Command Palette
Search for a command to run...
更智能、更优、更快、更长:一种面向快速、内存高效及长上下文微调与推理的现代双向编码器
更智能、更优、更快、更长:一种面向快速、内存高效及长上下文微调与推理的现代双向编码器
摘要
仅包含编码器的Transformer模型(如BERT)在检索与分类任务中,相较于更大的仅解码器模型,在性能与模型规模之间展现出优异的权衡。尽管BERT已成为众多生产系统中的核心组件,但自其发布以来,其性能改进始终有限,缺乏显著的帕累托优化。本文提出ModernBERT,将现代模型优化技术引入仅编码器架构,实现了对传统编码器模型的重大帕累托改进。ModernBERT在2万亿个标记上进行训练,原生支持8192的序列长度,在涵盖多种分类任务以及不同领域(包括代码)的单向量与多向量检索任务上均取得了当前最先进的性能表现。除了在下游任务中表现出色外,ModernBERT还是目前效率最高的编码器模型,在推理阶段对常见GPU具有极佳的运行速度与内存占用优化,具备出色的实用性与部署潜力。
一句话总结
Answer.AI、LightOn、约翰霍普金斯大学、NVIDIA 和 HuggingFace 的研究人员提出了 ModernBERT,这是一种在 2 万亿 token 上训练的、仅编码器的 Transformer 模型,原生支持 8192 长度的序列,实现了分类和检索任务在多个领域(包括代码)的最先进性能,同时在标准 GPU 上推理效率最高,通过现代架构优化超越了以往模型。
主要贡献
- ModernBERT 引入了面向仅编码器 Transformer 的现代化架构,解决了长期存在的序列长度(原生支持 8192 个 token)、模型效率和训练数据范围等限制,在多种任务上显著优于旧版 BERT 模型。
- 在包含代码数据的 2 万亿 token 上进行训练,ModernBERT 在 BEIR 基准套件的单向量(DPR)和多向量(ColBERT)检索任务中均达到最先进水平,超越了以往编码器模型在多个领域的语义搜索性能。
- 模型设计注重高推理效率,处理 8192 token 序列的速度接近之前模型的两倍,并发布了完整的训练检查点以及 FlexBERT,一个模块化框架,支持可复现的实验研究。
引言
仅编码器的 Transformer 模型在众多自然语言处理应用中仍居核心地位,尤其在信息检索和分类、命名实体识别等判别性任务中,因其高效性与性能-尺寸比优异而广受青睐。尽管大语言模型兴起,编码器模型仍在广泛应用——尤其是在检索增强生成(RAG)流程中——但多数系统仍依赖于 BERT 等过时架构,其存在上下文长度受限(512 token)、设计低效以及训练数据缺乏现代内容或代码相关数据等问题。此前的现代化尝试仅解决了训练效率或更长上下文等单一问题,未能兼顾性能与效率在多样化任务中的统一提升。本文作者提出 ModernBERT,一种重新设计的编码器模型,采用更高效的架构并在 2 万亿 token(含代码数据)上训练,实现了在检索、分类及代码相关任务上的最先进性能。该模型处理 8192 token 序列的速度接近先前模型的两倍,同时发布了 FlexBERT 模块化框架和所有中间训练检查点,以支持未来研究。
