Command Palette
Search for a command to run...
YOLOv10:实时端到端目标检测
YOLOv10:实时端到端目标检测
摘要
近年来,YOLO系列模型因其在计算成本与检测性能之间实现了高效平衡,已成为实时目标检测领域的主流范式。研究人员在YOLO的网络架构设计、优化目标、数据增强策略等方面开展了广泛探索,取得了显著进展。然而,其对非极大值抑制(Non-Maximum Suppression, NMS)后处理的依赖,不仅阻碍了YOLO模型的端到端部署,还显著增加了推理延迟。此外,YOLO中各类组件的设计缺乏系统性与全面性评估,导致明显的计算冗余,限制了模型的潜力发挥,使其整体效率处于次优状态,仍具备较大的性能提升空间。针对上述问题,本文致力于从后处理机制与模型架构两个维度进一步突破YOLO在性能与效率之间的边界。为此,我们首先提出一种适用于无NMS训练的统一双分配策略(Consistent Dual Assignments),在实现优异检测性能的同时显著降低推理延迟。此外,我们引入了一种面向效率与精度协同优化的全局模型设计策略,从效率与准确性双重角度对YOLO的各个组件进行系统性优化,大幅减少了计算开销,显著提升了模型表达能力。基于上述创新,我们提出新一代实时端到端目标检测模型——YOLOv10。大量实验结果表明,YOLOv10在不同模型规模下均实现了当前最优的性能与效率平衡。例如,在COCO数据集上,当检测精度(AP)相近时,YOLOv10-S的推理速度比RT-DETR-R18快1.8倍,参数量和浮点运算量(FLOPs)分别减少2.8倍;相较于YOLOv9-C,YOLOv10-B在保持相同性能的前提下,推理延迟降低46%,参数量减少25%。这些结果充分验证了YOLOv10在实时检测任务中的卓越优势。
一句话总结
清华大学的研究人员提出了 YOLOv10,一种新的实时端到端目标检测框架,通过一致的双重分配机制消除了非极大值抑制(NMS),并采用整体效率-精度驱动的设计,在多个尺度上实现了最先进的速度、精度和模型紧凑性。其中,YOLOv10-S 比 RT-DETR-R18 快 1.8 倍,YOLOv10-B 相比 YOLOv9-C 延迟降低 46%。
主要贡献
-
本文解决了 YOLO 系列因依赖非极大值抑制(NMS)进行后处理而导致的效率低下问题,提出了一种一致的双重分配策略,实现无 NMS 训练,支持一对一标签分配和一致的匹配度量,从而在低推理延迟下实现端到端部署,并保持竞争力的精度。
-
提出了一种整体效率-精度驱动的模型设计策略,系统性地优化 YOLO 的关键组件,包括轻量级分类头、空间-通道解耦下采样、基于秩引导的模块设计,以及高效的局部自注意力模块,显著减少计算冗余的同时提升模型能力。
-
在 COCO 数据集上的大量实验表明,YOLOv10 实现了最先进的性能-效率权衡:YOLOv10-S 在相近 AP 水平下比 RT-DETR-R18 快 1.8 倍;YOLOv10-B 在相同性能下延迟降低 46%,参数减少 25%。
引言
