Command Palette
Search for a command to run...
从「助手」到「用户」,微软 UserLM-8B 模拟真实人类对话,驱动 LLM 优化新浪潮;专为轻量化设计!Extract-0 助力小参数模型实现精准信息抽取

在大语言模型(LLM)飞速发展的今天,我们见证了一个又一个以「助手」角色出现的强大模型,它们致力于提供详尽、结构化的响应,以满足用户的明确需求。然而,在真实对话场景中,用户往往不会一次性完整表达意图,而是在多轮对话中逐渐透露信息,语言风格也普遍呈现出零散化、个性化与即时调整的特点。相比之下传统的「助手型」模型则并不擅长模拟用户,并且越是优秀的 LLM 助手,在「扮演」用户时反而越是失真。这一局限也暴露了当前 LLM 评估体系的关键痛点:由于缺乏能够精准模拟人类对话的高质量「用户」角色,现有评估环境往往过度理想化,与真实应用的复杂语境存在显著差距。
正是在这一背景下,微软推出了最新用户语言模型 UserLM-8B,与通常承担「助手」角色的典型 LLM 不同,该模型基于 WildChat 对话语料库训练,可以用来模拟对话中的「用户」角色进行多轮对话,并以此沿用于大模型能力评估。在实际利用 UserLM 模拟编程和数学对话时,GPT-4o 评分从 74.6% 下降到 57.4%,证实了更拟真的模拟环境会导致「助手」因难以应对用户表达的细微差别而表现下滑。
UserLM-8B 的推出,为大模型评估提供了一个更真实、更具鲁棒性的测试环境。借助其模拟的用户对话,即便是顶尖的助手模型的性能也会显著下降,使得研究者和开发者能够更准确地识别模型在实际交互中的薄弱环节。这进一步推动着 LLM 能力评估不再是单一、静态的基准测试与得分比较,逐渐重视着更接近现实的「实战演习」,让 LLM 更好理解用户真实意图,从而不断优化人类的用户体验。
目前,HyperAI 超神经官网已上线了「UserLM-8b:用户对话模拟模型」,快来试试吧~
在线使用:https://go.hyper.ai/EHcdQ
10 月 20 日-10 月 24 日,hyper.ai 官网更新速览:
* 优质公共数据集:8 个
* 优质教程精选:7 个
* 本周论文推荐: 5 篇
* 社区文章解读:5 篇
* 热门百科词条:5 条
* 10 月截稿顶会:1 个
访问官网:hyper.ai
公共数据集精选
1. CP2K_Benchmark 性能基准测试数据集
CP2K Benchmark 数据集是一套专门为高性能计算(HPC)环境设计的性能测试与验证输入集合。该数据集来自开源第一性原理模拟软件 CP2K,用于评估在不同硬件平台、并行策略(MPI/OpenMP)和编译优化设置下,量子化学与分子动力学计算的性能表现。
直接使用:https://go.hyper.ai/BGnLb
2. Smilei_Benchmark 等离子体动力学模拟基准测试数据集
Smilei,全称 Simulation of Matter Irradiated by Light at Extreme Intensities,是一个开源、易于使用的电磁粒子 – 网格(Particle-In-Cell, PIC)代码,旨在为激光–等离子体相互作用、粒子加速、强场 QED 和空间物理等领域提供一个高精度、高性能、可扩展的等离子体动力学模拟平台。
直接使用:https://go.hyper.ai/6VCxB
3. Gatk_benchmark 基因组分析示例数据集
GATK(Genome Analysis Toolkit)是由美国麻省理工学院与哈佛大学联合设立的 Broad Institute(博德研究所)开发的开源生物信息学工具包。该项目的目标是为高通量测序(NGS)数据提供一套标准化的分析流程。
直接使用:https://go.hyper.ai/0VAuf
4. LAMMPS-Bench 分子动力学基准数据集
LAMMPS Bench 数据集用于测试和比较 LAMMPS(分子动力学模拟软件)在不同硬件或配置上的性能表现。这些数据集并不是科学实验数据,而是用来评估计算性能(speed 、 scaling 、效率)的,包含特定体系结构、力场文件、输入脚本、初始原子坐标等内容,由 LAMMPS 官方在 bench/ 文件夹中提供。
