Command Palette
Search for a command to run...
HuatuoGPT-o1:迈向基于 LLM 的医学复杂推理
HuatuoGPT-o1:迈向基于 LLM 的医学复杂推理
Junying Chen Zhenyang Cai Ke Ji Xidong Wang Wanlong Liu Rongsheng Wang Jianye Hou Benyou Wang
摘要
OpenAI o1 的突破凸显了通过增强推理能力来提升 LLM 的巨大潜力。然而,当前关于推理的研究大多聚焦于数学任务,导致医学等关键领域尚未得到充分探索。尽管医学领域与数学存在差异,但鉴于医疗行业的高标准,其同样需要稳健的推理能力以提供可靠的解答。然而,与数学领域不同,医学推理的验证极具挑战性。针对这一难题,我们提出了一套包含医学验证器(medical verifier)的可验证医学问题集,用于核查模型输出的正确性。这种可验证性使得通过两阶段方法推动医学推理的进展成为可能:(1)利用验证器引导搜索复杂的推理轨迹,以用于微调 LLMs;(2)应用基于验证器奖励的强化学习(RL),进一步增强复杂推理能力。在此基础上,我们推出了 HuatuoGPT-o1,这是一款具备复杂推理能力的医学 LLM。仅需 4 万个可验证问题,该模型在复杂推理任务上便超越了通用模型及特定医学领域的基线模型。实验结果表明,复杂推理能力显著提升了医学问题的解决效率,且通过强化学习获得的增益更为显著。我们期望本研究能为医学及其他专业领域的推理能力发展提供新的启示。
一句话总结
HuatuoGPT-o1 是一个医疗大语言模型,它通过两阶段方法推进复杂推理,该方法结合了由医疗验证器指导的微调以及仅在 4 万个可验证问题上的基于验证器奖励的强化学习,表现优于通用和医疗特定的基线。
核心贡献
- 这项工作引入了可验证的医疗问题,并配对医疗验证器以检查模型输出的正确性,这在通常具有挑战性的领域中尤为如此。该提议解决了与数学任务相比验证医疗推理的困难。
