Command Palette
Search for a command to run...
迈向卓越的规模:面向真实世界中照片级图像恢复的模型扩展实践
迈向卓越的规模:面向真实世界中照片级图像恢复的模型扩展实践
Fanghua Yu Jinjin Gu Zheyuan Li Jinfan Hu Xiangtao Kong Xintao Wang Jingwen He Yu Qiao Chao Dong
摘要
我们提出SUPIR(Scaling-UP Image Restoration),一种开创性的图像修复方法,该方法融合了生成先验(generative prior)与模型规模扩展的强大能力。通过结合多模态技术与先进的生成先验,SUPIR在智能化、逼真的图像修复领域实现了显著突破。作为SUPIR的核心驱动力,模型规模扩展显著提升了其性能,并展现出图像修复任务中的全新潜力。我们构建了一个包含2000万张高分辨率、高质量图像的数据集用于模型训练,每张图像均配有详尽的文本描述注释。SUPIR具备根据文本提示进行图像修复的能力,极大地拓展了其应用场景与实用价值。此外,我们引入负向质量提示(negative-quality prompts),进一步优化了修复结果的感知质量。同时,我们设计了一种基于修复引导的采样方法,有效缓解了基于生成模型修复中常见的保真度问题。实验结果表明,SUPIR不仅展现出卓越的修复效果,更首次实现了通过文本提示对修复过程进行可控调节的创新能力。
一句话总结
中国科学院深圳先进技术研究院、上海人工智能实验室、香港理工大学、ARC实验室、腾讯PCG以及香港中文大学的作者们提出了SUPIR,一种可扩展的生成式图像修复模型,该模型利用包含文本标注的2000万张图像数据集,通过文本提示实现可控修复,包括负质量提示和修复引导采样,显著提升了感知质量和语义保真度,优于以往方法。
主要贡献
-
SUPIR提出了一种大规模图像修复框架,利用参数量达26亿的Stable Diffusion XL(SDXL)模型作为生成先验,并结合一种新颖的ZeroSFT连接器和参数量达130亿的多模态语言模型,无需依赖特定退化假设,即可在多种退化类型下实现高度真实且智能的修复。
-
该方法在新收集的2000万张高分辨率、高质量图像数据集上进行训练,包含详细的文本标注,并引入负质量提示和修复引导采样策略,在保持输入保真度的同时提升感知质量,有效应对生成式修复中的关键挑战。
-
SUPIR在真实世界图像修复任务中达到最先进性能,通过文本提示展现出卓越的视觉质量和可控性——支持细粒度操作,如材质指定、语义调整和物体修复——在复杂真实退化场景下通过大量实验得到验证。
引言
作者利用大规模生成模型与模型扩展技术,推动真实场景中照片级图像修复的发展,这些场景下的图像遭受多样且复杂的退化。以往方法通常依赖特定任务假设或有限的生成先验,限制了其泛化能力和感知质量。模型扩展受到工程挑战的制约,包括计算成本高、架构不兼容以及因不可控生成导致的保真度损失。为克服这些问题,作者提出SUPIR,一种基于Stable Diffusion XL的可扩展图像修复框架,采用新颖的ZeroSFT连接器,实现无需全量微调的高效适配。模型在包含丰富文本标注的2000万张图像数据集上训练,并使用参数量达130亿的多模态模型生成准确提示。关键创新包括负质量提示以引导感知质量,以及修复引导采样策略以保持输入保真度。最终成果是一个高度可控、最先进的修复系统,能够实现语义感知、文本驱动的图像增强。
