Command Palette
Search for a command to run...
基于单个非自回归Transformer的掩码音频生成
基于单个非自回归Transformer的掩码音频生成
Alon Ziv Itai Gat Gael Le Lan Tal Remez Felix Kreuk Alexandre Défossez Jade Copet Gabriel Synnaeve Yossi Adi
摘要
我们提出MAGNeT,一种直接作用于多路音频标记(audio tokens)序列的掩码生成建模方法。与以往工作不同,MAGNeT采用单阶段、非自回归的Transformer架构。在训练阶段,模型基于掩码调度器(masking scheduler)生成的掩码片段进行预测;在推理阶段,则通过多个解码步骤逐步构建输出序列。为进一步提升生成音频的质量,我们引入一种新颖的重评分(rescoring)机制:利用一个外部预训练模型对MAGNeT的预测结果进行重评分与排序,从而为后续解码步骤提供更优的候选序列。此外,我们探索了一种混合版本的MAGNeT,该版本将自回归与非自回归模型相结合——先以自回归方式生成序列的前几秒,随后其余部分则并行解码。我们展示了MAGNeT在文本到音乐及文本到音频生成任务中的高效性,并进行了全面的实证评估,涵盖客观指标与人类主观评测。实验结果表明,该方法在生成质量上可与现有基线相媲美,同时显著提升推理速度(相比自回归基线快约7倍)。通过消融实验与深入分析,我们揭示了MAGNeT各组件的重要性,并系统探讨了自回归与非自回归建模在延迟(latency)、吞吐量(throughput)与生成质量之间的权衡关系。更多生成样例可访问我们的演示页面:https://pages.cs.huji.ac.il/adiyoss-lab/MAGNeT。
一句话总结
Meta FAIR、Kyutai 与耶路撒冷希伯来大学的研究人员提出 MAGNET,一种用于文本到音乐和文本到音频生成的单阶段非自回归 Transformer 模型,采用掩码标记预测和基于外部预训练模型的新型重评分机制,在保持竞争力质量的同时,推理速度比自回归基线快达 7 倍,其混合变体支持早期自回归精炼以提升连贯性。
主要贡献
- MAGNET 引入了一种单阶段、非自回归 Transformer 模型,通过在训练中预测掩码片段并在推理中迭代优化输出,直接从多流离散标记生成音频,相比自回归基线实现更快生成速度,同时保持高质量。
- 该方法结合了一种新颖的重评分机制,利用外部预训练模型对 MAGNET 的预测结果进行排序与优化,在不增加推理延迟的前提下显著提升音频质量。