- 开发了一种两阶段训练方法,利用验证器指导微调期间的复杂推理轨迹搜索,并应用基于验证器奖励的强化学习。实验表明,该方法提高了医疗问题解决能力,并从强化学习增强中显著受益。
- HuatuoGPT-o1 被引入为一种能够进行复杂推理的医疗大语言模型,表现优于通用和医疗特定的基线。仅使用 4 万个可验证问题就实现了性能提升,突显了所提出框架的效率。
引言
大语言模型的近期进展凸显了复杂推理的价值,但大多数努力集中在数学而非医学等高风险领域。医疗应用需要稳健的推理以获得可靠的诊断,但在没有明确真实值的情况下,验证思维过程仍然具有挑战性。作者通过构建 4 万个可验证医疗问题并部署医疗验证器来评估解决方案的正确性,填补了这一空白。他们引入了一个两阶段训练框架,利用验证器指导搜索进行微调,并利用强化学习来完善复杂推理能力。这种方法产生了 HuatuoGPT-o1,这是一个专用模型,表现优于通用和医疗特定基线,同时证明了复杂推理在医疗背景下的有效性。
数据集
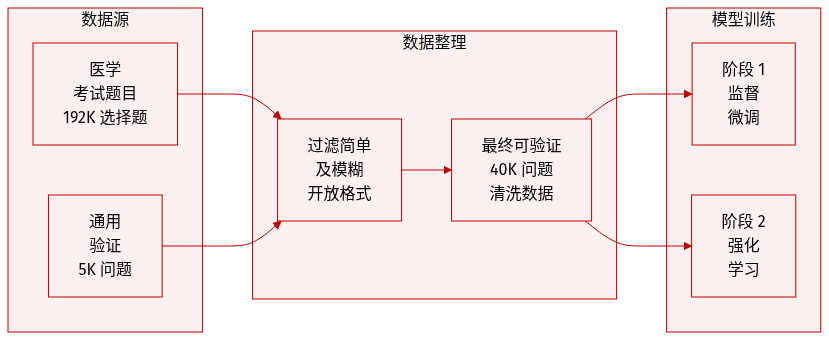
-
数据集组成和来源
- 作者从 MedQA-USMLE 和 MedMcQA 的训练集中获取的 19.2 万道医疗选择题构建了核心数据集。
- 他们将这些闭集问题转换为具有唯一真实答案的开放形式问题,以实现推理验证。
- 为了支持泛化,集合中还包括来自 MMLU-Pro 非医疗轨道的 5 千道通用验证问题。
-
关键细节和过滤规则
- 通过移除三个小型 LLM(Gemma2-9B、LLaMA-3.1-8B、Qwen2.5-7B)回答正确的项目来选择具有挑战性的问题。
- 简短的问题和缺乏唯一正确答案的问题被丢弃,并使用 GPT-4o 过滤掉模糊的情况。
- 最终过滤后的医疗数据集包含 4 万个可验证问题。
- 另外包含 4 千个未转换的闭集问题以增强泛化能力。
-
训练划分和使用
