Command Palette
Search for a command to run...
InkSight:通过教导视觉-语言模型识写,实现离线到在线手写体转换
InkSight:通过教导视觉-语言模型识写,实现离线到在线手写体转换
摘要
数字笔记正日益受到欢迎,它提供了一种持久、可编辑且易于索引的笔记存储方式,以向量化形式呈现,即所谓的“数字墨水”(digital ink)。然而,这种数字化笔记方式与传统纸笔笔记之间仍存在显著差距,后者至今仍被绝大多数用户所青睐。我们的研究工作 InkSight 致力于弥合这一鸿沟,通过赋能实体笔记使用者,使其能够轻松地将手写笔记(离线书写)转化为数字墨水(在线书写),这一过程我们称之为“去渲染”(derendering)。以往相关研究主要聚焦于图像的几何特性,导致模型泛化能力受限,难以超越其训练数据的领域。相比之下,我们的方法融合了阅读与书写的先验知识,使得在缺乏大量成对样本(此类数据获取困难)的情况下仍可训练出高性能模型。据我们所知,这是首个能够有效处理任意照片中具有多样化视觉特征与背景的手写文本去渲染工作。此外,该方法还能泛化至简单的草图场景。人类评估结果显示,在具有挑战性的 HierText 数据集上,我们的模型生成的 87% 的样本被认定为对输入图像的有效追踪,其中 67% 的结果在视觉上与人类用笔绘制的轨迹极为相似。
一句话总结
来自 Google DeepMind 和 EPFL 的作者提出了 InkSight,这是一种视觉-语言模型,能够通过结合阅读与书写的先验知识,将任意照片中的手写内容反向还原为逼真的数字墨迹轨迹,实现超越训练域的泛化能力,且无需大规模成对数据集,适用于数字笔记记录和草图转换等场景。
主要贡献
- InkSight 是首个通过视觉-语言模型结合阅读与书写先验,实现“反渲染”——将任意手写文本照片转换为数字墨迹——的系统,从而在无需大量成对训练数据的情况下实现稳健性能。
- 该方法在多种手写风格、背景甚至简单草图上均达到当前最优的泛化能力,人工评估显示 87% 的输出为输入图像的有效描摹,67% 的轨迹与人类笔迹相似。
- 该方法采用简单而高效的架构,结合 ViT 编码器与 mT5 编码器-解码器,并公开发布模型、生成的 inkML 格式墨迹数据及专家标注数据,以支持后续研究。
引言
作者利用视觉-语言模型解决将离线手写内容——手写笔记的照片——转换为数字墨迹的挑战,这一过程称为反渲染。该能力弥合了传统纸笔笔记与现代数字工作流之间的鸿沟,使用户在保留手写自然感的同时,获得可编辑性、可搜索性以及与数字工具的集成能力。以往工作严重依赖几何先验和手工启发式规则,限制了其在特定书写系统、干净背景或受控条件下的泛化能力,且面临成对训练数据匮乏的问题。主要贡献在于提出一种新颖、数据高效的方案,通过多任务训练框架融合学习到的阅读与书写先验,使模型能够在无需大规模成对数据集的情况下推断笔画顺序与空间结构。系统基于 ViT 与 mT5 的简单架构,通过 OCR 引导的词段分割处理输入图像,并生成语义与几何上准确的数字墨迹序列。其在多样手写风格、复杂背景甚至简单草图上均表现出色,人工评估显示与真实笔迹高度一致。作者公开发布模型与数据集以支持未来研究。
数据集
- 数据集包含两个主要部分:公共数据集与内部收集的 OCR(文本图像)与数字墨迹(笔迹轨迹)数据。
- 公共 OCR 训练数据包括 RIMES、HierText、IMGUR5K、ICDAR'15 历史文档与 IAM,尽可能提取词级裁剪图像,共获得 29.5 万份拉丁字母样本。