研究人员利用 YOLO 基础目标检测器在自动驾驶、机器人等实时应用中的广泛部署,这些场景中精度与速度的平衡至关重要。先前的 YOLO 变体依赖非极大值抑制(NMS)进行后处理,引入延迟,阻碍端到端部署,并对超参数敏感。此外,YOLO 中的架构组件长期孤立优化,导致计算冗余和次优的效率与性能。为解决这些问题,研究人员提出 YOLOv10,新一代实时端到端检测器。其核心贡献包括:一种一致的双重分配策略,支持训练阶段的一对多监督与推理阶段的一对一预测,实现无 NMS 训练,确保高精度与低延迟。同时提出整体效率-精度驱动设计,集成轻量级分类头、空间-通道解耦下采样、基于秩引导的模块设计、大核卷积以及部分自注意力模块(PSA),以减少冗余并增强能力。结果表明,YOLOv10 在多个尺度上实现了最先进的精度-效率权衡,相比 YOLOv9 和 RT-DETR 等先前模型,在速度、参数量和 FLOPs 上均表现更优,同时保持或提升精度。
方法
研究人员采用双头架构,使 YOLO 模型实现无 NMS 训练,解决推理效率与性能之间的权衡。如图所示,该框架包含共享主干网络和 PAN(路径聚合网络)颈部,连接两个并行检测头。第一个为一对多头,在训练中通过将多个正预测分配给每个真实框,提供丰富的监督信号。第二个为一对一头,每个真实框仅分配一个预测,从而在推理阶段无需 NMS 后处理。两个头共享相同的网络结构和优化目标,但采用不同的标签分配策略。训练时,模型通过双头联合优化,使主干和颈部受益于一对多分支的丰富监督。推理时,一对多头被丢弃,仅由一对一头生成预测,实现端到端部署且无额外计算开销。该设计确保模型在训练中获得高精度,同时保持高推理效率。
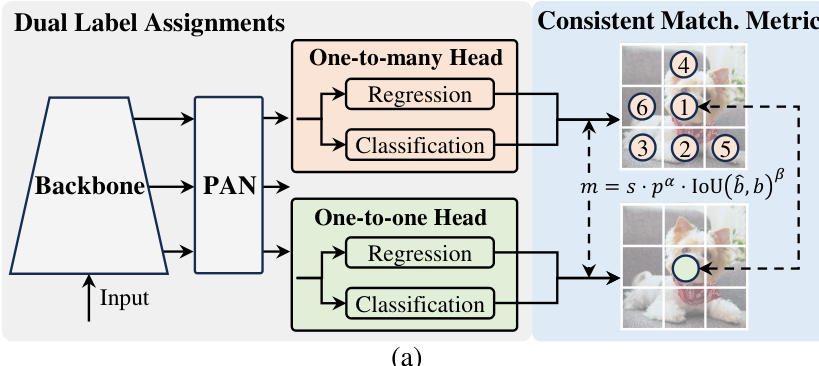
为确保一对一头的优化与一对多头保持一致,研究人员引入了一致匹配度量。该度量定义为 m=s⋅pα⋅IoU(b^,b)β,定量评估预测与真实框之间的匹配程度,其中 p 为分类得分,b^ 和 b 分别为预测与真实边界框,s 为空间先验,表示锚点是否位于目标区域内,α 和 β 为平衡分类与回归任务的超参数。研究人员为两个头采用统一的匹配度量,将一对一头的超参数(αo2o,βo2o)设置为与一对多头(αo2m,βo2m)成比例,具体为 αo2o=r⋅αo2m 和 βo2o=r⋅βo2m。这确保一对多头的最佳正样本也是对头头的最佳正样本,协调两分支的优化过程,缩小监督差距。这种一致性对一对一头学习高质量预测至关重要,使其与一对多头的优异性能保持对齐。
实验
- YOLOv10 在所有模型尺度上均达到最先进的性能与端到端延迟表现,优于 YOLOv8、YOLOv6、YOLOv9、YOLO-MS、Gold-YOLO 和 RT-DETR。在 COCO 上,YOLOv10-N/S 相比 YOLOv6-3.0-N/S 实现 1.5/2.0 AP 提升,参数减少 51%/61%,计算量降低 41%/52%;YOLOv10-L 相比 Gold-YOLO-L 参数减少 68%,延迟降低 32%,AP 提升 1.4%;YOLOv10-S/X 在相近精度下分别比 RT-DETR-R18/R101 快 1.8× 和 1.3×。
