Command Palette
Search for a command to run...
通用OCR理论:通过统一的端到端模型迈向OCR-2.0
通用OCR理论:通过统一的端到端模型迈向OCR-2.0
摘要
传统OCR系统(OCR-1.0)在日益增长的智能化处理人造光学字符需求面前,已逐渐难以满足实际应用需求。本文将各类人造光学信号(如纯文本、数学与分子式、表格、图表、乐谱,甚至几何图形等)统称为“字符”,并提出通用OCR理论(General OCR Theory),同时构建了一个性能卓越的模型——GOT(General OCR Transformer),以推动OCR技术迈入OCR-2.0时代。GOT模型拥有5.8亿参数,是一个统一、简洁且端到端的架构,由高压缩率编码器与长上下文解码器构成。作为典型的OCR-2.0模型,GOT能够应对上述各类“字符”在多种OCR任务中的处理需求。在输入方面,模型支持常见场景图像与文档图像的切片式与整页式输入;在输出方面,GOT可通过简单提示(prompt)生成纯文本或结构化格式结果(如Markdown、TikZ、SMILES、Kern等)。此外,该模型还具备交互式OCR能力,支持基于坐标或颜色的区域级识别引导。为进一步提升实用性,我们还将动态分辨率适配与多页文档OCR技术集成至GOT中。实验结果充分验证了所提模型在多项指标上的显著优势。
一句话摘要
来自StepFun、旷视科技、中国科学院大学和清华大学的作者提出GOT,一个5.8亿参数的统一端到端OCR-2.0模型,通过高压缩编码器和长上下文解码器,将识别能力从文本扩展到多种人工光学信号——如数学公式、表格、图表和几何图形,支持切片/整页输入、格式化输出(Markdown/TikZ/SMILES)、交互式区域级识别、动态分辨率和多页处理,显著推动了智能文档理解的发展。
主要贡献
- 本文提出通用OCR理论,并引入GOT,一种统一的OCR-2.0模型,旨在克服传统OCR-1.0系统和大视觉语言模型(LVLM)的局限性,通过单一架构支持端到端处理多种人工光学信号——包括文本、数学公式、表格、图表、乐谱和几何图形。
- GOT采用高压缩编码器(8000万参数)和长上下文解码器(5.8亿参数),可高效处理整页与切片输入,支持动态分辨率和多页OCR,同时可通过坐标或颜色实现交互式区域级识别。
- 模型通过三阶段训练策略与合成数据生成,在多样化OCR任务中取得优异表现,尤其在涉及格式化输出(如Markdown、TikZ、SMILES)和高密度文本场景的基准测试中表现突出。
引言
