Command Palette
Search for a command to run...
TransPixar:通过透明性推进文本到视频生成
TransPixar:通过透明性推进文本到视频生成
Luozhou Wang Yijun Li Zhifei Chen Jui-Hsien Wang Zhifei Zhang He Zhang Zhe Lin Yingcong Chen
摘要
文本到视频生成模型近年来取得了显著进展,广泛应用于娱乐、广告和教育等领域。然而,生成包含透明度通道(Alpha通道)的RGBA视频仍面临挑战,主要受限于可用数据集的稀缺性以及现有模型难以适配该任务。Alpha通道在视觉特效(VFX)中至关重要,能够实现烟雾、反射等透明元素与场景的自然融合。为此,我们提出TransPixeler方法,可在保留原有RGB生成能力的基础上,扩展预训练视频模型以支持RGBA视频生成。TransPixeler采用扩散Transformer(DiT)架构,引入专用于Alpha通道的令牌(tokens),并基于LoRA(Low-Rank Adaptation)技术进行微调,实现RGB与Alpha通道的联合生成,且保持高度一致性。通过优化注意力机制,TransPixeler有效保留了原始RGB模型的优势,并在训练数据有限的情况下,实现了RGB与Alpha通道之间的强对齐。该方法能够高效生成多样化且一致的RGBA视频,显著推动了视觉特效及交互式内容创作的发展。
一句话总结
香港科技大学(广州)、香港科技大学与Adobe研究院的作者提出TransPixeler,一种基于LoRA增强的DiT方法,采用自适应alpha通道注意力机制,能够在仅依赖有限训练数据的情况下,实现从文本生成高保真RGBA视频,同时保持RGB质量,通过联合RGB-alpha建模推动视觉特效与交互内容创作的发展。
主要贡献
- TransPixeler解决了RGBA视频生成这一对视觉特效和交互内容至关重要的挑战,通过将预训练的基于DiT的文生视频模型扩展为联合生成RGB与alpha通道,克服了稀缺的RGBA训练数据和单向生成流程的限制。
- 该方法引入了专用于alpha的标记(tokens)和改进的注意力机制,在保持RGB生成质量的同时,实现RGB与alpha通道之间的双向对齐,并仅对alpha相关投影应用LoRA微调,以最小化干扰。
- 大量实验表明,TransPixeler能够生成多样且高保真的RGBA视频,具备强RGB-alpha一致性,在烟雾、反射和透明物体等复杂构图上优于生成后预测的方法。
引言
