Command Palette
Search for a command to run...
溶血性预测准确率提升 350%,港中文/浙大/澳门理工等团队提出通用框架 Bi-TEAM,融合生物学语义与化学精度

在生物化学与分子工程领域,表征学习正逐渐成为解析分子功能、推动治疗性分子发现的关键技术。嵌入特征的质量,往往决定了肽性质预测与从头设计等下游任务的性能上限。作为连接生物功能与化学特性的核心分子,肽的结构与功能建模在药物研发中具有重要价值。近年来,非经典氨基酸的引入显著拓展了肽的功能空间,并提升了其稳定性与生物利用度,但复杂的化学修饰也给传统建模方法带来了新的挑战。如何在模型中同时整合生物进化信息与化学合理性,正成为该领域亟待突破的关键问题。
目前,肽建模主要沿两条技术路径展开。一方面,以 ESM 、 ProtT5 为代表的蛋白质语言模型通过大规模序列预训练捕捉生物上下文与进化信息,为下游任务提供可迁移的生物表征。另一方面,为应对非经典氨基酸的修饰问题,研究人员基于化学语言模型,通过原子级分词捕捉化学细节,弥补了蛋白质模型在化学层面的不足。
然而,两类模型均存在固有局限。蛋白质语言模型受限于天然氨基酸字符表,难以处理非经典残基,现有近似或扩展词汇的方法常引入偏差或导致语义稀疏。化学语言模型则忽略全局生物上下文,且密集分词易超出上下文窗口,难以适配长序列建模,通用模型还存在领域偏差。
针对上述问题,香港中文大学联合澳门理工大学、浙江大学、中南大学湘雅第二医院、中国电子科技大学等提出了一种选择性融合建模范式,基于「化学变异是对生物语义空间的局部扰动」这一认知,设计了将局部化学变异注入全局蛋白质背景的通用框架 Bi-TEAM 。
该框架以生物表征为语义主干,通过自适应注入化学信号,实现生物进化信息与化学合理性的有效融合。在多项任务上,Bi-TEAM 持续超越最先进的基线模型:在基于骨架相似性的严格数据划分下,马修斯相关系数提升高达 66%;在溶血预测任务中,准确性提升 350% 。
相关研究成果以「Bi-TEAM: A Unified Cross-Scale Representation Learning Framework for Chemically Modified Biomolecules」为题,已发表预印本于 arXiv 。
研究亮点:
* Bi-TEAM 框架既能自适应整合多尺度生化性质,也能作为高保真的先验模型,实现高效的肽设计
* 研究人员将 Bi-TEAM 在 3 个生化领域的 10 个多样化数据集上进行了全面评估,在 7 个关键预测任务中达到了 SOTA 级别
* 该模型在预测与生成任务中实现双重突破,严格的骨架相似性划分下 MCC 提升 66%,同时将细胞穿透环肽的设计成功率提升至近 4 倍

论文地址:
https://arxiv.org/abs/2603.01873
关注公众号,后台回复「Bi-TEAM」获取完整 PDF
覆盖三大生化领域,10 个多样化数据集进行全面评估
该研究从性质预测与引导生成两个维度展开评估,覆盖修饰肽、翻译后修饰(PTMs)以及天然蛋白三大研究领域,共涉及 10 个数据集。
在修饰肽领域,研究重点评估模型的膜通透性预测能力。核心训练数据来自 ProPAMPA 数据库,该数据集中环原子数范围为 12–46,序列长度分布近似正态,但在两端存在明显长尾;同时包含大量天然与非经典氨基酸残基,体现出较高的化学多样性,经 RDKit 去重后,共包含 6,876 条非共轭环肽序列。
为评估模型的泛化能力,研究进一步引入 3 个外部湿实验数据集:ProCacoPAMPA 、 CycPeptMPDB v1.2 以及 Rezai 数据集。这些数据集覆盖不同长度与结构类型的环肽样本。其中:
ProCacoPAMPA:从既有研究中整理得到所有长度为 6 和 10 的跨膜环肽序列,并统一构建为标准化数据集合。
CycPeptMPDB v1.2:目前公开规模最大的非经典环肽膜通透性数据库的最新版本,整合自 56 篇文献,共包含 8,466 条记录。在本研究中,研究人员去除了与 ProPAMPA 数据集重复的样本,最终获得包含 1,230 个数据点的精炼子集。
Rezai:则包含 11 条环肽的被动膜通透性数据,这些数据通过 PAMPA 实验测得,常被用于小样本条件下的模型外部验证。
为进一步验证模型的成药性和疾病关联性,研究人员在 PTM 数据集上开展了成药性预测任务。所使用的数据包括成药性数据集和疾病关联数据集两类。前者以较长蛋白序列为主,修饰位点呈现明显的长尾分布特征;后者主要来源于 dbPTM 、全基因组关联研究(GWAS)等数据库,其修饰位点分布与前者相似,但序列长度范围更广,从而提供了更加多样化的结构背景。
在天然蛋白领域,研究人员重点评估模型在溶解度预测与溶血性预测任务中的表现,以探究肽类溶血过程及蛋白溶解度变化的关键机制。所采用的数据集主要包括溶血、抗污染以及溶解度三类。其中:
溶血数据来源于 DBAASP v3 数据库,共包含 9,316 条由 L 型经典氨基酸组成的序列。
抗污染数据集则主要由短肽序列构成,长度集中在 5–10 个氨基酸残基之间,其 LogP 分布近似正态,样本在特征空间中表现出较好的聚类结构。
溶解度数据集来源于 PROSO II 注释的蛋白序列,其标签基于蛋白质结构计划(Protein Structure Initiative)的回顾性分析所得。
Bi-TEAM:用于化学修饰生物分子的统一跨尺度表征学习框架
Bi-TEAM 旨在解决现有单模态模型难以同时捕捉全局生物进化信息(evolutionary biological space)与局部化学结构细节(fine-grained chemical space)的问题。如下图所示,其核心思路是构建一种双视角表征体系,将进化生物空间与化学结构空间进行深度融合,从而为包含非经典氨基酸的肽序列提供更精准的建模能力。
在整体架构上,模型以蛋白质语言模型构建的生物空间作为语义主干,充分利用其在大规模天然序列中学习到的进化规律与上下文关联。同时,引入化学语言模型(CLM)以捕捉原子层面的结构信息,弥补蛋白质语言模型(PLM)在处理化学修饰时的天然局限。两类模型在表征层面形成互补,共同拓展输入序列的表达能力。