- 4 万个医疗问题被平均划分,2 万个用于第一阶段的监督微调,2 万个用于第二阶段的强化学习。
- 通用 MMLU-Pro 数据在训练过程中与医疗数据一起整合。
- 所有数据都经过严格筛选,以避免使用 64 个连续字符重叠的过滤器与评估基准发生污染。
-
处理和验证策略
- GPT-4o 将选定的选择题重新格式化为包含特定查询和简洁标准答案的开放性问题。
- 基于 GPT-4o 的验证器根据真实答案检查模型输出,以提供构建正确推理轨迹的二元反馈。
- 由于医疗领域别名普遍存在,避免使用精确匹配方法,转而采用基于 LLM 的验证。
方法
作者提出了一个两阶段框架,用于训练大语言模型(LLMs)执行医疗复杂推理,强调开发“先思考后回答”的行为。整体方法论分为两个不同的阶段:第一阶段侧重于通过监督微调(SFT)学习复杂推理,第二阶段使用强化学习(RL)增强推理能力。
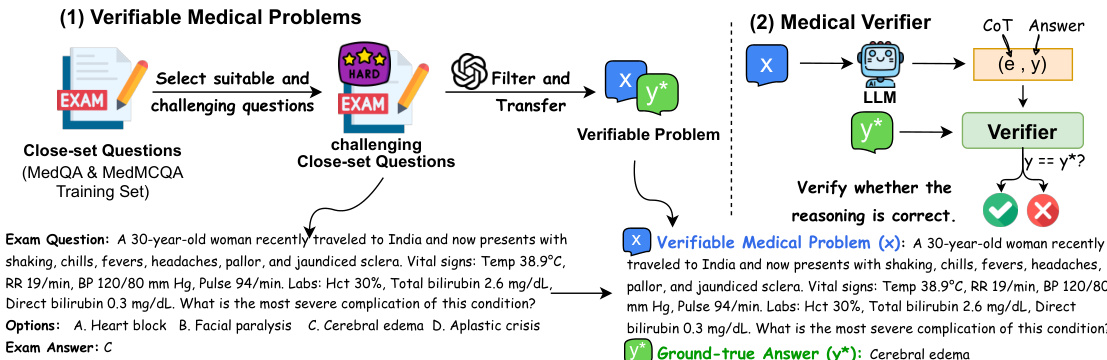
该过程始于构建可验证的医疗问题,源自 MedQA 和 MedMCQA 等闭集问题集。这些问题经过过滤并转换为具有挑战性的可验证实例,每个实例由一个问题 x 和一个真实答案 y∗ 组成。采用医疗验证器来评估模型响应的正确性。框架进入第一阶段,LLM 被训练生成复杂推理轨迹。给定问题 x,生成初始思维链(CoT)e0 和答案 y0。验证器检查 y0 是否匹配 y∗。如果不正确,模型通过应用四种搜索策略之一迭代细化答案:探索新路径、回溯、验证或修正。此迭代搜索持续进行,直到答案被验证为正确或达到最大迭代次数。成功的推理轨迹随后被重新格式化为连贯的自然语言复杂 CoT(e^),用于通过 SFT 训练模型以生成问题的正式响应(y^)。此阶段教导模型在提供最终答案之前进行深入的探索性推理。
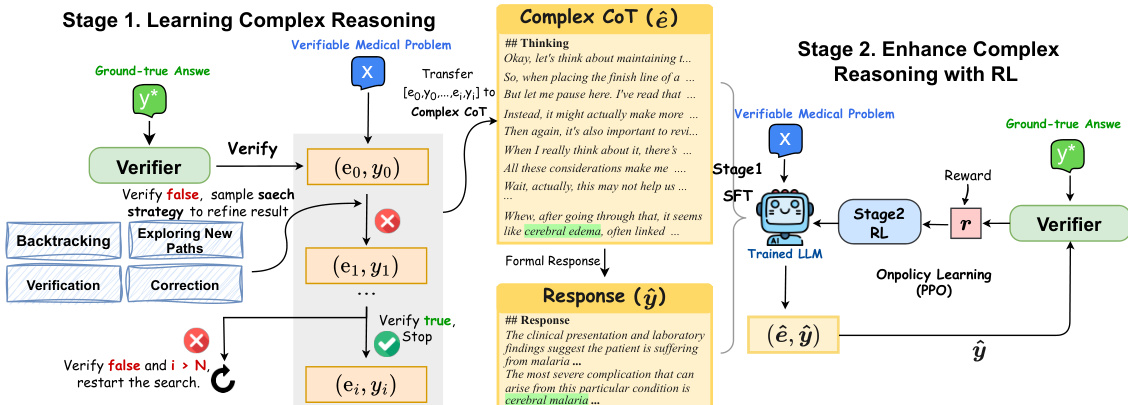

