Command Palette
Search for a command to run...
VIRES:基于草图与文本引导生成的视频实例重绘
VIRES:基于草图与文本引导生成的视频实例重绘
Shuchen Weng Haojie Zheng Peixuan Zhang Yuchen Hong Han Jiang Si Li Boxin Shi
摘要
我们提出VIRES,一种基于草图与文本引导的视频实例重绘方法,能够实现视频实例的重绘、替换、生成与删除。现有方法在时间一致性以及与所提供草图序列的精确对齐方面仍面临挑战。VIRES利用文本到视频模型的生成先验,有效保持时间一致性并生成视觉上令人满意的输出结果。我们提出一种标准化自缩放的序列化ControlNet,可高效提取结构布局,并自适应地捕捉高对比度草图细节。此外,我们通过引入草图注意力机制,增强扩散Transformer主干网络,以更好地解析并注入细粒度的草图语义信息。一个草图感知编码器确保重绘结果与输入草图序列保持精准对齐。同时,我们构建了VireSet数据集,该数据集包含针对视频实例编辑方法训练与评估而精心标注的详细信息。实验结果表明,VIRES在视觉质量、时间一致性、条件对齐性以及人工评分方面均显著优于现有最先进方法。项目主页:https://hjzheng.net/projects/VIRES/
一句话总结
北京大学、OpenBayes 和北京邮电大学的作者提出 VIRES,一种基于草图和文本引导的视频实例编辑模型,通过将序列化 ControlNet 与自适应缩放和草图注意力机制整合到扩散变换器中,实现高保真度的重绘、替换、生成和删除,确保时间一致性与精确的条件对齐,在新提出的 VIRESSET 数据集上超越了先前方法。
主要贡献
- VIRES 通过引入基于扩散变换器(DiT)的框架,解决了视频实例编辑中时间不一致和草图对齐不准确的问题,利用预训练的文本到视频生成先验,实现具有草图和文本引导的一致性、高质量视频编辑。
- 该方法提出一种带有标准化自缩放的序列化 ControlNet,用于提取结构布局并自适应捕捉高对比度草图细节,同时结合草图注意力机制和草图感知编码器,将细粒度草图语义注入潜在空间,并在生成过程中确保对齐。
- VIRES 在新提出的 VIRESSET 数据集上进行了评估,该数据集包含 8.5 万条训练视频和 1 千条评估视频,配有大语言模型生成的文本和基于 HED 的草图序列,其在视觉质量、时间一致性、条件对齐和人类偏好方面均优于当前最先进方法。
引言