作者针对现实应用中日益增长的智能、多功能光学字符识别(OCR)需求展开研究,用户不仅需要识别传统文本,还希望处理包括文本、数学公式、表格、图表、乐谱和几何图形在内的多样化人工视觉内容。以往的OCR系统(OCR-1.0)依赖复杂的模块化流水线,存在维护成本高、误差传播严重、跨任务泛化能力差等问题。与此同时,大视觉语言模型(LVLM)虽强大,但因参数量大、对密集文本的token压缩效率低、训练成本过高,尤其在新增语言或格式等OCR模式时,难以胜任纯OCR任务。为克服这些局限,作者提出通用OCR理论(OCR-2.0),引入GOT——一个5.8亿参数的统一端到端模型。GOT配备高压缩编码器与长上下文解码器,可高效识别来自切片与整页输入的多种“字符”。其支持通过坐标或颜色实现交互式区域级识别,具备超高清图像的动态分辨率能力,支持多页OCR,并可通过提示控制生成结构化输出(如Markdown、TikZ、SMILES)。模型采用三阶段训练策略结合合成数据进行训练,在保持低推理与训练成本的同时,实现了跨任务的强性能表现。
数据集
- 数据集包含约500万张图像-文本对,来源于多样化的现实世界与合成数据,用于多个预训练与微调阶段。
- 场景文本OCR数据中,200万张图像-文本对来自Laion-2B(英文)和Wukong(中文),伪真实标签通过PaddleOCR生成。其中一半为中文,一半为英文。文本内容按阅读顺序扁平化处理,或裁剪为文本区域图像切片,额外生成100万张切片类型对。
- 文档级OCR数据包括120万张全页PDF-图像对,以及从Common Crawl PDF中使用Fitz提取的80万张图像切片,切片基于解析的边界框在行级与段落级进行裁剪。
- 联合训练中,3.2.2数据的80%作为纯OCR数据,补充了来自CASIA-HWDB2(中文)、IAM(英文)和NorHand-v3(挪威语)的手写文本。行级手写样本被分组并粘贴至空白页,以模拟长文本识别。
- Mathpix-markdown格式数据包括:100万对数学公式,通过Mathpix-markdown-it与Chrome-driver从LaTeX渲染;100万对分子式,来自ChEMBL_25,使用Mathpix-markdown-it与rdkit.Chem生成;30万对表格,使用LaTeX渲染;100万张全页对(0.5M英文来自Nougat,0.5M中文来自Vary,另加0.2M内部标注数据)。
- 通用OCR数据包括:50万张乐谱样本,来自GrandStaff,使用Verovio重新渲染,背景与元数据多样;100万对几何图形,使用TikZ命令生成基础形状与曲线;200万对图表数据(100万来自Matplotlib,100万来自Pyecharts),文本与数值随机取自公开语料库。
