Command Palette
Search for a command to run...
ScribblePrompt: 面向各类生物医学图像的高效且灵活的交互式分割方法
ScribblePrompt: 面向各类生物医学图像的高效且灵活的交互式分割方法
Halle E. Wong Marianne Rakic John Guttag Adrian V. Dalca
摘要
生物医学图像分割是科学研究与临床护理中的关键环节。在拥有充足标注数据的情况下,可以通过训练深度学习模型来自动、准确地完成特定的生物医学图像分割任务。然而,通过人工分割图像来构建训练数据不仅极其耗费人力,还需要深厚的领域专业知识。我们提出了 ScribblePrompt,这是一种基于神经网络的灵活交互式生物医学图像分割工具,它允许人类标注人员通过 scribble(涂鸦)、click(点击)和 bounding box(边界框)来分割此前未见过的结构。通过严谨的定量实验,我们证明了在交互量相当的情况下,对于训练过程中未涉及的新数据集,ScribblePrompt 比以往的方法能够生成更准确的分割结果。在针对领域专家的用户研究中,与次优方法相比,ScribblePrompt 在将 Dice 系数提高 15% 的同时,将标注时间缩短了 28%。ScribblePrompt 的成功源于一系列精心的设计决策。其中包括:一种结合了高度多样化的图像集与任务的训练策略;用于模拟用户交互与标签的新型算法;以及一个能够实现快速 inference 的网络架构。我们通过交互式 Demo 展示了 ScribblePrompt 的功能,并提供了代码,同时在 https://scribbleprompt.csail.mit.edu 发布了一个 scribble 标注数据集。
一句话总结
来自 MIT 的研究人员提出了 ScribblePrompt,这是一种基于神经网络的灵活交互式分割工具。该工具利用 scribble、click 和 bounding box 来分割未见过的生物医学结构。通过多样化的训练策略和新颖的模拟交互算法,该方法比以往的方法减少了 28% 的专家标注时间,并将 Dice 分数提高了 15%。
核心贡献
- 本文引入了 ScribblePrompt,这是一个基于神经网络的灵活交互式分割框架,支持包括 scribble、click 和 bounding box 在内的多种用户输入。该方法允许在推理时对先前未见过的生物医学结构进行分割,而无需进行特定任务的重新训练。
