Command Palette
Search for a command to run...
文档解析新 SOTA!MinerU 新版本创新「由粗到细」两阶段解析策略;S2S 领域基准首发!腾讯最新基准数据集评测语音模型能力

在数字化浪潮下,各行各业积累了海量的非结构化文档数据,尤其是以 PDF 格式为主的学术论文、报告、表单等等。将这些文档高效、精准地转化为机器可读的结构化数据,是实现信息自动化提取、文档管理和智能分析的重要前提,也是释放数据价值的关键一步。
基于持续增长的 OCR 需求,OpenDataLab 与上海 AI 实验室联合推出了视觉语言模型 MinerU2.5-2509-1.2B,聚焦于将 PDF 等复杂格式文档转化为结构化的机器可读数据(如 Markdown 、 JSON 等),专为高精度、高效率的文档解析任务而设计。新版本模型通过「由粗到细」的两阶段策略实现高效解析:第一阶段通过高效的布局分析来识别结构元素,勾勒文档框架;第二阶段在原分辨率裁剪区域内进行精细识别,确保文本、公式与表格等细节还原。
MinerU2.5-2509-1.2B 将全局布局分析与局部内容识别解耦,展示了强大的文档解析能力,在多项识别任务中的表现均优于通用型及垂直领域模型,同时在计算开销上展现了显著优势。它不仅是一个技术卓越的模型,更是切实提高技术效率的工具,为下游的数据分析、信息检索、构建语料库等用户需求提供了有力支持。
目前,HyperAI 超神经官网已上线了「MinerU2.5-2509-1.2B:文档解析 Demo」,快来试试吧~
在线使用:https://go.hyper.ai/emEKs
10 月 13 日-10 月 17 日,hyper.ai 官网更新速览:
* 优质公共数据集:10 个
* 优质教程精选:11 个
* 本周论文推荐: 5 篇
* 社区文章解读:5 篇
* 热门百科词条:5 条
* 10 月截稿顶会:1 个
访问官网:hyper.ai
公共数据集精选
1. FDAbench-Full 异构数据分析基准数据集
FDAbench-Full 是由南洋理工大学、新加坡国立大学联合华为技术有限公司发布的首个面向数据代理(Data Agents)的异构数据分析任务基准测试集,旨在评估模型在数据库查询生成、 SQL 理解 以及金融数据分析等方面的能力。