数据集
- 数据集包含约 2 万亿 token 的主要英文数据,来源多样,包括网页文档、代码仓库和科学文献,经过精心筛选,通过消融实验优化模型性能。
- 数据使用基于修改版 OLMo 分词器的现代 BPE 分词器进行处理,提升了分词效率和代码任务表现,同时保持与 BERT 特殊标记([CLS]、[SEP])及模板的向后兼容性。
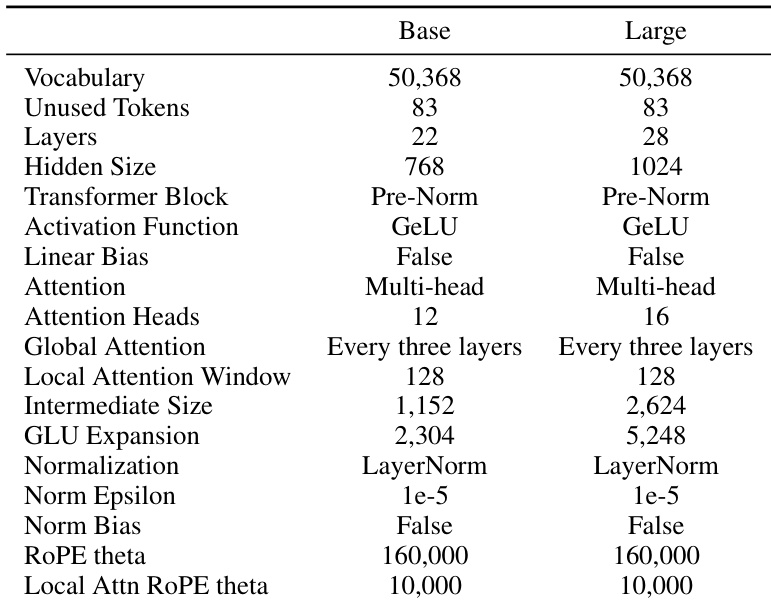
- 分词器词汇量设为 50,368(选择为 64 的倍数以优化 GPU 利用率),并额外保留 83 个未使用 token,以支持未来下游应用。
- 为最大化训练效率并确保一致的批处理大小,作者采用贪心算法的序列打包技术,实现超过 99% 的打包效率,显著降低因去填充(unpadding)导致的批大小波动。
- 为评估目的,创建了四个合成文档集,每组包含 8,192 个文档:两个固定长度集(每文档 512 token 和 8,192 token),以及两个长度可变集,分别来自以 256 和 4,096 token 为中心的正态分布,以模拟真实世界输入的多样性。
- 在单块 NVIDIA RTX 4090 GPU 上进行推理效率评估,通过十次运行测量每秒处理的 token 数,分别在标准设置和 xformers 增强设置下进行,以评估如去填充等优化技术的影响。
方法
作者采用现代化的仅编码器 Transformer 架构,在 BERT 基础设计之上融合近期进展,实现显著的性能与效率提升。整体框架在标准 Transformer 架构(Vaswani et al., 2017)基础上,引入一系列面向效率和硬件感知的架构改进。请参考框架图以获取模型结构的高层次概览。
在架构优化方面,ModernBERT 采纳了多项成熟技术。所有线性层(除最终解码器线性层外)均禁用偏置项,所有 LayerNorm 中的偏置项也一并移除,使模型能将更多参数分配给线性变换。位置嵌入被旋转位置编码(RoPE)替代,其在短上下文和长上下文场景中均表现更优,跨框架实现高效,且便于上下文扩展。归一化采用预归一化结构,使用标准 LayerNorm,训练更稳定,并在嵌入层后加入 LayerNorm,同时移除第一注意力层中的首个 LayerNorm 以避免冗余。激活函数从 GeLU 升级为 GeGLU,这是一种门控线性单元变体,在近期研究中已展现出一致的实证优势。
