超过7.2万个复杂视频场景中的物体表达,旨在提升模型性能。我们还人工验证了Ref-SAV数据集中2,000个视频对象,以在复杂环境下对指代视频目标分割任务进行基准测试。实验结果表明,Sa2VA在多项任务中均表现出色,尤其在指代视频目标分割任务上表现突出,展现出其在复杂真实场景应用中的巨大潜力。更进一步,Sa2VA具有良好的可扩展性,可轻松适配多种视觉-语言模型(VLM),如Qwen-VL与Intern-VL,且能以快速、高效的方式集成至当前开源的VLM体系中。相关代码与模型已公开,供社区使用。
一句话总结
来自加州大学默塞德分校、字节跳动种子团队、武汉大学和北京大学的作者提出 Sa2VA,一种统一模型,将 SAM-2 与多模态大语言模型(MLLM)集成,通过共享的 LLM 令牌空间实现图像和视频的密集、具身理解,利用指令引导的掩码生成完成指代分割等任务——在复杂视频场景中超越先前方法,并支持快速适配其他 VLM,同时发布了新的 Ref-SAV 数据集并开源。
主要贡献
-
Sa2VA 是首个将 SAM-2 与多模态大语言模型(MLLM)整合到单一框架中的统一模型,通过共享的 LLM 令牌空间实现对图像和视频的密集、具身理解,支持指代分割、视频对话和具身描述等多种任务,仅需少量单次指令微调即可实现。
-
该模型通过端到端训练方法(冻结 SAM-2 组件)解决了任务设计、性能平衡和知识继承等关键挑战,使系统可无缝扩展至 Qwen-VL 和 Intern-VL 等先进 VLM,同时保持强大的语言与感知能力。
-
Sa2VA 在新基准 Ref-SAV 上进行评估,该数据集为大规模、自动标注的视频数据集,包含超过 72k 个物体表达式,并对 2k 个样本进行人工验证。在零样本指代视频对象分割任务中,其性能较先前方法提升超过 15%,在复杂真实场景中表现出卓越性能。
引言
作者通过统一两个强大基础模型——SAM-2(在可提示分割与跟踪方面表现优异)和多模态大语言模型(MLLM,具备开放式的语言理解能力),解决了实现图像与视频密集、具身理解的挑战。以往工作或局限于视频分割、视频问答等狭窄任务,或以模块化方式组合模型,牺牲了端到端性能与灵活性。现有方法难以在具身任务与对话能力之间取得平衡,常需以牺牲一方为代价。为克服这些局限,作者提出 Sa2VA,一种通过单次视觉指令微调整合 SAM-2 与 MLLM 的统一框架,支持图像与视频输入的端到端训练。该模型将视觉输入视为令牌,无需架构特化即可无缝处理指代分割、视觉问答和具身对话等多样化任务。