Command Palette
Search for a command to run...
Fish-Speech:利用 Large Language Models 实现先进的多语言 Text-to-Speech 合成
Fish-Speech:利用 Large Language Models 实现先进的多语言 Text-to-Speech 合成
Shijia Liao Yuxuan Wang Tianyu Li Yifan Cheng Ruoyi Zhang Rongzhi Zhou Yijin Xing
摘要
文本转语音(Text-to-Speech, TTS)系统在处理复杂的语言特征、处理多音字表达以及生成自然的多语言语音方面仍面临持续挑战,而这些能力对于未来的 AI 应用至关重要。在本文中,我们提出了 Fish-Speech,这是一个采用串行快慢双自回归(Dual-AR)架构的新型框架,旨在增强分组有限标量向量量化(Grouped Finite Scalar Vector Quantization, GFSQ)在序列生成任务中的稳定性。该架构在保持高保真输出的同时,提升了 codebook 的处理效率,使其在 AI 交互和语音克隆方面表现得尤为出色。Fish-Speech 利用 Large Language Models (LLMs) 进行语言特征提取,从而消除了对传统字形转音素(G2P)转换的需求,进而简化了 synthesis pipeline 并增强了多语言支持。此外,我们通过 GFSQ 开发了 FF-GAN,实现了卓越的压缩率和接近 100% 的 codebook 利用率。我们的方法解决了当前 TTS 系统的关键局限性,并为更先进、具备上下文感知能力的语音合成奠定了基础。实验结果表明,Fish-Speech 在处理复杂语言场景和语音克隆任务方面显著优于基准模型,展示了其推动 AI 应用中 TTS 技术进步的潜力。
一句话总结
作者提出了 Fish-Speech,这是一种新型的多语言文本转语音框架,利用串行快慢 Dual-AR 架构来增强 Grouped Finite Scalar Vector Quantization 的稳定性,并利用 Large Language Models 进行语言特征提取以消除传统的 G2P 转换,通过 FF-GAN 实现高保真语音克隆和卓越的压缩效果。
核心贡献
- 本文介绍了 Fish-Speech,该框架具有串行快慢 Dual Autoregressive (Dual-AR) 架构,旨在提高序列生成过程中 Grouped Finite Scalar Vector Quantization (GFSQ) 的稳定性。
- 该工作实现了一种非字形转音素 (non-G2P) 结构,利用 Large Language Models (LLMs) 进行语言特征提取,从而简化了合成流水线并增强了多语言支持。
- 研究人员通过 GFSQ 开发了 FF-GAN,实现了卓越的压缩率和接近 100% 的 codebook 利用率,使系统在复杂语言场景和语音克隆任务中优于基准模型。
引言
