Command Palette
Search for a command to run...
Allegro:揭开商业级视频生成模型的黑箱
Allegro:揭开商业级视频生成模型的黑箱
Yuan Zhou Qiuyue Wang Yuxuan Cai Huan Yang
摘要
视频生成领域已取得显著进展,开源社区贡献了大量研究论文与训练高质量模型的工具。然而,尽管已有诸多努力,当前可获取的信息与资源仍不足以支持达到商业级性能。在本报告中,我们揭开了该领域的“黑箱”,介绍了一款名为 Allegro 的先进视频生成模型,该模型在生成质量与时间一致性方面均表现出色。同时,我们指出了当前领域的若干局限性,并提出了一套全面的方法论,用于训练高性能、具备商业应用潜力的视频生成模型,涵盖数据构建、模型架构设计、训练流程优化以及评估体系等关键环节。用户研究表明,Allegro 在性能上超越了现有大多数开源模型,并接近主流商业模型水平,仅略逊于 Hailuo 与 Kling。代码仓库:https://github.com/rhymes-ai/Allegro模型页面:https://huggingface.co/rhymes-ai/Allegro成果展示:https://rhymes.ai/allegro_gallery
一句话总结
Rhymes AI 的研究人员提出了 Allegro,一个高性能视频生成模型,通过全面的训练方法(包括优化的数据、架构和评估),实现了商业级质量与时间一致性,优于大多数开源模型,并在用户研究中接近顶级商业系统。
主要贡献
- 本文填补了开源视频生成领域的空白,提出 Allegro,一个高性能模型,实现了商业级质量与时间一致性,克服了先前系统在数据建模、文本-视频对齐和控制精度方面的关键挑战。
- Allegro 的方法包括一个新颖的数据整理流程,生成包含 1.06 亿张图像和 4800 万段视频的标注数据集,同时对 VAE 和扩散 Transformer(DiT)架构进行改进,以提升视频生成的效率与保真度。
- 在六项维度的用户研究与基准评估中,Allegro 超越所有现有开源模型,并优于大多数商业系统,在整体质量上仅次于 Hailuo 和 Kling,同时在视频-文本相关性与视觉连贯性方面表现卓越。
引言
研究人员利用基于扩散的模型应对自动化、高质量视频生成日益增长的需求,尤其在数字内容创作、广告和娱乐等应用中。尽管开源文本到图像模型已达到商业水平,但文本到视频生成仍因长期时间动态建模、视频内容与复杂文本提示对齐,以及带准确语义标注的训练数据扩展等未解挑战而滞后。以往工作在数据整理、模型设计和评估方面常缺乏透明度,限制了可复现性与性能。本文提出 Allegro,一个达到商业水平的文本到视频模型,通过全面的流水线实现最先进成果:包含 1.06 亿图像与 4800 万视频的标注数据集、专为视频优化的重设计 VAE 与 DiT 架构,以及包含用户研究的多维评估框架。Allegro 在质量和相关性方面超越现有开源模型,并与顶级商业系统相当,未来扩展将聚焦于带文本条件的图像到视频生成及细粒度运动控制。
数据集
- 数据集基于大量原始图像与视频构建,数据来源包括 WebVid、Panda-70M、HD-VILA、HD-VG 和 OpenVid-1M 等公开集合,构成多样化且大规模的视频数据基础。
- 采用系统化的数据整理流程,对原始数据进行七步顺序过滤:时长与分辨率过滤(保留 ≥2 秒、≥360p 分辨率、≥23 FPS 的片段)、场景分割(将视频拆分为单场景片段,移除首尾各 10 帧)、低级指标过滤(通过 DOVER 评估亮度与清晰度,LPIPS 评估语义一致性,UniMatch 评估运动幅度)、美学过滤(使用 LAION Aesthetics Predictor)、内容无关伪影过滤(通过检测工具移除水印、文字、黑边)、粗粒度标注(在中间帧上使用 Tag2Text 生成描述)、CLIP 相似性过滤(保留描述与视觉内容高度对齐的样本)。