其关键创新在于解耦设计:冻结 SAM-2 的编码器与记忆模块,保留其跟踪能力的同时,实现与不断演进的 MLLM 的兼容。作者还引入 Ref-SAV,一个新基准,包含长视频、严重遮挡和复杂文本等挑战性条件,以更真实地反映交互式应用需求。实验表明,Sa2VA 在多个基准上达到最先进性能,尤其在 Ref-SAV 零样本设置下较先前方法提升 15%,为统一、密集视觉理解建立了新的强基线。
数据集
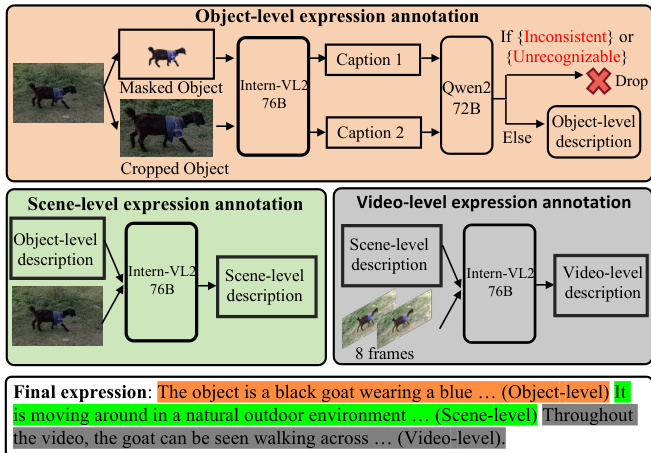
- Ref-SAV 数据集基于 SA-V 数据集,通过自动化标注流程构建,训练集中的指代对象文本表达由自动标注生成,无需人工标注。
- 该流程包含三个阶段:
- 物体级标注:选取物体面积最大的帧,裁剪并掩码该物体。原始图像与掩码图像分别输入 InternVL2-76B 生成描述,再通过 Qwen2-72B 验证并清洗,剔除不一致或错误输出。
- 场景级标注:将原始图像与物体级描述输入 InternVL2-76B,生成包含物体与周围环境关系的丰富上下文描述。
- 视频级标注:从视频中均匀采样八帧,用黄色边框突出目标物体。这些帧与场景级描述配对,用于生成捕捉物体运动与行为的动态视频级描述。
- Ref-SAV 训练集包含 37,311 个视频和 72,509 个物体表达式,全部自动生成。
- 评估基准来自 SA-V 训练集的独立子集,确保与训练数据无重叠,包含 1,147 个视频和 1,945 个表达式:1,694 个长表达式(自动生成并经人工筛选)和 251 个短表达式(人工标注)。
- 本文在训练与评估中使用该数据集,训练集采用完整自动化流程输出。训练过程中应用混合比例与处理策略,以平衡表达长度与复杂度;评估基准则用于评估长、短指代表达的性能。
- 一个关键处理细节是在采样视频帧上使用黄色边框突出目标物体,有助于模型在生成视频级描述时理解空间与时间上下文。
方法
作者采用统一框架应对多样化的图像与视频理解任务,将预训练多模态大语言模型(MLLM)与 SAM-2(基础视频分割模型)集成。整体架构如框架图所示,其工作流程为:首先将文本、视觉与提示输入编码为令牌嵌入。文本通过分词器与语言嵌入模块处理,视觉输入(图像与视频)则分别由图像与视频编码器处理。视觉提示(如边界框或点)通过专用提示编码器处理。这些嵌入随后合并并输入大语言模型(LLM),生成输出令牌,其中包含特殊 “[SEG]” 令牌。该令牌作为 SAM-2 解码器的空间-时间提示,使其能够为图像与视频生成精确的分割掩码。该框架支持多种任务,包括指代分割、视频对象分割、图像与视频对话、具身描述生成,通过条件化输出以满足特定任务需求。