直接使用:https://go.hyper.ai/L4gye
5. PromptCoT-2.0-SFT-4.8M 监督微调提示 SFT 数据集
PromptCoT-2.0-SFT-4.8M 是一个大规模合成提示数据集,旨在为大型语言模型提供高质量的推理提示语料以用于微调或自我演练。该数据集在监督微调与自我演练两个场景下共包含约 480 万条带有推理轨迹的完全合成提示(prompts),覆盖数学与编程两大推理领域。
直接使用:https://go.hyper.ai/f188j
6. Extract-0 文档信息提取数据
Extract-0 是一个专为文档信息抽取任务设计的高质量训练与评测数据集,旨在支持小规模参数模型在复杂抽取任务中的性能优化研究。
直接使用:https://go.hyper.ai/z9BQO
7. EmoBench-M 情绪感知基准数据集
EmoBench-M 是由深圳大学联合光明实验室、澳门大学等机构提出的一个用于评估多模态大语言模型(MLLMs)情感理解能力的基准数据集,旨在填补现有单模态或静态情感数据集在动态、多模态交互场景下的不足,更加贴近真实环境中人类情绪表达与感知的复杂性。
直接使用:https://go.hyper.ai/WafXo
8. GeoReasoning-10K 几何多模态推理数据集
GeoReasoning-10K 是一个几何领域多模态推理数据集,旨在弥合几何领域中视觉模态和语言模态之间的差距。该数据集包含 10,000 对几何图像 – 文本样本,并带有详细的几何推理注释。每个样本对均在几何结构、语义表达与视觉呈现上保持一致性,形成高精度的跨模态语义对齐映射。
直接使用:https://go.hyper.ai/7qisY

公共教程精选
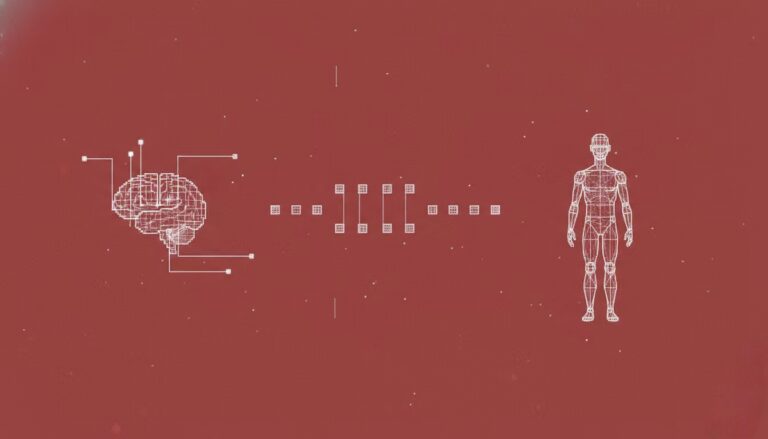
1. UserLM-8b:用户对话模拟模型
UserLM-8b 是由微软发布的用户行为模拟模型。与在对话中扮演「助手」角色的典型 LLM 不同,UserLM-8b 是用来模拟对话中的「用户」角色(基于 WildChat 对话语料库训练),可以用于大模型助手能力评估。该模型并非常见的大模型助手,不能模拟更真实的对话或者解决问题,但该模型有助于开发更强大的助手。