数据集
- 数据集包含2000万张高分辨率 1024×1024 图像,源自自建数据集,选材标准为高质量与纹理丰富性,解决了图像修复(IR)领域缺乏大规模高质量图像数据集的问题。
- 额外包含70,000张未对齐的高分辨率人脸图像,来自FFHQ-raw数据集,以增强模型的人脸修复能力。
- 训练时混合使用自建数据集与FFHQ-raw数据,其中自建图像构成主要训练集。
- 所有训练图像均配有文本标注,以支持多模态语言引导,使模型在训练和推理阶段均可使用文本提示。
- 采用新策略:基于负质量提示(如“模糊”、“低分辨率”、“脏污”)使用SDXL生成10万张低质量图像,并加入训练数据,以提升模型在无分类器引导(CFG)中对负提示的理解与响应能力。
- 训练过程中,模型采用改进的SDXL架构,包含裁剪后的编码器副本和ZeroSFT连接器,实现高效且有效的特征融合。
- 图像处理流程包括:使用专用编码器 Edr 对低质量输入进行退化鲁棒编码,随后通过退化模型 D 处理,将输入送入LLaVA多模态大语言模型,生成用于提示的文本描述。
- 训练过程在CFG中同时使用正向与负向提示,模型被训练以平衡这些信号,确保提升感知质量并减少伪影。
方法
作者将SDXL模型作为图像修复的生成先验,选择其Base模型,因其具备直接生成高分辨率图像的能力,且适用于高质量数据集的训练。这一选择避免了SDXL的Base-Refine策略带来的冗余,该策略在以提升图像质量而非理解文本为目标时效果较差。为有效整合低质量(LQ)输入,框架采用退化鲁棒编码器,经微调后将LQ图像映射至预训练SDXL模型的同一潜在空间。该微调过程最小化退化图像与真实图像解码输出之间的差异,确保编码器准确表示LQ输入内容,而不将伪影误认为有意义特征。

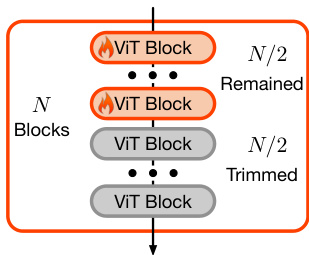
核心适配机制通过一种新型适配器实现,称为“裁剪ControlNet”,旨在根据提供的LQ输入引导SDXL模型进行图像修复。该适配器基于ControlNet架构,但专为可扩展性和高效性设计。作者通过裁剪可训练副本中每个编码器块内的半数视觉Transformer(ViT)块实现这一目标,如下方图示所示。该裁剪策略在保留ControlNet核心特性——大网络容量与有效初始化——的同时,使模型适用于SDXL的规模。该适配器被训练以识别LQ图像内容,并在像素级别对生成过程施加精细控制。
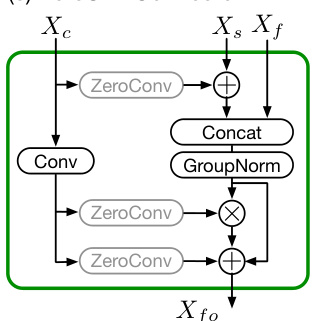
为进一步增强LQ引导的影响,作者重新设计了适配器与SDXL模型之间的连接器。该新连接器名为ZeroSFT,是零卷积操作的扩展。它引入额外的空间特征传输(SFT)操作和组归一化,实现对扩散过程更有效的调制。ZeroSFT模块处理LQ图像的潜在表示以及当前扩散步骤的潜在状态,生成一个优化后的引导信号,并将其融入生成过程。