- 该工作提出了用于模拟真实用户交互和生成合成标签的新颖算法,这有助于在高度多样化的图像和任务集上进行训练。这种模拟引擎使模型能够有效地泛化到新的数据集和专门的医学成像模态。
- 实验结果和用户研究表明,该系统优于以往的方法,与次优的基准模型相比,Dice 分数提高了 15%,标注时间减少了 28%。ScribblePrompt-UNet 架构还提供了能够在 CPU 上运行的计算效率。
引言
准确的生物医学图像分割对于临床护理和科学研究至关重要,但手动标注仍然是一个劳动密集型过程,需要大量的领域专业知识。现有的深度学习方法通常难以泛化,因为它们通常针对特定任务或模态进行训练,在遇到未见过的结构时会失效。虽然像 SAM 这样的视觉基础模型显示出潜力,但它们在细微的生物医学轮廓描绘上表现往往不佳,且所需的交互类型有限。研究人员利用名为 ScribblePrompt 的新框架,通过 scribble、click 和 bounding box 在各种生物医学图像上实现灵活的交互式分割。通过引入新颖的 scribble 模拟引擎和多样化的训练策略,该工具可以在无需重新训练的情况下泛化到未见过的任务,在显著减少标注时间的同时提高分割精度。
数据集
研究人员使用以下数据策略开发了一个全面的生物医学成像框架:
- 数据集组成与来源:训练集构建在 MegaMedical 等大规模工作之上,包含 77 个开放获取的生物医学成像数据集。该集合包括跨越 16 种图像类型和 711 个标签的 54,000 多次扫描,涵盖了大脑、胸部、腹部、脊柱、细胞、皮肤、眼睛等多个领域。
- 任务定义与处理:
- 2D 分割任务由数据集、特定轴(针对 3D 模态)和标签的组合来定义。
- 对于具有多个标签的数据集,每个标签都被视为一个单独的二值分割任务。
- 对于 3D 体数据,研究人员提取中间切片和包含最大标签区域的切片。
- 为了防止过拟合,研究人员实施了一种合成标签机制,其中超像素算法将图像划分为多标签掩码,从中随机选择单个标签以特定概率替换 ground truth。
- 训练策略:研究人员在训练期间使用分层采样来平衡不同规模的数据集。这种采样按数据集和模态进行,然后按轴进行,最后按标签进行。在模拟用户交互之前,输入图像和采样的分割结果都会进行数据增强。