在线运行:https://go.hyper.ai/EHcdQ
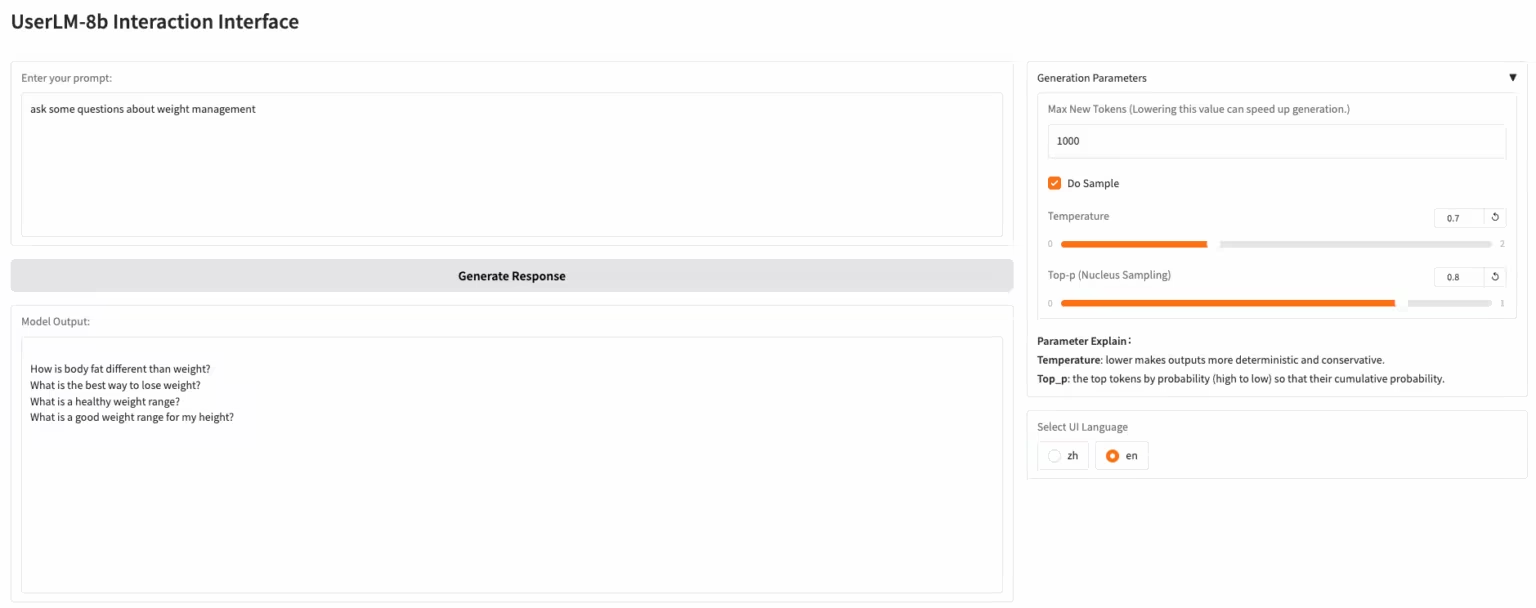
2. MiMo-Audio-7B-Instruct:小米开源的端到端语音模型
MiMo-Audio 是小米公司发布的端到端语音模型。该预训练数据已扩展至超过一亿小时,研究人员观察到它在多种音频任务上展现出了少样本学习能力。团队对这些能力进行了系统评估,发现 MiMo-Audio-7B-Base 在开源模型的语音智能与音频理解基准测试中均达到了当前最优水平(SOTA)。
在线运行:https://go.hyper.ai/3DWbb
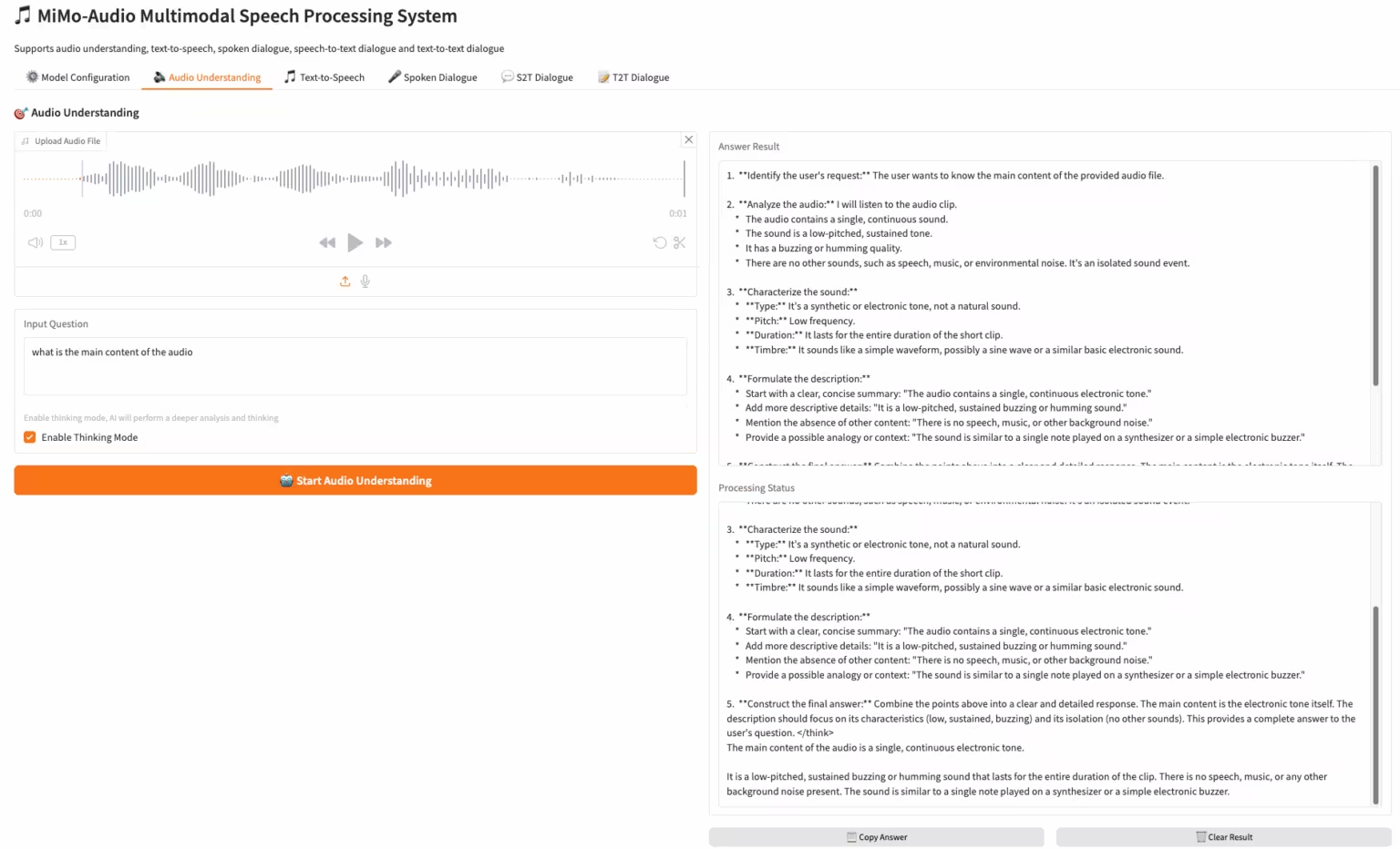
3. Wan2.2-Animate-14B:开放式高级大规模视频生成模型
Wan2.2-Animate-14B 是由阿里巴巴通义万相团队开源的一款动作生成模型,模型同时支持动作模仿和角色扮演两种模式,能基于表演者的视频,精确复制面部表情和动作,生成高度逼真的角色动画视频。
在线运行:https://go.hyper.ai/UbtSO
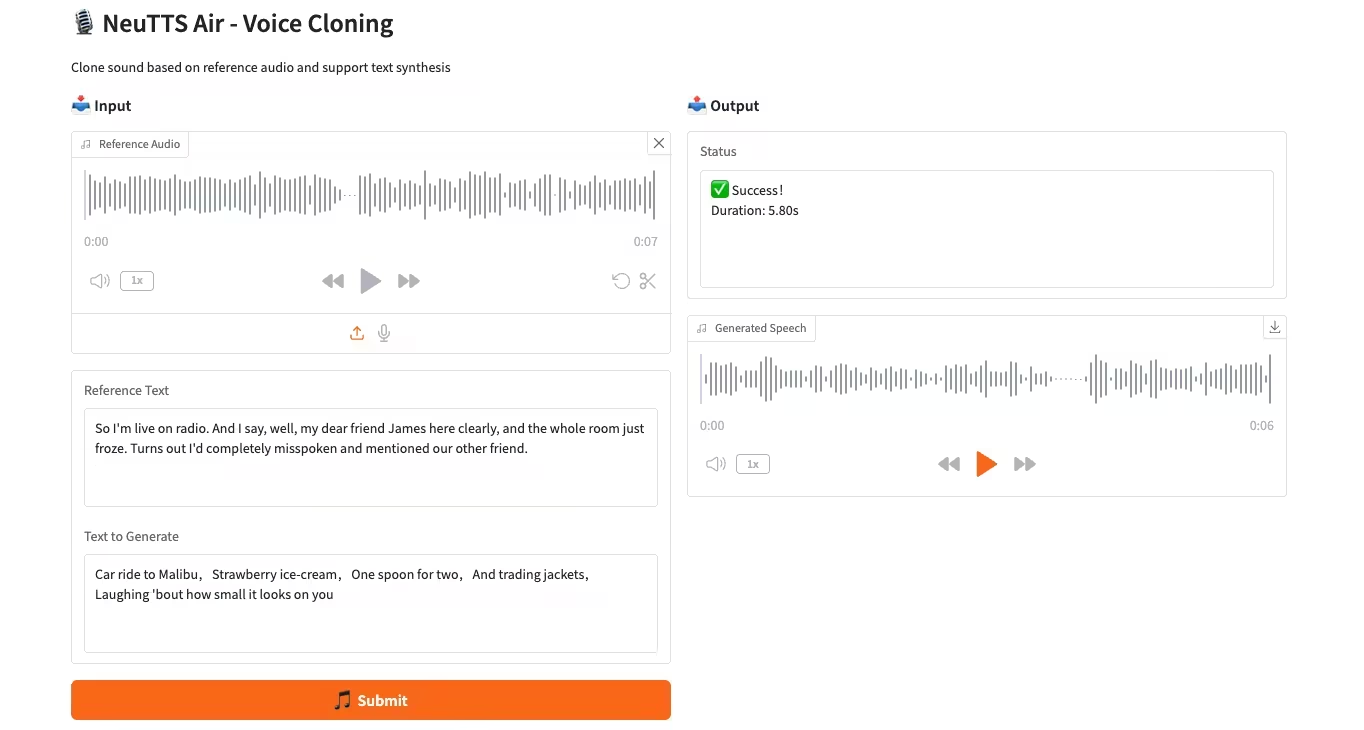
4. CPU 部署 NeuTTS-Air 语音克隆模型
NeuTTS-Air 是 Neuphonic 公司发布的端到端语音合成模型 (TTS) 。基于 0.5B Qwen LLM 主干和 NeuCodec 音频编解码器,该模型在 On-Device 部署和即时语音克隆上展现少样本学习能力。系统评估显示,NeuTTS Air 在开源模型中达到 SOTA 水平,尤其在超真实合成和实时推理基准上。
在线运行:https://go.hyper.ai/KMMG1
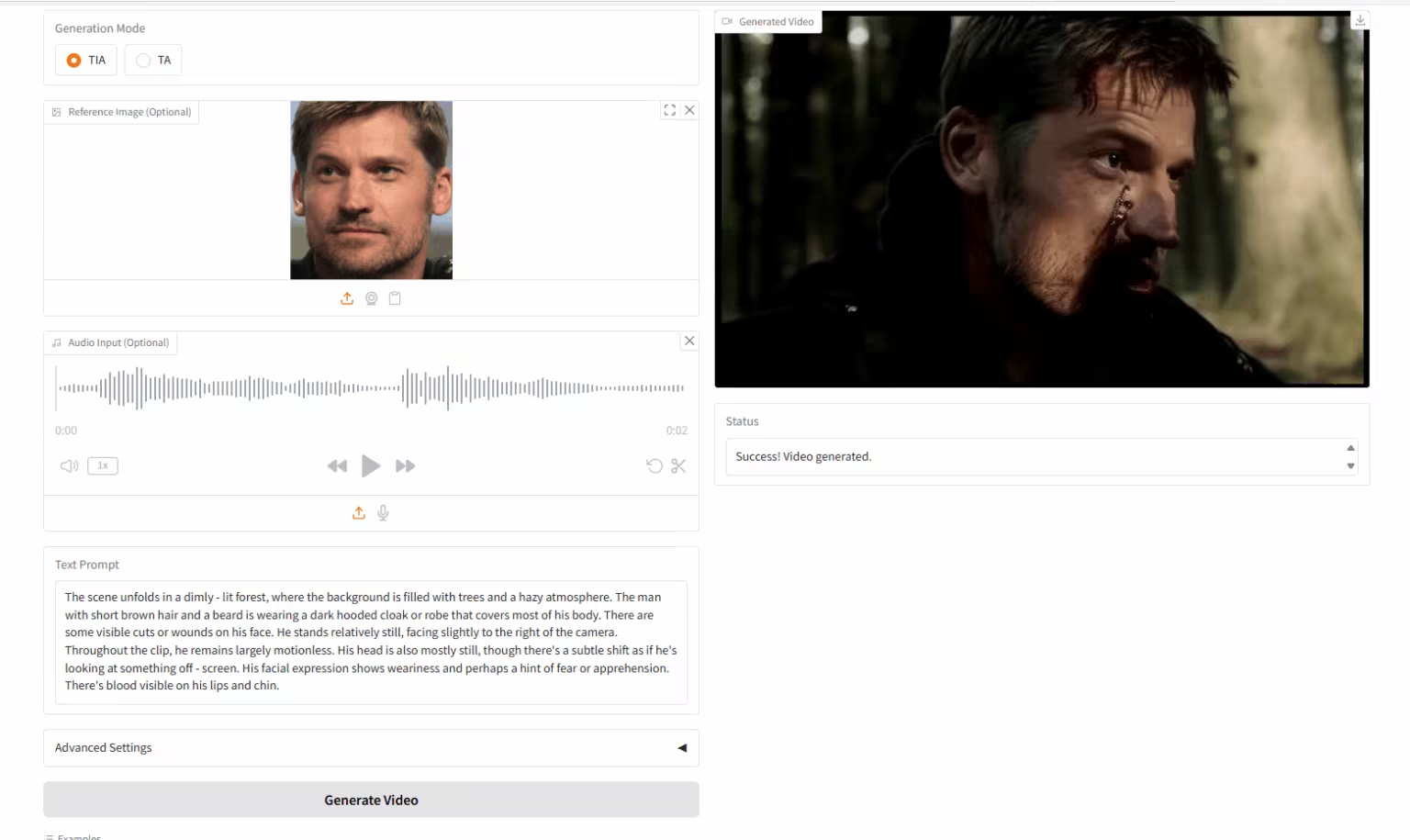
5. HuMo-1.7B:多模态视频生成框架