在处理含修饰的肽序列时,Bi-TEAM 通过两条互补的信息流进行编码:一条为生物序列流(biological sequence),将修饰氨基酸映射为结构最接近的天然氨基酸,从而避免分词表膨胀,并保留可用于建模的进化语义;另一条为类 SELFIES 表征流(SELFIES-like representation),用于在原子层面精确描述修饰残基的官能团变化与化学键结构,为化学语言模型提供稳定的结构信息。
完成双流编码后,模型通过由位置感知修饰提示引导的双门控残差机制进行融合:以生物表征为语义主干,利用门控单元筛选并注入关键化学信号,同时保留生物特征的残差连接,从而在保持训练稳定性的同时,使模型能够在全局序列约束与局部化学变化之间建立有效关联。
在应用层面,Bi-TEAM 具有良好的通用性。当处理不含修饰的天然蛋白序列时,模型可以直接省略映射与定位步骤,无需调整整体架构即可适配常规蛋白任务。
训练策略上,研究采用「预训练-微调」的两阶段框架:首先分别在天然蛋白序列和小分子化学语料上对两类基础编码器进行领域适配预训练;随后通过多任务联合微调,使模型学习不同任务场景下生物特征与化学特征的融合规律,从而进一步提升整体泛化能力。
Bi-TEAM 在穿透性环肽设计取得突破,成功率提升 4.6 倍
为验证 Bi-TEAM 在未知化学空间中的应用能力,该研究以无创药物递送为场景,聚焦靶向新生血管性年龄相关性黄斑变性(nAMD)治疗的细胞穿透性非经典环肽设计,系统开展「预测-引导-分析」的全流程实验,评估模型在属性引导型分子设计中的表现。
nAMD 是老年人不可逆失明的重要原因,其核心病理为 VEGF 驱动的脉络膜新生血管与渗漏。目前临床主要依赖玻璃体内注射大分子抗 VEGF 药物(如 Aflibercept,115 kD),但该类药物难以穿透眼部生理屏障,长期注射也存在并发症与依从性问题。如果能够设计既能特异性结合 Aflibercept 、又能促进其跨屏障转运的肽结合剂,将为无创滴眼液疗法提供新的可能。相比易降解、半衰期短的线性肽,结构更稳定、通透性更强的环肽被认为是更理想的递送载体,这也是研究人员聚焦环肽设计的主要动机。
该研究首先开展细胞穿透肽(CPPs)预测评估,为后续生成任务提供基础。数据集按照 pLM4CPP 标准方案构建,整合 CPPsite2.0 、 C2Pred 、 CellPPD 等数据库,经筛选去重后得到 1,399 个阳性样本(实验验证的穿透肽)和 4,080 个阴性样本。对比模型包括 SeqVec 、 ESM2 、 ProtT5 等主流蛋白嵌入模型,评估指标涵盖 ACC 、 BACC 、 Sn 、 Sp 、 MCC 和 AUC 。
结果表明,Bi-TEAM 在所有指标上均取得最佳表现:ACC 较 SeqVec 提升 5.52%,BACC 较 ESM2-480 提升 5.88%,Sn 提升 12.58%,Sp 较 ProtT5-XL BFD 提升 1.45%,MCC 较 SeqVec 提升 14.68%,AUC 较 ESM2-480 提升 8.45% 。其中灵敏度与 MCC 的显著提升,表明模型在识别真实穿透肽方面具有明显优势。
在此基础上,研究进一步开展属性引导的环肽生成实验。以 BoltzDesign1 为基线框架,在两种条件下分别生成 1,000 条长度为 10-20 的环肽:一类仅采用默认结构约束,另一类在生成过程中引入 Bi-TEAM 作为额外梯度引导。
以 Bi-TEAM 预测对数几率大于 0.5 为成功标准。结果显示,传统方法生成具有细胞穿透性的环肽成功率仅为 6.7%,而在 Bi-TEAM 引导下提升至 30.7% 。同时结构质量并未下降:生成的肽-Aflibercept 复合物平均 pLDDT 超过 0.82,说明模型在提升穿透性的同时仍保持了良好的结构置信度和结合界面稳定性。