- MedScribble 数据集:为了进行人工评估,研究人员策划了 MedScribble 数据集,其中包含三名标注者对 64 对图像分割进行的 manual scribble 标注。这些配对是从 14 个不同数据集的验证集中随机选择的。一个包含来自 7 个未见数据集的 31 对图像分割配对的特定子集被用于报告 manual scribble 评估的结果。
方法
ScribblePrompt 框架被设计为一种可以在多种生物医学成像模态中泛化的交互式分割方法。核心目标是学习一个函数 fθ(xt,ui,y^i−1t),在给定输入图像 xt、一组用户交互 ui 和之前的预测 y^i−1t 的情况下,生成迭代分割 y^i。通过最小化真实分割 yt 与 k 次迭代预测之间的差异,利用监督分割损失来优化模型:
L(θ;T)=Et∈T[E(xt,yt)∈t[∑i=1kLSeg(yt,ftheta(xt,ui,y^i−1t))]]
训练过程涉及模拟一系列交互步骤。如框架图所示:
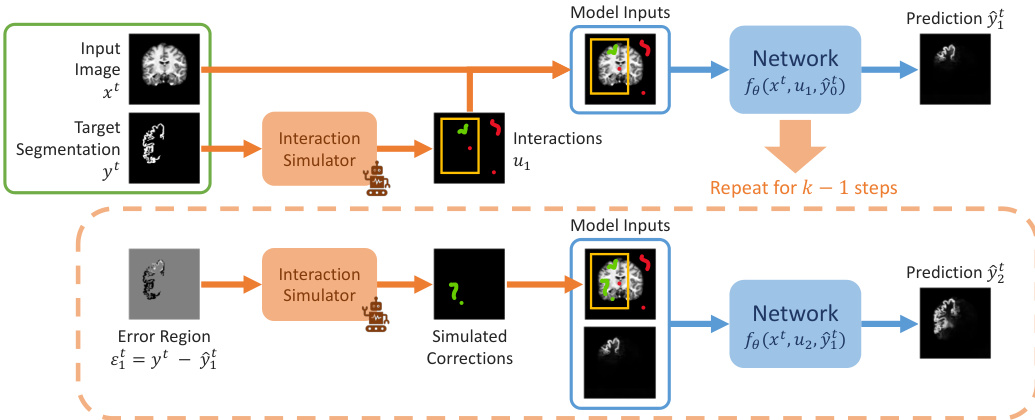
最初,根据 ground truth yt 模拟一组交互 u1(例如 bounding boxes、clicks 或 scribbles),以产生第一次预测 y^1t。在随后的步骤中,框架通过识别错误区域 εit=yt−y^it 并基于此错误生成新的交互 ui+1 来模拟用户修正。这个迭代过程重复 k 步以细化分割。
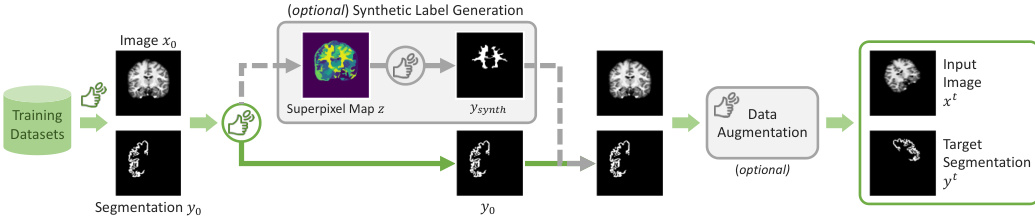
为了增强泛化能力并防止模型过拟合特定任务,研究人员结合了合成标签生成机制。在训练期间,样本 (x0,y0) 可能会以概率 psynth 被合成标签 ysynth 替换。这是通过对图像 x0 应用超像素算法来创建 k 个超像素的映射实现的,从中随机选择一个超像素作为合成目标。包含此可选增强在内的整体训练流程如下图所示:
交互模拟针对不同的 prompt 类型采用了多种策略。对于 scribbles,研究人员实施了线、中心线和轮廓策略,然后通过随机掩码和变形进行破坏,以模拟人类的多样性。对于 clicks,采用了随机、中心或内部边界区域采样。Bounding boxes 通过计算标签的最小包围框并将其稍微扩大来模拟。这些 prompts 被编码到输入通道中,使网络能够高效处理。对于 ScribblePrompt-UNet 架构,输入由五个通道组成:图像、bounding box 编码、正向 click/scribble 编码、负向 click/scribble 编码以及之前的预测 logits。