- 所有视频片段均重新编码为 H.264 格式,帧率为 30 FPS,最终片段时长为 2 至 16 秒,单镜头,且质量高。
- 过滤后,使用 Aria(一个微调的视频标注模型)对数据进行粗粒度与细粒度标注。细粒度标注包含空间细节(主体、背景、风格)、时间动态(运动、交互)以及显式相机控制提示(如“Camera [MOTION_PATTERN]”)。
- 数据按训练阶段划分为三个子集:
- 文本到图像预训练:从 4.12 亿张原始图像中提取 1.07 亿张图像-文本对,用于训练从文本生成图像。
- 文本到视频预训练:包含 4800 万段 360p 视频与 1800 万段 720p 视频,用于学习从文本生成具有时间一致性的视频。
- 文本到视频微调:精选 200 万高质量视频片段,用于最终优化视频生成质量与连贯性。
- 数据分布分析显示逐步优化:预训练阶段使用均衡的时长分布(短、中、长),而微调阶段则专注于中长时长视频(6–16 秒),具有中等运动与语义变化。
- VideoVAE 训练仅使用短边 ≥720 像素的数据,共获得 5.47 万段视频与 373 万张图像。空间增强仅使用随机裁剪;时间增强采用 [1, 3, 5, 10] 的随机帧采样间隔,以加速时间层收敛。
- 训练使用 L1 与 LPIPS 损失(权重分别为 1.0 与 0.1),采用两阶段流程:先联合训练图像与视频数据(每批包含 16 帧视频 + 4 张图像),随后冻结图像 VAE 的空间层,仅对 24 帧视频微调时间层。
- 过滤流程显著提升数据质量,剔除模糊、对焦不良或含伪影的内容,同时保留清晰、美观且语义丰富的样本,如自然动态场景、人类活动及细节丰富的交互。
方法
研究人员采用视频变分自编码器(VideoVAE)在压缩潜在空间中高效建模高维视频数据。VideoVAE 架构基于现有图像 VAE(即 Playground v2.5 模型),以保留其强大的空间压缩能力。为扩展至视频建模,研究人员引入时间建模层。框架在图像 VAE 的编码器和解码器输入输出端分别添加一维时间卷积层。此外,在 VAE 的每个 ResNet 块后插入一个由四个 3D 卷积层组成的时间模块。该设计使模型能够捕捉时间依赖性并实现时间压缩。时间下采样通过步长为 2 的步进卷积实现,上采样则通过帧重复后接反卷积操作完成。最终的 VideoVAE 模型参数量为 1.7496 亿,分别在时间、高度和宽度维度实现 4×8×8 的压缩比,从输入视频 T×3×H×W 得到形状为 T/ST×Cl×H/SH×W/SW 的潜在表示。潜在空间保留了基础图像 VAE 的通道维度 Cl=4。
VideoVAE 是整体视频生成框架的核心组件,该框架围绕视频扩散 Transformer(VideoDiT)构建。如图所示,VideoDiT 框架包含三个主要模块,协同工作以实现从文本生成视频。第一模块为文本编码器,将自然语言描述转换为文本嵌入。研究人员将原始的 mT5 文本编码器替换为 T5 编码器,以提升文本-视频对齐能力,增强生成视频的质量与连贯性。第二模块为 VideoVAE,将输入视频帧编码至压缩潜在空间,实现高效的扩散建模。第三模块为视频 Transformer 网络,处理来自 VideoVAE 的视觉 token 与文本嵌入,预测扩散过程中的噪声。