视频实例编辑能够对视频中的特定对象进行精确、内容感知的修改,广泛应用于电影制作、内容创作和视觉特效领域。然而,现有方法在保持时间一致性以及准确对齐用户提供的引导信息方面仍面临挑战——尤其是在使用草图进行细粒度控制时。现有方法要么依赖零样本文本到图像模型,导致闪烁和不一致的结果;要么通过微调模型,但难以保留详细的草图对齐。作者提出 VIRES,一种基于扩散变换器的框架,利用文本到视频模型的生成先验,实现高时间一致性。他们提出一种带有标准化自缩放的序列化 ControlNet,以实现鲁棒的结构提取;引入草图注意力机制,将细粒度草图语义注入潜在空间;并设计草图感知编码器,确保与多层级纹理特征对齐。此外,他们发布了 VIRESSET,一个大规模数据集,包含 8.5 万条训练视频和 1 千条评估视频,配有文本和草图序列标注,为视频实例编辑方法的更有效训练与评估提供了支持。
数据集
- 该数据集名为 VIRESSET,专为训练和评估视频实例编辑方法而设计,解决了现有数据集在时间不一致性和视觉外观变化方面的局限性。
- 数据最初来源于 SA-V,一个涵盖室内(54%)和室外(46%)场景的多样化视频集合,由来自 47 个国家的多位贡献者录制,原始视频平均时长为 14 秒,分辨率为 1401 × 1037 像素。
- 实例掩码最初以 6 FPS 提供,通过人工和自动标注完成,作者使用预训练的 SAM-2 模型生成中间帧的掩码,以提升时间一致性,将标注率提高至 24 FPS。
- 对实例进行筛选,仅保留覆盖帧面积至少 10% 且连续存在至少 51 帧的实例;从中随机采样 51 帧的片段。
- 每个选定实例在其边界框周围添加小边距后裁剪,并缩放至 512 × 512 分辨率,以标准化模型训练输入。
- 生成额外标注:使用预训练的 PLLaVa 模型生成视觉外观的文本描述,通过 HED 边缘检测提取草图序列,以提供结构引导。
- 由 10 名志愿者对 1% 的样本进行质量检查,接受率为 91%。
- 最终数据集包含 85,000 条训练片段和 1,000 条评估片段,每条片段包含 51 帧,帧率为 24 FPS,对应 512 × 512 分辨率图像、草图序列和文本描述。
方法
VIRES 框架作为一个条件视频生成系统,利用草图和文本引导在视频片段中重绘特定实例。整体流程从输入编码开始:原始视频片段 x 通过预训练的时空 VAE 编码器 Ex 压缩为潜在表示 z。同时,草图序列 s 由序列化 ControlNet Fs 处理以提取结构布局,文本描述 y 通过预训练文本编码器 Fy 转换为词嵌入 fy。这些条件特征随后被注入去噪网络,以引导生成过程。
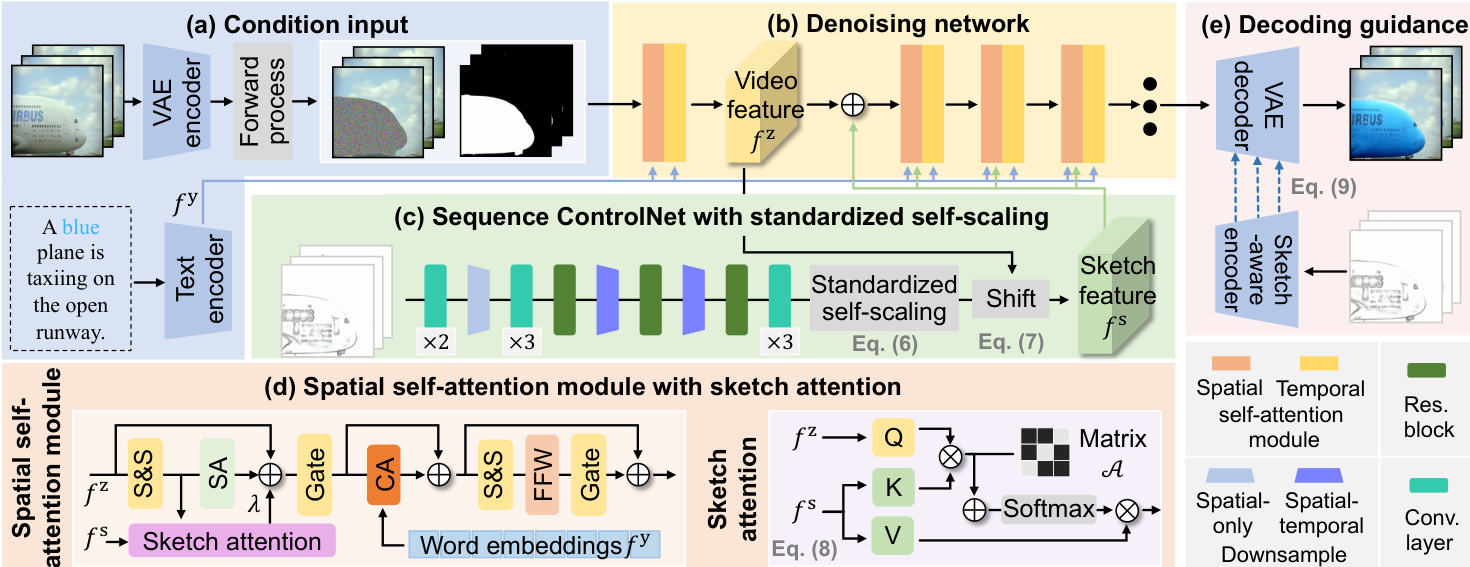