- 公共数字墨迹数据来自 VNOOnDB、SCUT-Couch 与 DeepWriting;DeepWriting 按字符、词、行级别裁剪,VNOOnDB 提供单个词级墨迹,总计约 270 万样本。
- 内部 OCR 数据包含约 50 万样本,主要为手写(67%)与印刷体(33%),其中 95% 标注为英文。内部数字墨迹数据包含约 1600 万样本,以中文(37%)与日文(23%)为主。
- 所有 OCR 训练数据均经过筛选,确保图像每边至少 25 像素,宽高比在 0.5 至 4.0 之间,以适配 224×224 渲染。
- 数字墨迹经预处理:以 20 毫秒间隔重采样,使用 Ramer-Douglas-Peucker 算法简化以减少笔画长度,并归一化至 224×224 画布中心,坐标缩放至 [0, 224]。
- 墨迹被分词为离散标记:以笔画起始标记开头,随后为分别表示 x 与 y 坐标的标记,每个坐标四舍五入为整数,使用大小为 2N + 3 = 451 的词汇表(N = 224)。
- 完整标记集结合多语言 mT5 分词器(约 2 万个标记)与 451 个专用墨迹标记,实现文本与墨迹的联合建模,同时将模型规模减少约 80%。
- 反渲染训练中,数字墨迹样本使用 Cairo 图形库渲染为 224×224 图像,辅以随机增强,包括旋转、笔画与背景颜色、笔画粗细、背景噪声、网格与盒式模糊。
- 渲染与增强设计用于模拟真实世界变化,未观察到透视倾斜、平移或缩放带来的性能提升。
- 模型在 OCR 与数字墨迹数据的混合数据上训练,训练划分来自公共与内部数据集,混合比例针对反渲染与识别任务进行优化。
- 评估使用 IAM(约 1.76 万)、IMGUR5K(约 2.37 万)与过滤后的 HierText(约 1300 个手写词)的测试集,另使用约 200 个来自 HierText 的人工标注黄金样本作为参考与人工评估基准。
方法
作者采用一种混合视觉-语言模型架构,命名为 InkSight,专为数字墨迹的理解与生成设计。该框架整合了视觉 Transformer(ViT)编码器与 mT5 编码器-解码器 Transformer 模型。ViT 编码器使用预训练权重初始化,处理输入图像以提取视觉特征。这些特征随后输入 mT5 编码器-解码器,根据提供的任务特定指令生成输出。模型使用统一的标记词汇表,包含标准 mT5 字符标记与专用墨迹表示标记,使其能够处理文本与墨迹输出。训练期间,ViT 编码器权重被冻结,而 mT5 编码器-解码器从头训练以适应自定义标记集。该设计使模型可在单一统一框架内执行多项任务,包括从图像反渲染墨迹、文本识别以及从文本生成墨迹。

训练过程采用多任务混合策略以增强泛化性与鲁棒性。如图所示,训练混合包含五种不同任务类型:两种反渲染任务(生成墨迹输出)、两种识别任务(生成文本输出)以及一种混合任务(生成文本与墨迹输出)。每种任务由特定输入提示文本定义,引导模型在训练与推理阶段的行为。该设置使模型能够学习多种能力,如从图像生成逼真墨迹、识别图像中的文本,以及在单次推理中结合两项任务。所有任务在训练中随机打乱并赋予相等概率,确保各目标间均衡学习。

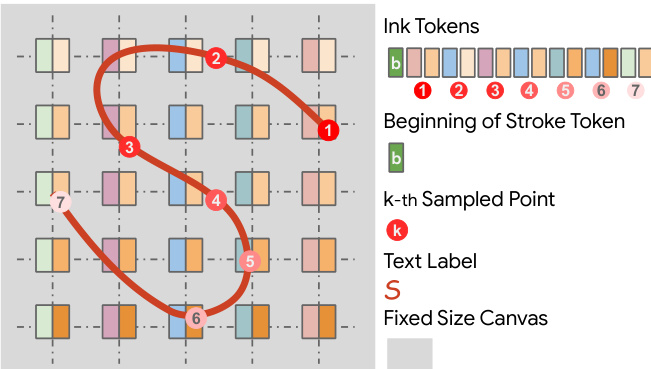
为在模型中表示墨迹,采用固定大小画布,每个位置对应一个标记。墨迹标记按序列组织,以捕捉笔画的空间与时间顺序。笔画起始由特殊标记标记,笔画上的后续点由索引标记表示,第 k 个采样点由标记 k 表示。文本标签也嵌入该标记序列中,使模型能够将墨迹笔画与对应文本内容关联。该分词方案使模型能够以结构化方式处理与生成墨迹,保留笔画与文本之间的空间关系。