直接使用:https://go.hyper.ai/AUjv5
2. PubMedVision 医疗多模态评估数据集
PubMedVision 是一个用于医学多模态能力评估的数据集,涵盖多种医学成像模态与解剖区域,旨在为多模态大语言模型(MLLMs)在医疗视觉-文本理解任务方面提供标准化测试资源,以检验它们在医学领域的视觉知识融合与推理性能。
直接使用:https://go.hyper.ai/qdvVe
3. Verse-Bench 视听联合生成评测数据集
Verse-Bench 是由 StepFun 联合香港科技大学、香港科技大学(广州)等机构发布的一个用于评估音频与视频联合生成的基准数据集,旨在推动生成模型不仅能生成视频,还能在时间上与音频内容(包括环境音与语音)保持严格对齐。
直接使用:https://go.hyper.ai/mvau0

4. MMMC 教育视频生成基准数据集
MMMC 是由新加坡国立大学 Show Lab 发布的一个用于教学视频生成的大规模多学科教育视频生成基准数据集,旨在为教育类人工智能模型提供高质量的训练与评测资源,支持从结构化代码与教学内容自动生成专业教学视频的研究。
直接使用:https://go.hyper.ai/AELav
5. T2I-CoReBench 多模态图像生成基准数据集
T2I-CoReBench 是由中国科学技术大学联合快手科技 Kling 团队、香港大学提出的一个面向文本驱动图像生成模型的综合评测基准,旨在同时衡量图像生成模型的组合能力与推理能力。
直接使用:https://go.hyper.ai/SLyED
6. WildSpeech-Bench 语音理解生成基准数据集
WildSpeech-Bench 是由腾讯发布的首个用于评估 SpeechLLM 语音转语音能力的基准,旨在衡量模型在真实语音交互场景中完整语音输入到语音输出(Speech-to-Speech, S2S)的理解与生成能力。
直接使用:https://go.hyper.ai/Cy63e
7. OmniRetarget 全域机器人运动重映射数据集