- 细粒度OCR数据(60万样本)来自RCTW、ReCTS、ShopSign和COCO-Text(自然场景),以及解析后的PDF(文档级任务)。坐标经归一化并放大1000倍;颜色引导样本使用红、绿、蓝边界框。
- 超大图像OCR数据(50万对)通过水平或垂直拼接单页PDF生成,采用InternVL-1.5的分块方法,最多支持12块,实现1024×1024滑动窗口处理。
- 多页OCR数据(20万对)通过从Mathpix格式PDF中随机抽取2–8页构建,确保每页不超过650个token,总长度不超过8000 token,内容混合中英文。
- 模型训练采用多种数据子集的混合,各阶段使用不同比例。数据处理保持一致格式,包括图像裁剪、坐标归一化及区域与颜色引导任务的元数据构建。
- 评估阶段使用400张图像的基准集(200张中文,200张英文),经人工校正,因文本较短,采用字符级指标。
方法
作者采用三阶段训练框架开发通用OCR理论(OCR-2.0)模型,即GOT。GOT整体架构包含三个核心组件:视觉编码器、线性层和输出解码器。线性层作为连接器,负责在视觉编码器与语言解码器之间映射通道维度。该框架设计用于在不同训练阶段逐步构建并优化模型能力。
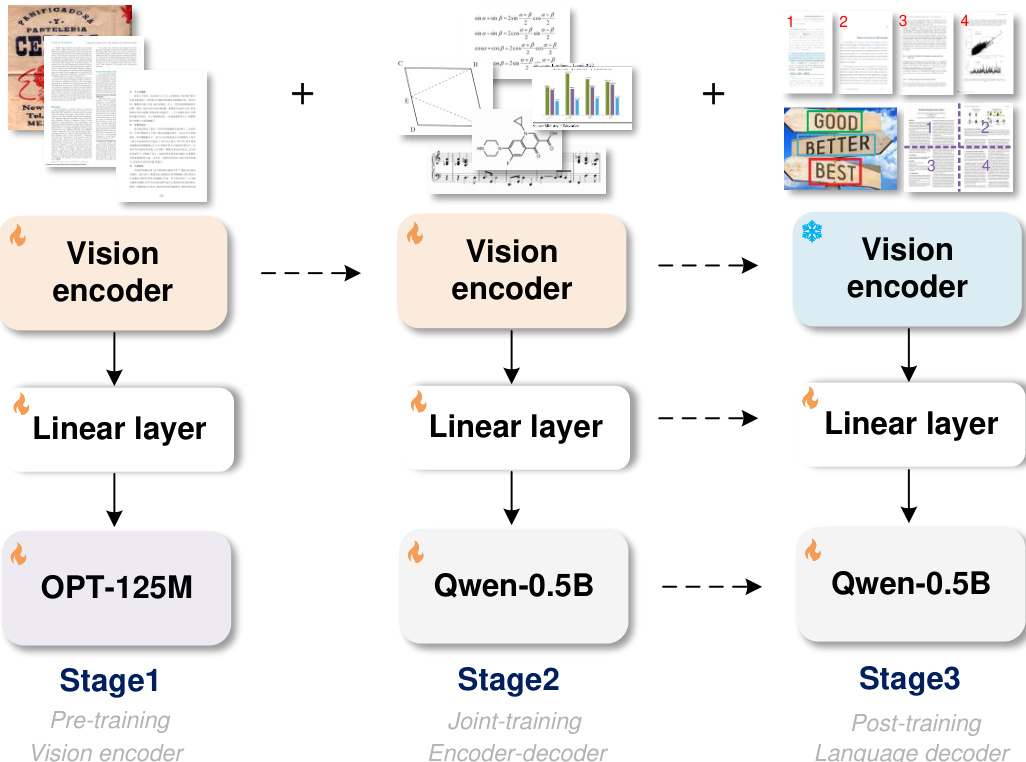
如图所示,第一阶段聚焦于视觉编码器的预训练。此阶段使用小型解码器(OPT-125M)反向传播梯度至编码器,提升训练效率并节省GPU资源。视觉编码器在多样化图像上进行训练,包括场景文本与文档级字符,以确保其具备处理常见文本识别任务所需的编码能力。该阶段为编码器处理各类视觉输入奠定了坚实基础。

第二阶段将预训练的视觉编码器与更大解码器(Qwen-0.5B)结合,构成完整的GOT架构。此阶段通过利用更广泛的OCR-2.0数据(如乐谱、数学与分子公式、几何图形)扩展模型知识,使其能够处理更广泛的光学字符识别任务,显著增强泛化能力。
最终阶段专注于解码器的后训练,以定制新功能。该过程无需修改视觉编码器。通过生成细粒度、多裁剪/多页的合成数据并融入训练,实现区域提示OCR、超大图像OCR和批量PDF OCR等高级功能。该方法使模型可针对特定用户需求进行定制,而无需重新训练整个系统,具备高度适应性与高效性。
实验
- 在8×8 L40s GPU上完成三阶段训练:预训练(3轮,批量大小128,学习率1e-4)、联合训练(1轮,最大token长度6000)、后训练(1轮,最大token长度8192,学习率2e-5),前一阶段保留80%数据以维持性能。
