Command Palette
Search for a command to run...
LGM:用于高分辨率3D内容生成的大规模多视角高斯模型
LGM:用于高分辨率3D内容生成的大规模多视角高斯模型
Jiaxiang Tang Zhaoxi Chen Xiaokang Chen Tengfei Wang Gang Zeng Ziwei Liu
摘要
三维内容生成在质量和速度方面均取得了显著进展。尽管当前的前馈模型可在数秒内生成三维物体,但其分辨率受限于训练过程中所需的高计算开销。本文提出了一种名为大视图高斯模型(Large Multi-View Gaussian Model, LGM)的新框架,能够基于文本提示或单视图图像生成高分辨率三维模型。我们的核心思想包含两点:1)三维表示:提出多视图高斯特征作为高效且强大的三维表示方式,该表示可实现可微分渲染的融合;2)三维主干网络:设计了一种非对称U-Net结构作为高吞吐量的主干网络,用于处理多视图图像输入。这些多视图图像可通过多视图扩散模型从文本或单视图图像生成。 大量实验验证了所提方法在保真度与效率方面的优越性能。尤为突出的是,我们在保持生成速度低于5秒的前提下,将训练分辨率提升至512,从而实现了真正意义上的高分辨率三维内容生成。
一句话总结
北京大学、南洋理工大学与上海人工智能实验室提出LGM,一种前馈式框架,通过异构U-Net主干网络融合文本或单视图输入的多视角图像,在5秒内生成高分辨率3D高斯,突破了以往方法在分辨率与效率上的限制,利用高斯点绘(Gaussian splatting)与鲁棒数据增强,实现游戏、VR和影视领域中快速、高保真的3D内容生成。
主要贡献
-
本文针对高分辨率3D内容生成的挑战,提出LGM,一种前馈式框架,能够从单视图图像或文本提示生成精细的3D高斯,克服了以往前馈方法依赖低分辨率三平面表示所导致的分辨率瓶颈。
-
LGM提出一种新颖的异构U-Net主干网络,作用于多视角图像,高效预测并融合3D高斯特征,支持端到端可微渲染与训练,分辨率高达512,显著高于此前方法,同时保持低于5秒的快速推理速度。
-
该方法在文本到3D与图像到3D任务中均表现出色,生成高达65,536个高斯的高保真结果,并引入数据增强以弥合真实与合成多视角图像之间的域差距,同时提供通用的网格提取流程,适用于下游应用。
引言
作者利用3D高斯点绘作为高保真、高效的表示方式,实现从文本或单视图图像快速生成高分辨率3D内容。以往前馈方法依赖三平面NeRF或Transformer主干网络,受限于内存与渲染效率,导致分辨率受限;而基于优化的方法(如SDS)虽细节更丰富,但速度较慢。本文核心贡献是提出一种新颖框架,采用异构U-Net从多视角输入回归密集3D高斯,支持512×512分辨率下的端到端训练,可在5秒内生成高质量3D模型。该方法整合多视角扩散模型进行输入合成,应用针对性数据增强以应对域差距,并包含通用网格提取流程,在文本到3D与图像到3D任务中均达到当前最优的速度与分辨率。
数据集
- 数据集源自Objaverse,一个大规模3D物体库,通过预定义关键词列表进行筛选,剔除不相关或低质量场景。
- 筛选关键词包括:flying, mountain, trash, featuring, a set of, a small, numerous, square, collection, broken, group, ceiling, wall, various, elements, splatter, resembling, landscape, stair, silhouette, garbage, debris, room, preview, floor, grass, house, beam, white, background, building, cube, box, frame, roof, structure。