实验
研究人员通过 manual scribble 测试、模拟迭代交互、针对经验丰富的神经影像研究人员的用户研究以及计算运行时间分析评估了 ScribblePrompt。实验验证了模型使用 bounding boxes、clicks 和 scribbles 等灵活 prompts 泛化到未见过的医学模态和解剖区域的能力。研究结果表明,与现有的通用模型相比,ScribblePrompt 提供了卓越的分割精度和更高的效率,提供了更具响应性且用户友好的体验,并显著减少了标注时间。
研究人员通过涉及经验丰富的标注者的用户研究,将 ScribblePrompt-UNet 与 SAM (ViT-b) 模型进行了对比。结果表明,ScribblePrompt-UNet 实现了更高的分割精度和更低的错误率,同时每个任务所需的时间更少,交互次数更少。与 SAM (ViT-b) 相比,ScribblePrompt-UNet 实现了更高的平均 Dice 分数。与 SAM 基准相比,ScribblePrompt-UNet 模型产生了更低的 HD95 值。用户使用 ScribblePrompt-UNet 完成任务的效率更高,每个任务所需的时间和交互步骤更少。

研究人员在不同数据集上使用 manual scribble 输入,将 ScribblePrompt 模型与几种基准方法进行了评估。结果显示,与现有的交互式分割方法相比,ScribblePrompt-UNet 和 ScribblePrompt-SAM 都实现了更高的 Dice 分数和更低的 Hausdorff Distance。在使用 manual scribble prompts 时,ScribblePrompt 模型优于 SAM 变体和 MedSAM。与 MIDeepSeg 相比,ScribblePrompt 模型展示了卓越的精度和边界贴合度。在 manual scribble 评估中,ScribblePrompt 变体在所有对比方法中实现了最高的 Dice 分数。
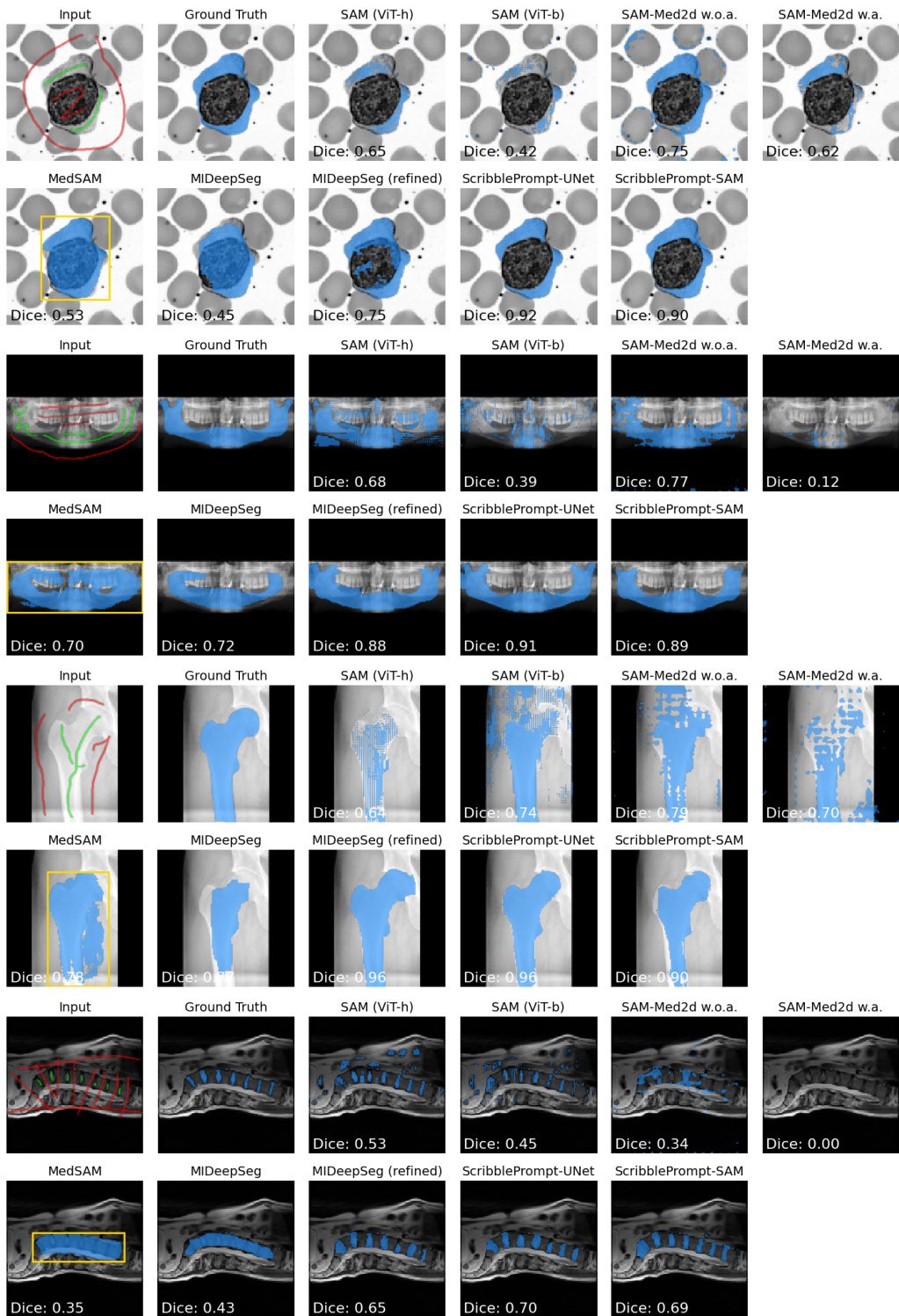
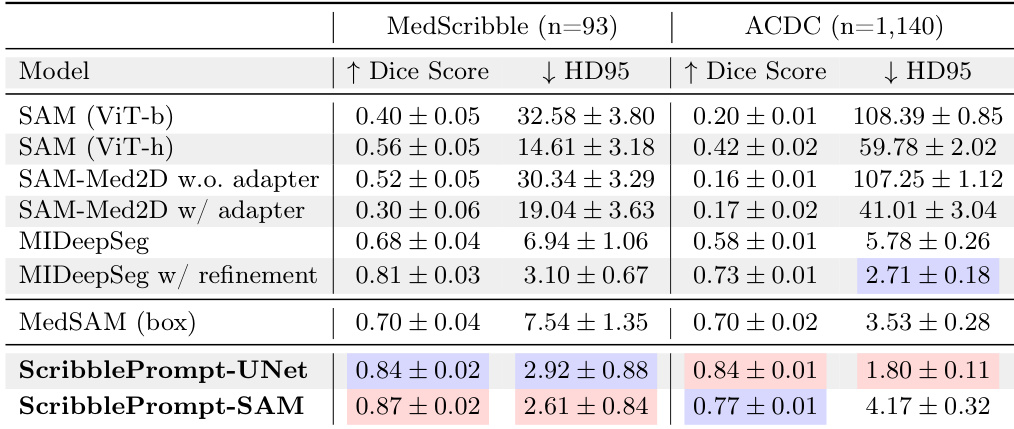
