Command Palette
Search for a command to run...
Qwen2.5-Coder 技术报告
Qwen2.5-Coder 技术报告
摘要
在本报告中,我们介绍了Qwen2.5-Coder系列模型,这是对前代模型CodeQwen1.5的一次重大升级。该系列包含六个不同规模的模型:Qwen2.5-Coder-(0.5B/1.5B/3B/7B/14B/32B)。作为专为代码任务优化的模型,Qwen2.5-Coder基于Qwen2.5架构构建,并在超过5.5万亿个标记(tokens)的海量语料上继续进行预训练。通过精细的数据清洗、可扩展的合成数据生成以及均衡的数据混合策略,Qwen2.5-Coder在展现卓越代码生成能力的同时,依然保持了出色的通用能力和数学推理能力。该系列模型已在多种代码相关任务上进行了全面评估,在超过10个基准测试中取得了当前最优(SOTA)性能,涵盖代码生成、代码补全、代码推理与代码修复等多个方面,且在同等模型规模下持续超越更大规模的模型。我们相信,Qwen2.5-Coder系列的发布将推动代码智能领域的研究进展,并凭借其宽松的许可协议,助力开发者在真实应用场景中更广泛地采用与部署。
一句话总结
阿里巴巴通义实验室推出的 Qwen2.5-Coder 是一系列参数规模最高达 32B 的六款代码专用模型,基于 Qwen2.5 架构,通过增强的数据筛选与合成数据生成,实现了代码生成、补全与推理任务的最先进性能,同时保持了强大的通用与数学能力,在宽松许可协议下推动了更广泛的实际开发者应用。
主要贡献
-
Qwen2.5-Coder 是基于 Qwen2.5 架构构建的一系列代码专用语言模型,使用超过 5.5 万亿 token 的精选代码与文本数据进行预训练,通过文件级与仓库级预训练策略,显著提升了代码生成、补全、推理与修复能力。