VideoDiT 的核心是一个由多个扩散 Transformer(DiT)块组成的视频 Transformer。每个 DiT 块包含一个具有 3D RoPE 的自注意力模块,用于在空间与时间维度上建模视频 token;一个跨注意力模块,用于注入文本条件以引导生成;一个前馈层;以及 AdaLN-single 模块,用于融合扩散时间步信息。采用 3D 注意力是关键设计选择,使模型能够捕捉完整的时空依赖关系,相比使用独立 2D 与 1D 注意力的方法,显著提升视频一致性与动态运动表现。模型采用多阶段训练策略,逐步构建能力:第一阶段为文本到图像预训练,建立文本与图像之间的映射;第二阶段为文本到视频预训练,分为三个逐步增加复杂度的子阶段:首先在 368×640 分辨率下使用 40 帧,随后在相同帧数下扩展至 720×1280 分辨率,最后在 720×1280 分辨率下将视频长度增加至 88 帧;第三阶段为文本到视频微调,使用一批高质量动态视频进一步提升模型生成高质量、多样化视频的能力。
实验
- 在 100 段视频的验证集(120 帧,720p)上,将 VideoVAE 与开源 3D VAE(Open-Sora v1.2、Open-Sora-Plan v1.2.0)进行对比,PSNR 达到 31.25,SSIM 达到 0.8553,优于所有竞争模型,且闪烁更少,细节保留更好。
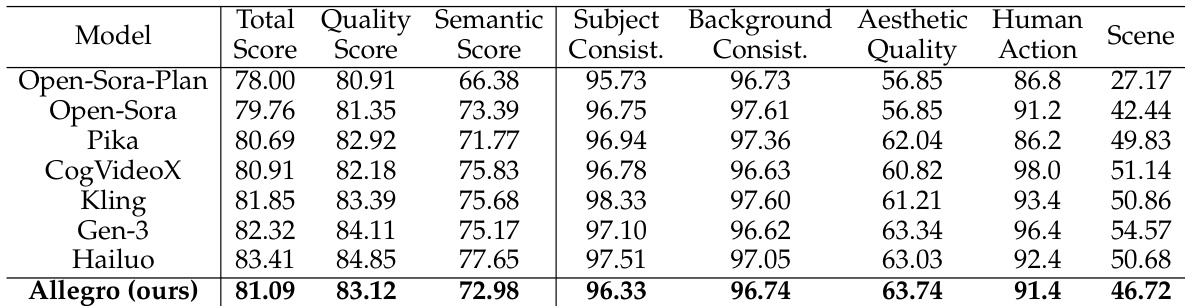
- 在 VBench 基准上评估 Allegro 模型,使用 946 个文本提示生成的 4730 段视频,其在开源模型中表现最佳,整体得分仅次于 Gen-3、Kling 与 Hailuo。
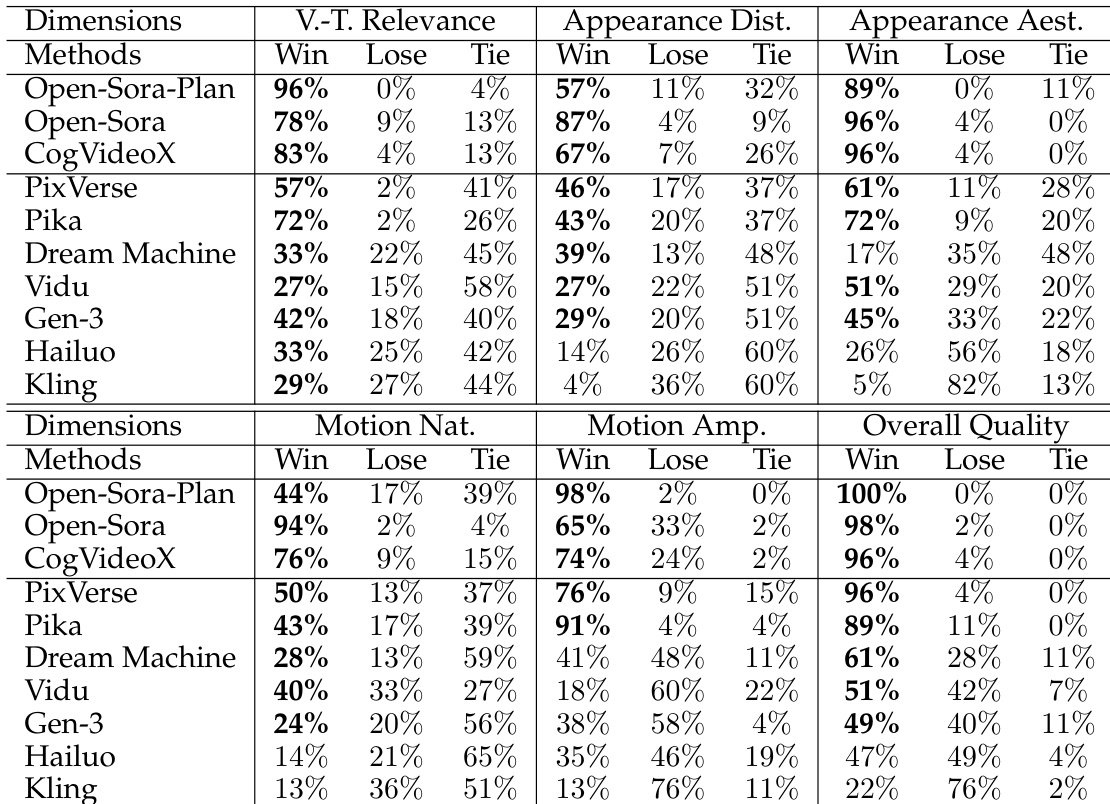
- 在 46 个多样化提示的用户研究中,Allegro 在六个维度上均优于所有开源模型及多数商业模型:视频-文本相关性、外观失真、外观美学、运动自然性、运动幅度与整体质量,尤其在文本-视频对齐方面表现突出。
- 消融研究证实,使用微调后的 T5 文本编码器显著提升语义保真度,优于 mT5;多阶段训练(从 40×368×640 到 88×720×1280)实现了运动质量与视觉真实感的渐进提升。
研究人员采用多阶段训练策略提升视频生成能力,从低分辨率帧开始,逐步提高分辨率与帧数,以增强运动质量与视觉细节。结果表明,最终微调阶段显著提升了美学、运动自然性与文本-视频对齐能力,模型在所有评估维度上均表现优异。

研究人员使用 100 段视频的验证集评估其 VideoVAE 模型与现有开源 VideoVAE 的性能,通过 PSNR 与 SSIM 测量重建质量。结果表明,其 VideoVAE 的 PSNR 与 SSIM 均高于 Open-Sora 与 Open-Sora-Plan,分别达到 31.25 与 0.8553,表明其重建质量更优,且闪烁与失真更少。

研究人员开展用户研究,将 Allegro 模型与多个开源及商业视频生成模型在六个评估维度上进行对比。结果表明,Allegro 超越所有开源模型,并在与商业模型的对比中表现强劲,尤其在视频-文本相关性与整体质量方面表现突出,但在运动幅度上仍落后于顶级商业模型。
研究人员为其模型采用多阶段训练策略,从 T2I 预训练模型出发,逐步提升分辨率与帧数。结果表明,最终的 T2V 微调阶段在最少的训练步数与数据量下达到最高性能,表明训练效率高。

研究人员使用 VBench 基准评估其 Allegro 模型,与多个开源及商业视频生成模型进行对比。结果表明,Allegro 超越所有开源模型,并跻身顶级商业模型行列,在视频-文本相关性与整体质量上取得最高分,且在所有评估维度上均表现强劲。