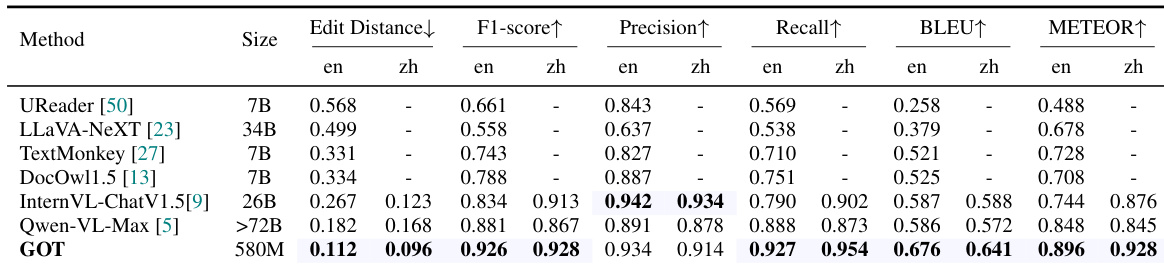
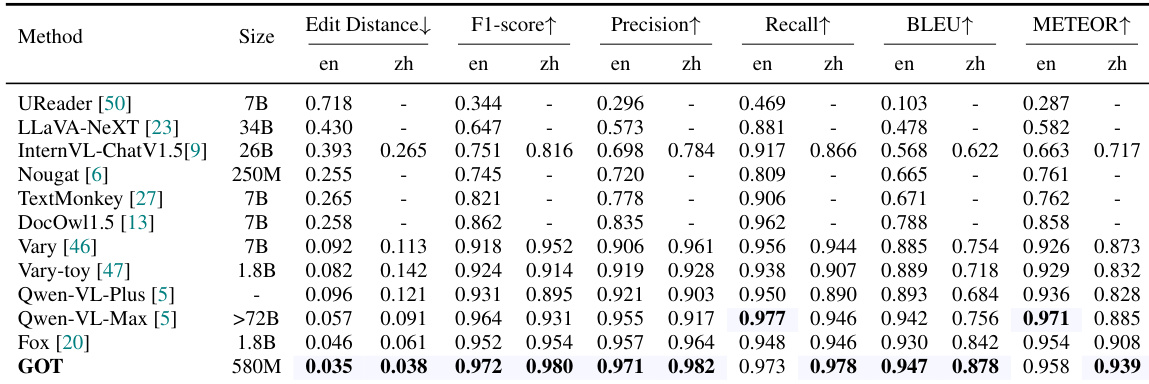
- 在英文与中文文档级OCR任务中均达到当前最优结果,于Fox基准测试中以5.8亿参数超越以往模型,如表1所示。
- 在纯文档OCR(表1)、场景文本OCR(表2)和格式化文档OCR(表3)任务中表现优异,多裁剪推理显著提升小文本、公式与表格的识别效果。
- 在细粒度OCR任务中表现卓越,超越Fox在基于边界框与基于颜色的指代OCR任务上的表现,表明其具备强大的交互式OCR能力(表4)。
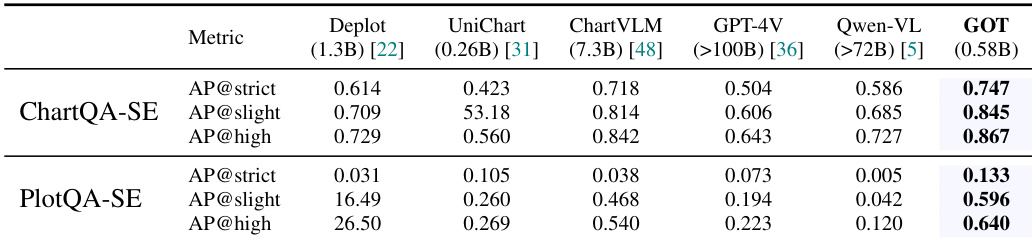
- 在通用OCR任务中表现领先,涵盖乐谱、几何与图表识别,图表OCR结果优于专用模型与主流LVLM(表5)。
- 验证了动态分辨率与多页OCR能力,有效处理高分辨率与多页文档,如图7与图8所示。
结果表明,GOT在ChartQA-SE与PlotQA-SE两个基准测试中均达到最高性能,全面超越所有对比模型。其在ChartQA-SE上的优异表现,尤其在AP@high指标上,表明其具备强大的结构化图表理解能力;在PlotQA-SE上的竞争力则体现其在通用图表OCR任务中的高效性。
结果表明,GOT在文档级OCR任务中达到当前最优性能,全面超越所有基线模型,在F1分数、精确率、召回率、BLEU与METEOR等多个指标上表现优异,适用于中英文文本识别。模型在编辑距离与F1分数上的突出表现,充分证明其在处理密集文本与复杂文档布局方面的强大能力。
结果表明,GOT在格式化文档OCR任务中表现强劲,多裁剪推理显著提升公式与表格的识别准确率,优于单尺度输入。模型在通用OCR任务中也表现出色,尤其在乐谱与几何识别方面表现卓越。
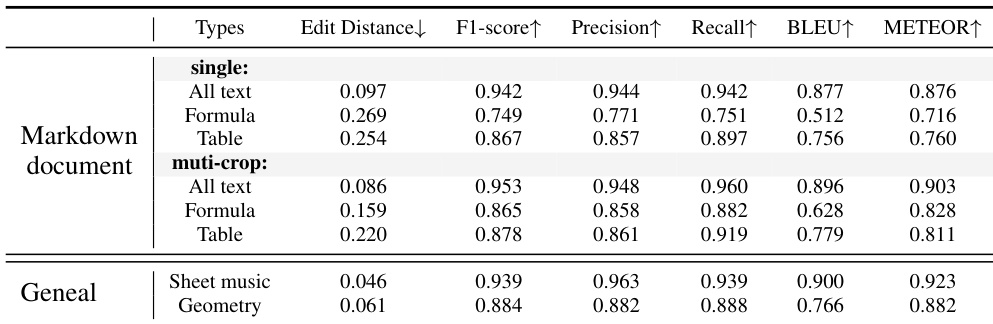
结果表明,GOT在文档级OCR任务中达到当前最优性能,全面超越所有对比模型,在英文与中文文本识别的多个指标(F1分数、精确率、召回率、BLEU、METEOR)上均表现领先。其在编辑距离与F1分数上的优异表现,充分证明其在处理密集文本与复杂文档布局方面的强大能力。
结果表明,GOT在中英文文档OCR任务的多个指标上均优于Fox [20]。尤其在英文区域与颜色任务中,GOT在F1分数、精确率、召回率、BLEU与METEOR上均超越Fox;在中文区域与颜色任务中同样全面领先,充分展现其强大的文本识别与理解能力。