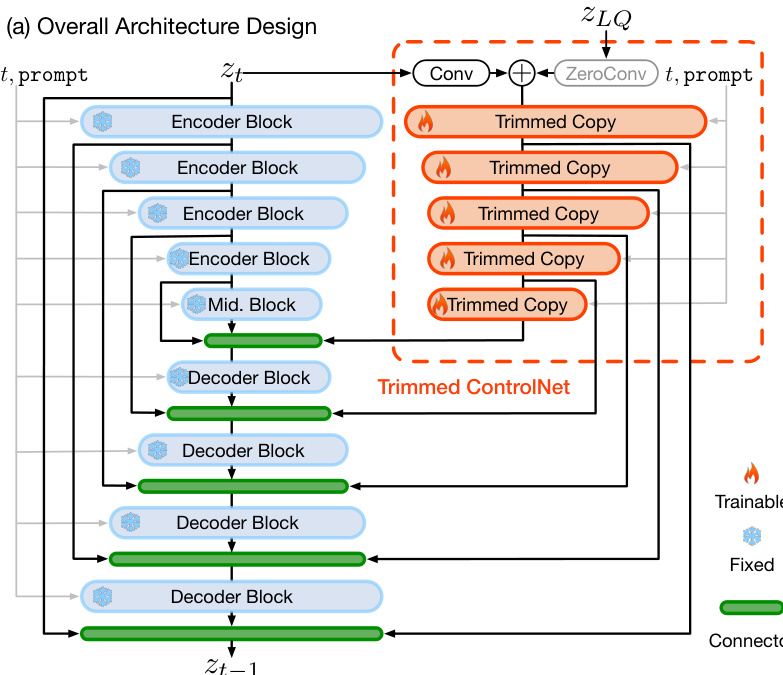
整体框架如下方图示所示,将这些组件整合为一个连贯系统。低质量图像首先由退化鲁棒编码器编码为潜在表示 zLQ。该潜在表示与多模态大语言模型生成的文本提示一同输入裁剪ControlNet。控制信号随后用于引导预训练的SDXL模型通过扩散过程,采用修复引导采样方法进行采样。该方法修改EDM采样算法,在扩散早期阶段有选择性地引导预测结果向LQ潜在表示靠拢,确保输入保真度,同时在后期阶段允许生成高频细节。
实验
- 在2000万张高质量图像-文本对、7万张人脸图像以及10万张负质量样本上训练,使用合成退化模型;在64块A6000 GPU上,以256的批量大小,10天内完成1024×1024图像的高保真修复。
- 在合成数据上,优于最先进方法(BSRGAN、Real-ESRGAN、StableSR、DiffBIR、PASD)的非参考指标(ManIQA、ClipIQA、MUSIQ),尽管PSNR/SSIM较低,凸显了指标与人类评估之间的不一致。
- 在60张真实世界低质量图像上,用户研究(20名参与者)显示其感知质量最高,显著优于现有方法,并在建筑和自然景观等复杂场景中保持结构保真度。
- 消融实验验证了所提ZeroSFT连接器优于零卷积,提升保真度而不牺牲感知质量;大规模数据训练对高质量修复至关重要。
- 修复引导采样中 τ_r = 4 时,保真度与感知质量达到良好平衡;负质量提示与训练样本显著提升输出质量并减少伪影。
- 退化鲁棒编码器有效降低低质量输入中的噪声与模糊,防止生成模型将伪影误认为内容。
- 文本提示实现可控修复,可准确重建缺失细节(如自行车部件、帽子纹理)和语义操作(如人脸属性),但当提示与输入内容矛盾时无效。
作者将所提ZeroSFT连接器与零卷积进行对比,结果显示ZeroSFT在所有指标上均表现更优,尤其在PSNR和SSIM等全参考指标上,同时保持强劲的非参考指标得分。这表明ZeroSFT在不牺牲感知质量的前提下,更好地保持了图像保真度。

结果表明,所提方法在所有退化类型下,于非参考指标(如ManIQA、ClipIQA、MUSIQ)上均取得最佳性能,表明其具有卓越的感知质量。尽管在全参考指标(如PSNR和SSIM)上表现具有竞争力,但并未始终优于其他方法,凸显了保真度与感知真实感之间的权衡。
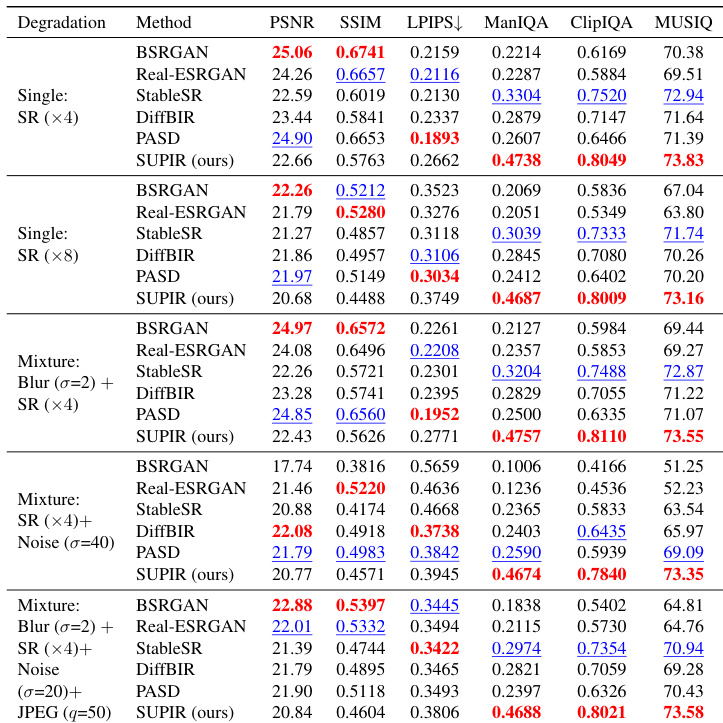
结果表明,所提方法在非参考指标CLIP-IQA、MUSIQ和MANIQA上均取得最佳表现,超越所有对比方法。在PASD指标上位列第二,而Real-ESRGAN和StableSR在PSNR和SSIM等全参考指标上表现更优,再次凸显感知质量与传统指标得分之间的权衡。

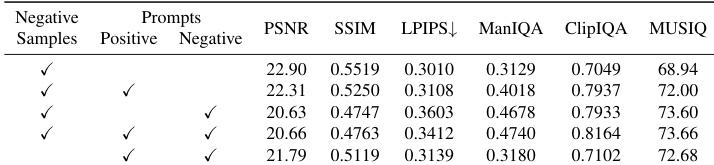
作者开展消融研究,评估负样本、正向提示与负向提示对图像修复质量的影响。结果表明,使用负样本对实现有效的提示驱动改进至关重要,若缺失则正负提示均无法提升感知质量。当三者协同使用时,方法在所有指标上均达到最佳表现,尤其在ManIQA、ClipIQA和MUSIQ等非参考指标上,表明其具有卓越的感知质量。