OmniRetarget 是由亚马逊联合麻省理工学院、加利福尼亚大学伯克利分校等机构发布的一个用于类人机器人全身运动重映射的高质量轨迹数据集,包含 G1 仿人机器人与物体及复杂地形交互时的运动轨迹,涵盖机器人携物运动、地形行走及物体-地形混合交互三类场景。
直接使用:https://go.hyper.ai/xfZY4

8. Paper2Video 论文视频基准数据
Paper2Video 是由新加坡国立大学发布的首个论文与视频配对的基准数据集,旨在为从学术论文自动生成演示视频(包括幻灯片、字幕、语音、以及演讲者头像)任务提供标准基准与评估资源。
直接使用:https://go.hyper.ai/NeRuV
9. FoMER Bench 多模态评测数据集
FoMER Bench 是一个基础模型具身推理(FoMER)基准,涵盖 3 种不同的机器人类型和多种机器人模式,旨在评估 LMM 在复杂具身决策场景中的推理能力。
直接使用:https://go.hyper.ai/Tiy5w
10. OCRBench-v2 文本识别基准数据集
OCRBench-v2 是由华中科技大学联合华南理工大学、字节跳动等机构发布的一个多模态大型模型光学字符识别(OCR)的评估基准,旨在评估大型多模态模型(LMM)在不同文本相关任务中的 OCR 能力。
直接使用:https://go.hyper.ai/hhGFR
公共教程精选
本周汇总了 4 类优质公共教程:
* OCR 教程:2 个
* AI4S 教程:2 个
* 大模型 教程:1 个
* 多模态 教程:6 个
OCR 教程
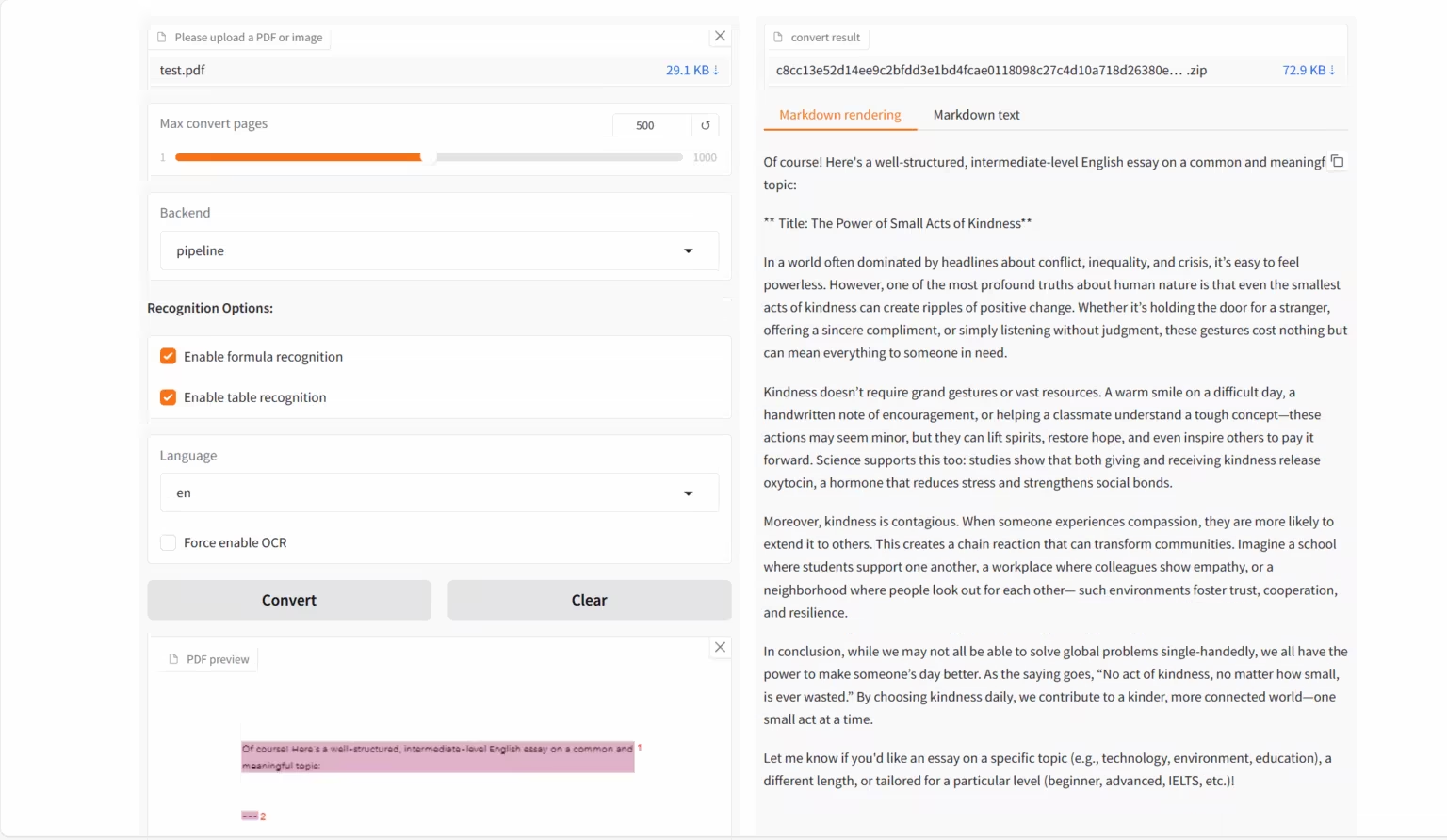
1. MinerU2.5-2509-1.2B:文档解析 Demo
MinerU2.5-2509-1.2B 是由 OpenDataLab 与上海 AI 实验室推出的视觉语言模型,专为高精度、高效率的文档解析任务而设计。它是 MinerU 系列的最新迭代版本,聚焦于将 PDF 等复杂格式文档转化为结构化的机器可读数据(如 Markdown 、 JSON 等)。
在线运行:https://go.hyper.ai/emEKs
2. Dolphin 多模态文档图像解析
