Command Palette
Search for a command to run...
HunyuanVideo: 大规模视频生成模型的系统性框架
HunyuanVideo: 大规模视频生成模型的系统性框架
Hunyuan Foundation Model Team
摘要
视频生成领域的最新进展已深刻改变了个人生活及各行各业。然而,领先的视频生成模型目前仍处于闭源状态,这导致业界与开源社区在视频生成能力上存在巨大的性能差距。在本报告中,我们推出了 HunyuanVideo,这是一款新型开源视频基础模型(video foundation model)。其视频生成性能不仅可与领先的闭源模型相媲美,甚至在某些方面更具优势。HunyuanVideo 拥有一个综合性的框架,集成了多项核心贡献,包括数据清洗(data curation)、先进的架构设计、渐进式模型扩展(progressive model scaling)与训练,以及旨在促进大规模模型训练与推理的高效基础设施。凭借这些技术,我们成功训练出了一个参数量超过 130 亿的视频生成模型,使其成为目前所有开源模型中规模最大的一个。我们进行了广泛的实验,并实施了一系列针对性设计,以确保模型具备高视觉质量、动态运动效果、精准的文本-视频对齐(text-video alignment)以及先进的电影级拍摄技巧。根据专业的真人评估结果,HunyuanVideo 的表现超越了此前的 SOTA(state-of-the-art)模型,包括 Runway Gen-3、Luma 1.6 以及三款表现顶尖的中文视频生成模型。通过发布该基础模型的代码及其应用,我们的目标是弥合闭源社区与开源社区之间的鸿沟。这一举措将赋能社区中的每一个人去实践他们的创意,从而培育一个更加动态、更具活力的视频生成生态系统。
一句话总结
Hunyuan Foundation Model 团队推出了 HunyuanVideo,这是一个拥有 130 亿参数的开源视频基础模型。该模型利用数据清洗、先进架构、渐进式扩展和高效基础设施的系统化框架,实现了极高的视觉质量和运动动态,在专业人工评估中表现优于 Runway Gen-3 和 Luma 1.6 等闭源模型。
核心贡献
- 本研究推出了 HunyuanVideo,这是一个拥有超过 130 亿参数的开源视频基础模型,采用了涵盖数据清洗、先进架构设计和渐进式扩展的全面框架。专业人工评估表明,该模型的性能可与 Runway Gen-3 和 Luma 1.6 等领先的闭源模型相媲美或更优。
