Command Palette
Search for a command to run...
基于分页注意力的大型语言模型服务中的高效内存管理
基于分页注意力的大型语言模型服务中的高效内存管理
Woosuk Kwon Zhuohan Li Siyuan Zhuang Ying Sheng Lianmin Zheng Cody Hao Yu Joseph E. Gonzalez Hao Zhang Ion Stoica
摘要
大规模语言模型(LLM)的高吞吐量服务需要同时处理大量请求,通过批量处理来提升效率。然而,现有系统面临严峻挑战:每个请求的键值缓存(KV cache)内存占用巨大,且其大小会动态变化。当内存管理效率低下时,内存碎片化和冗余复制会导致大量内存浪费,从而限制了可批量处理的请求数量。为解决这一问题,我们提出 PagedAttention,一种受操作系统中经典虚拟内存与分页技术启发的注意力机制算法。在此基础上,我们构建了 vLLM——一个高效的 LLM 服务系统,具备以下优势:(1)实现 KV 缓存内存的近乎零浪费;(2)支持请求内部及跨请求之间的 KV 缓存灵活共享,进一步降低内存使用量。实验结果表明,在保持与当前最先进系统(如 FasterTransformer 和 Orca)相当延迟水平的前提下,vLLM 将主流 LLM 的吞吐量提升了 2 至 4 倍。该性能提升在处理长序列、大模型以及复杂解码算法时尤为显著。vLLM 的源代码已公开,可在 https://github.com/vllm-project/vllm 获取。
一句话总结
加州大学伯克利分校、斯坦福大学、加州大学圣地亚哥分校以及一位独立研究者提出了 vLLM,这是一个高吞吐量的大语言模型(LLM)服务系统,利用受虚拟内存启发的 PagedAttention 技术,消除了 KV 缓存碎片化问题,并实现了灵活的缓存共享,相比当前最先进的系统,吞吐量提升 2–4 倍,且延迟开销极小,尤其在长序列和复杂解码场景下表现突出。
主要贡献
- 现有 LLM 服务系统由于采用连续内存分配,导致 KV 缓存内存严重浪费,产生内部和外部碎片,限制了批处理大小和吞吐量——尤其在动态、变长序列和复杂解码策略(如束搜索或并行采样)下更为明显。
- PagedAttention 引入了一种受操作系统虚拟内存启发的新型注意力机制,将 KV 缓存划分为固定大小的块,可非连续分配,从而实现近乎零的内存浪费,并支持请求内和请求间序列的高效缓存共享。
- 基于 PagedAttention 构建的 vLLM,在多种模型和工作负载下,相比 FasterTransformer 和 Orca 等先进系统,吞吐量提升 2–4 倍,且在长序列、大模型和高级解码算法场景下优势进一步放大。
引言