Dolphin 是由字节跳动团队推出的多模态文档解析模型。该模型基于先解析结构后解析内容的两阶段方法第一阶段生成文档布局元素序列,第二阶段用元素作为锚点并行解析内容。 Dolphin 在多种文档解析任务上表现出色,性能超越 GPT-4.1 、 Mistral-OCR 等模型。
在线运行:https://go.hyper.ai/lLT6X

AI4S 教程
1. BindCraft:蛋白质粘合剂设计
BindCraft 是由 Martin Pacesa 开源的一键式蛋白质结合剂设计管道,宣称实验成功率 10–100% 。它直接调用 AlphaFold2 预训练权重,无需高通量筛选、实验迭代,甚至无需已知结合位点,即可在硅片中生成纳摩尔级亲和力的从头结合剂。
在线运行:https://go.hyper.ai/eSoHk
2. Ml-simplefold:轻量级蛋白质折叠预测 AI 模型
Ml-simplefold 是由苹果公司推出的轻量级蛋白质折叠预测 AI 模型。模型基于流匹配(Flow Matching)技术,跳过多序列比对(MSA)等复杂模块,直接从随机噪声生成蛋白质的三维结构,大幅降低计算成本。
在线运行:https://go.hyper.ai/Y0Us9
大模型教程
1. SpikingBrain-1.0 基于内生复杂性的类脑脉冲大模型
「瞬悉 1.0」(SpikingBrain-1.0)是由中国科学院自动化研究所联合脑认知与类脑智能全国重点实验室、沐曦集成电路有限公司等机构发布原生国产自主可控类脑脉冲大模型。该模型受大脑机制启发,将混合高效注意力机制、 MoE 模块和脉冲编码集成到其架构中,并由与开源模型生态系统兼容的通用转换管道支持。
在线运行:https://go.hyper.ai/i3zHC
多模态教程
1. HuMo-1.7B:多模态视频生成框架
HuMo 是由清华大学和字节跳动智能创作实验室发布的多模态视频生成框架,专注于人类中心的视频生成。能从文本、图像和音频等多种模态输入中生成高质量、精细且可控的人类视频。
在线运行:https://go.hyper.ai/Xe4dM
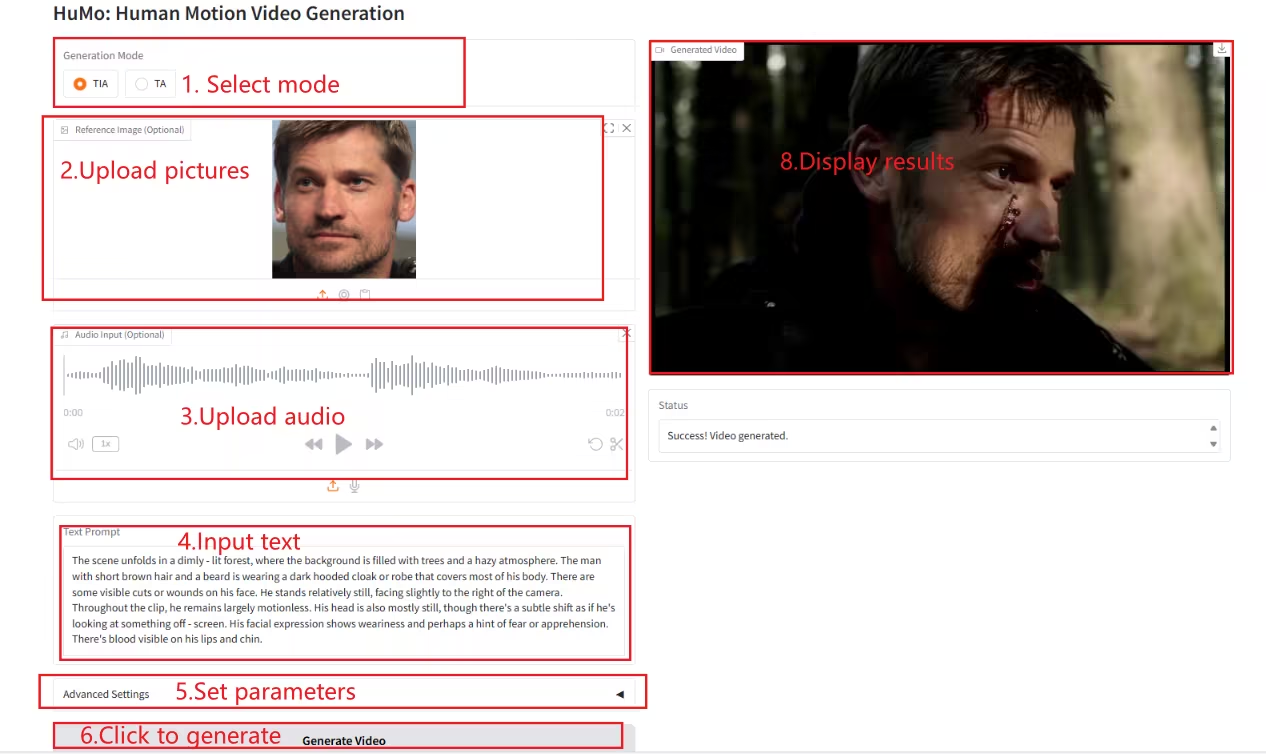
2. NeuTTS-Air: 轻量高效语音克隆模型