去噪网络基于 DiT 主干,由堆叠的 Transformer 块构成,包含空间和时间自注意力模块,用于建模帧内与帧间依赖关系。前向扩散过程在潜在码 z 与高斯噪声 ϵ 之间沿线性路径进行,定义为 z^t=tz+(1−t)ϵ,其中 t∈[0,1]。为实现实例级重绘,应用潜在掩码步骤:zt=z^t⊙m^+z⊙(1−m^),其中 m^ 为下采样后的实例掩码。反向扩散过程由常微分方程(ODE)控制:dz/dt=vθ(zt,t,s,m,y),其中 vθ 为估计的向量场。模型使用流匹配目标进行训练,最小化损失 Lfm=Et,z,ϵ[∥vt(zt)−vθ(zt,t,s,m,y)∥2],目标速度为 vt=z−ϵ。
序列化 ControlNet 旨在从草图序列中提取结构布局,同时确保时间一致性。其采用 3D 因果卷积、残差块和下采样层以捕捉时空依赖性。网络逐步增加通道数以匹配 DiT 主干的特征维度,最终层保持高通道数以保留结构细节。为自适应捕捉高对比度草图特征,引入标准化自缩放模块。该过程首先对草图特征 fs 进行标准化:f^s=((fs−μ(fs))/σ(fs))⊙fs,然后通过 fˉs=f^s−μ(f^s)+μ(fz) 将其均值与视频特征 fz 对齐。该调制仅应用于 DiT 主干的第一个 Transformer 块,以降低计算开销。
为进一步将细粒度草图语义注入潜在空间,草图注意力机制被集成到每个 Transformer 块(除第一个外)的空间自注意力模块中。该机制以并行分支实现,使用预定义的二值矩阵 A 表示潜在码与草图特征之间的对应关系,计算注意力得分。注意力机制定义为 fˉz=Softmax((QK⊤+A)/C)V,其中 Q、K 和 V 为来自视频和草图序列的变换特征。草图注意力输出通过可学习参数 λ 缩放后,加到主注意力输出上。
在解码阶段,引入草图感知编码器,以提供多层级纹理特征,指导时空 VAE 解码器。该编码器与 VAE 编码器采用相同架构,从草图序列在每个下采样层级提取纹理特征。这些特征随后在对应层级添加到解码器输出中:D(z′,Es(s))i=Es(s)i+D(z′)i。草图感知编码器使用组合损失函数 Lvae=∑iLsm+λ1L1+λ2Lpc+λ3Lkl 进行训练,包含 SSIM、L1、感知和 KL 损失,以确保结构对齐、重建保真度、清晰度和正则化。
实验
- 在 8 块 H100 GPU 上,使用预训练的时空 VAE 和 DiT 主干对 VIRES 进行训练,采用三阶段训练流程:草图感知编码器训练(22K 步)、序列化 ControlNet 与自缩放训练(35K 步)、全模型微调(45K 步),使用 Adam 优化器,学习率为 1×10−5。
- 在 VIRESET 和 DAVIS 数据集上进行验证,从每个数据集中随机选取 50 个视频用于评估。
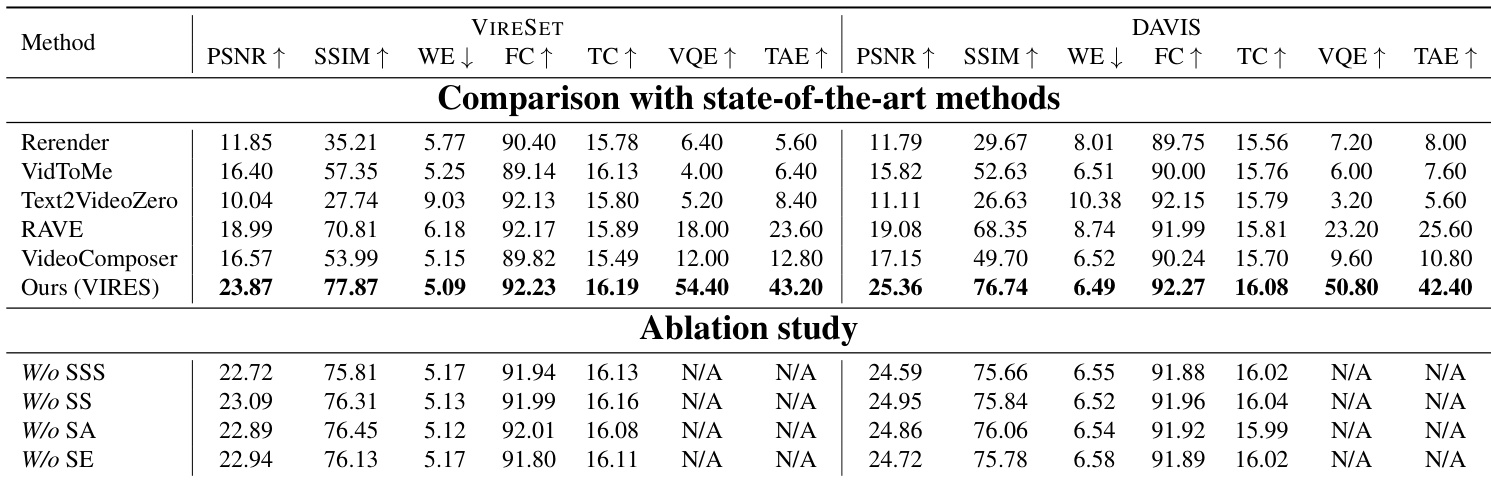
- 在五个指标(PSNR、SSIM、Warp Error(WE)、Frame Consistency(FC)、Text Consistency(TC))上均达到最先进性能,优于 VideoComposer、Text2Video-Zero、Rerender、VidToMe 和 RAVE 在两个数据集上的表现。