- 消融实验表明,采用一致双重分配的无 NMS 训练使 YOLOv10-S 的端到端延迟降低 4.63ms,同时保持 44.3% AP;效率驱动设计使 YOLOv10-M 参数减少 11.8M,FLOPs 降低 20.8 GFLOPs,延迟减少 0.65ms。
- 一致匹配度量通过对齐一对多与一对一头之间的监督,优化了 AP-延迟权衡,消除了超参数调优的需要。
- 基于精度驱动的设计引入大核卷积与部分自注意力(PSA)模块,使 YOLOv10-S 的 AP 分别提升 0.4% 和 1.4%,延迟增加极小;PSA 相比 Transformer 块实现 0.3% AP 提升与 0.05ms 延迟降低。
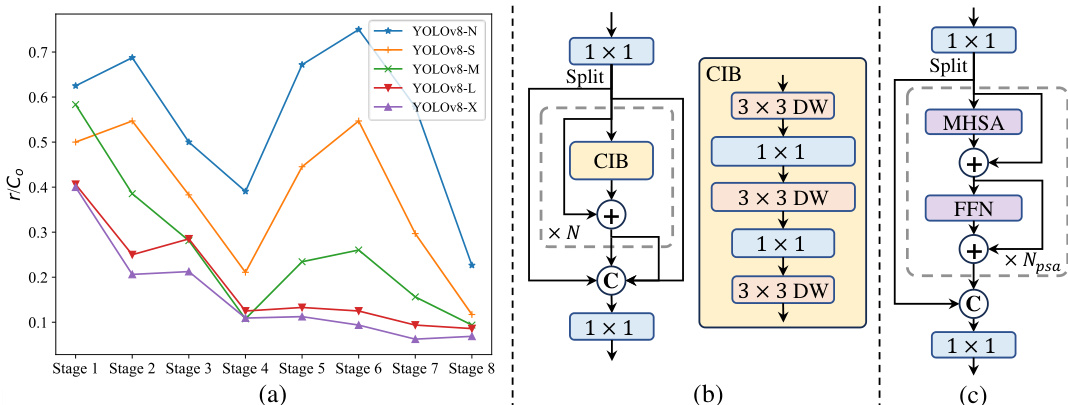
- 基于秩引导的模块设计使高冗余阶段高效集成 CIB,未造成性能损失,显著提升模型效率。
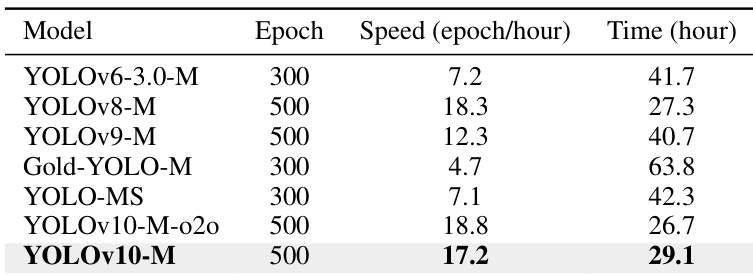
- 训练成本分析显示,尽管训练 500 轮,YOLOv10 仍保持高吞吐量,无 NMS 训练仅增加 18s/轮开销,优于其他训练 300 轮的模型。
- 在 CPU(OpenVINO)上,YOLOv10 展现出最先进的性能-效率权衡。
- 可视化结果验证了模型在低光、旋转、密集目标等复杂场景下的鲁棒检测能力。
实验结果表明,双重标签分配与一致匹配度量显著改善了 AP-延迟权衡,当两者同时应用时达到最佳性能,实现 44.3% AP 与 2.44ms 延迟。消融研究进一步证明,效率驱动设计在保持竞争力性能的同时减少参数与 FLOPs,凸显所提架构改进的有效性。

研究人员对比了 YOLOv10-M 与其他 YOLO 变体的训练效率,结果显示 YOLOv10-M 实现了每小时 17.2 轮的高训练吞吐量,在 8 块 NVIDIA 3090 GPU 上总训练时间为 29.1 小时。这表明,尽管采用 500 轮训练,YOLOv10 的训练成本仍远低于其他模型,具有可接受的训练开销。
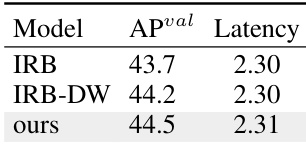
研究人员通过不同模型变体的对比,评估了所提出的紧凑反向块(CIB)设计的有效性。结果表明,基于 CIB 的模型相比 IRB-DW 提升 0.8% AP,同时保持相近延迟,证明该模块设计在不增加计算成本的前提下有效提升了性能。
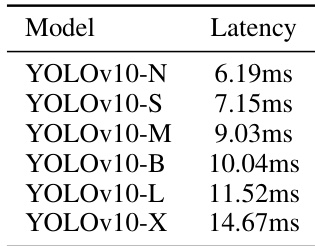
研究人员展示了 YOLOv10 在不同尺度下的延迟结果,表明模型越大,推理延迟越高。YOLOv10-N 延迟最低,为 6.19ms;YOLOv10-X 延迟最高,达 14.67ms,呈现出模型规模与延迟正相关的清晰趋势。
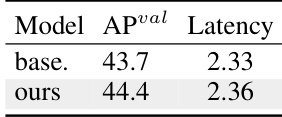
研究人员通过消融实验评估了所提无 NMS 训练与一致双重分配对 YOLOv10-S 的影响。结果表明,该方法将模型 AP 从 43.7% 提升至 44.4%,延迟仅增加 0.03ms,体现了精度与速度之间极小的权衡。