第二阶段使用在线策略强化学习进一步细化模型的推理技能。第一阶段的微调模型作为初始策略 πθ。训练目标是改进复杂 CoT 推理的生成。奖励函数旨在引导模型走向正确和彻底的推理。对于正确答案分配 1 的高奖励,对于错误答案分配 0.1 的低奖励,对于缺乏先思考后回答行为的响应分配 0 的奖励。为了在稀疏奖励下稳定训练,总奖励将此函数得分与学习策略 πθ 和初始策略 πref 之间的 Kullback-Leibler (KL) 散度相结合,并由系数 β 缩放。Proximal Policy Optimization (PPO) 算法用于 RL 训练,其中策略采样响应,计算奖励,并更新其参数。


实验
评估在传统和具有挑战性的医疗基准上评估 HuatuoGPT-o1,以展示其优于现有医疗特定和推理聚焦模型的优势。消融研究验证,结合复杂思维链推理和基于 PPO 的强化学习的两阶段训练策略,与简单微调相比显著增强了问题解决能力。此外,该框架通过高验证器可靠性和成功适应中文医疗领域证明了其鲁棒性,确认了所提出方法的泛化性。
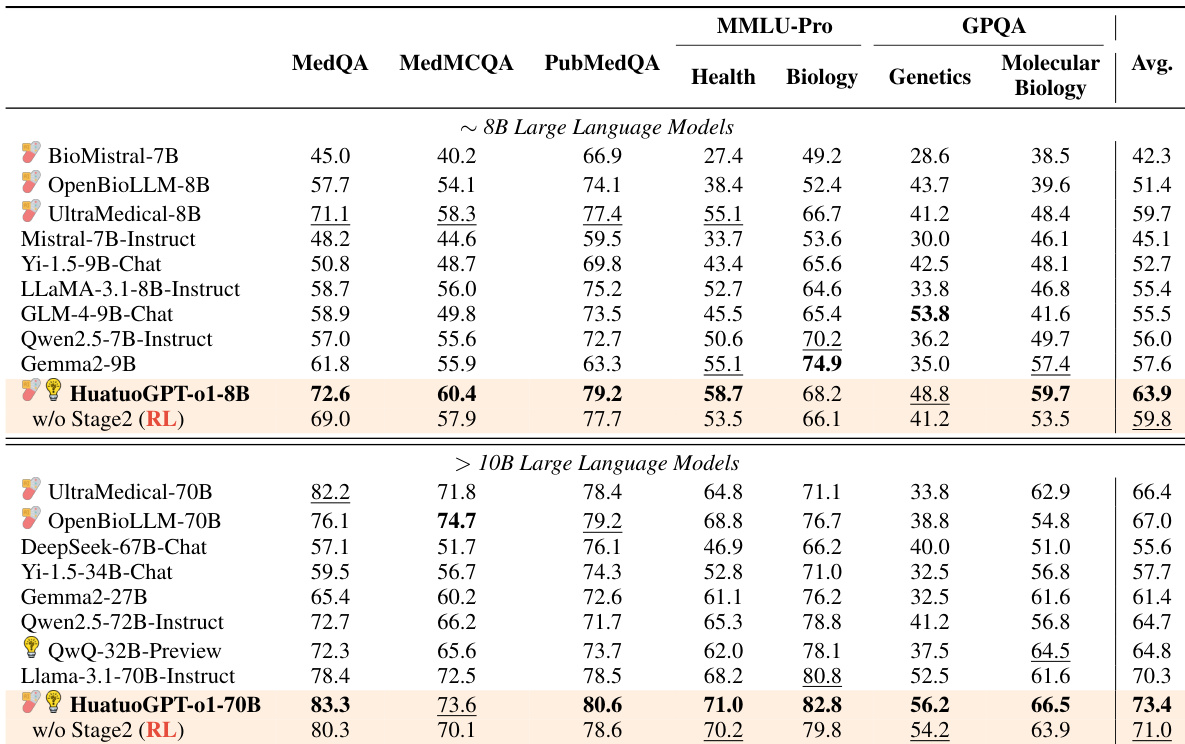
作者在医疗基准上评估各种大语言模型,表明他们的模型 HuatuoGPT-o1 在多个数据集上取得了强劲结果。8B 和 70B 版本优于其他开源模型,特别是在需要推理和医疗知识的挑战性任务上。HuatuoGPT-o1 模型在大多数医疗基准上优于其他开源 LLM。70B 版本超越了专为高级推理能力设计的模型。性能提升归因于涉及复杂思维链和强化学习的两阶段训练策略。
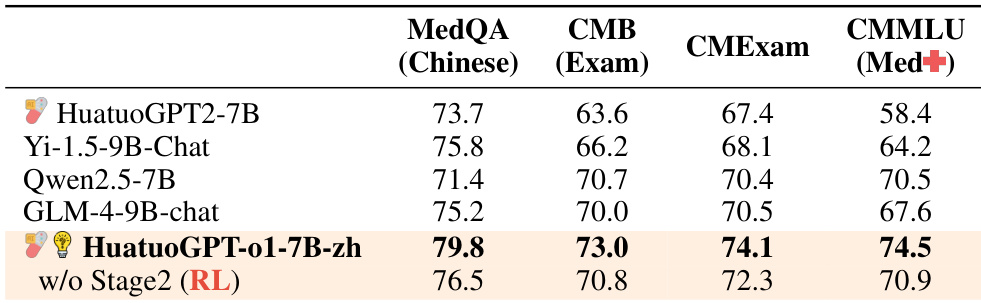
作者比较了各种中文医疗模型在多个基准上的性能,包括 MedQA、CMB、CMEExam 和 CMMLU。结果显示 HuatuoGPT-o1-7B-zh 在所有评估数据集上获得最高分数,展示了在中文医疗领域的强劲性能。HuatuoGPT-o1-7B-zh 在所有评估基准上优于其他中文医疗模型。该模型在比较的所有模型中在 CMMLU (Med+) 基准上获得最高分数。结果证明了训练方法在适应中文医疗领域方面的有效性。