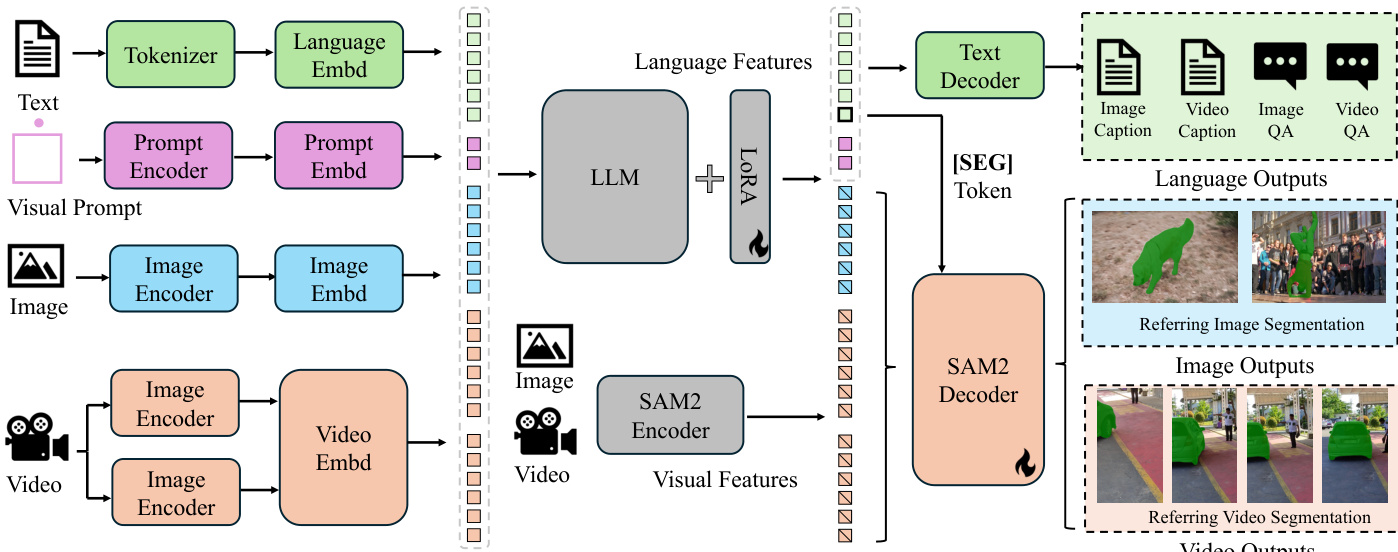
模型采用解耦设计,将 SAM-2 附加于预训练 MLLM 之上,不将 SAM-2 的输出令牌融入 LLM。这一设计简化了架构,避免计算开销,并保留了 MLLM 的知识继承能力,使系统可适应 MLLM 的持续演进。训练过程中,SAM-2 解码器通过 “[SEG]” 令牌进行微调,该令牌由 LLM 的隐藏状态生成,作为提示。梯度通过该令牌反向传播至 MLLM,实现联合学习。在视频任务中,模型采用基于记忆的跟踪机制:关键帧被处理以生成初始掩码,其特征用于在后续帧中跟踪对象,具体见推理算法。
实验
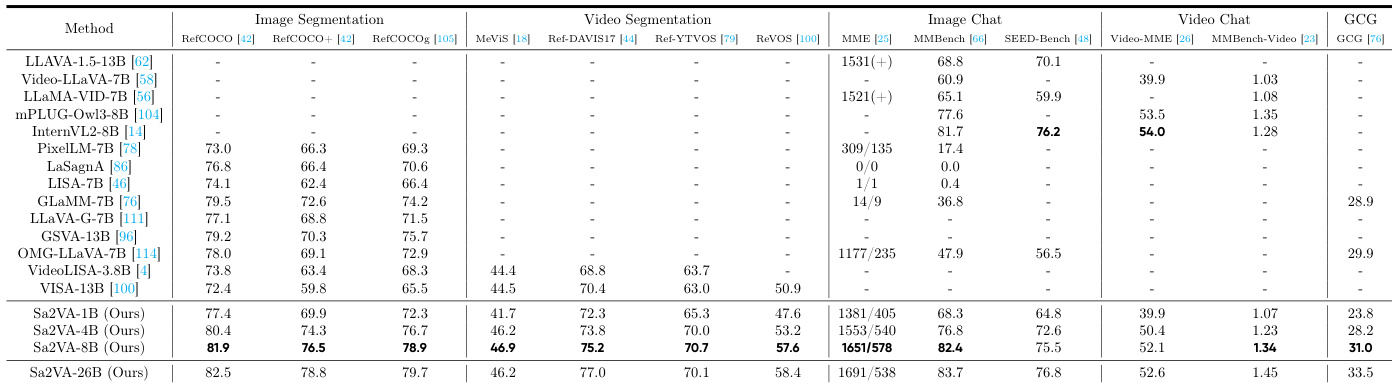
- Sa2VA 在图像指代分割任务上达到最先进性能,RefCOCO、RefCOCO+ 和 RefCOCOg 上的 cIoU 分别为 81.9、76.5 和 78.9,分别比 GLaMM-7B 提升 2.4、3.9 和 4.7 cIoU,优于 LISA、PixelLLM、PSALM 和 OMG-LLaVA。
- 在视频分割基准上,Sa2VA-8B 在 MeVIS、Ref-DAVIS17 和 ReVOS 上的 J&F 分别达到 46.9、75.2 和 57.6,分别超过 VISA-13B 2.4、4.8 和 6.7 J&F,MMBench-Video 得分为 1.34,优于 InternVL2-8B(1.28)。
- Sa2VA 保持了强大的多模态对话性能,在 MME、MMbench 和 SEED-Bench 上得分分别为 2229(1651/578)、82.4 和 75.5,与 InternVL2 相当,表现出对灾难性遗忘的鲁棒性。
- 消融实验表明,图像与视频问答、分割及多模态数据集的联合协同训练至关重要,当关键数据集被移除时,MME 性能下降高达 129,MMBasech-Video 下降 34%。
- 使用单一通用 “[SEG]” 令牌的设计优于帧特定令牌,有效保留了从图像分割到视频分割的知识迁移能力。
- 使用所提出的 Ref-SAV 数据集进行训练显著提升性能,UniRef++ 在 Overall J&F 上提升 4.1(10.5 到 14.6),验证了其在视频指代分割中的价值。