- MAGNET 的混合变体结合了自回归与非自回归解码——先自回归生成初始片段,再并行生成剩余部分——在质量、延迟与吞吐量之间取得平衡,评估显示在文本到音乐和文本到音频任务上推理速度比自回归模型快达 x7。
引言
研究人员利用自监督音频表征学习和序列建模的最新进展,解决高质量、低延迟条件音频生成的挑战——这对数字音频工作站中的音乐创作等交互式应用至关重要。以往工作依赖于自回归模型(因逐个生成标记导致高推理延迟)或扩散模型(需数百步才能达到高保真度,且难以处理长音频合成)。本文提出 MAGNET,一种单阶段非自回归 Transformer 模型,通过迭代预测多流离散表征中的掩码片段来生成音频,实现并行解码和显著更快的推理。其核心贡献包括:一种新颖的掩码生成框架,可在高达 7 倍速度提升下实现 30 秒音频生成;一种利用外部预训练模型增强质量的重评分方法;以及一种结合自回归与非自回归解码的混合变体,以提升整体性能。
数据集
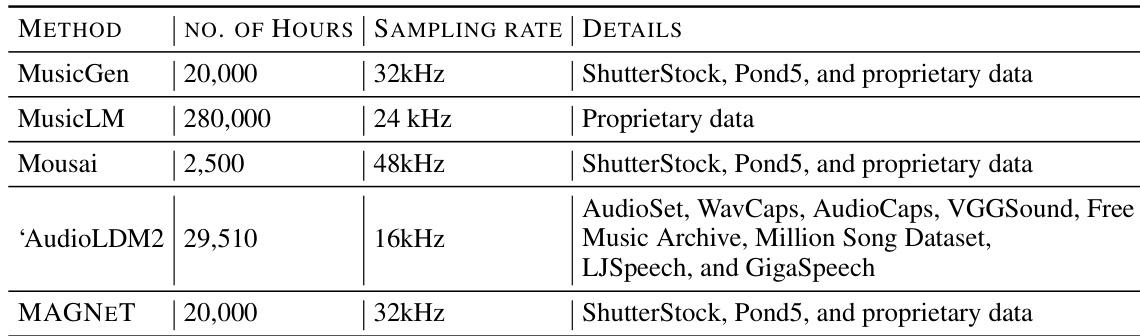
- 数据集包含 20K 小时的授权音乐,遵循 Copet 等人(2023)的设置,用于训练 MAGNET 模型。
- 数据集包含三个主要来源:
- 10K 高质量音乐曲目,来自精心筛选的集合。
- 25K 仅乐器曲目,来自 Shutterstock。
- 365K 仅乐器曲目,来自 Pond5。
- 所有曲目均为完整长度,采样率为 32 kHz,附带包括文本描述、流派、BPM 和标签在内的元数据。
- 评估使用 MusicCaps 基准,包含 5.5K 由专业音乐家创作的 10 秒样本,以及一个 1K 个样本的流派平衡子集。
- 客观指标在非平衡 MusicCaps 集上报告,而定性评估使用流派平衡子集的样本。
- 消融实验在 Copet 等人(2023)使用的域内测试集上进行。
- 训练数据经过处理以确保音频格式和元数据结构一致,未提及显式裁剪——完整曲目原样使用。
- 模型训练采用三种数据源的混合,训练划分比例与 Copet 等人(2023)原始设置一致。
方法
研究人员采用非自回归 Transformer 架构进行音频生成,以输入文本的语义表示为条件。模型直接作用于 EnCodec 分词器生成的离散音频标记,该分词器通过残差向量量化(RVQ)生成多个并行标记流。每一流对应一个码本,首个码本捕捉音频的粗粒度特征,后续码本通过编码量化误差逐步细化信号。MAGNET 的核心框架旨在以单阶段、非自回归方式生成这些标记序列,相比传统自回归模型实现更快推理。
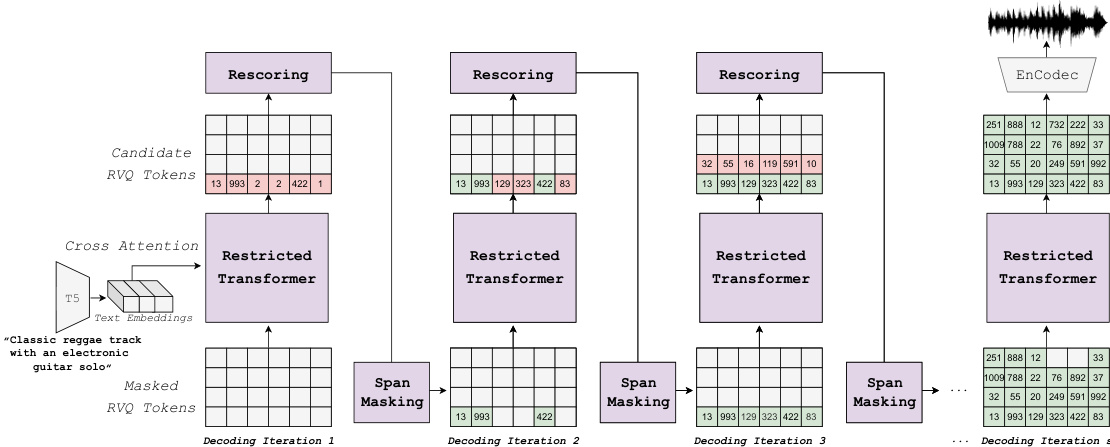