为提升计算效率,ModernBERT 集成多项优化。注意力层交替使用全局注意力与局部注意力机制:每第三层采用 RoPE theta 为 160,000 的全局注意力,其余层则使用 128 token 滑动窗口注意力,RoPE theta 为 10,000。这种交替注意力策略在长程建模与计算效率之间取得平衡。模型还采用去填充技术,通过将序列拼接为单一锯齿状序列,在训练和推理阶段均消除填充 token,避免对语义空 token 的冗余计算。该技术基于 Flash Attention 的可变长度注意力与 RoPE 支持实现,高效处理未填充序列。Flash Attention 以混合方式使用:全局注意力层采用 Flash Attention 3,局部注意力层采用 Flash Attention 2,确保在不同硬件上的兼容性与性能。此外,利用 PyTorch 的 torch.compile 编译兼容模块,训练吞吐量提升约 10%,且开销极小。
模型设计具有明确的硬件感知性,旨在最大化 GPU 利用率,同时保持深层窄层架构。在相同参数量下,更深的窄层模型通常优于更浅更宽的模型,尽管可能带来更高的推理延迟。ModernBERT 通过设计 22 层(基础版)和 28 层(大型版)模型,在参数量分别为 1.49 亿和 3.95 亿时取得平衡。基础模型隐藏层大小为 768,GLU 扩展为 2,304;大型模型隐藏层大小为 1,024,GLU 扩展为 5,248。这些维度经过精心选择,以优化目标常见 GPU(包括 NVIDIA T4、A10、L4、RTX 3090、RTX 4090、A100 和 H100)上的张量核心与流式多处理器的分块处理效率。设计过程包含大量消融实验,以确保在该硬件集合上的最优性能,重点聚焦于推理效率。
实验
- 在 1.7 万亿 token 上训练 ModernBERT-base,掩码率为 30%,使用 StableAdamW 优化器和 1−sqrt 学习率衰减,通过从 ModernBERT-base 初始化权重和批量大小调度实现稳定训练与更快收敛。
- 通过将 RoPE theta 提升至 160,000 并额外训练 3000 亿 token,将 ModernBERT 的上下文长度扩展至 8192 token,实现检索与分类任务的均衡性能。
- 在 GLUE 基准测试中,ModernBERT-base 超越所有现有基础模型,包括 DeBERTaV3-base,成为首个实现此突破的 MLM 训练模型;ModernBERT-large 以 10 倍更少参数达到接近 DeBERTaV3-large 的性能。
- 在短上下文检索(BEIR)中,两个 ModernBERT 变体均超越现有编码器,包括 GTE-en-MLM 和 NomicBERT,其中 ModernBERT-large 尽管参数更少(395M vs. 435M),仍取得更大领先优势。
