Command Palette
Search for a command to run...
LTX-Video:实时视频潜在扩散
LTX-Video:实时视频潜在扩散
摘要
我们提出 LTX-Video,这是一种基于 Transformer 的潜在扩散模型,采用整体化方法进行视频生成,通过无缝融合 Video-VAE 与去噪 Transformer 的功能职责,实现高效协同。与现有方法将这两个组件视为独立模块不同,LTX-Video 旨在优化二者之间的交互,以提升生成效率与质量。其核心是一个精心设计的 Video-VAE,实现了高达 1:192 的压缩比,每 token 对应时空维度 32×32×8 像素的下采样,这一效果得益于将 patchify 操作从 Transformer 的输入端前移至 VAE 的输入端。在如此高压缩的潜在空间中运行,使得 Transformer 能够高效执行完整的时空自注意力机制,这对于生成高分辨率且具有时间一致性的视频至关重要。然而,高压缩率也带来了细节表达能力受限的问题。为解决该问题,我们的 VAE 解码器同时承担潜在表示到像素的转换与最终去噪步骤,直接在像素空间输出干净结果。该设计在不引入额外上采样模块运行开销的前提下,保留了生成精细细节的能力。本模型支持多种应用场景,包括文本到视频与图像到视频生成,并可在训练阶段同步实现两种能力。在性能方面,LTX-Video 实现了超实时生成速度:在单张 Nvidia H100 GPU 上,仅用 2 秒即可生成 5 秒时长、24 帧/秒、分辨率为 768×512 的视频,显著优于同规模的现有所有模型。项目源代码与预训练模型已公开发布,为可访问性与可扩展性视频生成树立了全新基准。
一句话总结
Lightricks 的研究者提出了 LTX-Video,这是一种统一的基于 Transformer 的潜在扩散模型,将 Video-VAE 与去噪 Transformer 整合到一个优化的单一流程中,通过 1:192 的压缩比实现高效的全时空自注意力,并采用一种新颖的 VAE 设计,同时完成潜在空间到像素的转换与最终去噪,可在 H100 GPU 上实现 768x512 分辨率下实时性能的快速、高质量文本到视频及图像到视频生成,为可扩展且可访问的视频合成树立了新基准。
主要贡献
- LTX-Video 提出了一种统一架构,将 Video-VAE 与去噪 Transformer 整合到单一优化流程中,通过 1:192 的压缩比(每 token 对应 32×32×8 像素)在高度压缩的潜在空间中实现高效的全时空自注意力,该压缩比通过将分块操作从 Transformer 输入移至 VAE 输入实现。
- 为解决高压缩下细节丢失问题,赋予 VAE 解码器双重角色:潜在空间到像素的转换与最终去噪,直接在像素空间生成高保真输出,无需额外的上采样模块。
- LTX-Video 实现了超实时生成——在 H100 GPU 上仅用 2 秒即可生成 5 秒、768×512 分辨率、24 fps 的视频,优于同规模(20 亿参数)的现有模型,且仅用一个开源模型即可支持文本到视频与图像到视频生成。
引言