如上图所示,整体框架由迭代解码步骤构成,模型逐步优化部分生成序列。过程从完全掩码的标记序列开始。在每次解码迭代中,根据预定义的掩码调度器对部分标记片段进行掩码。随后,模型使用受限的 Transformer 架构预测掩码位置的标记。为提升生成音频质量,引入一种新颖的重评分机制:外部预训练模型对候选预测进行评估与排序。最终标记选择基于模型置信度与重评分模型概率的凸组合。该过程重复固定次数的解码步骤,逐步构建输出序列。
MAGNET 的关键创新在于其掩码策略,该策略作用于标记片段而非单个标记。这一设计解决了由于音频编码器感受野导致的相邻标记间信息泄露问题。研究人员评估了多种片段长度,发现 60ms 的片段长度表现最优。掩码过程经过精心设计,通过采样一定数量的片段,使预期掩码率与调度器输出一致。推理过程中,模型选择置信度最低的片段进行重新掩码,有助于聚焦于序列中最不确定的部分进行优化。
为进一步提升模型优化效果,MAGNET 引入了受限上下文机制。鉴于 RVQ 的层级结构(后续码本高度依赖早期码本),自注意力机制被限制仅能关注约 200ms 的有限时间窗口内标记。该限制基于对 EnCodec 编码器有效感受野的分析,尽管存在 LSTM 模块,其感受野仍被限制。通过限制上下文,模型能更专注于相关信息,避免对局部噪声的过拟合。
推理过程还通过无分类器指导退火机制进一步增强。训练期间,模型同时在条件与无条件两种情况下进行优化;推理时,采样分布为这两种概率的线性组合。指导系数在迭代解码过程中逐渐退火,初始值较高以确保强文本提示遵循,随后逐步降低,使模型能更专注于上下文填充。该方法有助于在文本遵循性与音频质量及稳定性之间取得平衡。
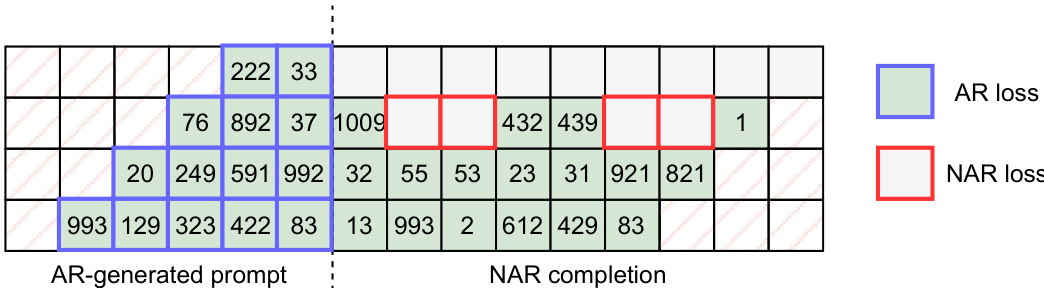
最后,研究人员探索了 MAGNET 的混合版本,结合自回归与非自回归建模。该混合方法以自回归方式生成音频序列的初始部分,确保高质量,随后切换至非自回归解码完成剩余部分,实现显著的速度提升。该混合模型的训练采用联合目标,结合自回归与非自回归损失函数,过渡点由随机采样的时间步决定。
实验
- MAGNET 在文本到音乐和文本到音频生成任务上进行评估,使用与 Copet 等人(2023)和 Kreuk 等人(2022a)相同的训练数据,采用 EnCodec 作为音频分词器,T5 作为文本条件模型。
- 在 MusicCaps 基准上,MAGNET-small(300M)和 MAGNET-large(1.5B)在 FAD 和 CLAP 指标上与 MusicGen 和 AudioLDM2 相当,但速度显著更快——在小批量下延迟降低高达 10 倍。
