Command Palette
Search for a command to run...
BioInstruct:面向生物医学自然语言处理的 Large Language Models 指令微调研究
BioInstruct:面向生物医学自然语言处理的 Large Language Models 指令微调研究
Hieu Tran Zhichao Yang Zonghai Yao Hong Yu
摘要
本研究旨在通过引入领域特定的指令数据集,并探讨其与多任务学习(multi-task learning)原则结合后的影响,从而提升大语言模型(LLMs)在生物医学自然语言处理(BioNLP)任务中的表现。我们构建了 BioInstruct 数据集,其中包含 25,005 条指令,用于对 LLMs(包括 LLaMA 1 和 LLaMA 2 的 7B 及 13B 版本)进行指令微调(instruction-tune)。这些指令是通过向 GPT-4 模型提供提示词(prompting)生成的,具体方法是从 80 条人工筛选的指令中随机抽取三个种子样本作为示例。我们采用了低秩自适应(LoRA)技术进行参数高效微调(parameter-efficient fine-tuning)。随后,我们在多个 BioNLP 任务上对这些经过指令微调的 LLMs 进行了评估,这些任务可分为三大类:问答(QA)、信息抽取(IE)和文本生成(SEN)。我们还研究了指令的类别(如 QA、IE 和生成任务)是否会对模型性能产生影响。与未经指令微调的 LLMs 相比,我们经过指令微调的 LLMs 展现出了显著的性能提升:在 QA 任务中,平均准确率(accuracy)提升了 17.3%;在 IE 任务中,平均 F1 值提升了 5.7%;在生成任务中,平均 GPT-4 评分提升了 96%。此外,我们基于 LLaMA 1 构建的 7B 参数指令微调模型,在生物医学领域与其他同样基于 LLaMA 1 并使用海量领域特定数据或多种任务进行微调的 LLMs 相比,表现出了极强的竞争力,甚至在某些指标上实现了超越。
一句话总结
为了增强大型语言模型在生物医学自然语言处理方面的能力,研究人员提出了 BioInstruct,这是一个通过 GPT-4 生成的包含 25,005 条指令的领域特定数据集。通过使用低秩自适应(LoRA)对 LLaMA 1 和 2(7B 和 13B)模型进行指令微调,该数据集显著提升了模型在问答、信息提取和文本生成任务中的表现。
核心贡献
- 本文介绍了 BioInstruct,这是一个领域特定的指令数据集,包含 25,005 条指令,这些指令是通过使用从人工策划的生物医学任务中抽取的样本来提示 GPT-4 生成的。
- 该工作利用低秩自适应(LoRA)在 LLaMA 1 和 LLaMA 2 模型上实现了参数高效微调,以使大型语言模型适应生物医学自然语言处理领域。
- 实验结果表明,经过指令微调的模型在问答、信息提取和文本生成任务中取得了显著的性能提升,其中 7B 参数的 LLaMA 1 模型在与其他领域特定模型的竞争中表现出色。
引言
大型语言模型(LLMs)对于医疗问答和信息提取等生物医学自然语言处理(BioNLP)任务变得日益重要。虽然在特定任务数据集上进行传统的微调可以达到很高的准确度,但这通常需要海量的高质量标注数据,且容易出现过拟合。研究人员通过引入 BioInstruct 来应对这些挑战,这是一个由 GPT-4 生成的包含 25,005 条指令的领域特定指令微调数据集。通过在 LLaMA 模型上应用低秩自适应(LoRA)进行参数高效微调,研究人员展示了在问答、信息提取和文本生成任务中显著的性能增益。
数据集
-
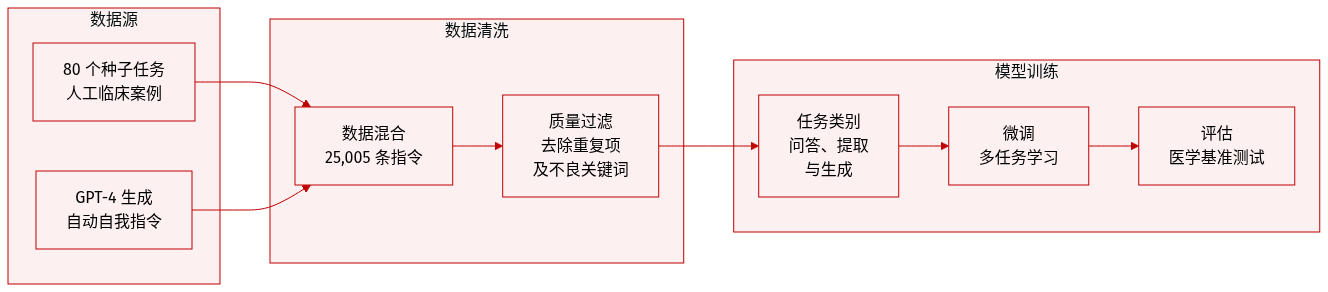
数据集构成与来源:BioInstruct 是一个包含 25,005 条自然语言指令的数据集,专为生物医学和临床 NLP 任务设计。该数据集使用自动化的“Self-Instruct”方法生成,从 80 个手动构建的种子任务开始,涵盖了生物医学问答、摘要生成、临床试验资格评估和鉴别诊断等多个领域。
-
数据结构与元数据:BioInstruct 中的每个条目都遵循结构化格式,包含三个字段:自然语言指令、输入参数和预期的文本输出。为了组织数据,研究人员使用 GPT-4 将指令分为四大类:问答(22.8%)、信息提取(33.8%)、生成(33.5%)和其他任务(10%)。这种分类通过人工评分者间信度分析进行了验证,Krippendorff's alpha 系数为 0.83。
-
处理与过滤规则:为了确保高质量和多样性,在生成过程中应用了若干过滤约束:
- 多样性:只有当新指令与现有指令的 ROUGE-L 相似度低于 0.7 时,才会将其添加到集合中。
- 关键词过滤:删除了包含“image”、“picture”或“graph”等术语的指令,因为这些术语通常不适用于语言模型。
- 启发式过滤:如果指令过长(超过 150 个单词)、过短(少于 3 个单词)或输出是输入的重复,则丢弃无效的生成结果。
-
模型使用与评估:研究人员使用 BioInstruct 微调模型以探索多任务性能。通过在特定任务子集上进行训练开展消融研究,以确定各任务对基准性能的贡献。在评估方面,使用了多个专业的生物医学基准测试,包括用于问答的 MedQA-USMLE、MedMCQA、PubMedQA 和 BioASQ MCQA,以及用于临床生成任务的 Conv2note 和 ICliniq。
方法
所提出的方法围绕两个基本阶段构建:构建名为 BioInstruct 的专门数据集,以及随后对各种大型语言模型(LLMs)进行微调。
首先关注 BioInstruct 数据集的开发,该数据集作为模型的底层知识库。该数据集旨在弥合通用语言能力与专业生物学知识之间的差距。通过策划高质量的领域特定指令,确保随后的训练过程能够针对生物学推理和术语的细微差别进行优化。
数据集准备完成后,进入微调阶段。在此阶段,多种 LLM 架构使用 BioInstruct 语料库进行监督微调。这一过程旨在使预训练模型符合生物医学领域的特定要求,增强其遵循复杂生物学指令并提供准确、具备上下文感知能力响应的能力。
实验
本研究通过在问答、信息提取和文本生成任务上微调 LLaMA 模型,评估了新引入的自动化指令微调数据集 BioInstruct 的有效性。实验验证了指令微调显著增强了模型在生物医学领域的性能,通常优于已有的领域特定基准模型。研究结果表明,虽然增加数据量通常会提高能力,但产生最佳结果的具体任务组合取决于目标应用。
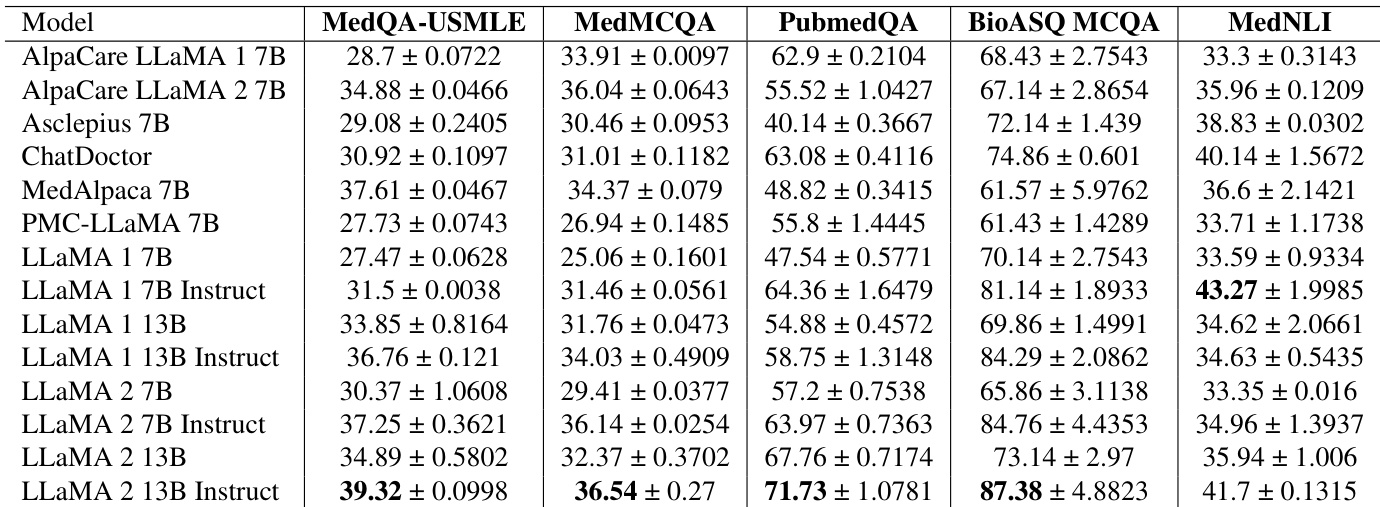
研究人员在生物医学领域的选择题问答和自然语言推理任务上评估了多个大型语言模型。结果显示,与非指令版本及多个专业基准模型相比,经过指令微调的 LLaMA 模型在这些基准测试中通常表现出更高的性能。指令微调的 LLaMA 模型在医疗问答和推理任务中表现出优于基础模型的性能。LLaMA 2 13B Instruct 模型在大多数评估的生物医学问答基准中获得了最高分。ChatDoctor 和 MedAlpaca 等专业基准模型表现出竞争力的结果,但通常会被指令微调的 LLaMA 变体超越。
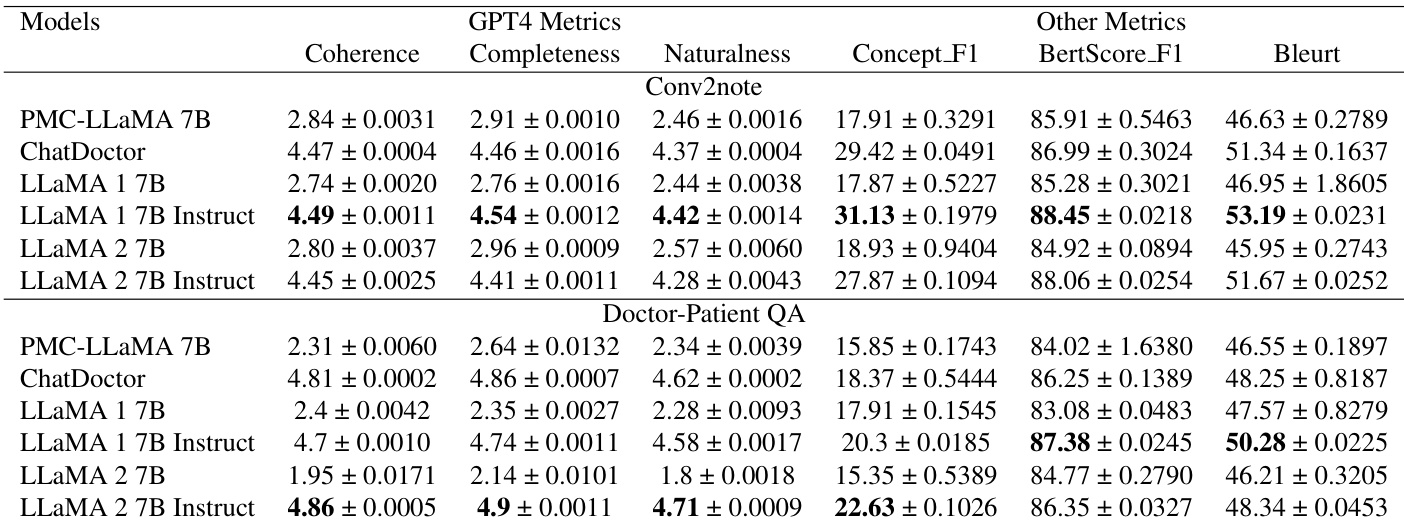
研究人员使用基于 GPT-4 的评分和语义相似度度量等指标,在 Conv2note 和 Doctor-Patient QA 两个文本生成任务上评估了多个模型。结果显示,与非指令版本和多个基准模型相比,指令微调的 LLaMA 模型在连贯性、完整性和自然度方面通常获得更高的分数。在 Conv2note 任务中,指令微调的 LLaMA 1 7B 在连贯性和完整性方面优于其他模型。对于 Doctor-Patient QA,指令微调的 LLaMA 2 7B 模型表现出比基准模型更高的连贯性和自然度分数。在 Conv2note 任务中,指令微调的 LLaMA 1 7B 模型相对于原始 LLaMA 1 7B 显示出改进的语义相似度和概念重叠。
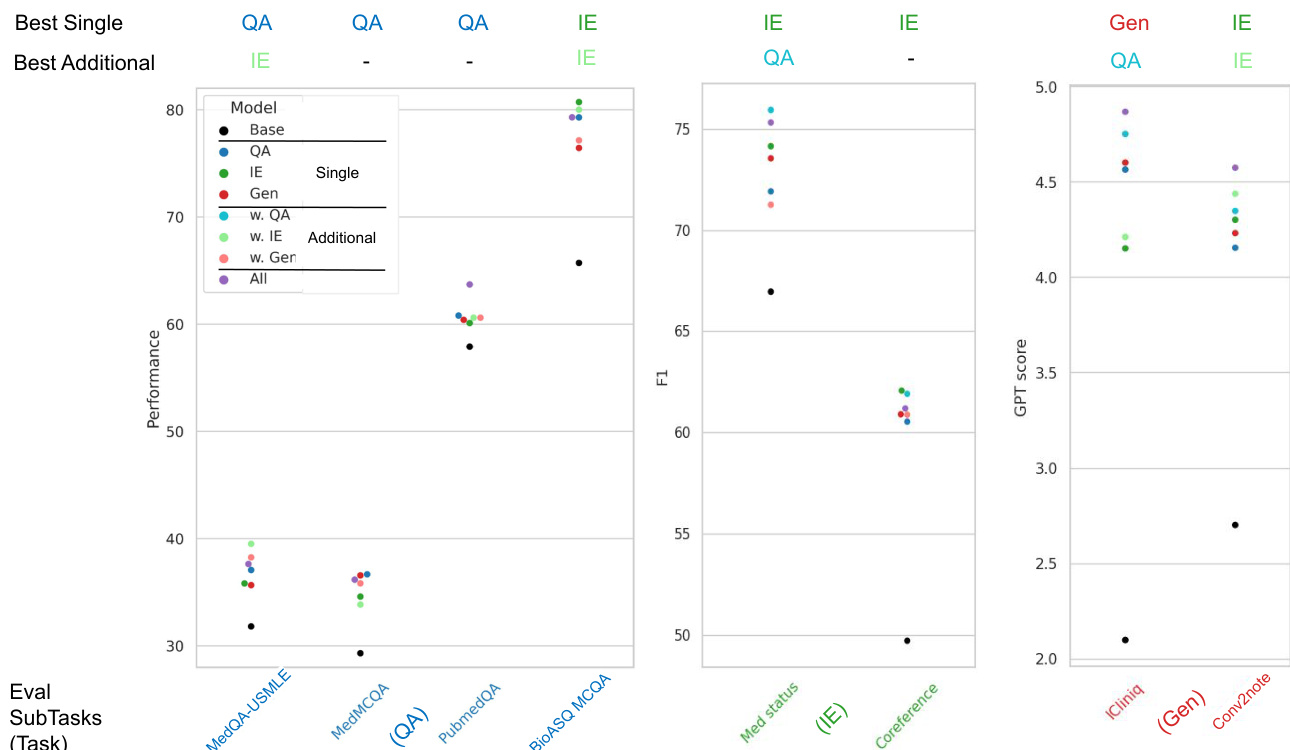
通过检查在特定任务类别上的训练如何影响不同评估任务的性能,研究人员评估了多任务指令微调的影响。结果表明,虽然某些任务组合能提供协同效益,但增加训练任务的有效性取决于具体的评估目标。使用额外的问答任务进行训练可以提升信息提取和生成任务的性能。在补充了问答训练后,信息提取任务显示出轻微的性能提升。多任务微调带来的性能增益具有任务依赖性,因为某些任务组合可能会导致某些评估类别的性能下降。

表格对比了多个生物医学语言模型在药物状态提取和指代消解任务上的表现。结果表明,与非指令版本及多个领域特定基准模型相比,指令微调模型通常达到更高的性能水平。指令微调的 LLaMA 2 7B 模型在药物状态提取方面获得了最高的精确率(precision)和 F1 分数。在指代消解方面,指令微调的 LLaMA 2 7B 模型在精确率、召回率(recall)和 F1 分数上均优于所有列出的其他模型。指令微调在不同版本的模型中都显著提高了药物状态提取的召回率。

研究人员在生物医学选择题、自然语言推理、文本生成和信息提取任务上评估了各种 LLaMA 模型,以衡量指令微调的影响。结果表明,在连贯性、自然度和提取准确度方面,指令微调模型始终优于其基础版本和多个专业基准模型。此外,虽然多任务指令微调可以为信息提取和生成提供协同效益,但添加特定训练任务的有效性仍然高度依赖于目标评估目标。