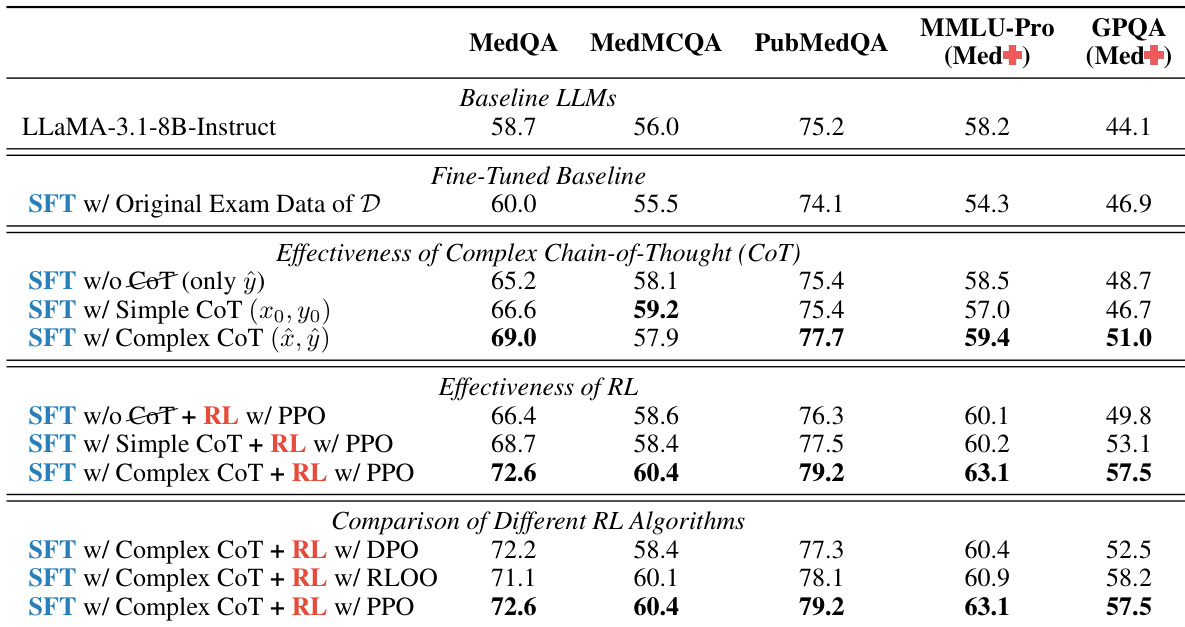
作者进行消融研究以评估不同推理策略和强化学习算法对医疗语言模型的有效性。结果显示,复杂思维链推理和基于 PPO 的强化学习相比简单方法显著提高了性能。复杂 CoT 推理导致比简单 CoT 和直接学习大幅性能提升。PPO 优于其他强化学习算法如 DPO 和 RLOO。复杂 CoT 和 PPO 的结合在所有基准上产生最高性能。
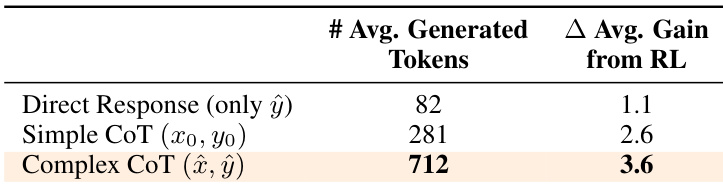
该表比较了不同推理策略在平均生成 tokens 和强化学习性能提升方面的表现。结果显示,复杂 CoT 生成最多的 tokens 并实现最高提升,表明其在增强模型性能方面的有效性。复杂 CoT 生成的 tokens 明显多于其他策略。复杂 CoT 从强化学习中获得最高性能提升。直接响应导致最低 token 生成和来自强化学习的最小提升。
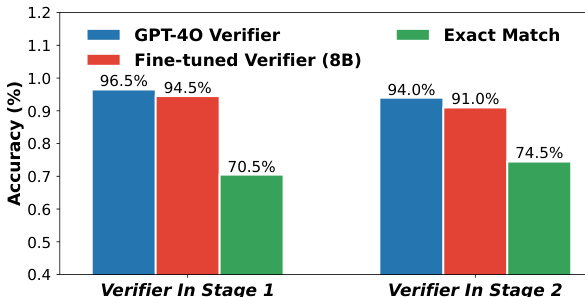
作者比较了两种验证器 GPT-4o 和微调 8B 模型在两个阶段的准确性。结果显示,GPT-4o 在两个阶段都实现了比微调验证器更高的准确性,在更具挑战性的第二阶段任务上性能差距显著。GPT-4o 验证器在两个阶段都优于微调验证器。两个验证器之间的性能差距在第二阶段扩大。微调验证器显示较低准确性,特别是在第二阶段。
作者在通用和中文特定医疗基准上评估 HuatuoGPT-o1,展示了优于现有开源模型的性能,特别是在推理密集型任务上。消融研究确认这些提升是由结合复杂思维链推理与基于 PPO 的强化学习的两阶段训练策略驱动的。此外,验证器比较表明 GPT-4o 保持比微调替代方案更高的准确性,特别是在具有挑战性的评估阶段。