NeuTTS-Air 是 Neuphonic 公司发布的端到端语音合成模型 (TTS) 。基于 0.5B Qwen LLM 主干和 NeuCodec 音频编解码器,它在 On-Device 部署和即时语音克隆上展现少样本学习能力。系统评估显示,NeuTTS Air 在开源模型中达到 SOTA 水平,尤其在超真实合成和实时推理基准上。
在线运行:https://go.hyper.ai/7ONYq
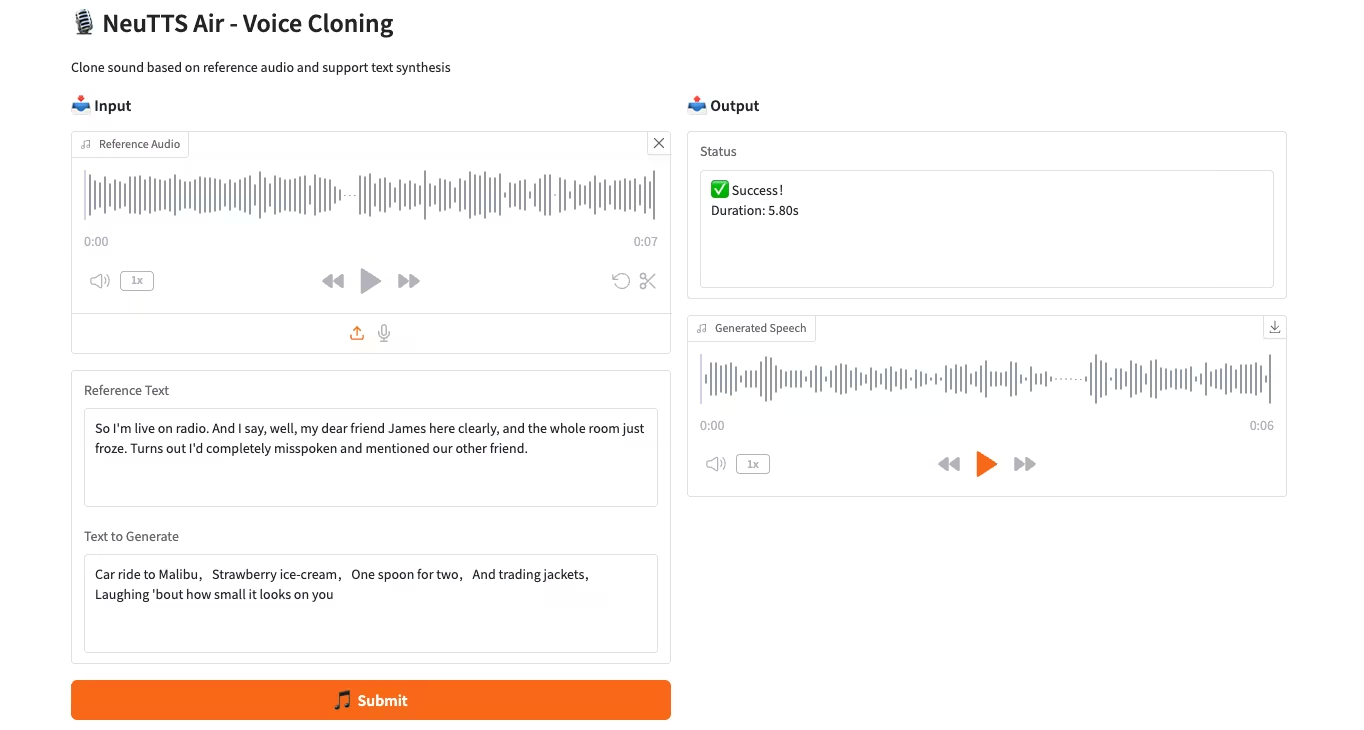
3. Moondream3-preview:模块化视觉语言理解模型
Moondream3 是由 Moondream 团队提出来的基于混合专家架构的视觉语言模型,拥有 90 亿参数(其中 20 亿为激活参数)。该模型提供最先进的视觉推理能力,支持最大 32K 上下文长度,能够高效处理高分辨率图像。
在线运行:https://go.hyper.ai/eKGcP
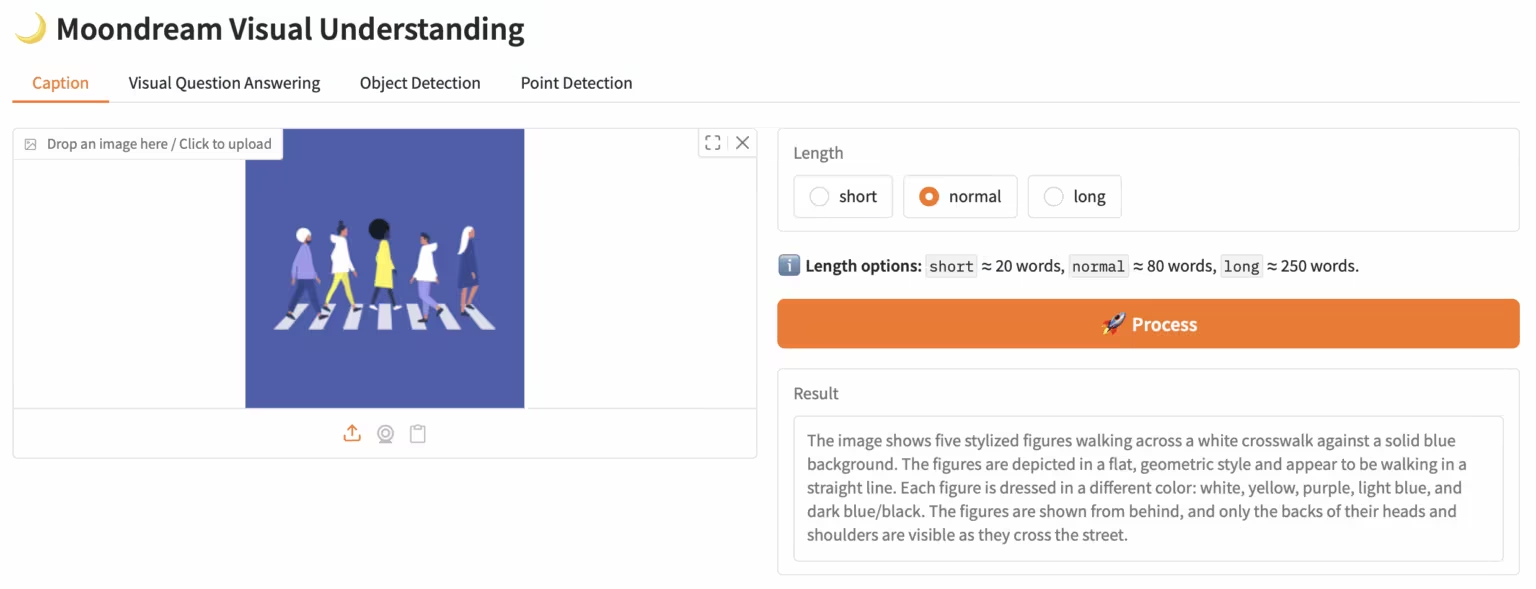
4. LiveCC:实时视频解说大模型
LiveCC 是一个专注于大规模流式语音转录的视频大语言模型项目,该项目旨在通过创新的视频-自动语音识别(ASR)流式方法训练出首个具备实时评论能力的视频大语言模型,在流式和离线基准测试中均达到了当前最优水平。
在线运行:https://go.hyper.ai/3Gdr2
5. Hunyuan3D-Part:组件式 3D 生成模型
Hunyuan3D-Part 是由腾讯混元团队推出的 3D 生成模型,由 P3–SAM 和 X–Part 组成,首次实现高精度、可控的组件式 3D 生成,支持 50+ 组件自动生成。在游戏建模、 3D 打印等领域有广泛应用,如将汽车模型拆分车身和轮子,便于游戏绑定滚动逻辑或 3D 打印分步制作。
在线运行:https://go.hyper.ai/1w1Jq

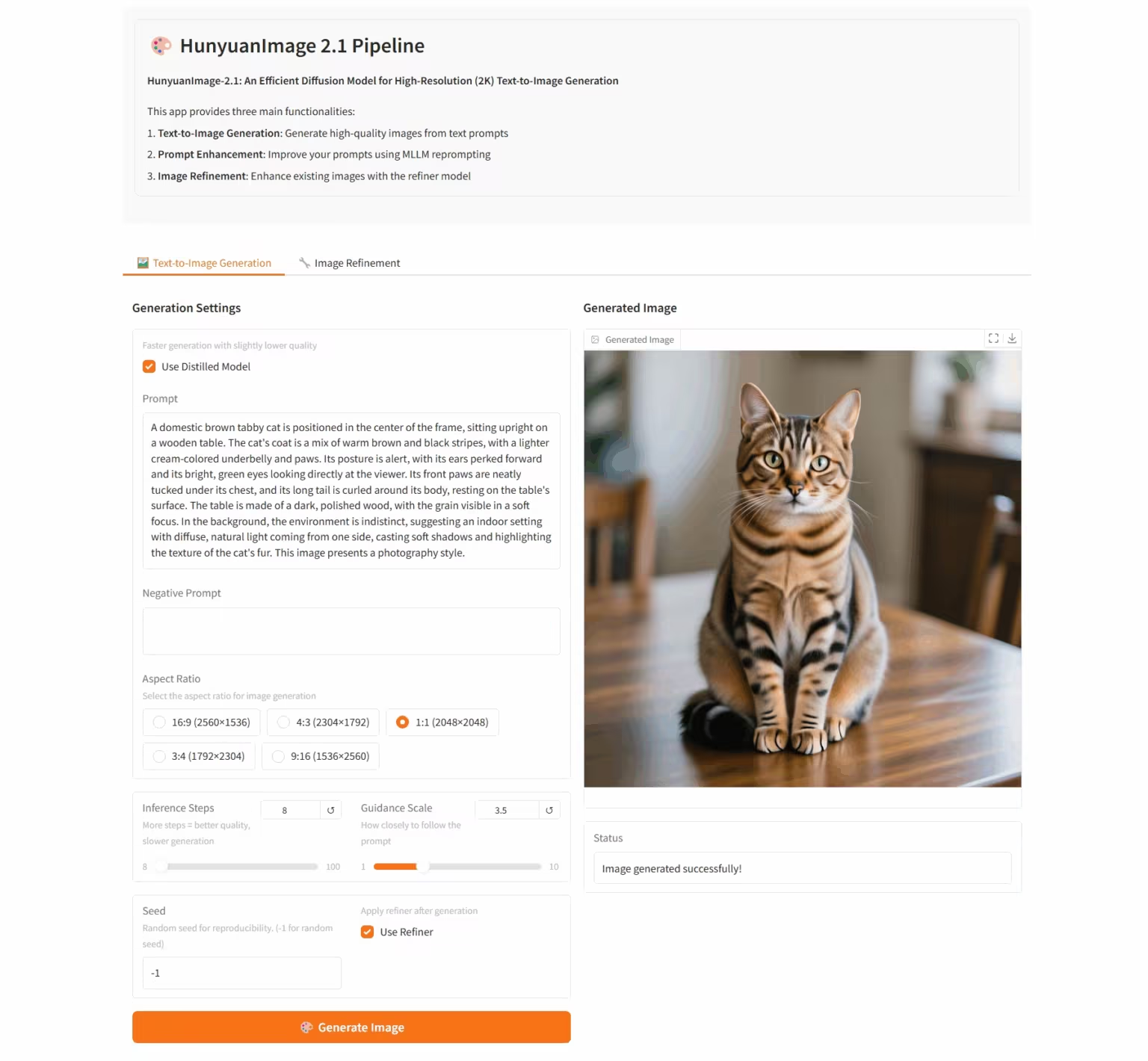
6. HunyuanImage-2.1:用于高分辨率(2K)文生图的扩散模型