高质量的文本转语音 (TTS) 系统对于推进 AI 交互、语音克隆和多语言虚拟助手至关重要。传统架构通常依赖于字形转音素 (G2P) 转换,这在处理依赖上下文的多音字时面临困难,并且需要复杂的、特定语言的语音规则,从而阻碍了扩展性。此外,许多现有解决方案必须在语义理解和声学稳定性之间进行权衡,这可能会限制其在语音克隆中的有效性。作者利用了一种新型的 Fish-Speech 框架,该框架利用 Large Language Models (LLMs) 直接进行语言特征提取,有效地消除了对 G2P 转换的需求。主要贡献是串行快慢 Dual Autoregressive (Dual-AR) 架构结合了新型 Firefly-GAN (FFGAN) 声码器,实现了高保真合成、接近 100% 的 codebook 利用率,并且比传统的 DiT 或 Flow-based 结构具有显著更低的延迟。
数据集
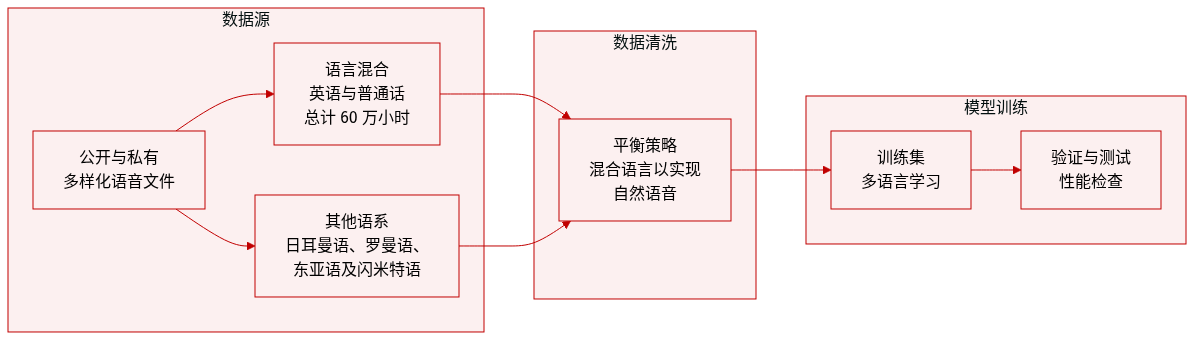
作者构建了一个庞大的多语言语音数据集,总计约 720,000 小时,数据来源于公共仓库和私有数据采集的结合。
- 数据集组成与来源: 该集合由多样化的公共来源和内部数据采集过程构建,以确保高度的多样性。
- 子集详情:
- 英语和普通话: 作为主要组成部分,每种语言分配了 300,000 小时。
- 其他语系: 作者为日耳曼语系 (德语)、罗曼语系 (法语、意大利语)、东亚语系 (日语、韩语) 和闪米特语系 (阿拉伯语) 各包含了 20,000 小时。
- 数据处理与策略: 作者在不同语言之间实施了精细的平衡策略。这种特定的分布旨在促进同步多语言学习,并提高模型生成自然混合语言内容的能力。
方法
Fish-Speech 框架被设计为一个高性能的文本转语音 (TTS) 系统,能够处理多情感和多语言语音合成。作者采用了一种层级化方法,将双自回归架构与先进的向量量化技术相结合,以确保稳定性和效率。
系统的核心是 Dual Autoregressive (Dual-AR) 架构,它通过两个顺序的 transformer 模块处理语音信息:Slow Transformer 和 Fast Transformer。如 Dual-AR 框架的架构概览所示:
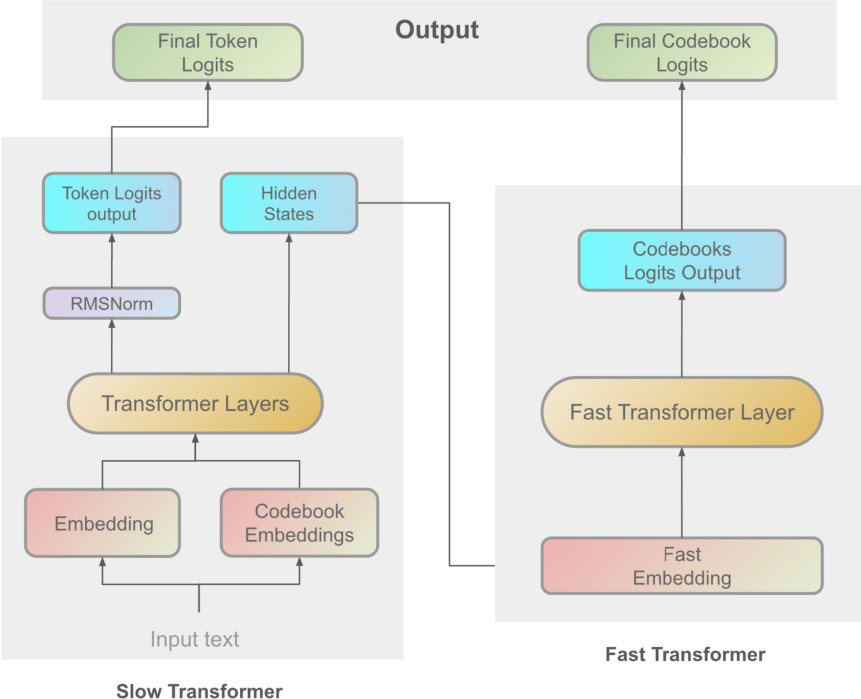
Slow Transformer 在高层抽象水平上运行,接收输入文本 embeddings 以捕获全局语言结构和语义内容。它生成中间隐藏状态 h,并通过以下变换预测语义 token logits z:
h=SlowTransformer(x)z=Wtok⋅Norm(h)其中 Norm(⋅) 表示层归一化,Wtok 表示 token 预测层的可学习参数。随后,Fast Transformer 通过处理详细的声学特征来细化输出。它将隐藏状态 h 与 codebook embeddings c 的拼接序列作为输入:
h~=[h;c],(hfast)
hfast=FastTransformer(h~,(hfast))
y=Wcbk⋅Norm(hfast)
其中 Wcbk 包含 codebook 预测的可学习参数,y 表示生成的 codebook logits。这种层级化设计增强了序列生成的稳定性并优化了 codebook 处理。
为了实现高效量化,作者引入了 Grouped Finite Scalar Vector Quantization (GFSQ)。该方法将输入特征矩阵 Z 分为 G 个组:
Z=[Z(1),Z(2),…,Z(G)]