-
模型在超过 10 个基准测试中达到最先进水平,持续优于同规模的更大模型,并在编码能力上与 GPT-4o 相当,同时保持了强大的通用与数学推理能力。
-
支持高达 128K token 的长上下文理解,通过“代码中的针”等任务及 Text-to-SQL 等实际应用验证,具备在代码助手与产物生成等真实场景中应用的能力。
引言
作者基于 Qwen2.5 架构提出 Qwen2.5-Coder,这是一个包含六款代码专用语言模型的家族,参数规模从 0.5B 到 32B,旨在推动开源代码智能的发展。本工作针对以往代码大模型的关键局限——如任务覆盖范围窄、长上下文理解能力弱、真实编码任务表现不佳——通过在精心筛选的 5.5 万亿 token 数据集上进行训练加以解决,该数据集融合了高质量公开代码、网络爬取的代码相关文本以及合成数据。模型进一步通过精心设计的指令微调流程进行优化,涵盖代码生成、补全、推理、编辑与 Text-to-SQL 等多样化编码任务。主要贡献在于构建了一个可扩展、高性能的开源代码模型系列,在超过十个基准测试中达到最先进水平,优于同规模的更大模型,媲美 GPT-4o 等专有模型,同时支持高达 128K token 的长上下文推理,并在代码助手与产物生成等实际应用中展现出强大潜力。
数据集
-
Qwen2.5-Coder-Data 数据集由五类核心数据构成:源代码数据、文本-代码对齐数据、合成数据、数学数据与文本数据,旨在支持全面的代码与语言理解。
-
源代码数据包含截至 2024 年 2 月前创建的公共 GitHub 仓库,覆盖 92 种编程语言,还整合了 Pull Requests、Commits、Jupyter Notebooks 与 Kaggle 数据集,均采用基于规则的过滤方法以确保质量与相关性。