HunyuanImage-2.1 是由腾讯混元团队推出的开源文生图模型,支持原生 2K 分辨率,具备强大的复杂语义理解能力,能精准生成场景细节、人物表情和动作。模型支持中英文输入,能生成多种风格的图像,如漫画、手办等,同时对图像中的文字和细节把控稳定。
在线运行:https://go.hyper.ai/i96yp
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD 教程】,入群探讨各类技术问题、分享应用效果~

本周论文推荐
1. QeRL: Beyond Efficiency — Quantization-enhanced Reinforcement Learning for LLMs
本文提出了 QeRL——一种面向大语言模型的量化增强型强化学习框架。该模型通过结合 NVFP4 量化技术与低秩适配(LoRA),在加速 RL 采样阶段的同时显著降低了内存开销。 QeRL 是首个能够在单张 H100 80GB GPU 上完成 320 亿参数(32B)大模型强化学习训练的框架,同时实现了整体训练速度的提升。
论文链接:https://go.hyper.ai/catLh
2. Diffusion Transformers with Representation Autoencoders
本文探索用预训练的表征编码器(如 DINO 、 SigLIP 、 MAE)结合训练好的解码器替代 VAE,构建我们称之为表征自编码器(RAEs)的新架构。这类模型不仅能够实现高质量的重建,还具备语义丰富的潜在空间,同时支持可扩展的基于 Transformer 的架构设计。
论文链接:https://go.hyper.ai/fqVs4
3. D2E: Scaling Vision-Action Pretraining on Desktop Data for Transfer to Embodied AI
本文提出了 D2E(Desktop to Embodied AI)框架,证明桌面交互可作为机器人具身 AI 任务的有效预训练基础。与以往局限于特定领域或数据封闭的方案不同,D2E 建立了一条从可扩展的桌面数据采集到具身领域验证迁移的完整技术链条。
论文链接:https://go.hyper.ai/aNbE4