- 论文提出了一种文本引导蒸馏方法,将条件输入和无条件输入的组合输出压缩到单个学生模型中。该方法解决了无分类器引导(classifier-free guidance)计算成本高的问题,并在推理过程中实现了约 1.9 倍的加速。
- 研究开发了一个视频转音频(V2A)模块,旨在自主生成与输入视频同步的电影级拟音(foley audio)和背景音乐。该模块通过弥合视觉生成与听觉真实感之间的差距,实现了凝聚力强的多媒体体验合成。
引言
高质量视频生成对于行业转型至关重要,但在专有闭源模型与现有的开源替代方案之间存在显著的性能差距。虽然扩散模型推动了图像生成的进步,但视频领域仍缺乏强大的开源基础模型,这限制了社区驱动的算法创新。本研究推出了 HunyuanVideo,这是一个可以与领先商业系统竞争的系统化框架及 130 亿参数开源基础模型。通过利用优化的扩展策略、先进的架构设计和高效的训练基础设施,实现了卓越的视觉质量、运动动态和文本-视频对齐。
数据集
-
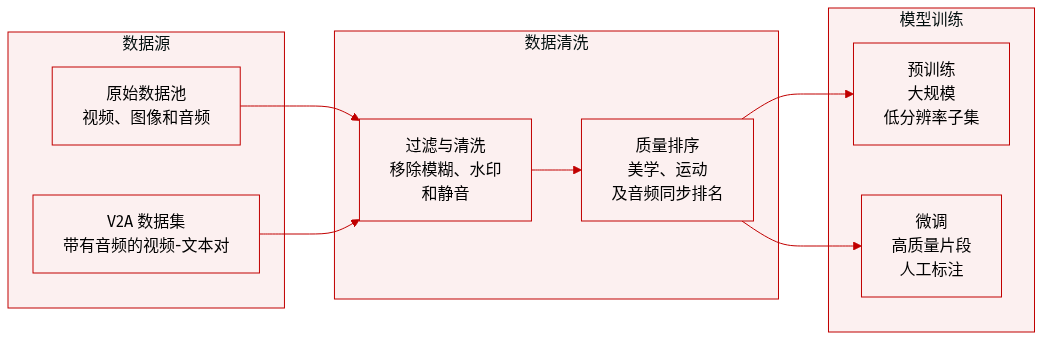
数据集组成与来源 采用了图像与视频联合训练策略。原始视频池涵盖了人物、动物、植物、风景、车辆、物体、建筑和动画等多种领域。对于图像训练,从数十亿个图像-文本对池开始。此外还构建了一个独立的视频转音频(V2A)数据集,由带有相应音频流的视频-文本对组成。
-
各子集的关键细节
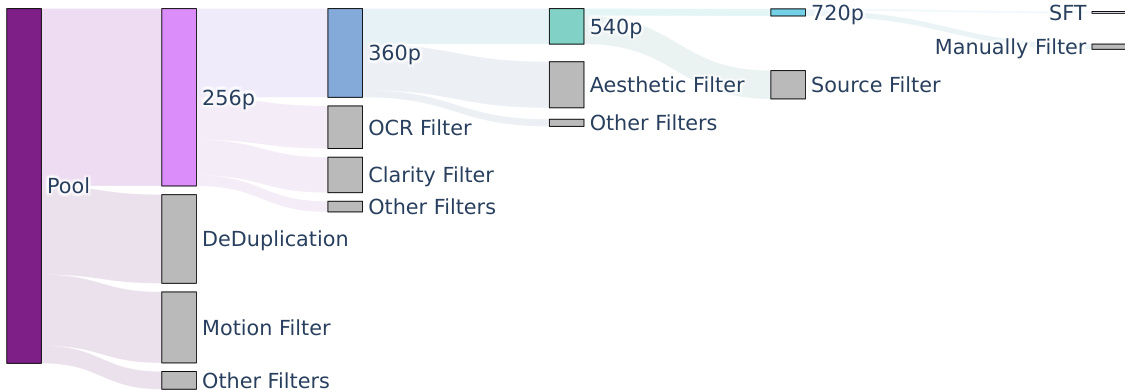
- 视频子集: 通过分层过滤流水线创建了五个不同的视频训练数据集。这些子集的空间分辨率逐渐增加,范围从 256p (256 x 256 x 65) 到 720p (720 x 1280 x 129)。
- 图像子集: 通过提高过滤阈值构建了两个图像数据集。第一个包含数十亿个样本用于初始文本到图像预训练,第二个包含数亿个样本用于第二阶段预训练。
- 微调数据集: 通过人工标注构建了一个包含约 100 万个样本的专门视频微调数据集,专注于高视觉美感和引人入胜的运动。
- V2A 子集: 对于音频训练,保留了约 250,000 小时用于预训练,并构建了一个包含数百万个高质量片段(80,000 小时)的精选子集用于监督微调。
-
数据处理与过滤
- 视频预处理: 使用 PySceneDetect 将原始视频分割成单镜头片段。利用拉普拉斯算子识别清晰的起始帧,并使用内部 VideoCLIP 模型计算嵌入(embeddings),用于去重和 k-means 概念重采样(目标为 10K 中心点)。