- Sa2VA-4B 在 RefCOCOg 上实现最佳区域描述性能,METEOR 得分为 17.3,超越 Osprey(16.6);Sa2VA-26B 在全部五个 Ref-VOS 数据集上均优于视觉专家模型。
- 使用更强基础 MLLM(如 InternVL2.5)进行模型扩展,在各基准上均持续提升性能,表明其具备良好可扩展性。
- 推理过程主要由自回归 MLLM 组件主导,Sa2VA-26B 在固定长度条件下耗时 0.463s,Sa2VA-1B 为 0.123s,而 SAM-2 保持高效,达 39.5 FPS。
- 均匀关键帧采样(62.9 J&F)优于连续首帧采样(58.9 J&F),表明先进采样策略可进一步提升性能。
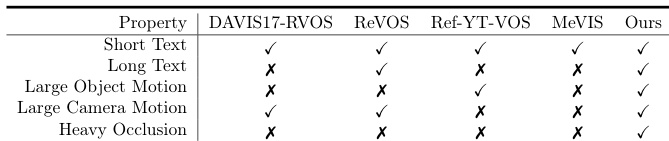
作者在 Ref-SAV 基准上将本方法与现有 Ref-VOS 模型进行比较,指出先前模型难以应对严重遮挡、长文本描述和多样标注等挑战性条件。而本方法 Sa2VA 在所有这些条件下均取得优异结果,展现出在复杂视频分割任务中的卓越性能与鲁棒性。
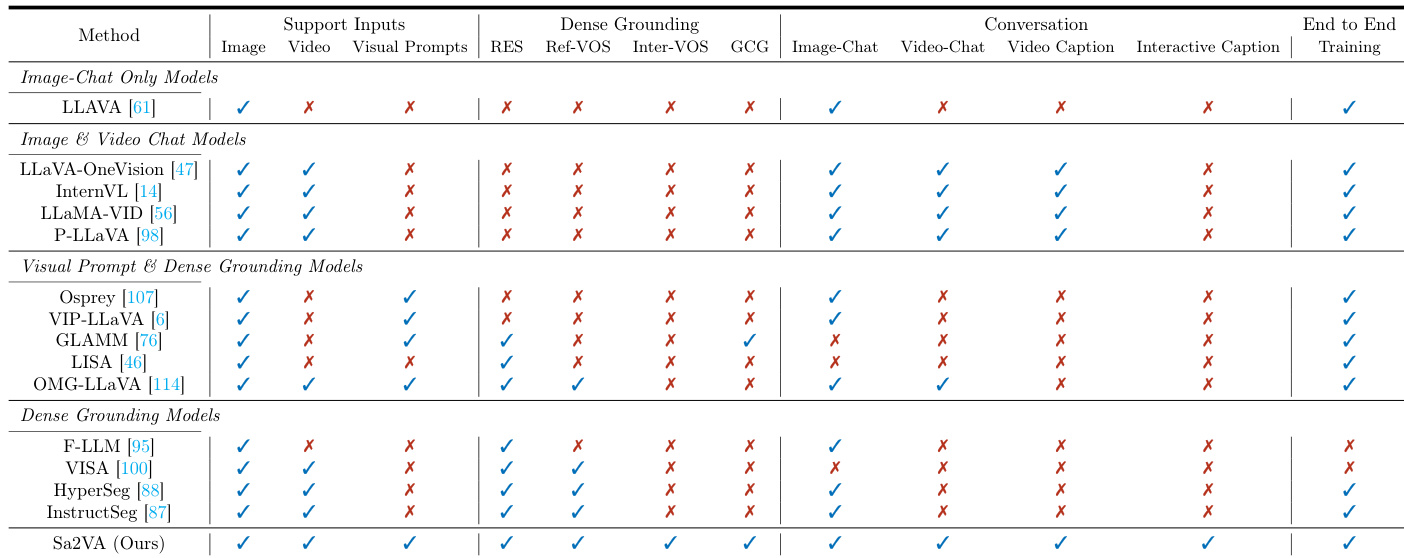
作者使用表格对比 Sa2VA 与现有模型在多项能力上的表现,显示 Sa2VA 是唯一支持所有列出任务的模型,包括图像与视频对话、密集具身理解、视觉提示理解。结果表明,Sa2VA 在所有类别中均实现全面性能,优于仅限特定任务的专用模型。
结果显示,Sa2VA-4B 在 RefCOCOg 数据集上取得最高 METEOR 得分 17.3,优于其他近期视觉提示理解模型,表明 Sa2VA 能生成准确且上下文感知的区域描述。
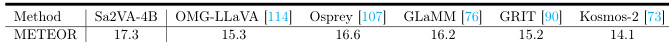
作者使用 Sa2VA-8B 在图像分割基准上实现最先进性能,RefCOCO、RefCOCO+ 和 RefCOCOg 上的 cIoU 分别为 81.9、76.5 和 78.9,超越 GLaMM-7B 等先前模型。该模型在图像与视频对话任务中也表现出色,MME、MMbench 和 SEED-Bench 上得分均较高,表明其在分割与对话能力上的多功能性。
作者使用表 14 对比 Sa2VA 与不同基础 MLLM 集成后的性能,显示基础模型的选择显著影响各任务结果。结果显示,Sa2VA-InternVL3-14B 在图像与视频分割基准上得分最高,而 Sa2VA-Qwen3VL-4B 在 MMBench 及其他图像对话任务中表现最佳,表明模型选择对任务优化至关重要。