作者针对大语言模型(LLM)服务中的内存效率这一关键挑战展开研究,指出高昂的成本和有限的 GPU 内存严重制约了吞吐量。现有系统将自回归生成所必需的 KV 缓存存储在预分配至最大序列长度的连续内存块中,导致严重的内部和外部碎片,内存利用率低下,且无法在多个序列或请求间共享缓存。这限制了批处理规模,导致 GPU 资源利用率不足,尤其在变长输入和复杂解码策略(如束搜索或并行采样)下问题更加突出。为克服这些限制,作者提出 PagedAttention,一种受操作系统虚拟内存启发的注意力机制,将 KV 缓存划分为固定大小的块,支持非连续分配。该机制实现了动态按需分配,消除了碎片化,并支持细粒度的跨序列和请求内存共享。在此基础上,作者开发了 vLLM,一个分布式服务引擎,结合块级内存管理与抢占式调度,实现了近乎零的 KV 缓存浪费,相比 FasterTransformer 和 Orca 等先前系统,吞吐量提升 2–4 倍,且不牺牲准确性。
方法
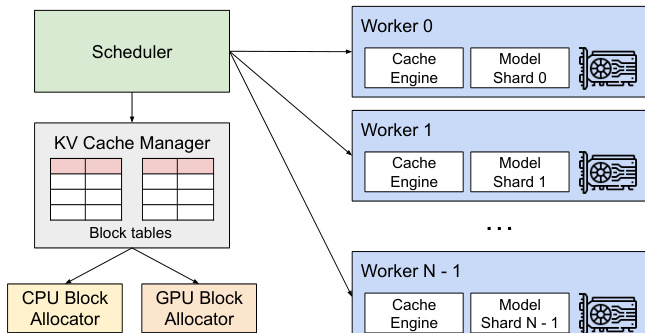
作者采用一种新颖的注意力算法 PagedAttention 及其对应的系统架构 vLLM,以解决大语言模型(LLM)服务中内存碎片化和 KV 缓存利用效率低下的问题。系统核心是一个集中式调度器,负责协调多个 GPU 工作节点的执行,每个工作节点托管模型的一个分片。该调度器管理一个共享的 KV 缓存管理器,负责在分布式系统中动态分配和管理 KV 缓存内存。KV 缓存管理器通过将 KV 缓存组织为固定大小的块(类似于虚拟内存中的页),并维护块表,将每个请求的逻辑 KV 块映射到 GPU DRAM 中对应的物理块。这种逻辑与物理内存的分离,实现了动态内存分配,无需为最大可能序列长度预先预留内存,显著减少了内部碎片。

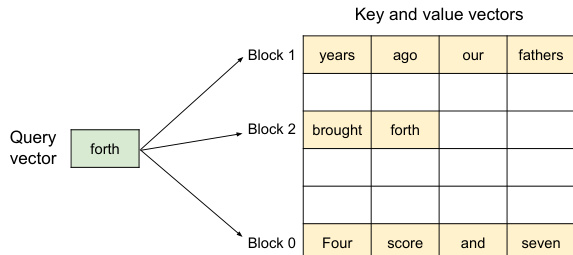
如图所示,PagedAttention 算法能够在键值向量存储于非连续物理内存块时,高效计算注意力分数。与要求序列的 KV 缓存必须存储在单一连续块不同,PagedAttention 将缓存划分为固定大小的 KV 块。在注意力计算过程中,算法识别出与特定查询 token 相关的块,并分别获取。查询 token qi 的注意力分数通过将 qi 与每个块 Kj 中的键向量相乘,得到注意力分数行向量 Aij,再将该向量与对应值向量 Vj 相乘,生成最终输出 oi。这种分块计算方式使注意力核函数能够并行处理多个位置,提升硬件利用率并降低延迟,同时支持灵活的内存管理。
内存管理过程如下例所示。在提示阶段,提示 token 的 KV 缓存被生成并存储在逻辑块中。例如,提示的前四个 token 存储在逻辑块 0,接下来的三个 token 存储在逻辑块 1。块表记录了这些逻辑块到 GPU DRAM 中物理块的映射。随着自回归生成阶段的推进,新 token 被生成,其 KV 缓存被存储在最后一个逻辑块的下一个可用槽位中。当一个逻辑块填满时,系统会分配一个新的物理块,并在块表中将其映射到一个新的逻辑块。该过程确保内存仅在需要时分配,且任何块内未使用的空间是唯一的内存浪费来源,其大小受块大小限制。系统还可同时处理多个请求,如图所示,不同请求的逻辑块可映射到非连续的物理块,从而高效利用可用 GPU 内存。
在分布式环境中,vLLM 支持模型并行,即模型被分割到多个 GPU 上。KV 缓存管理器保持集中式,为所有 GPU 工作节点提供统一的逻辑块到物理块的映射。每个工作节点仅存储其对应注意力头的部分 KV 缓存。调度器通过广播每个请求的输入 token 和块表来协调执行。工作节点随后执行模型,在注意力操作中根据提供的块表读取 KV 缓存。该设计使系统能够扩展至超出单个 GPU 内存容量的大模型,同时保持高效的内存管理。