- 分层过滤: 多阶段流水线根据视觉美感(通过 Dover)、清晰度(去除模糊)、运动速度(通过光流)和内容进行数据过滤。该流水线还使用 OCR 来移除过多的文本或字幕,并使用类 YOLOX 模型来检测并移除水印、Logo 或边框。
- 音频过滤: 对于 V2A,移除了没有音频或静音比例超过 80% 的视频。将音频分为四类:纯声音、带语音的声音、带音乐的声音和纯音乐。使用视听一致性评分来确保视听对齐。
-
元数据与特征提取
- 字幕生成(Captioning): 对于 V2A,使用声音和音乐字幕模型生成描述,然后将其合并为结构化字幕格式。
- 视觉特征: 使用 CLIP 以 4 fps 的时间分辨率提取视觉特征,然后进行重采样以与音频帧率对齐。
方法
HunyuanVideo 框架被设计为一个全面的流水线,涵盖从数据预处理到大规模模型训练及多种下游应用的过程。流程始于数据预处理,原始图像和视频池经过严格的数据过滤和结构化字幕生成,以确保高质量的训练信号。
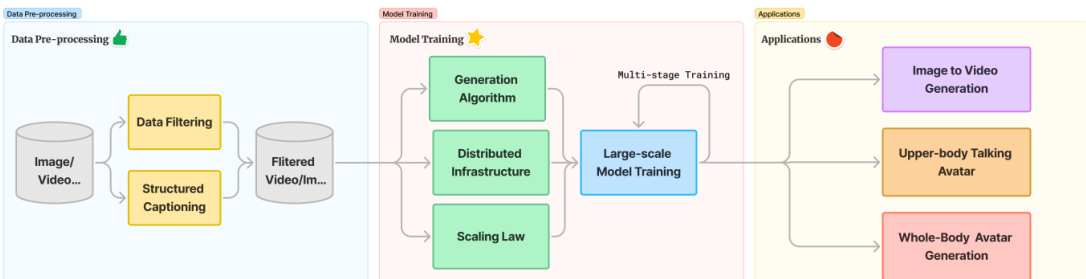
模型训练阶段采用多阶段方法,结合了生成算法、分布式基础设施和扩展定律(scaling law)实验来优化性能。该阶段为各种应用提供支持,例如图像到视频生成和数字人动画。
为了实现高效的视频处理,采用了 3D 变分自编码器(3DVAE)。该组件使用 CausalConv3D 将像素空间的视频和图像压缩到紧凑的潜空间(latent space)。对于维度为 (T+1)×3×H×W 的视频,3DVAE 生成形状为 (ctT+1)×C×(csH)×(csW) 的潜特征,其中 ct=4,cs=8,C=16。这种压缩允许随后的扩散 Transformer 在保持高原始分辨率的同时,在减少的 token 数量上进行操作。
生成过程的核心是统一的图像和视频生成架构,该架构使用 Diffusion Transformer (DiT) 作为骨干网络。模型采用了“双流到单流”的混合设计。在初始的双流阶段,视频和文本 token 通过 Transformer 块进行独立处理,使每种模态能够学习特定的调制机制。随后,在单流阶段,将 token 进行拼接以实现深度多模态融合。为了支持不同的分辨率和长宽比,采用了 3D 旋转位置嵌入(RoPE),通过将特征通道划分为分段 dt、dh 和 dw,将标准 RoPE 扩展到时间、高度和宽度维度。
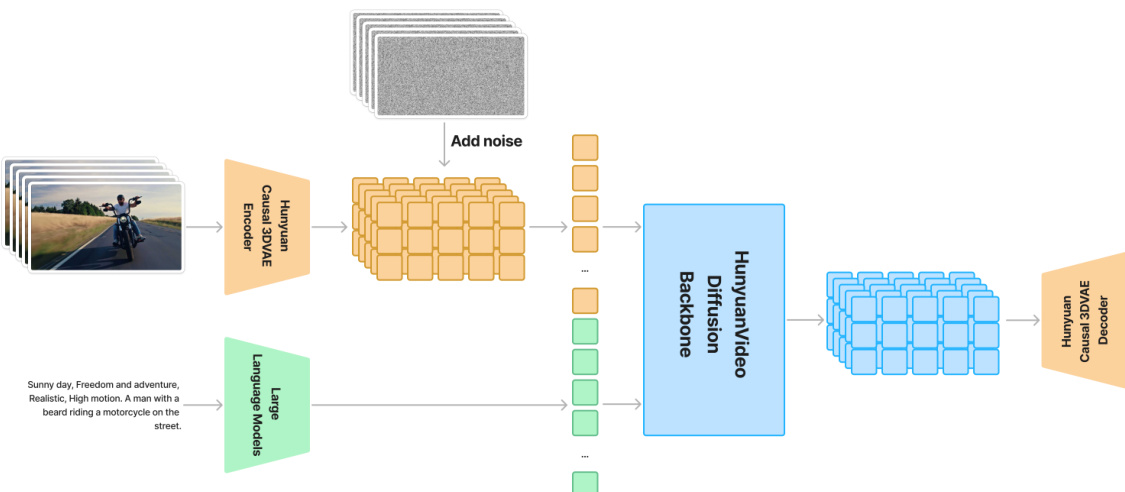