-
文本-代码对齐数据源自 Common Crawl,包含代码相关的文档、教程与博客。采用四阶段由粗到细的分层过滤方法,每阶段均利用 fastText 等轻量级模型以保持效率与表层准确性,实现细粒度质量控制并赋予质量评分,最终保留的数据在代码生成基准上表现更优。
-
合成数据由前代模型 CodeQwen1.5 生成,并通过基于执行器的验证步骤,仅保留可执行代码,有效降低幻觉风险。
-
数学数据来自 Qwen2.5-Math 预训练语料库,用于强化数学推理能力,同时不损害代码生成性能。
-
文本数据来自 Qwen2.5 模型的预训练语料库,保留通用语言能力。所有代码片段均被移除,以防止数据重叠并确保来源独立。
-
数据集在两个预训练阶段使用:文件级与仓库级。文件级预训练采用最大序列长度 8,192 token 与 5.2T 高质量数据,目标包括下一个 token 预测与填空中间(FIM)格式化。
-
仓库级预训练将上下文扩展至 32,768 token,RoPE 基频调整为 1,000,000,并应用 YARN 机制以支持高达 131,072 token。使用约 300B token 的长上下文代码数据,并采用仓库级 FIM 格式。
-
所有数据均通过 10-gram 词级重叠方法进行去污染处理,以移除与 HumanEval、MBPP、GSM8K、MATH 等关键测试数据集匹配的训练样本,防止测试泄露。
-
数据处理聚焦于质量与多样性,通过迭代过滤与验证确保高信噪比,尤其在文本-代码对齐与合成数据生成方面表现突出。
方法