文本到视频模型的兴起得益于时空 Transformer 与 3D VAE,但以往方法常采用传统 VAE 设计,难以在空间与时间压缩之间取得最优平衡。尽管近期工作如 DC-VAE 在图像生成中展示了高空间压缩与深层潜在空间的优势,但将其扩展至视频仍具挑战,因需在保持运动保真度与高频细节方面面临更高复杂度。本文提出 LTX-Video,一种基于 Transformer 的潜在扩散模型,通过使用 128 通道潜在深度的 3D VAE 与高空间压缩,实现高效高质量的视频生成。其关键创新在于将最终去噪步骤移至 VAE 解码器,使其在高压缩率下重建缺失的高频细节。模型采用归一化分数坐标的旋转位置编码(Rotary Positional Embeddings)与注意力归一化,提升时空一致性与训练稳定性。该模型可在消费级硬件上以每运行 2 秒生成 5 秒视频,速度与质量均优于同类模型,并通过轻量级条件机制支持文本到视频与图像到视频生成。开源发布强调可及性、可持续性与负责任使用。
数据集
- 训练数据集结合公开数据与授权材料,包含视频与图像,以确保视觉概念的广泛覆盖并支持多样化的生成能力。
- 图像数据在训练混合中被视为独立的分辨率-时长组合,丰富模型对视频数据中不常见静态视觉概念的接触。
- 所有数据均经过严格质量控制:使用在数万对人工标注图像上训练的 Siamese 网络预测美学评分,低于阈值的样本被过滤。
- 为减少分布偏移,用于训练美学模型的图像对基于多标签网络的前三个共享标签进行选择,确保语义相关性一致。
- 视频数据过滤掉运动极少的片段,聚焦于与模型预期用途一致的动态内容。
- 从视频中裁剪掉黑边,以标准化宽高比并最大化可用视觉区域。
- 微调阶段仅使用通过过滤流程识别出的最高美学内容,以促进视觉吸引力强的输出。
- 所有视频与图像均通过内部自动标注系统重新标注,以提升元数据准确性并强化文本-图像对齐。
- 标注统计显示词数范围广泛(图 14a)与片段时长分布(图 14b),大多数片段时长不超过 10 秒。
- 最终数据集通过统一流程处理,整合美学过滤、运动与宽高比标准化及元数据增强,实现高质量、语境丰富的训练。
方法
作者采用整体化潜在扩散方法,将 Video-VAE 与去噪 Transformer 集成,优化其在高度压缩潜在空间中的交互。该框架的核心是一个 Video-VAE,通过时空下采样实现 1:192 的压缩比(每 token 对应 32×32×8 像素)。该高压缩比得益于将分块操作从 Transformer 输入移至 VAE 输入,使 Transformer 能在压缩空间中高效执行全时空自注意力。整体去噪过程如框架图所示,模型首先执行潜在空间到潜在空间的去噪步骤,随后进行最终的潜在空间到像素的去噪步骤以生成输出视频。
Video-VAE 架构详见图 4,由因果编码器与去噪解码器组成。因果编码器采用 3D 因果卷积,处理输入视频以生成压缩的潜在表示。去噪解码器在扩散时间步条件下运行,并引入多层噪声注入,负责将潜在表示还原至像素空间并执行最终去噪。解码器的双重角色是关键创新,使模型可直接在像素空间生成精细细节,无需独立上采样模块,从而保留细节并降低计算成本。
为应对高压缩带来的挑战,作者对 VAE 引入多项关键改进。采用新型重建生成对抗网络(rGAN)损失,其中判别器在每次迭代中同时接收原始样本与重建样本,简化了真实与虚假样本的区分任务,提升重建质量。此外,引入多层噪声注入机制以生成更丰富的高频细节,并采用均匀对数方差以防止通道利用率不足。还引入时空离散小波变换(DWT)损失,以确保高频细节的重建,这些细节常在标准 L1 或 L2 损失中丢失。