研究人员在 MedScribble 和 ACDC 数据集上使用 manual scribbles 评估了多种交互式分割模型。结果显示,与所有其他测试方法相比,ScribblePrompt 模型实现了最高的 Dice 分数和最低的 Hausdorff Distance。在分割精度方面,ScribblePrompt-SAM 和 ScribblePrompt-UNet 优于 SAM、SAM-Med2D 和 MedSAM 等现有方法。在 ACDC 数据集上,ScribblePrompt-UNet 在 Dice 分数和 Hausdorff Distance 方面均实现了最佳的综合性能。与基于 SAM 的基准模型相比,ScribblePrompt 模型展示了处理 manual scribble 输入的卓越能力。
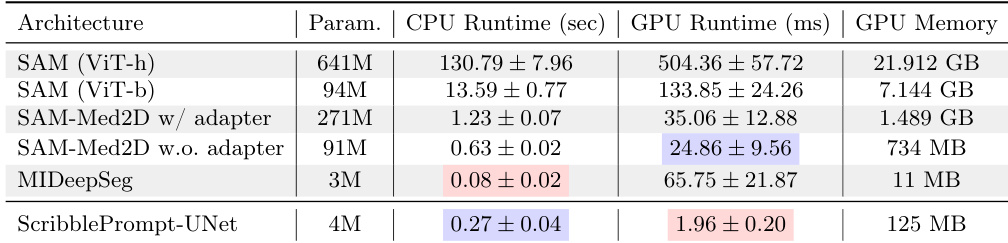
研究人员将 ScribblePrompt-UNet 的计算效率与几种基于 SAM 的模型以及 MIDeepSeg 进行了比较。结果显示,ScribblePrompt-UNet 在 CPU 和 GPU 硬件上均保持低延迟。与所有其他评估模型相比,ScribblePrompt-UNet 实现了显著更快的 GPU 推理时间。在单个 CPU 上,ScribblePrompt-UNet 展示了具有竞争力的低延迟性能,优于较大的 SAM 变体。模型在参数量和推理速度之间表现出明显的权衡,ScribblePrompt-UNet 以较小的参数占用提供了高效率。
研究人员使用 ACDC 数据集将 ScribblePrompt-UNet 与 scribble-supervised 学习方法 ScribFormer 进行了比较。结果显示,ScribblePrompt-UNet 在保持显著较低 HD95 的同时,实现了相当的 Dice 分数。ScribblePrompt-UNet 实现了与 ScribFormer 相似的 Dice 分数。如较低的 HD95 所示,ScribblePrompt-UNet 展示了更好的边界准确性。ScribblePrompt-UNet 的性能与专门的 scribble-supervised 模型具有竞争力。

研究人员通过用户研究、MedScribble 和 ACDC 数据集上的对比分割基准测试以及计算效率测试评估了 ScribblePrompt 模型。结果表明,与现有的 SAM 变体和专门的 scribble-supervised 方法相比,ScribblePrompt 模型提供了卓越的分割精度和更好的边界贴合度。此外,这些模型通过减少交互次数提高了用户生产力,并在不同硬件上提供了具有低延迟的高计算效率。