作者以 Qwen2.5 架构为基础,构建 Qwen2.5-Coder,通过多阶段训练流程适配代码专用任务。模型架构详见表 1,为基于 Transformer 的设计,不同模型尺寸(0.5B 至 32B)在关键参数上有所差异,包括隐藏层大小、注意力头数量、中间层大小以及嵌入层绑定的使用(仅应用于较小模型,不用于大模型)。所有模型共享 151,646 token 的一致词表大小,并在 5.5 万亿 token 的语料库上训练。架构支持大上下文窗口,可处理长代码序列。
为增强模型对代码的理解,Qwen2.5-Coder 引入一组特殊标记,如表 2 所示,用于处理多样化的代码结构。这些标记包括 </endoftext|> 用于标记序列边界,以及填空中间(FIM)标记 </fim_prefix|>、</fim_middle|> 与 </fim_suffix|>,用于训练模型预测缺失的代码片段。其他标记如 </repo_name|> 与 </file_sep|> 有助于组织仓库级数据,使模型能够在文件与仓库两个层级管理信息。
Qwen2.5-Coder 的训练过程采用三阶段流程,如框架图所示。第一阶段为文件级预训练,基于 Qwen2.5 基础模型在 5.2 万亿 token 的代码数据上进行训练。第二阶段为仓库级预训练,使用 3000 亿 token 数据进一步提升模型对整个仓库上下文的理解。第三阶段为对齐阶段,模型通过监督微调(SFT)与直接偏好优化(DPO)进行训练,使其输出更符合人类偏好,提升代码生成能力。

用于微调的指令数据来自多种来源,包括 GitHub 上的代码片段与开源指令数据集。采用多语言多智能体协作框架生成高质量、多语言的指令数据,不同编程语言的专用智能体通过协作讨论提升能力。指令数据质量通过基于检查清单的评分系统严格评估,涵盖一致性、相关性、难度与代码正确性等维度。