HuMo 是由清华大学和字节跳动智能创作实验室发布的多模态视频生成框架,专注于人类中心的视频生成。能从文本、图像和音频等多种模态输入中生成高质量、精细且可控的人类视频。该模型支持强大的文本提示跟随能力、一致的主体保留以及音频驱动的动作同步。
在线运行:https://go.hyper.ai/tnyQU
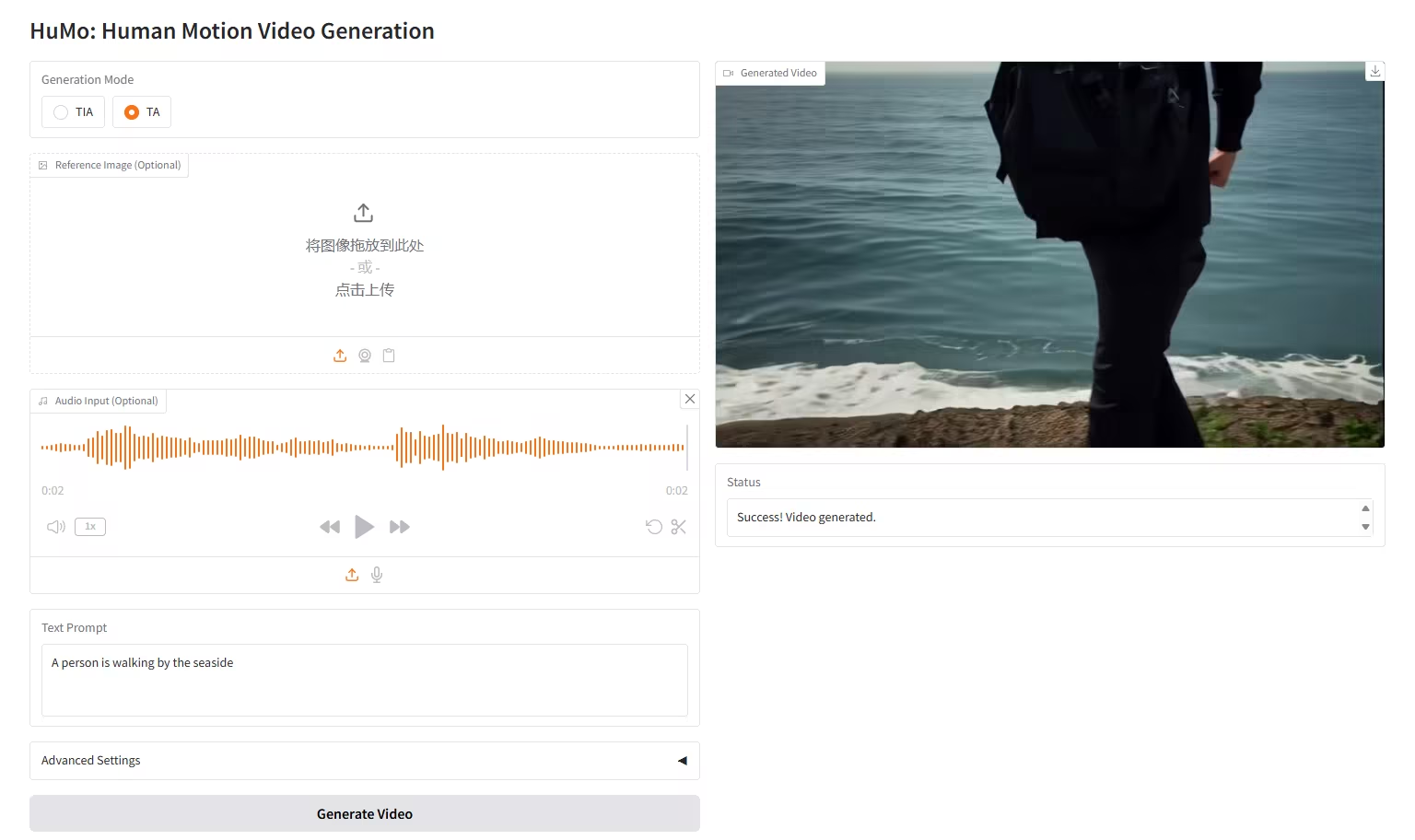
6. HuMo-17B:三模态协同创作
HuMo 是由清华大学和字节跳动智能创作实验室发布的多模态视频生成框架,支持从文本-图像(VideoGen from Text-Image)、文本-音频(VideoGen from Text-Audio)以及文本-图像-音频生成视频(VideoGen from Text-Image-Audio 。
在线运行:https://go.hyper.ai/liAti
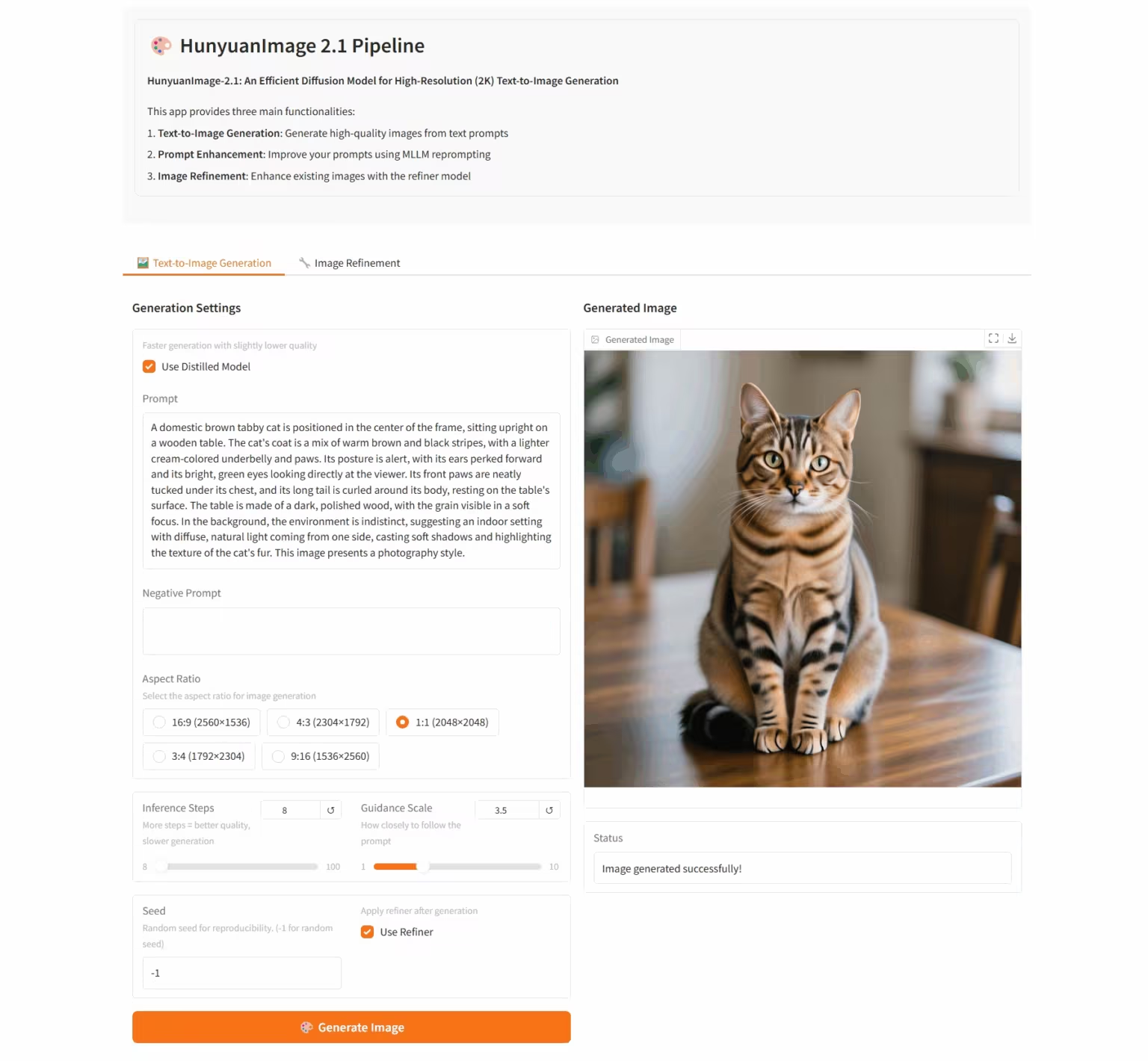
7. HunyuanImage-2.1:用于高分辨率(2K)文生图的扩散模型
HunyuanImage-2.1 是由腾讯混元团队推出的开源文生图模型,支持原生 2K 分辨率,具备强大的复杂语义理解能力,能精准生成场景细节、人物表情和动作。模型支持中英文输入,能生成多种风格的图像,如漫画、手办等,同时对图像中的文字和细节把控稳定。
在线运行:https://go.hyper.ai/hpWNA
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD 教程】,入群探讨各类技术问题、分享应用效果~

本周论文推荐
1. A Theoretical Study on Bridging Internal Probability and Self-Consistency for LLM Reasoning
本文提出 RPC(Perplexity-Consistency and Reasoning Pruning)——一种融合理论洞见的混合方法,包含两个核心组件:困惑度一致性与推理剪枝。理论分析与在七个基准数据集上的实证结果均表明,RPC 在降低推理误差方面具有显著潜力。值得注意的是,RPC 在达到与自洽性相当的推理性能的同时,不仅显著提升了置信度的可靠性,还将采样成本降低了 50% 。