- 每个场景沿球面螺旋路径生成100个相机视角,确保空间覆盖的多样性和均匀性。
- 相机半径固定为1.5单位,垂直视场角设为49.1度,以保持一致的透视与深度。
- 作者将筛选并渲染后的视角作为训练数据的一部分,与其他数据集以精心平衡的比例混合使用。
- 未进行显式裁剪,而是使用完整渲染图像,同时在渲染流程中构建相机位姿与场景ID等元数据,以支持训练与评估。
方法
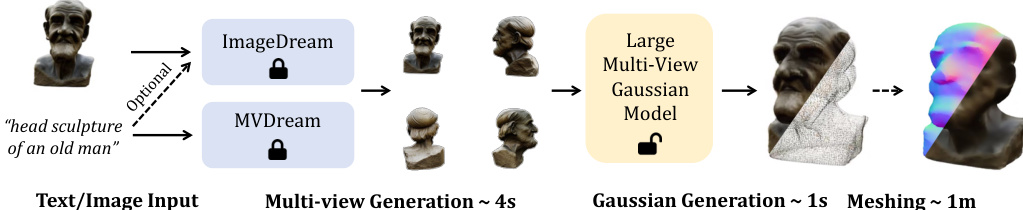
作者采用两步式流程实现高分辨率3D内容生成,首先使用现成模型从文本或图像输入合成多视角图像。具体而言,MVDream用于文本到多视角生成,ImageDream处理图像(及可选文本)输入,两者均生成四个固定仰角的正交视角图像。这些多视角图像作为核心U-Net模型的输入,用于预测并融合3D高斯。整体框架如流程图所示,初始多视角生成步骤后接高斯生成与可选网格提取。
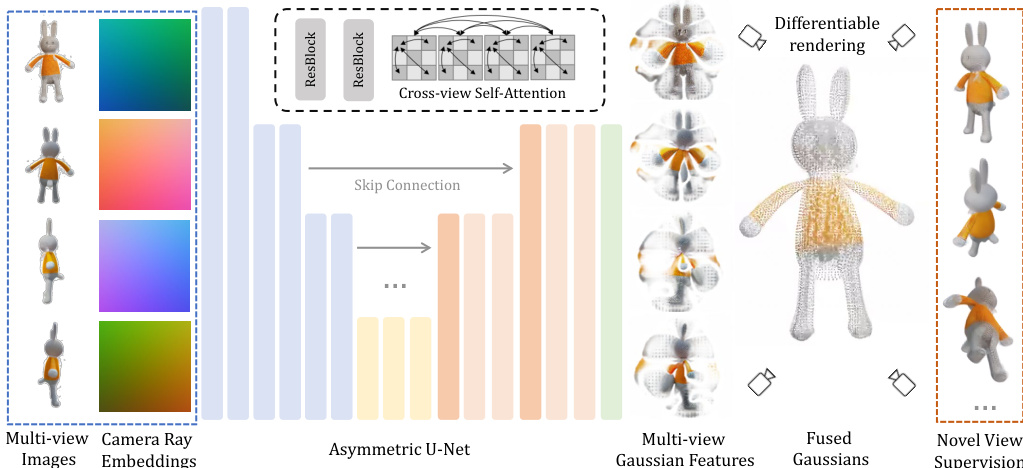
框架的核心组件是异构U-Net架构,如详细结构图所示。该网络接收四个输入图像及其对应的相机射线嵌入作为输入。RGB值与射线嵌入在像素级拼接,形成每个像素的9通道特征图,随后输入U-Net处理。架构包含残差层与自注意力机制,自注意力仅在深层应用以降低内存消耗。为实现跨视角信息传播,四个输入视角的特征在自注意力前被展平并拼接。U-Net输出为14通道特征图,解释为3D高斯的参数。网络设计为异构结构,输出分辨率低于输入,允许更高分辨率输入的同时限制输出高斯数量。预测的高斯参数(包括位置、尺度、旋转、不透明度与颜色)在四个视角间融合,形成最终的3D高斯表示。
为确保训练鲁棒性,作者实施数据增强策略,弥合训练数据(来自Objaverse数据集渲染)与推理数据(由扩散模型合成)之间的域差距。包括网格畸变(grid distortion),即随机扭曲三个输入视角以模拟多视角扩散输出中的不一致性;以及轨道相机抖动(orbital camera jitter),即随机旋转后三个视角的相机位姿围绕场景中心,以应对射线嵌入中的误差。模型使用可微渲染器监督生成的高斯。每个训练步骤中,从八个视角(四个输入视角与四个新视角)渲染图像,并在RGB与Alpha图像上计算均方误差损失。此外,对RGB图像应用基于VGG的LPIPS损失,以提升感知质量。
实验
- 图像到3D:相较于[47, 62],本方法生成的3D高斯具有更高视觉质量与更好内容保真度,支持平滑纹理网格且质量损失极小。多视角设置有效减少后视图模糊与平面几何问题,提升未见视角的细节表现。
- 文本到3D:在真实感与效率上优于[16, 47],实现更优的文本对齐,且因多视角扩散建模避免了多面问题。
- 多样性:在模糊文本或单视图输入下展现出高3D生成多样性,不同随机种子生成的物体形态各异且合理。
- 用户研究(表1):在30张图像上,20名志愿者评估600个样本;本方法在图像一致性与整体质量上得分最高,优于DreamGaussian [47] 与 TriplaneGaussian [62]。
- 消融研究:单视图输入导致后视图重建效果差且模糊;数据增强提升3D一致性与相机位姿准确性;更高训练分辨率(512×512)相比256×256生成更精细细节。
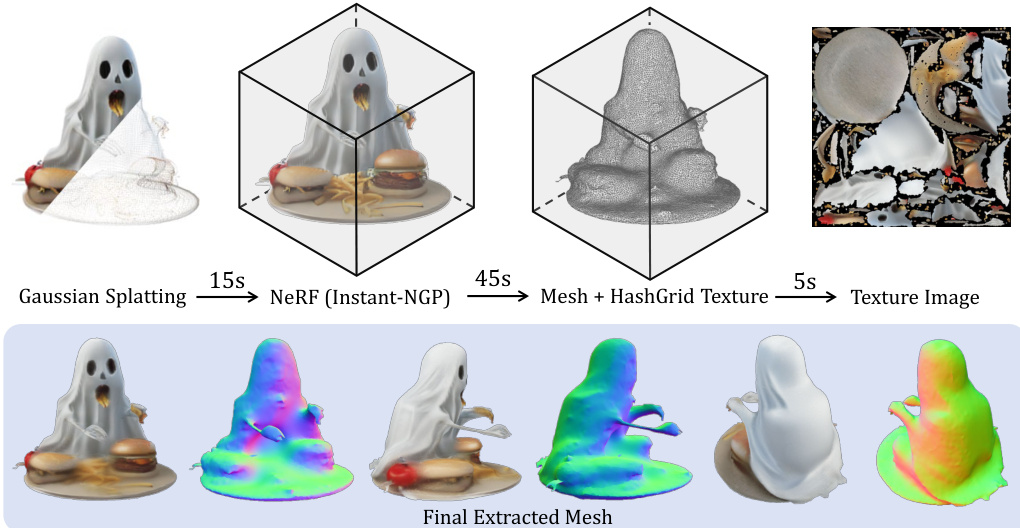
- 网格化:本方法生成的网格表面比DreamGaussian [47] 更平滑,且独立于底层高斯分布,有利于再照明。
- 局限性:失败主要源于低分辨率(256×256)多视角图像,导致细长结构不准确,高仰角视角出现问题。
实验结果表明,所提方法LGM在图像一致性和整体质量上均优于DreamGaussian与TriplaneGaussian。作者通过用户研究评估生成的3D高斯,LGM在与输入图像内容对齐程度与整体模型质量上均显著优于基线方法。