作者利用基于扩散Transformer(DiT)的文生视频模型,实现RGBA视频生成——即生成带有透明alpha通道的视频——同时保留预训练模型的高质量RGB生成能力。这对于游戏、VR、AR和电影中的视觉特效至关重要,因为烟雾、玻璃或反射等透明元素必须无缝融入场景。以往方法要么依赖事后视频抠像,存在泛化性和时序一致性差的问题;要么采用RGB先行、alpha预测的分离式流程,导致对齐效果差且数据受限。这些方法还受到RGBA视频数据集稀缺的制约,目前仅有约484个视频可用。作者的主要贡献是提出TransPixeler,一种在DiT模型中引入专用于alpha的标记和新型alpha通道自适应注意力机制的方法。通过仅对alpha相关投影进行基于LoRA的微调,并精心设计注意力交互(如允许RGB到alpha的注意力,同时移除文本到alpha的注意力),实现了强RGB-alpha对齐,且参数更新极少。这使得即使在训练数据有限的情况下,也能从文本生成高保真、多样化的RGBA视频,有效弥合了仅支持RGB的模型与先进视觉特效需求之间的差距。
方法
作者采用扩散Transformer(DiT)架构,将现有的RGB视频生成模型扩展为联合文生RGBA视频合成。核心框架基于一个预训练的DiT模型,该模型通过全自注意力机制处理文本与视频标记的组合序列。输入序列由文本标记 xtext 和视频标记 xvideo 构成,两者形状均为 B×L×D,其中 B 为批量大小,L 为序列长度,D 为潜在维度。这些标记被连接成单一序列,并在组合序列上应用标准自注意力机制。注意力计算定义为 Attention(Q,K,V)=softmax(dkQKT)V,其中查询、键和值表示通过投影矩阵 Wt 和位置编码函数 ft 从输入标记中获得。
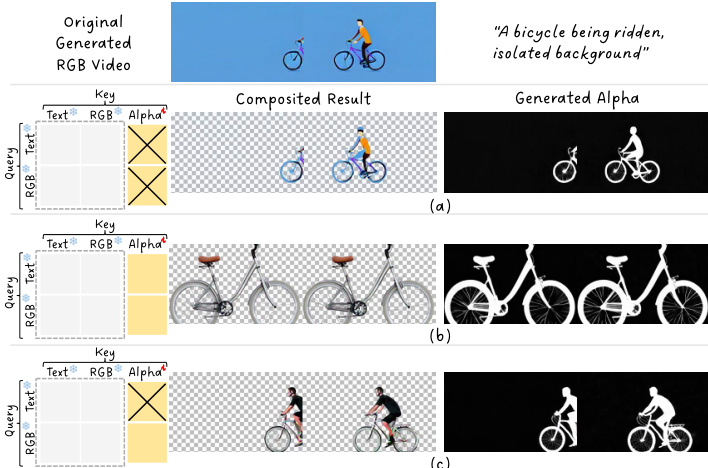
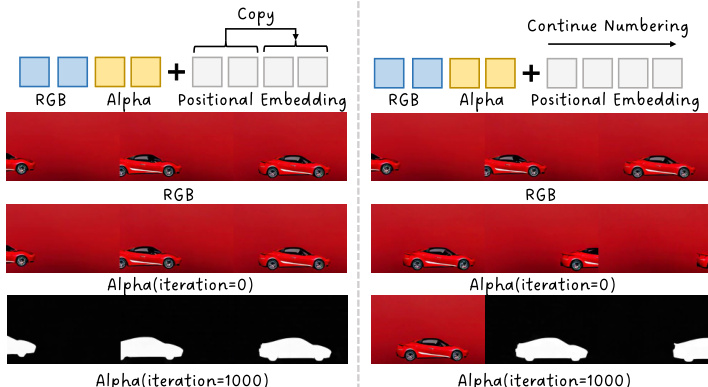
所提出的TransPixeler方法对基础DiT架构进行了多项关键修改,以实现alpha通道的生成。首先,输入序列长度翻倍,以容纳RGB和alpha视频标记。原始的 L 个视频标记用于生成RGB视频,而新增的 L 个alpha标记被追加以生成alpha视频。该序列扩展在框架图中有所展示。为确保模型能有效学习两个域的差异特征,位置编码函数被修改。与为RGB和alpha标记分配不同位置索引不同,该方法在两个域间共享相同的位置编码。这是通过使用与对应RGB标记相同的索引重新初始化alpha标记的位置嵌入,并添加一个可学习的域嵌入 d 来区分两种模态实现的。这一设计选择有助于在初始训练阶段最小化时空对齐挑战,加速收敛。