实验
- 并行采样:vLLM 通过分页内存管理和写时复制(copy-on-write)机制,实现了提示 KV 缓存在多个输出序列间的高效共享,降低内存占用;在 OPT-13B 模型与 Alpaca 数据集上,共享前缀场景下吞吐量比 Orca(Oracle)提升 1.67×–3.58×,束搜索场景下提升高达 2.3×。
- 束搜索:vLLM 在束搜索候选间动态共享 KV 缓存块,减少频繁的内存复制;在 OPT-13B 与 Alpaca 数据集上,束宽为 6 时,内存节省 37.6%–55.2%,吞吐量比 Orca(Oracle)提升 2.3×。
- 共享前缀:vLLM 缓存公共前缀的 KV 块,支持跨请求复用;在 LLaMA-13B 与 WMT16 翻译工作负载下,单次前缀场景下吞吐量提升 1.67×,五次前缀场景下提升 3.58×,均优于 Orca(Oracle)。
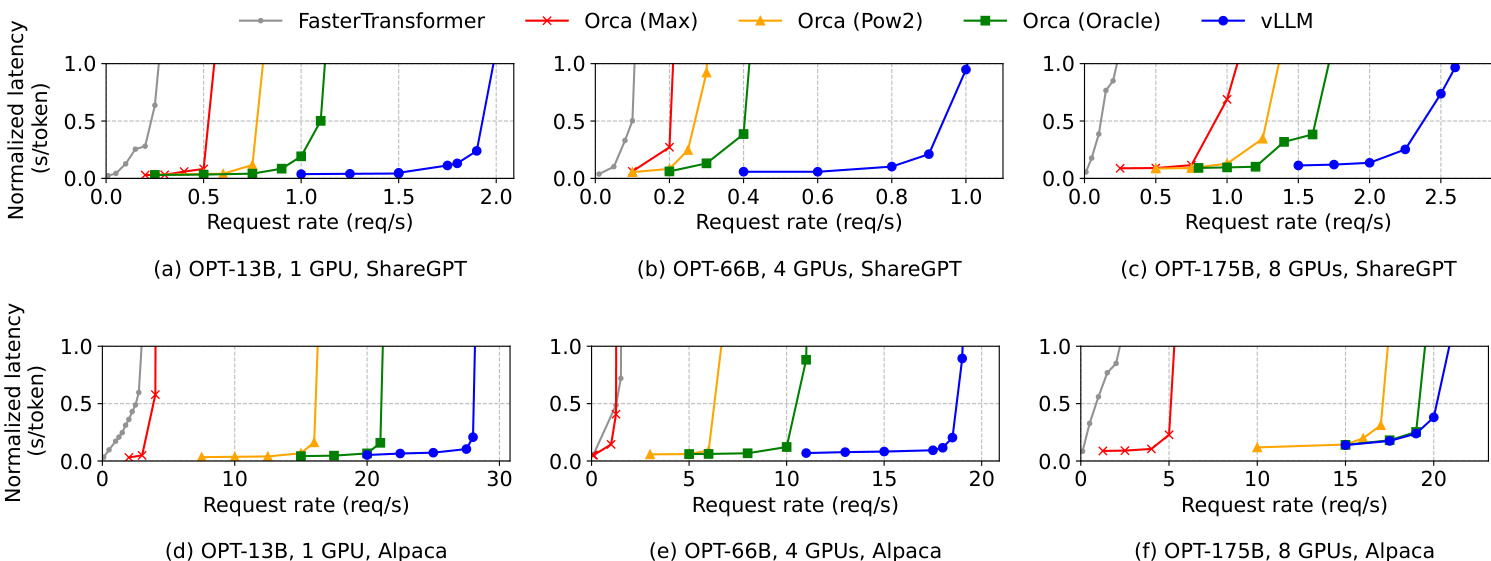
- 基础采样:在 OPT-13B 和 OPT-175B 模型上,vLLM 的请求速率比 Orca(Oracle)高 1.7×–2.7×,在 ShareGPT 数据集上比 Orca(Max)高 2.7×–8×,同时保持低归一化延迟;在 Alpaca 数据集上,请求速率最高可达 FasterTransformer 的 22 倍。
- 内存效率:通过块共享,vLLM 在并行采样中内存使用减少 6.1%–9.8%,在束搜索中(ShareGPT)减少 37.6%–66.3%;默认块大小为 16 时,可在 GPU 利用率与碎片化之间取得良好平衡。
实验结果表明,vLLM 在所有模型和数据集上均显著高于 Orca 和 FasterTransformer 的请求速率,尤其在 ShareGPT 数据集上提升最大,原因在于其提示更长、内存压力更高。vLLM 的性能优势在高请求负载下尤为明显,其在保持低归一化延迟的同时,超越了因内存管理效率低下而受限的基线系统。
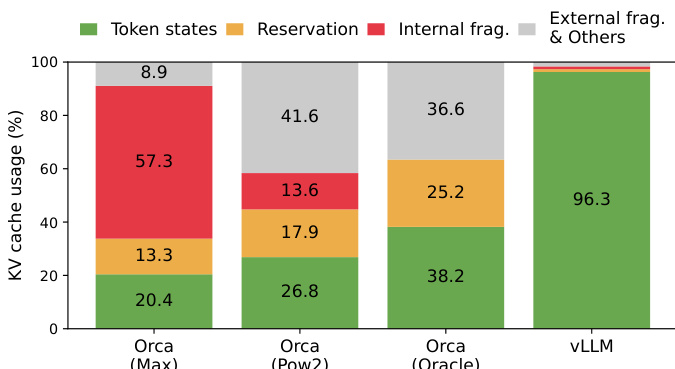
作者使用柱状图比较了不同系统间的 KV 缓存使用情况,结果显示 vLLM 在内部碎片和预留开销方面显著优于 Orca 变体。结果表明,vLLM 将内部碎片降至 3.7%,预留开销降至 0.4%,而 Orca(Max)的内部碎片高达 57.3%,预留开销为 13.3%,充分体现了 vLLM 在内存管理效率上的卓越表现。
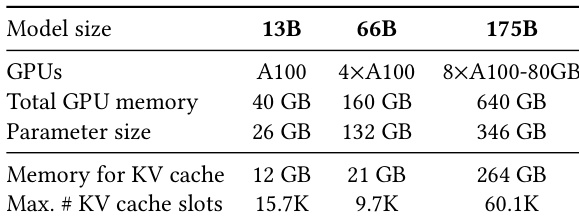
作者使用表格展示了其评估中不同模型规模下的 GPU 和内存配置。对于每种模型规模,表格列出了 GPU 数量、总 GPU 内存、参数量、KV 缓存所需内存以及最大 KV 缓存槽位数。结果显示,KV 缓存所需内存随模型规模增大而增加,最大 KV 缓存槽位数在不同模型间差异显著,其中 175B 模型支持的槽位数最多。