论文链接:https://go.hyper.ai/V3reH
2. Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning
本技术报告提出了一系列 Ring-linear 模型,具体包括 Ring-mini-linear-2.0 和 Ring-flash-linear-2.0,这两款模型均采用混合架构,有效融合了线性注意力(linear attention)与 Softmax 注意力(softmax attention),在长上下文推理场景中显著降低了 I/O 开销与计算负担。
论文链接:https://go.hyper.ai/xLhP3
3. BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping
本文提出了一种简单而高效的方法——自适应裁剪的平衡策略优化(Balanced Policy Optimization with Adaptive Clipping, BAPO),该方法动态调整裁剪边界,自适应地重新平衡正负贡献,有效保持策略熵,显著提升 RL 优化的稳定性。
论文链接:https://go.hyper.ai/EGQ4A
4. DeepAnalyze: Agentic Large Language Models for Autonomous Data Science
本文提出 DeepAnalyze-8B,这是首个专为自主数据科学设计的智能体型大语言模型,能够自动完成从数据源到分析师级深度研究报告的端到端流程。实验结果表明,仅使用 80 亿参数,该模型在性能上已超越此前基于多数先进专有大语言模型构建的工作流型智能体。
论文链接:https://go.hyper.ai/UTdwP
5. OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM
本文提出 OmniVinci 项目,旨在构建一个强大且开源的全模态大语言模型(LLM)。研究人员对模型架构设计与数据构建策略进行了深入研究,设计并实现了一套数据构建与合成流程,生成了包含 2400 万条单模态与全模态对话的数据集。
论文链接:https://go.hyper.ai/c3yQW
更多 AI 前沿论文:https://go.hyper.ai/iSYSZ
社区文章解读
1. 入选 NeurIPS 2025,英伟达提出 ERDM 模型,解长期预报难题,中远期预报持续领先 EDM 基准
英伟达与加州大学圣迭戈分校的研究团队在阐明扩散模型(EDM)框架基础上,面向序列建模需求,系统改进了噪声调度、去噪网络参数化、预处理流程、损失加权策略及采样算法,构建出增强型序列扩散模型(ERDM)。
查看完整报道:https://go.hyper.ai/QZBBl
2. 内含教程|MIT 等推出 BindCraft,直接调用 AF2,实现蛋白质结合体的智能化设计
瑞士洛桑联邦理工学院(EPFL)与麻省理工学院(MIT)的团队提出了一个用于从头设计蛋白质结合物的开源自动化流程 BindCraft,其核心思想是通过 AlphaFold2 权重反向传播幻觉结合剂序列并计算误差梯度。
查看完整报道:https://go.hyper.ai/LqNeb
3. 2 年 3 项诺奖,Alphabet 长期科研蓄力,AI+量子计算引领的科技实力与野心
随着 2025 年诺贝尔奖出炉,谷歌母公司 Alphabet 的科学家再次获奖。作为连续两年斩获诺贝尔奖的科技大厂,其「两年三奖五得主」的成就绝非偶然。从 2024 年凭 AI 技术拿下化学奖与物理学奖,到此次摘得物理学奖的量子科研突破,十余年的野心布局和科研战略共同孕育了其强大的科研实力。
查看完整报道:https://go.hyper.ai/mY9Z3
4. MIT 基于物理先验构建生成式 AI 模型,仅需单一光谱模态输入,达到实验相关性高达 99% 的跨模态光谱生成