为进一步提升模型生成高质量alpha视频的能力,作者采用低秩适应(LoRA)微调方案。LoRA层仅应用于alpha域标记,使模型能够专门适应alpha生成,而不会破坏预训练模型在RGB生成上的行为。这种选择性适应通过修改alpha标记的权重矩阵实现,更新后的权重为原始权重与由残差强度 γ 控制的低秩更新项的组合。注意力机制也通过自定义注意力掩码进行修正。该掩码阻止文本标记对alpha标记的注意力计算,因为文本与alpha之间存在领域差距,这会损害生成质量。掩码定义为:若 m≤Ltext 且 n>Ltext+L,则 Mmn∗=−∞,否则为 0。这确保了文本标记不会关注alpha标记,从而保留了模型在文本和RGB域中的原始行为。
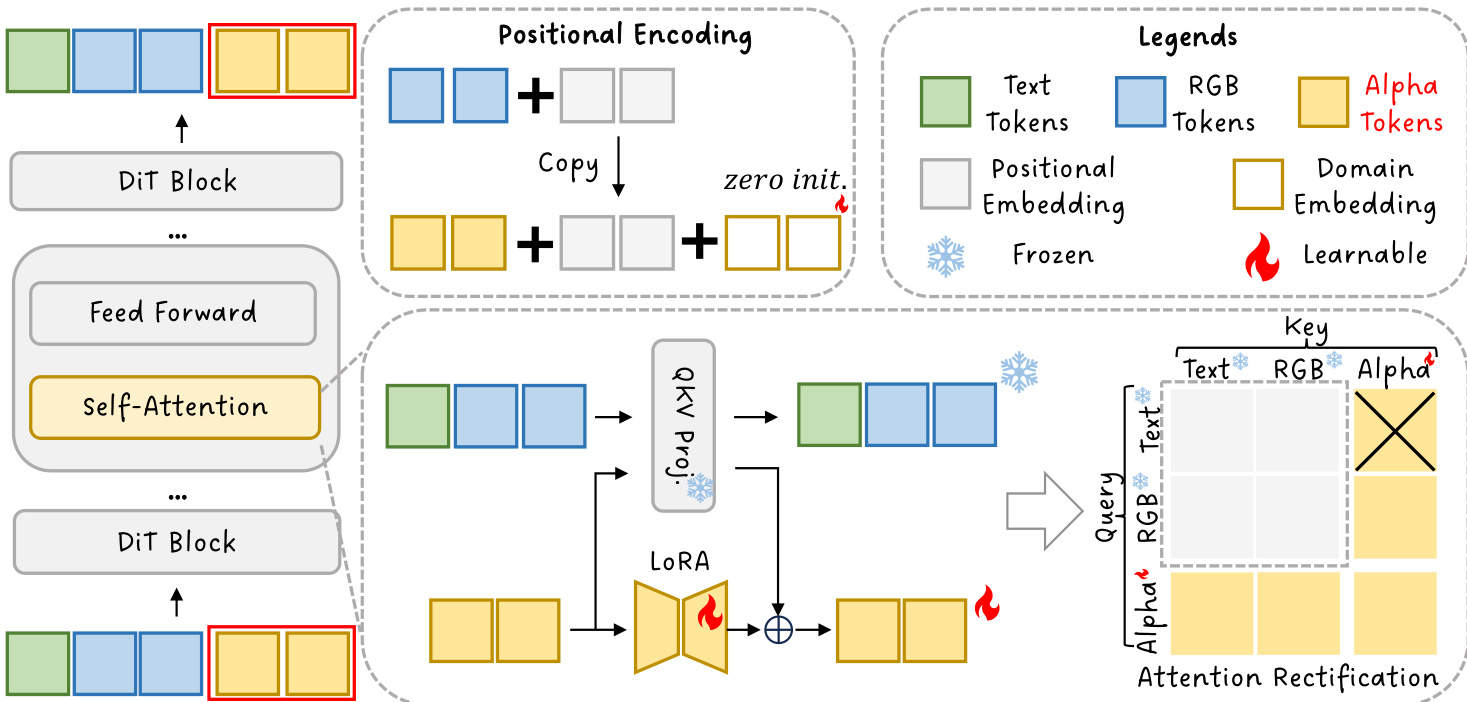
整体推理过程结合了上述修改。查询、键和值表示从连接的文本与视频标记中计算得出,视频标记应用了修改后的位置编码函数。注意力机制随后使用修正后的注意力掩码计算最终注意力输出。作者分析了按3×3分组结构组织的注意力矩阵,以理解不同标记类型之间的交互。他们发现,虽然文本到alpha的注意力有害,必须屏蔽,但RGB到alpha的注意力对于通过alpha引导来优化RGB生成至关重要。这一分析促成了注意力修正策略的设计,实现了在保持RGB质量与准确生成alpha通道之间的平衡。
实验
- 文生视频带透明度:展示了具有运动(旋转、奔跑、飞行)和透明材质(瓶子、玻璃)的动态物体生成,以及火焰、爆炸、裂纹和闪电等复杂效果,验证了在处理透明度与运动方面的鲁棒性。
- 图像生视频带透明度:与CogVideoX-I2V集成,从单张图像生成视频,支持可选的alpha通道,自动传播或生成后续帧的alpha通道,展现出良好的透明度与运动一致性。
- 与生成后预测方法对比:在RGB与alpha通道的定性对齐上优于Lotus + RGBA和SAM-2,尤其在非人类物体和复杂视觉效果方面,如图7所示。
- 与联合生成方法对比:在运动保真度和RGB-alpha对齐上超越LayerDiffusion + AnimateDiff,如图8所示;用户研究(87名参与者,30个视频)显示,我们的方法在对齐和提示遵循方面均显著更受青睐。
- 消融研究:验证了RGB到Alpha注意力对对齐的重要性;移除该机制会降低运动质量并导致错位。其他设计(批量扩展和潜在维度扩展)表现较差;我们的DiT序列扩展实现了最佳平衡。
- 定量评估:在80个生成的64帧视频上,实现了低光流差异(高运动对齐)和低FVD(高生成质量),表明在对齐与运动保真度之间取得了有效权衡。
- 局限性:由于序列扩展导致二次计算成本;性能依赖于底层T2V模型的生成先验;未来工作将探索效率优化。
结果表明,所提方法结合CogVideoX后,RGBA对齐度达93.3%,运动质量达78.3%,显著高于基线方法AnimateDiff + LayerDiff的6.7%和21.7%。这表明该方法能更好地将alpha通道与RGB内容对齐,同时保持运动质量。