实验
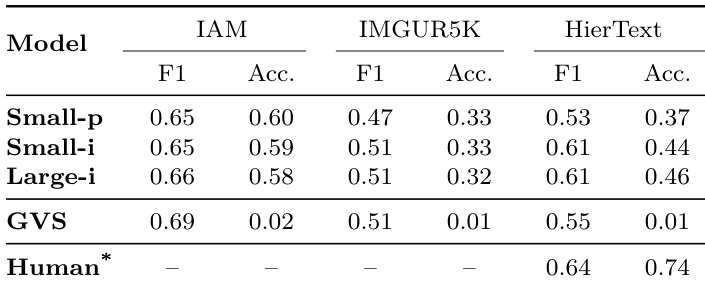
- Large-i 模型在 HierText 上优于 GVS 与较小变体,对真实数字墨迹的相似度更高,且对多样风格、遮挡与复杂背景的处理能力更强;在 IAM 与 IMGUR5K 上,性能与 GVS 相当,但更大规模下表现出更强鲁棒性。
- 在 200 个 HierText 样本的人工评估中,Large-i 模型获得最高比例的“良好描摹”与“类人”评分,性能随模型与数据规模提升而改善;常见错误包括细节缺失、多余笔画与重复描摹。
- 自动化评估确认模型排名与人工判断一致:Large-i 在 HierText 上取得最高字符级 F1 分数(0.58),在线手写识别的精确匹配准确率高达 78.2%,远超 GVS(接近 0%),表明其具备强大的语义与几何保真度。
- 训练中引入识别任务与数据增强显著提升反渲染质量与语义一致性;移除识别任务导致准确率下降并增加噪声误解释,而解冻 ViT 则引发不稳定与对背景噪声的过拟合。
- 模型可泛化至域外输入,如草图与多语言文本(如韩文、法文),但在未见书写系统上性能下降;Large-i 由于训练数据更广,相比 Small-p 具有更好鲁棒性。
- 使用 IAM 训练集反渲染的墨迹训练在线手写识别器,取得具有竞争力的 CER 表现(尤其与真实墨迹结合时),证明离线数据集可有效增强在线识别器训练。
- 使用文本输入进行推理(带文本反渲染)显著提升语义一致性,尤其在模糊输入下;而原始反渲染(Vanilla Derender)对噪声更鲁棒但语义准确性较低;回退机制可缓解解码过程中的任务混淆。
作者对比了在反渲染墨迹与真实墨迹上训练的模型在在线手写识别中的性能,以字符错误率(CER)为指标。结果表明,基于反渲染墨迹训练的模型 CER 略高于基于真实墨迹训练的模型,但结合两者数据可显著降低 CER,证明反渲染墨迹可有效增强真实数据用于训练。

作者在不同数据集上为模型变体使用不同的 dropout 与学习率,Small-i 与 Large-i 模型在 IAMOnDB 上使用较低学习率 0.001 与 dropout 0.25,而 Small-p 模型在 IAMOnDB 加上 IAM 反渲染数据上训练时使用较高学习率 0.005 与 dropout 0.3。结果表明,超参数选择取决于模型规模与训练数据,大模型通常采用更保守的学习率与 dropout 值。

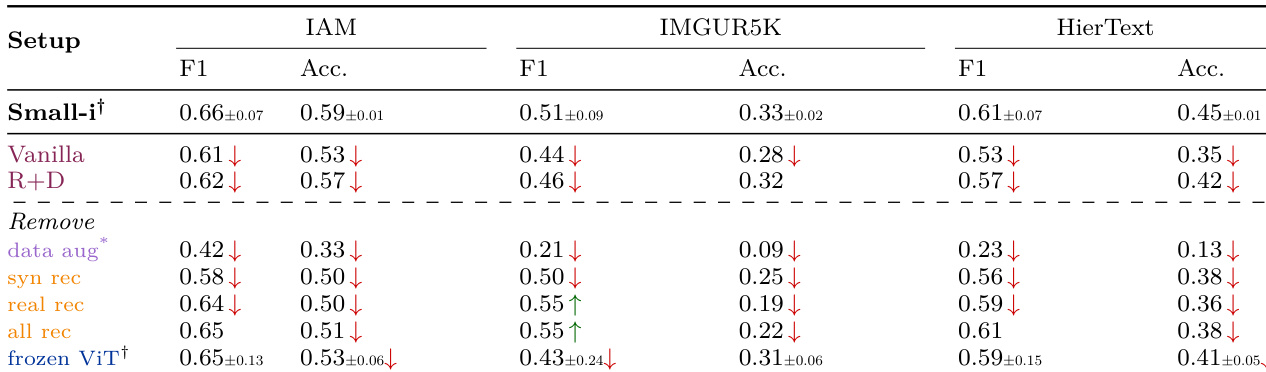
作者使用表 3 对 Small-i 模型进行消融研究,考察不同推理任务与设计选择的影响。结果表明,使用“带文本反渲染”任务优于其他推理模式,而移除数据增强或识别任务在所有数据集上均显著降低性能。
结果表明,Large-i 模型在 HierText 数据集上取得最高字符级 F1 分数,优于 Small-p 与 Small-i,而所有模型在 IAM 数据集上表现相近。GVS 基线在 IAM 上表现匹配或超过各模型,但在更复杂数据集上无法泛化,其在 HierText 上接近零的准确率即为明证。
作者对比了在 IAMOnDB 真实数字墨迹、IAM 反渲染墨迹以及两者结合数据上训练的在线手写识别器性能。结果表明,使用联合数据集训练的模型 CER 最低(4.6%),优于仅使用真实墨迹(6.1%)或仅使用反渲染墨迹(7.8%),表明反渲染墨迹可有效增强真实数据以提升识别性能。