- 在长上下文检索(MLDR)中,ModernBERT 超越短上下文模型,并在多向量设置中达到或超过 GTE-en-MLM 性能,NDCG@10 至少领先 9 分,归因于长预训练与局部注意力的协同效应。
- 在代码相关任务(CodeSearchNet、StackQA)中,ModernBERT 超越所有其他模型,展现出强大的代码理解能力,源于其在编程数据上的训练。
- ModernBERT 整体效率最高:处理 512 token 输入速度超过近期编码器,处理 8192 token 输入时,基础版快 2.65 倍,大型版快 3 倍,长上下文下吞吐量提升 98.8–118.8%,得益于局部注意力。
- ModernBERT 实现最高内存效率,在基础版支持的批处理大小是其他模型的两倍,大型版至少大 60%,且内存使用显著低于 DeBERTaV3。
结果表明,ModernBERT 在短上下文与长上下文检索任务中均超越所有其他模型,在固定长度与可变长度设置下均取得最高得分。ModernBERT 还展现出卓越的内存与推理效率,处理 token 更快,支持更大的批处理规模。
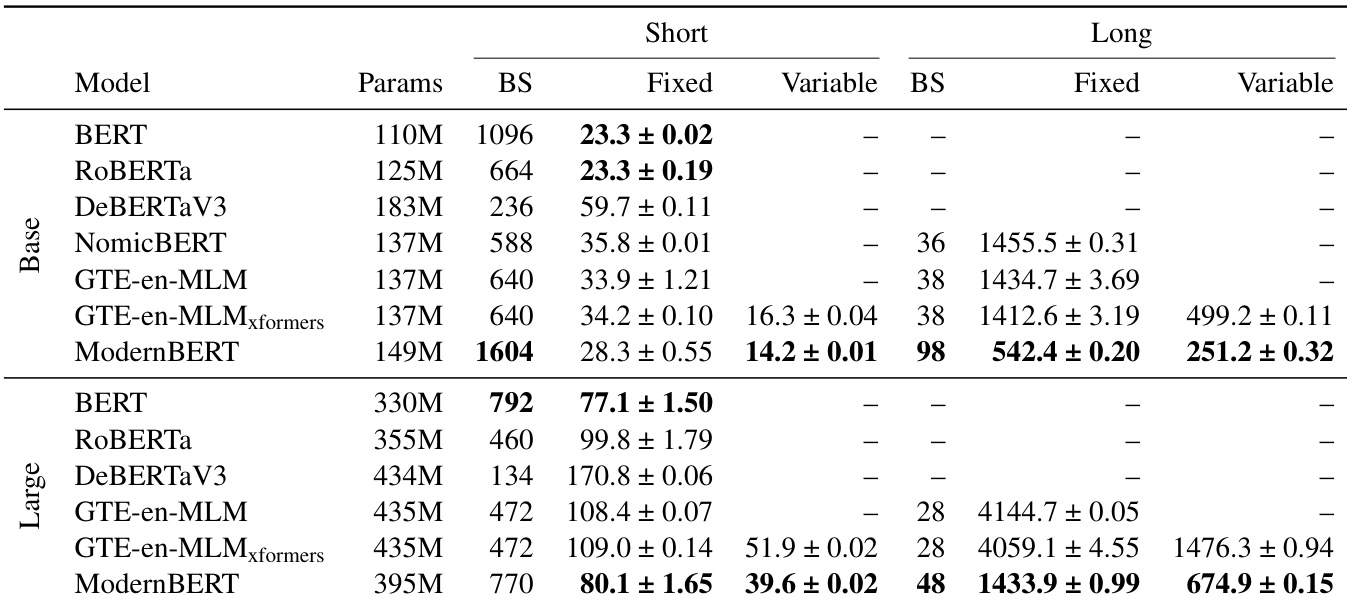
结果表明,ModernBERT 在短上下文与长上下文设置下均实现最高内存效率与推理速度。ModernBERT-base 处理固定长度输入比 GTE-en-MLM-base 快 14.5–30.9%,并能处理两倍大的批处理;ModernBERT-large 处理长上下文输入速度是次快编码器的 2.65 倍,且在内存效率上保持显著优势。
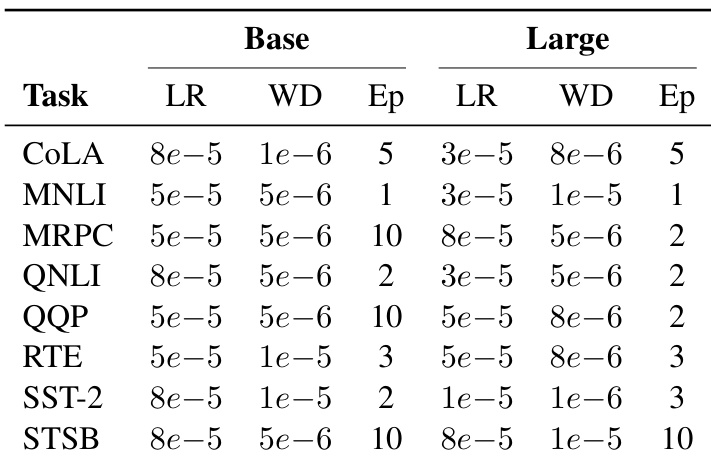
作者通过超参数搜索确定 ModernBERT 在 GLUE 任务上的最优训练设置,学习率范围为 5e-5 至 8e-5,权重衰减值在 1e-6 至 5e-6 之间,训练轮次根据任务在 1 至 10 轮之间调整。结果表明,ModernBERT 在所有 GLUE 基准测试中均表现强劲,基础模型超越所有现有基础模型,大型模型在大型编码器中排名第二。
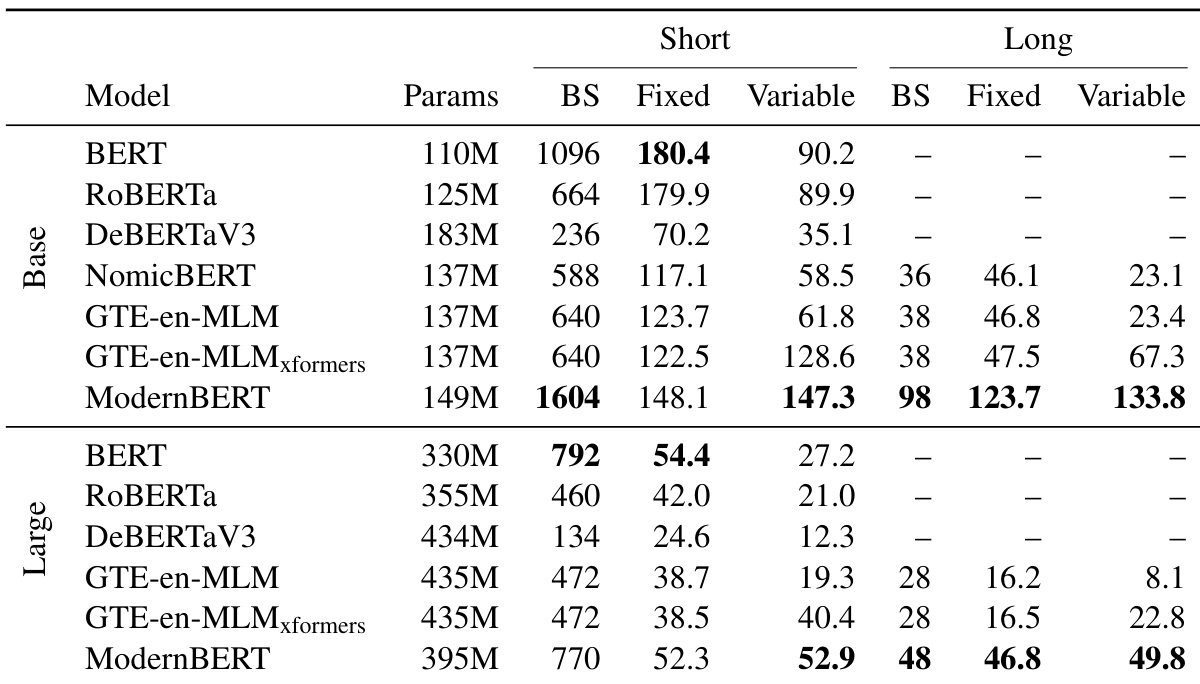
作者采用改进的梯形学习率调度(1−sqrt 衰减)与 StableAdamW 优化器训练 ModernBERT,在下游任务中取得优异表现。结果表明,ModernBERT 在自然语言理解与检索任务中均超越现有模型,尤其在长上下文场景下,内存与推理速度方面表现出显著效率提升。
结果表明,ModernBERT 在所有评估任务中平均得分最高,无论基础版还是大型版均超越所有其他模型。ModernBERT-base 在 GLUE 上超越所有现有基础模型,ModernBERT-large 在长上下文检索与自然语言理解任务中表现强劲,在多数任务上取得最佳结果,尽管其参数量少于竞争对手。