来自麻省理工的研究团队提出了一种物理先验生成式人工智能模型 SpectroGen,仅需单一光谱模态的输入,就能实现与实验结果相关性达 99% 的跨模态光谱生成。其引入了两项关键创新,首先是将光谱数据表示为数学分布曲线,其次是构建了一种基于物理先验的变分自动编码器生成算法。
查看完整报道:https://go.hyper.ai/OsYY2
5. 谷歌多团队联手打造 Earth AI,聚焦 3 大核心数据,地理空间推理能力提升 64%
Google 多个团队联合提出「Earth AI」地理空间人工智能模型与智能推理系统,构建可互操作的 GeoAI 模型家族,并通过定制化推理 Agent 实现多模态数据的协同分析。该系统聚焦影像、人口、环境三大核心数据类型,借助 Gemini 驱动的 Agent 串联三类模型,突破了单点模型的局限,使非专业用户也能执行跨领域实时分析,推动地球系统研究迈向可行动的全局洞察。
查看完整报道:https://go.hyper.ai/djq48
热门百科词条精选
1. DALL-E
2. 超网络 HyperNetworks
3. 帕累托前沿 Pareto Front
4. 双向长短期记忆 Bi-LSTM
5. 倒数排序融合 Reciprocal Rank Fusion
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
10 月截稿顶会

一站式追踪人工智能学术顶会:https://go.hyper.ai/event
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
关于 HyperAI 超神经 (hyper.ai)
HyperAI 超神经 (hyper.ai) 是国内领先的人工智能及高性能计算社区,致力于成为国内数据科学领域的基础设施,为国内开发者提供丰富、优质的公共资源,截至目前已经:
* 为 1800+ 公开数据集提供国内加速下载节点
* 收录 600+ 经典及流行在线教程
* 解读 200+ AI4Science 论文案例
* 支持 600+ 相关词条查询
* 托管国内首个完整的 Apache TVM 中文文档
访问官网开启学习之旅: