Command Palette
Search for a command to run...
用于随机梯度下降快速不确定性量化的廉价 Bootstrap 方法
用于随机梯度下降快速不确定性量化的廉价 Bootstrap 方法
Henry Lam Zitong Wang
摘要
随机梯度下降(SGD)或随机逼近法已广泛应用于模型训练与随机优化领域。尽管关于其收敛性的研究文献浩如烟海,但针对 SGD 所得解的统计推断(inference)直至近期才受到关注;鉴于不确定性量化(uncertainty quantification)需求日益增长,此类推断显得尤为重要。本文研究了两种计算成本较低的基于重采样(resampling)的方法,旨在为 SGD 解构建置信区间。其中一种方法通过对数据进行有放回重采样,并行运行少量但多个 SGD 实例;另一种则以在线(online)方式实现该过程。我们的方法可视为对既有自助法(bootstrap)方案的改进,在大幅降低重采样计算开销的同时,规避了现有批处理(batching)方法中复杂的混合条件(mixing conditions)。上述成果得益于近期提出的“廉价自助法”(cheap bootstrap)思想,以及对适用于 SGD 的 Berry-Esseen 型界(bound)的进一步优化。
一句话总结
哥伦比亚大学的 Henry Lam 和 Zitong Wang 提出了两种计算成本低廉的重采样方法,用于构建随机梯度下降(SGD)解的置信区间。通过利用“廉价自举”(cheap bootstrap)思想并改进 Berry-Esseen 界,他们的方法显著降低了重采样需求,同时规避了现有批量技术中用于不确定性量化的复杂混合条件。
主要贡献
- 本文介绍了两种基于重采样的计算高效方法,用于构建随机梯度下降解的置信区间,分别利用少量复现的并行运行或在线操作框架。
- 这些方法通过大幅减少重采样需求并规避现有批量方法中通常所需的复杂混合条件,增强了既有的自举方案。
- 理论有效性通过应用最新的“廉价自举”概念并针对随机梯度下降改进 Berry-Esseen 型界来支持,从而确保准确的不确定性量化。
引言
随机梯度下降(SGD)是现代机器学习和随机优化的基石,然而量化其解的统计不确定性对于需要可靠置信区间的应用而言仍是一个关键挑战。先前的方法存在显著局限性,包括需要不可用的 Hessian 信息、对批量均值方法中的超参数调整敏感、在线自举中维护大型集成带来的高计算开销,或需要从根本上改变 SGD 轨迹。作者利用最新的“廉价自举”概念并改进 Berry-Esseen 型界,提出了两种计算高效的重采样方法,这些方法以最小的重采样需求构建有效的置信区间,同时规避了复杂的混合条件。
方法
作者利用一种自举方法,旨在克服 SGD 推断中的挑战,而无需与混合相关的调整或对原始 SGD 进行实质性修改。该方法论结合了最新的“廉价自举”思想与 SGD 和重采样 SGD 运行之间渐近联合分布的推导。该框架支持离线和在线实现,分别称为廉价离线自举(COfB)和廉价在线自举(CONB)。
对于离线版本,COfB 通过对数据 B 次有放回重采样来重新运行 SGD。它通过类似于标准误差自举的方法,利用这些重采样迭代构建置信区间。关键论点是 B 可以非常小,例如 3,这使得该方法在计算上比 Delta 方法或在线自举要求更低。在线版本 CONB 则在新数据到来时,并行运行多个(即 B+1 个)SGD。它借用了在 SGD 迭代中扰动梯度估计的思想,但保持了极少量的 SGD 运行。
不同方法之间的比较突显了所提方法在计算和内存方面的优势。有关这些区别的总结,请参阅下方的比较表。
Delta 方法、随机缩放和在线自举需要相对较重的计算或内存负载。相比之下,所提方法引入了 B 但将其保持得非常小,从而实现了轻量的计算和内存负载。此外,二阶导数仅由 Delta 方法需要,这在某些应用场景中可能是一个挑战。
理论保证依赖于建立 SGD 与重采样 SGD 运行之间的渐近联合分布,特别是独立性。作者证明了在有放回重采样情况下,原始 SGD 运行和重采样 SGD 运行的联合中心极限定理。这指导了输出的聚合以构建渐近精确覆盖的区间。置信区间基于 t 统计量构建,并遵循 t 区间的行为。虽然其宽度大于正态区间,但随着 B 的增加,宽度会迅速收缩。
在高维稀疏设置中,作者通过两阶段方法扩展了这些方法。第一阶段通过 Lasso 模型选择将问题降低到低维子空间。第二阶段将 COfB 或 CONB 应用于限制在估计参数支撑集上的问题。该过程正确识别了真实模型参数的支撑集,并为非零条目提供了具有精确覆盖的置信区间。
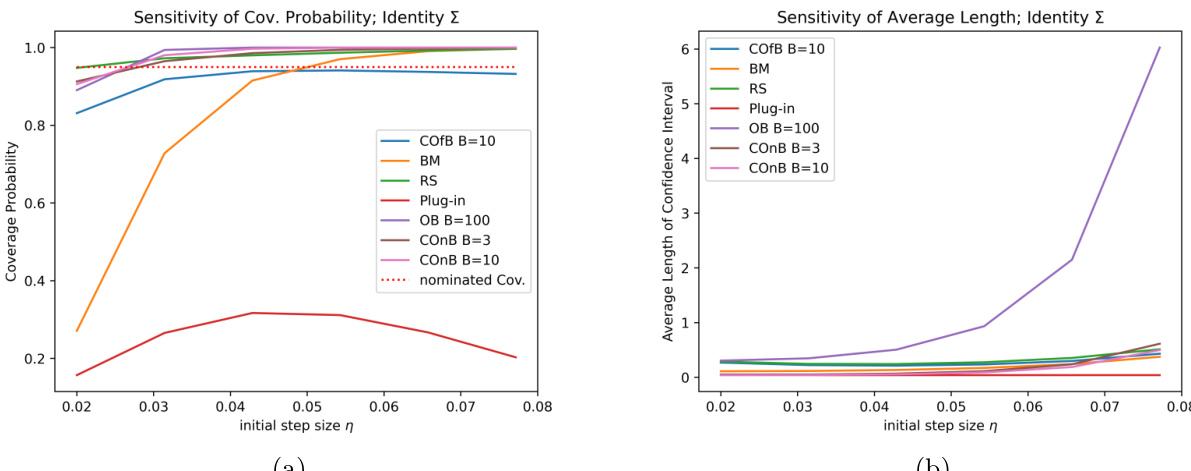
实验结果支持了关于置信区间覆盖概率和宽度的陈述。结果表明,这些方法通常能提供最准确的覆盖概率。请参阅下方的线性和逻辑回归结果。
尽管这些方法产生的置信区间较宽,但当 B 即使略有增加时,区间宽度也会急剧减小。此外,实验表明该方法在鲁棒性方面优于其他方法。该分析也适用于高维稀疏线性回归,以扩大其适用范围。请参阅下方的稀疏线性回归结果。
实验
- 在固定维度的线性和逻辑回归上的实验验证,所提出的 COfB 和 CONB 方法在各种维度和协方差结构下均实现了准确的 95% 覆盖概率,而 Delta 方法和 HiGrad 等基线方法随着维度增加会出现显著的覆盖不足。
- 对比分析表明,虽然所提方法产生的置信区间略宽于某些基线,但相比在线自举,它们提供了更优越的计算效率,并避免了 Delta 方法和随机缩放方法所需的矩阵运算的高计算成本。
- 敏感性分析证实,所提方法无论初始步长如何都能保持稳定的覆盖概率,而批量均值方法需要仔细调整,Delta 方法在步长变化时无法提供有效区间。
- 稀疏线性回归设置下的实验验证,该方法能正确识别非零系数并达到接近标称的覆盖,同时为零系数生成单点区间,有效处理了模型选择的不确定性。
- 鲁棒性测试显示,虽然这些方法在条件良好的曲率和各种学习率调度下表现良好,但在极端病态场景下性能会下降,导致区间变宽且覆盖精度降低。