文本引导由预训练的多模态大语言模型(MLLM)担任文本编码器提供。与传统的双向编码器不同,该 MLLM 使用仅解码器(decoder-only)结构,研究通过增加一个额外的双向 token 精炼器来增强其文本引导能力。此外,还从 CLIP 模型中提取全局信息并集成到 DiT 模块中。

训练过程受流匹配(Flow Matching)框架控制。给定潜表示 x1,模型预测速度 vt 以引导样本 xt 朝向地面真值 ut。目标是最小化均方误差:
Lgeneration=Et,x0,x1∥vt−ut∥2
为了确保收敛和高质量输出,采用了渐进式课程学习策略。这从低分辨率(256px)的图像预训练开始,逐步扩展到更高分辨率和更长时间的视频-图像联合训练。
实验
通过架构验证、扩展定律分析和下游应用测试,评估了 HunyuanVideo 框架的性能和可扩展性。实验证实,所提出的 3D VAE 和时空分块(spatial-temporal tiling)策略能够实现高分辨率视频处理,具有卓越的重建质量和极少的伪影。针对图像和视频模型的系统性扩展定律研究实现了模型大小和数据集配置的优化,而人工评估表明,与最先进的基准模型相比,该模型在文本对齐、运动动态和概念泛化方面表现出色。此外,微调实验表明,该基础模型可以有效地适配于特定任务,如肖像动画和完全可控的多信号数字人生成。
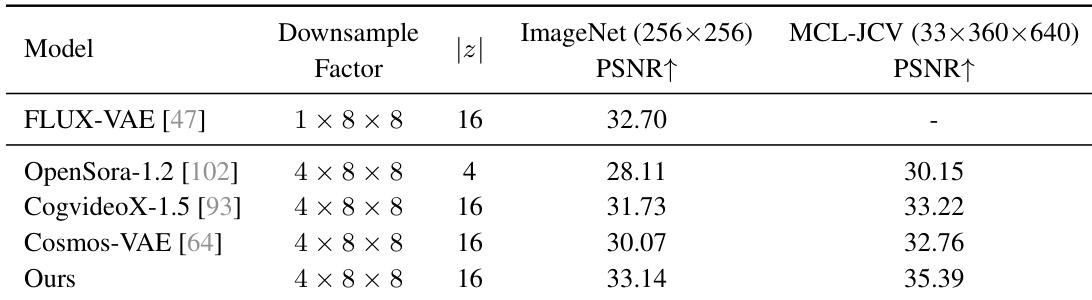
通过使用 ImageNet 和 MCL-JCV 数据集,将该 VAE 与几种开源最先进模型进行了对比。结果显示,所提出的模型在图像和视频基准测试中均实现了更高的重建质量。在视频数据的 PSNR 方面,该模型优于现有的视频 VAE。在图像重建方面,该模型的表现优于视频专用和图像专用 VAE。该方法在保持具有竞争力的下采样因子的同时,实现了更高的重建指标。
通过专业评估人员在多个标准下对 HunyuanVideo 与五个闭源基准模型进行了评估。结果显示,所提出的模型实现了最高的整体性能,并在对比方法中排名第一。与所有基准模型相比,HunyuanVideo 在整体性能方面取得了最高排名。相对于其他评估的视频生成模型,该模型表现出更优越的运动质量。所提出的方法在文本对齐和视觉质量评分方面保持了竞争力。

通过在 ImageNet 和 MCL-JCV 数据集上的重建基准测试,以及针对多个最先进基准模型的人工专业评估,对所提出的 VAE 和 HunyuanVideo 模型进行了评估。该 VAE 在保持具有竞争力的下采样因子的同时,展示了卓越的图像和视频重建质量。此外,与现有模型相比,HunyuanVideo 实现了顶尖的整体性能,特别是在运动质量、文本对齐和视觉保真度方面表现出色。