4. Thinking with Camera: A Unified Multimodal Model for Camera-Centric Understanding and Generation
本文提出了 Puffin——一种统一的、以相机为中心的多模态模型,该模型将空间感知能力沿相机维度进行拓展,融合语言回归与基于扩散的生成技术,能够从任意视角解析并生成场景。
论文链接:https://go.hyper.ai/9JBvw
5. DITING: A Multi-Agent Evaluation Framework for Benchmarking Web Novel Translation
本文提出了 DITING——首个面向网络小说翻译的综合性评估框架,从六个维度系统评估翻译的叙事一致性和文化忠实度:成语翻译、词汇歧义处理、术语本地化、时态一致性、零代词消解以及文化安全性,并基于超过 18,000 对专家标注的中英句子对提供支持。
论文链接:https://go.hyper.ai/KRUmn
更多 AI 前沿论文:https://go.hyper.ai/iSYSZ
社区文章解读
1. 香港科技大学等提出增量天气预报模型 VA-MoE,参数精简 75% 仍达 SOTA 性能
香港科技大学与浙江大学等研究团队推出「变量自适应专家混合模型(VA-MoE)」。该模型通过分阶段训练与变量索引嵌入机制,引导不同专家模块专注特定类型的气象变量,当新增变量或站点时,无需全量重训即可实现模型扩展,在保障精度的同时大幅降低计算开销。
查看完整报道:https://go.hyper.ai/nPWPN
2. NeurIPS 2025 丨华中科大等发布 OCRBench v2,Gemini 获中文榜冠军但分数仅及格
华中科技大学白翔团队联合华南理工大学、阿德莱德大学和字节跳动推出新一代 OCR 评测基准 OCRBench v2,分别从中文和英语两个语种上,对 2023 年至 2025 年间全球 58 个主流多模态大模型进行了测评。
查看完整报道:https://go.hyper.ai/AL1ZJ
3. 入选 NeurIPS 2025,多伦多大学等提出 Ctrl-DNA 框架,实现特定细胞基因表达的「靶向控制」