为确保生成代码的正确性,采用多语言沙箱进行代码验证。该沙箱支持多种编程语言(如 Python、Java、C++)的静态检查与动态执行。沙箱由多个模块组成:语言支持模块提供不同语言的解析与执行环境,单元测试生成器基于示例代码生成测试用例,代码执行引擎在隔离环境中运行测试。该验证流程对过滤低质量数据至关重要,确保模型学习生成正确可靠的代码。


实验
- 在代码、数学与文本的评估数据混合比例中,发现 70% 代码、20% 文本、10% 数学(7:2:1)为最优配置,尽管代码比例较低,仍实现卓越性能,最终数据集总量达 5.2 万亿 token。
- 在 HumanEval 与 MBPP 基准测试中,Qwen2.5-Coder-7B 在同规模开源模型中达到最先进水平,全面超越更大模型如 DS-Coder-33B。
- 在 BigCodeBench-Complete 上,Qwen2.5-Coder 展现出强大泛化能力,在完整与困难子集上均取得最佳表现,表明其具备稳健的分布外能力。
- 在 MultiPL-E 上,Qwen2.5-Coder 在八种编程语言中均达到最先进水平,其中五种语言得分超过 60%。
- 在代码补全基准测试(HumanEval-FIM、CrossCodeEval、CrossCodeLongEval、RepoEval、SAFIM)中,Qwen2.5-Coder-32B 达到最先进性能,相比同类模型有显著提升,且小规模模型(如 Qwen2.5-Coder-7B)也表现强劲,可媲美 33B 模型。
- 在 CRUXEval 上,Qwen2.5-Coder-7B-Instruct 在 Input-CoT 与 Output-CoT 任务中分别达到 65.8% 与 65.9% 准确率,超越更大模型,展现出强大的代码推理能力。