为理解引导机制,研究人员进一步分析生成序列的残基模式。已有研究表明,由色氨酸(W)、苯丙氨酸(F)和酪氨酸(Y)构成的疏水三联体,以及精氨酸(R)、赖氨酸(K)等正电荷残基,是细胞穿透肽实现膜转运的关键特征。
分析发现,在 Bi-TEAM 引导下,生成序列中疏水三联体与两个正电荷残基的共现频率显著提高,残基数量分布也呈现一致趋势。这一富集模式与已知的穿透肽结构—功能规律高度一致,说明 Bi-TEAM 不仅能够捕捉相关生物机制,还能在生成过程中显著提高具有膜穿透特性的序列出现概率。控制变量分析进一步排除了肽长度(10–20 残基)的影响,表明模型确实将采样分布引导至更有利于膜转运的化学—生物联合空间。
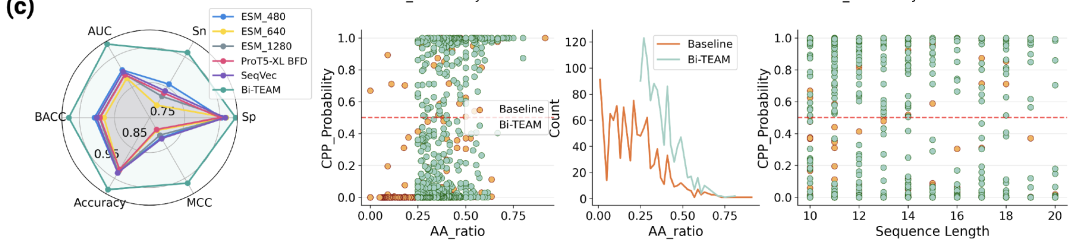
中:关键疏水残基丰度与穿透概率关系;
右:环肽长度与穿透概率关系
最后,该研究通过案例研究对结果进行了结构层面的验证。研究人员首先展示了 Aflibercept 二聚体的三维结构,并根据静电势对其分子表面进行着色;随后利用 AlphaFold3 预测设计环肽与 Aflibercept 的复合物结构。分析识别出两个潜在的环肽结合口袋:一个为由三个环构成的疏水腔体,另一个由环结构与 β 折叠片段共同形成。这些结构信息为后续环肽优化及潜在临床应用提供了重要依据。

聚焦多肽药物研发领域的技术创新
在肽科学领域,从基础研究到临床转化,全球范围内的一众科研机构均在为攻克重大疾病而积极探索新的技术路径与治疗方案。
例如,英国布里斯托大学生物化学学院的结构生物学团队,利用冷冻电镜和 X 射线晶体学等先进技术解析免疫系统的精细结构,并在此基础上开展结构引导的肽类药物设计。他们尝试通过设计能够精准激活人体补体系统的环肽分子,开发用于自身免疫疾病治疗的下一代候选药物。
与此同时,伦敦国王学院与萨格勒布大学合作开展的 ToxiCode 项目,则探索从动物毒液中发现新药的独特路径。项目结合人工智能与合成生物学,通过构建混合 AI 系统学习肽序列模式及其结构—活性关系,快速设计针对癌症、神经系统疾病和感染性疾病的新型生物活性肽,为可持续且符合伦理的药物发现提供了新的方法框架。
由此可见,多肽药物研发正逐渐形成一种新的研究范式:结构生物学、人工智能与化学生物学不断交汇,基础研究与产业开发之间的边界也愈发模糊。新的分子往往诞生于跨学科的技术组合之中,而真正决定其能否走向临床的,则是从实验室发现到产业化体系之间那条逐步被打通的转化路径。在这一过程中,多肽分子因其介于小分子与大分子之间的独特属性,正被重新认识,并在越来越多的疾病领域中展现出新的应用空间。
参考链接:
1.https://www.bristol.ac.uk/news/2025/november/bristol-researcher-awarded-over-850000-to-develop-new-treatments.html
2.https://www.kcl.ac.uk/news/kings-to-collaborate-in-venom-based-drug-discovery-project
3.https://mp.weixin.qq.com/s/X67D1qrUzclwOsJ9cKUtZg