- 在 Amazon Mechanical Turk 上进行用户研究,VIRES 在视觉质量和文本对齐偏好方面得分最高。
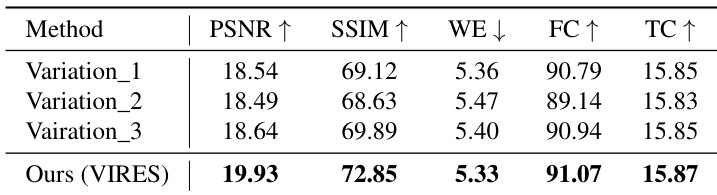
- 消融研究证实关键组件的必要性:标准化自缩放(SSS)、自缩放(SS)、草图注意力(SA)和草图感知编码器(SE),移除任一组件均导致纹理失真、细节丢失或对齐错误。
- 扩展应用包括从零开始的草图到视频生成、稀疏草图引导(最少仅需一帧草图即可有效)、以及通过迭代帧处理实现长时视频重绘。
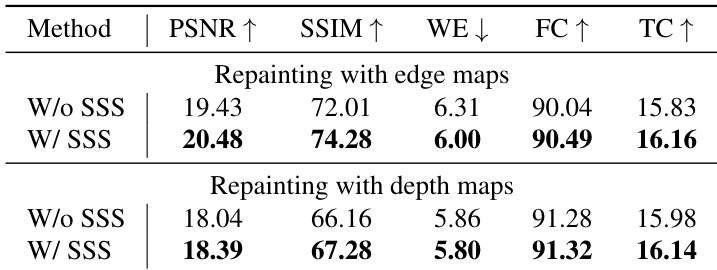
- 展示了对边缘图和深度图的泛化能力:SSS 在边缘图上显著提升性能(因高对比度过渡),但在更平滑的深度图上提升有限。
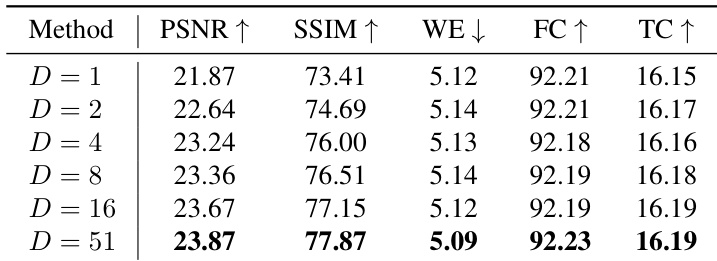
- 稀疏草图引导在不同间隔索引 d∈{0,…,4} 下表现稳健,即使仅使用一帧草图,仍保持高 PSNR、SSIM 和时间一致性。
结果表明,VIRES 在 VIRESET 和 DAVIS 两个数据集上的全部五个定量指标上均超越当前最先进方法,实现了最高的视觉感知质量、结构一致性、运动准确性、帧一致性和文本对齐得分。消融研究显示,移除任一关键组件——标准化自缩放、自缩放、草图注意力或草图感知编码器——均导致性能显著下降,凸显了各模块在有效视频重绘中的重要性。
作者使用预训练权重的时空 VAE 和 DiT 主干,在 8 块 H100 GPU 上以三阶段训练流程对 VIRES 模型进行训练,实现 512×512 分辨率的视频重绘。模型使用 Adam 优化器,学习率为 1×10−5,实验细节包括引入草图感知编码器、序列化 ControlNet 和草图注意力机制,以提升视频编辑性能。
结果表明,标准化自缩放(SSS)模块在使用边缘图和深度图进行视频重绘时显著提升性能。对于边缘图,采用 SSS 的模型在 PSNR、SSIM、FC 和 TC 指标上均优于无 SSS 的变体;而对于深度图,提升虽较温和,但在所有指标上均保持一致。
结果表明,VIRES 在所有五项指标上均优于基线变体,PSNR、SSIM、WE、FC 和 TC 均取得最佳表现。作者采用标准化自缩放方法提取条件特征,结果表明该方法显著优于更简单的替代方案,大幅提升了视频编辑质量。
结果表明,VIRES 在稀疏草图引导下仍保持高性能,即使仅使用一帧草图,也能达到接近最优的结果。模型展现出稳健的时间一致性与视觉质量,随着草图帧数增加,PSNR、SSIM 和 FC 指标保持稳定或进一步提升。