- 在数学基准测试(MATH、GSM8K、MMLU-STEM、TheoremQA)中,Qwen2.5-Coder 表现优异,归因于平衡的训练数据与强大的基础模型架构。
- 在通用自然语言基准测试(MMLU、ARC-Challenge、TruthfulQA、WinoGrande、HellaSwag)中,Qwen2.5-Coder 保持强劲表现,验证了其通用能力的有效保留。
- 在 LiveCodeBench 上,Qwen2.5-Coder-7B-Instruct 达到 37.6% Pass@1,超越同规模及更大模型;Qwen2.5-Coder-32B-Instruct 达到 31.4%,与众多闭源 API 相当。
- 在 McEval 与 MdEval 上,Qwen2.5-Coder-32B-Instruct 分别在 40 与 18 种语言中取得最佳表现,优于或媲美更大模型。
- 在 CodeEditorBench 上,Qwen2.5-Coder-32B-Instruct 达到 86.2% 胜率,与 DS-Coder-V2-Instruct(236B 参数)相当,展现出强大的代码编辑能力。
- 在 TableBench 上,Qwen2.5-Coder-32B-Instruct 在 TCoT 设置下取得 45.1 分,为所有评估模型中的最佳表现。
- 人类偏好对齐评估(CodeArena)显示,Qwen2.5-Coder-32B-Instruct 在与人类偏好对齐方面优于其他开源模型。
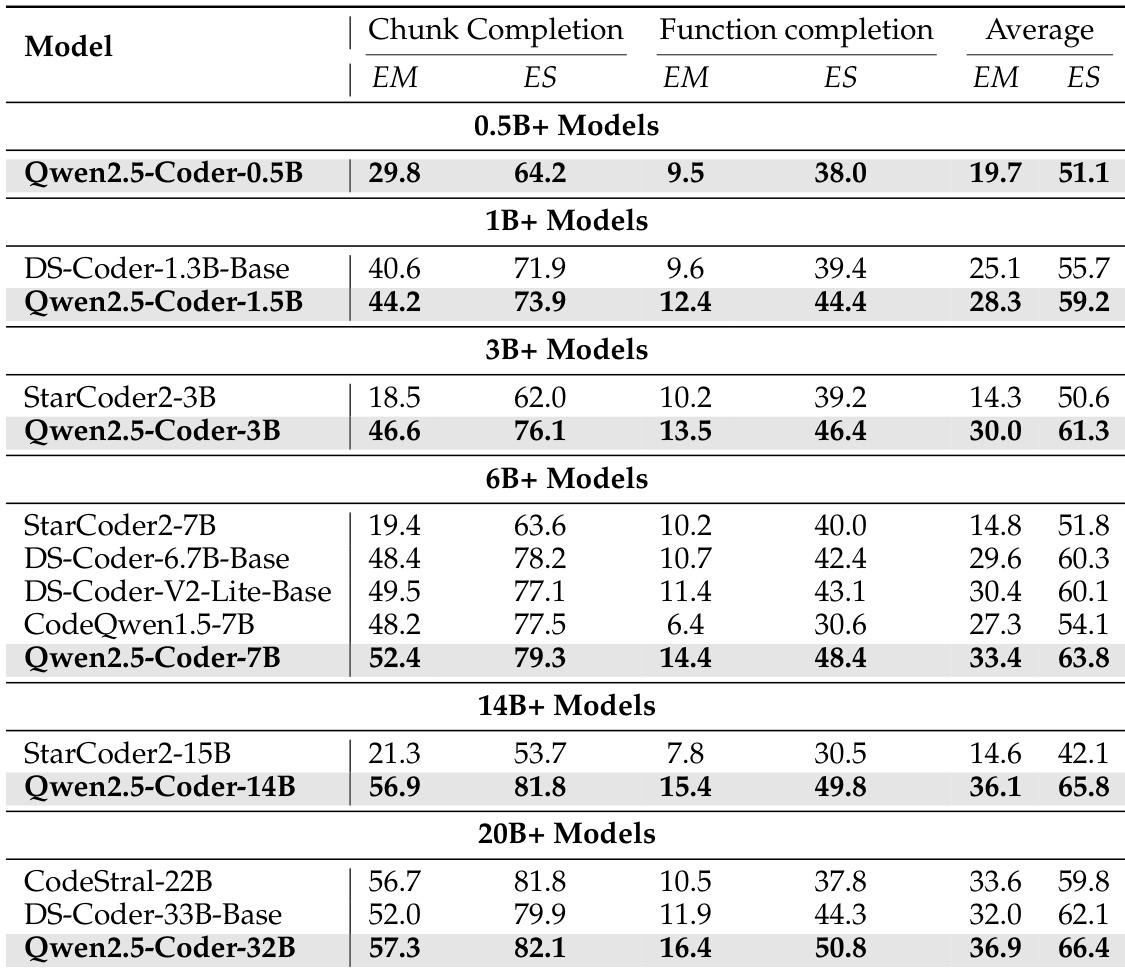
作者使用表格对比不同参数规模下各类代码补全模型的性能。结果显示,Qwen2.5-Coder 模型在同规模下始终优于其他模型,其中 Qwen2.5-Coder-32B 在 20B+ 类别中得分最高,展现出在代码块与函数补全任务中的强大性能。