去噪 Transformer 基于 Pixart-α 架构设计,旨在高效建模多样且复杂的视频数据。其集成多项先进特性,包括用于动态位置信息的旋转位置编码(RoPE)、用于归一化的 RMSNorm,以及用于稳定注意力 logits 的 QK 归一化。如图 6 所示的 Transformer 块架构整合了这些组件以处理潜在 token。模型通过 T5-XXL 文本编码器与交叉注意力机制对文本提示进行条件化,实现稳健的文本到视频合成。对于图像到视频生成,模型采用逐 token 时间步条件化策略,将首帧编码并以小扩散时间步进行条件化,实现给定图像的无缝动画化。
训练过程基于修正流(rectified-flow),模型学习预测去噪过程的速度。作者采用对数正态时间步调度,聚焦于更难的时间步,并使用多分辨率训练,使模型能够生成不同分辨率与时长的视频。该方法通过在训练中暴露于多样化的输入尺寸与 token 数量,确保模型对未见配置具有良好的泛化能力。
实验
- 使用 ADAM-W 优化器训练,先进行预训练,再在高美学视频子集上进行微调。
- 在 1,000 个文本到视频与 1,000 个图像到视频提示上的人类评估显示,LTX-Video 在整体质量、运动保真度与提示遵循性方面优于 Open-Sora Plan、CogVideoX(2B)与 PyramidFlow,两项任务的胜率均更高。
- 重建 GAN 损失显著提升了高 VAE 压缩比(1:192)下的高频细节恢复,相比标准 GAN 损失减少了可见伪影。
- 指数型 RoPE 频率间距的训练损失低于反指数间距,证实其在扩散训练中的优越性。
- 在 t = 0.05 时由 VAE 解码器执行最终去噪步骤,显著提升视频质量,尤其在高运动序列中表现优于仅在潜在空间中去噪的标准方法。
- LTX-Video 在提示遵循性方面表现优异,但对提示质量敏感;仅限于短视频(最长 10 秒);领域泛化能力尚未测试。
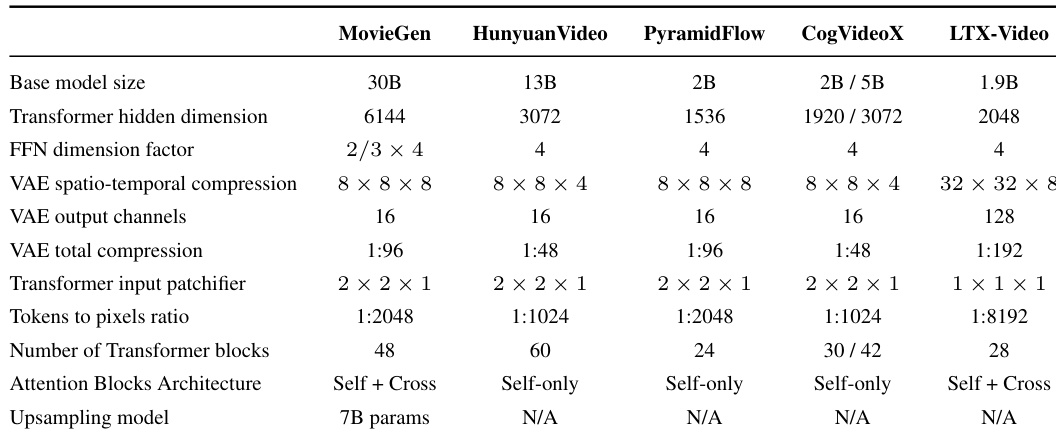
作者将 LTX-Video 与多个同规模的先进模型(包括 MovieGen、HunyuanVideo、PyramidFlow 与 CogVideoX)在人类评估研究中进行比较。结果表明,LTX-Video 在文本到视频与图像到视频任务中均显著优于这些模型,在成对比较中胜率更高,同时展现出显著的速度优势。
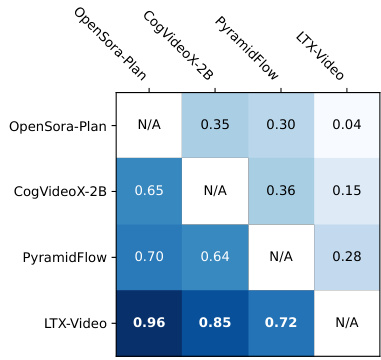
结果显示,LTX-Video 在文本到视频与图像到视频任务中均显著优于其他模型,成对比较中的胜率分别为 0.96 与 0.85。该模型在两类评估中表现一致,对所有测试模型均取得最高胜率。
结果显示,LTX-Video 在同规模模型中显著优于其他模型,在文本到视频与图像到视频任务中的胜率分别为 85% 与 91%。作者通过 20 名参与者的问卷调查,将 LTX-Video 与 Open-Sora Plan、CogVideoX 与 PyramidFlow 进行比较,发现 LTX-Video 获得强烈偏好,尤其在高运动场景中表现突出。
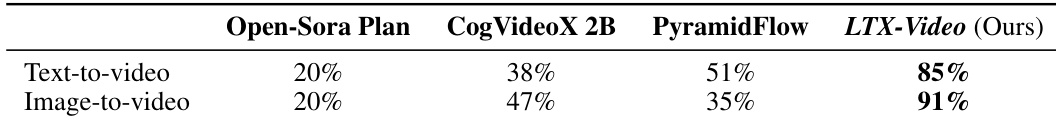
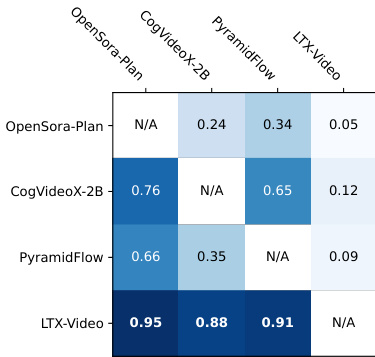
结果显示,LTX-Video 在文本到视频与图像到视频任务中均显著优于其他同规模模型,成对比较胜率分别为 0.95 与 0.91。模型在所有评估对中表现优异,人类评估中对视觉质量、运动保真度与提示遵循性均表现出强烈偏好。