组内的每个标量都会进行量化,生成的索引用于解码量化向量。随后,所有组的量化向量沿通道维度拼接,以重建量化下采样张量 zqd:
zqd(b,:,l)=[zqd(1)(b,:,l);zqd(2)(b,:,l);…;zqd(G)(b,:,l)]
最后,上采样函数 fup 将张量恢复到原始大小。
语音合成由 Firefly-GAN (FF-GAN) 声码器完成。该组件通过使用 ParallelBlock 替换传统的 Multi-Receptive Field (MRF) 模块进行了改进,ParallelBlock 利用堆叠平均机制和可配置的卷积核大小。FireFly Generator 的内部结构如下所示:
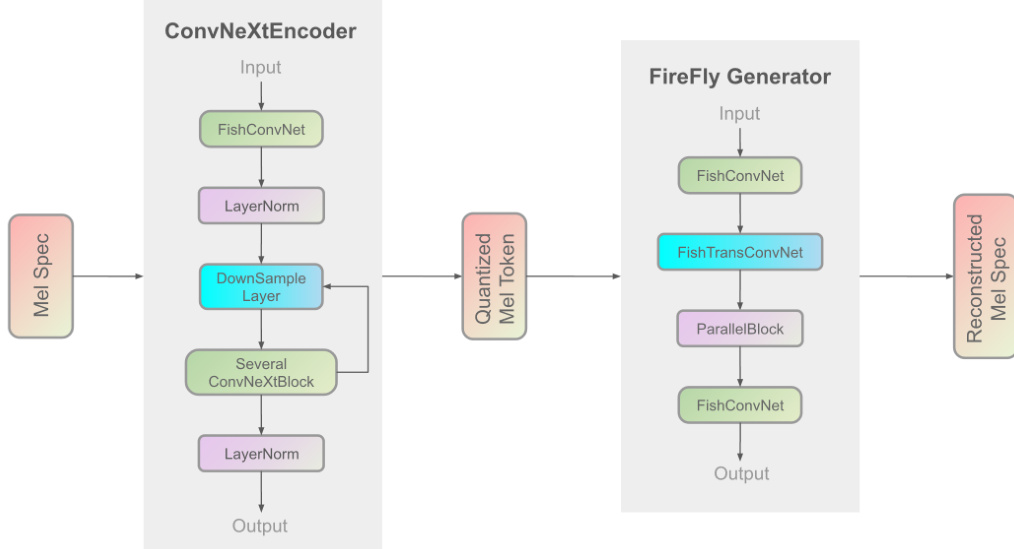
整体训练过程遵循三阶段流水线:在大规模标准数据上的初始预训练、在高质量数据集上的监督微调 (SFT),以及使用人工标注的正负样本对进行直接偏好优化 (DPO)。训练基础设施分为 AR 模型和声码器的独立组件,以优化资源利用率。
实验
评估框架利用客观指标、主观听力测试和推理速度基准来验证模型在语音克隆和实时处理方面的性能。结果表明,与基准模型相比,GFSQ 和 typo-codebook 策略显著增强了 codebook 利用率、说话人相似度和内容保真度。最终,该系统实现了高度的语音自然度和高效的实时推理,使其成为高质量语音合成和 AI agent 应用的稳健架构。
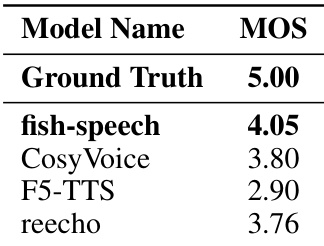
作者使用平均意见得分 (MOS) 评分对合成音频质量进行了主观评估。结果表明,与测试的基准模型相比,所提出的 fish-speech 模型实现了更高的感知质量评分。Fish-speech 在主观质量评分方面优于 CosyVoice、F5-TTS 和 reecho 等基准模型。所提出的方法在语音自然度和说话人相似度方面表现出卓越的性能。结果表明,该模型能更好地捕获并重现自然的人类语音特征。
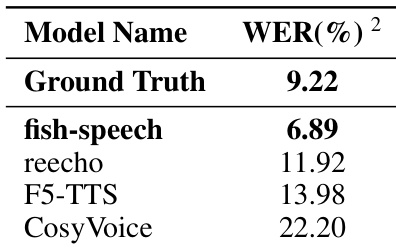
作者通过测量词错率 (WER) 来评估 fish-speech 模型在语音克隆任务中的表现。结果表明,与几个基准模型相比,所提出的模型实现了更高的可理解性。fish-speech 模型的词错率低于所有列出的基准模型。该模型在内容保真度方面的表现甚至超过了地面真值 (ground truth) 录音。所提出的方法在合成稳定性方面较竞争模型有显著提升。
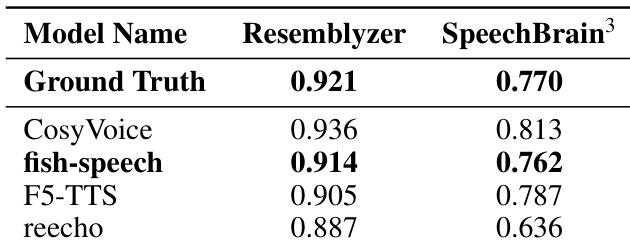
作者使用 Resemblyzer 和 SpeechBrain 指标评估了不同模型的说话人相似度。结果表明,所提出的 fish-speech 模型在两种评估框架下都非常接近地面真值的表现。fish-speech 模型实现的说话人相似度评分与地面真值极其接近。所提出的方法在捕获说话人特征方面优于 F5-TTS 和 reecho 等基准模型。在两种评估指标上的一致表现验证了模型保留说话人身份的能力。
作者通过主观质量评估、语音克隆可理解性测试和说话人相似度测量对 Fish-Speech 模型进行了评估。结果表明,与几个基准模型相比,所提出的模型能更优地捕获自然的人类语音特征并保持高内容保真度。此外,该模型在保留说话人身份方面表现出卓越的能力,并在不同的评估框架下提供了增强的合成稳定性。