- 在 30 秒音频上训练时,MAGNET 实现 10 秒生成的 FAD 为 2.9,CLAP 得分为 0.31,且随着序列长度缩短而进一步提升。
- 混合 MAGNET(结合自回归提示生成与非自回归补全)在 FAD 上优于全自回归基线(0.61),同时将延迟从 17.6 秒降至 3.2 秒。
- 消融实验表明,使用 3 个片段(60ms)的跨度掩码和时间受限上下文可改善 FAD,CFG 退火(λ₀=10, λ₁=1)表现最佳。
- 重评分可提升指标但增加推理时间,而减少高层码本的解码步数对质量影响极小,可将延迟降至 370ms,仅导致 FAD 增加 8%。
- 在 AudioCaps 上,MAGNET 性能与自回归 AudioGen 相当,但延迟显著更低。
研究人员使用 MAGNET 从文本生成音乐,并与 MusicGen 和 AudioLDM2 等基线进行比较。结果表明,MAGNET-small 的 FAD 和 CLAP 得分低于 MusicGen-small,但主观质量相当,且在延迟和解码步数上显著更快。
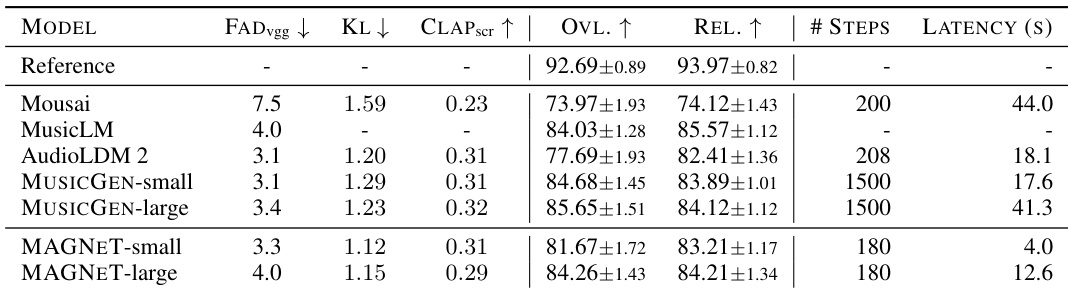
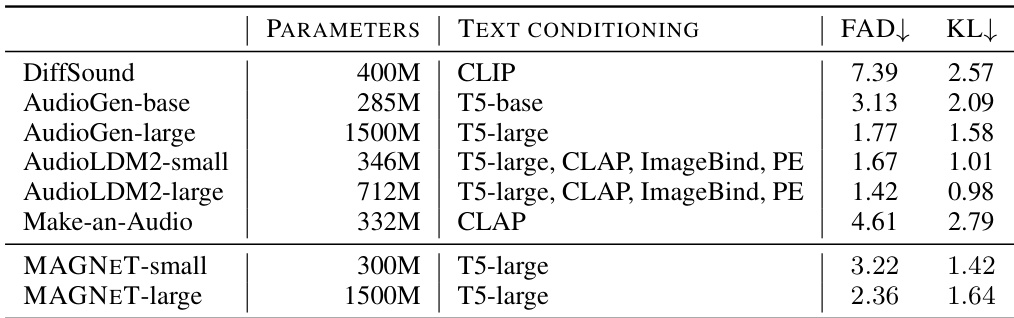
研究人员使用 MAGNET-small 和 MAGNET-large 模型生成文本条件音乐,性能与其它文本到音乐基线相当。结果表明,MAGNET-small 和 MAGNET-large 的 FAD 和 KL 得分均低于 DiffSound、AudioGen-base 和 Make-an-Audio,与 AudioLDM2-small 和 AudioLDM2-large 相当,其中 MAGNET-large 在所有模型中取得最佳 FAD 和 KL 得分。
研究人员评估了条件指导(CFG)退火对模型性能的影响,采用不同配置的指导系数 λ₀ 和 λ₁。结果表明,从 λ₀ = 10 退火至 λ₁ = 1 时获得最佳 FAD 得分,表明音频质量提升,同时 KL 和 CLAP 得分也具有竞争力,说明在音频-文本对齐与分布保真度之间取得良好平衡。

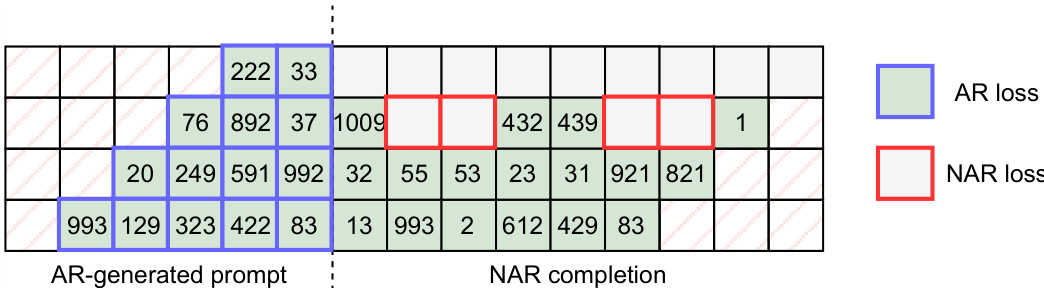
研究人员采用混合方法:先由自回归模型生成短音频提示,再由非自回归模型完成剩余部分。表格展示了该过程,显示自回归生成初始标记,随后非自回归完成剩余序列。
研究人员使用 MAGNET 进行文本到音乐生成,并与 MusicGen、MusicLM、Mousai 和 AudioLDM2 等基线进行比较,使用 MusicCaps 基准。结果表明,MAGNET 在性能上可与使用自回归建模的 MusicGen 相媲美,同时在延迟和解码步数上显著更快。