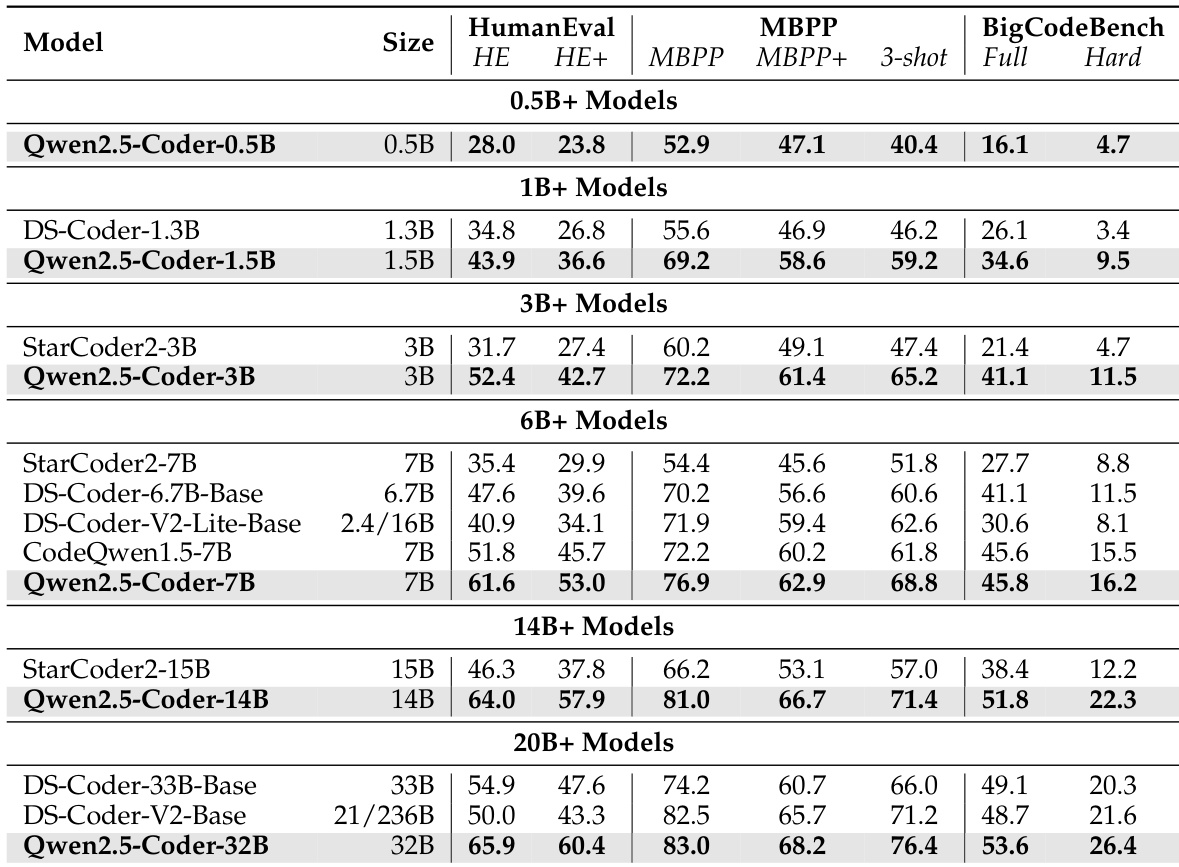
作者采用 70% 代码、20% 文本、10% 数学的数据混合比例训练 Qwen2.5-Coder 系列,该配置在多个代码生成基准测试中达到最先进水平。结果显示,Qwen2.5-Coder-32B 模型在 HumanEval、MBPP 与 BigCodeBench 上均优于其他开源模型,包括更大模型,展现出强大的代码生成能力。
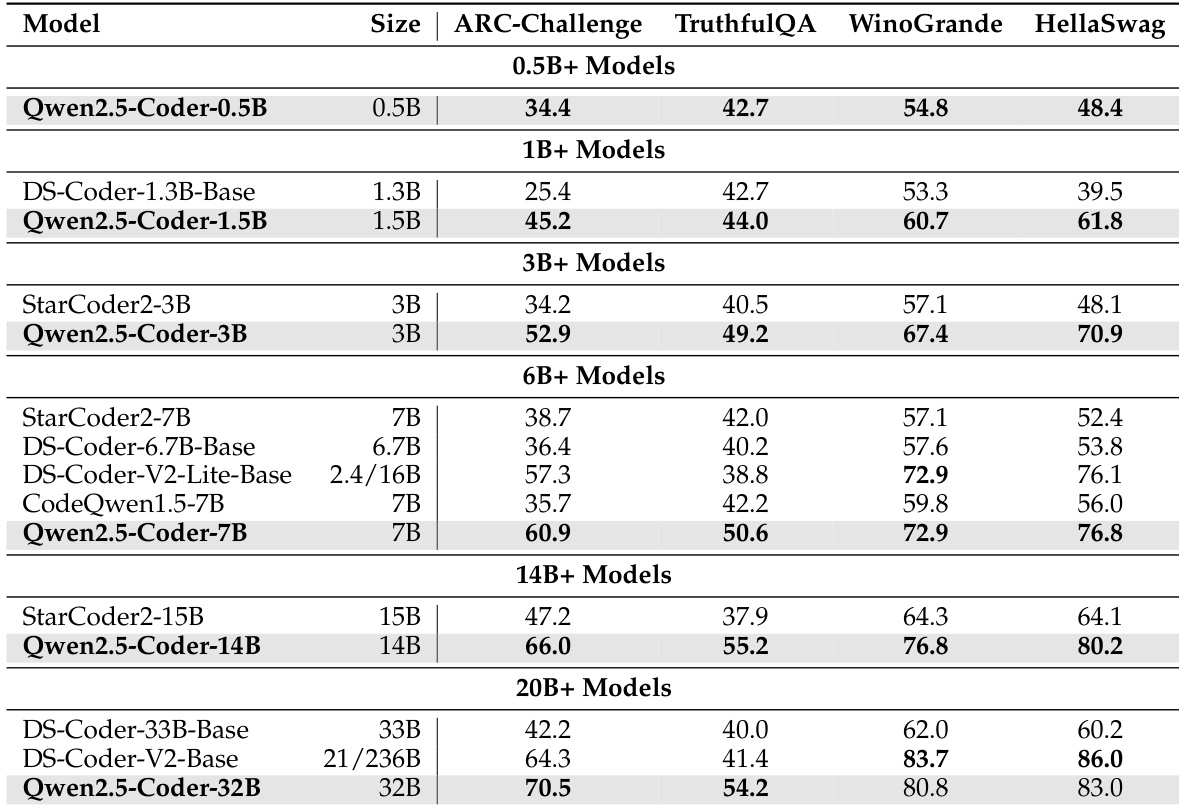
作者使用表格对比 Qwen2.5-Coder 模型在不同规模下于通用自然语言基准测试中的表现。结果显示,Qwen2.5-Coder 模型在同规模下始终优于其他模型,其中 32B 模型在所有评估基准上均取得最高分。
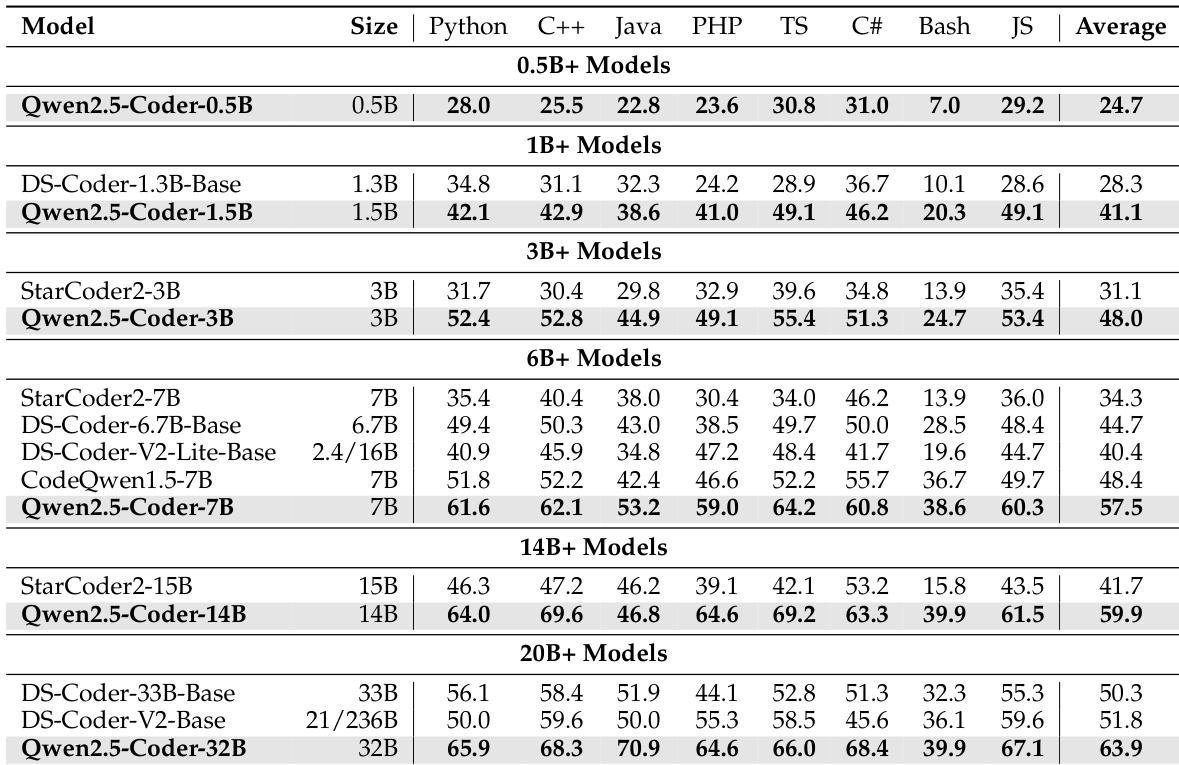
作者使用 MultiPL-E 基准测试评估多种代码模型在八种编程语言中的表现。结果显示,Qwen2.5-Coder-32B 平均得分最高,达 63.9,超越所有 20B+ 类别模型,展现出强大的多语言能力。
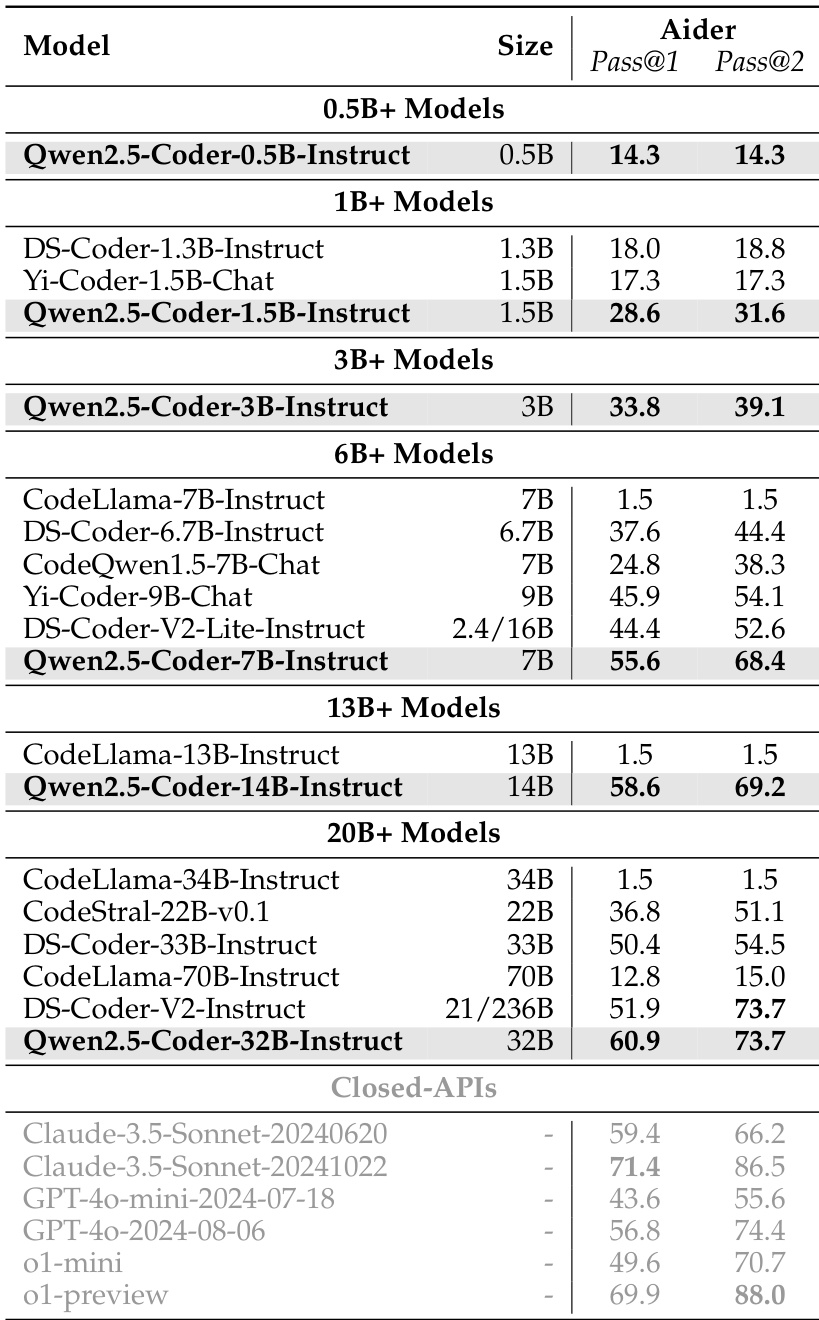
作者在 Aider 基准测试中评估 Qwen2.5-Coder 系列指令模型的性能,衡量其编辑代码以通过单元测试的能力。结果显示,Qwen2.5-Coder-32B-Instruct 达到 Pass@1 60.9 与 Pass@2 73.7,优于 DS-Coder-33B-Instruct 与 CodeStral-22B-v0.1 等更大模型,接近闭源 API 的性能。