多伦多大学团队联合昌平实验室等开发了一种名为 Ctrl-DNA 的约束强化学习框架,可最大化 CRE 在目标细胞中的调控活性,同时严格限制其在非目标细胞中的活性。
查看完整报道:https://go.hyper.ai/eVORr
4. AI 预判等离子体「暴走」,MIT 等基于机器学习实现小样本下的等离子体动力学高精度预测
麻省理工学院牵头的研究团队利用科学机器学习,将物理定律与实验数据智能融合。开发了一种神经状态空间模型,通过少量数据就能预测托卡马克配置变量 (TCV) 缓降过程中的等离子体动力学,以及可能出现的不稳定情况。
查看完整报道:https://go.hyper.ai/HQgZx
5. MOF 结构 36 年终获诺奖:当 AI 读懂化学,金属有机框架正迈向生成式研究时代
2025 年 10 月 8 日,为金属有机框架领域研究作出贡献的北川进、 Richard Robson 和 Omar Yaghi 荣获诺贝尔化学奖。金属有机框架领域历经三十余年,完成了从结构设计到产业化的演进,奠定了化学可计算的基础。如今,人工智能正以生成模型和扩散算法重塑 MOF 研究,开启化学设计的全新时代。
查看完整报道:https://go.hyper.ai/U5XgN
热门百科词条精选
1. DALL-E
2. 超网络 HyperNetworks
3. 帕累托前沿 Pareto Front
4. 双向长短期记忆 Bi-LSTM
5. 倒数排序融合 Reciprocal Rank Fusion
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
10 月截稿顶会

一站式追踪人工智能学术顶会:https://go.hyper.ai/event
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
关于 HyperAI 超神经 (hyper.ai)
HyperAI 超神经 (hyper.ai) 是国内领先的人工智能及高性能计算社区,致力于成为国内数据科学领域的基础设施,为国内开发者提供丰富、优质的公共资源,截至目前已经:
* 为 1800+ 公开数据集提供国内加速下载节点
* 收录 600+ 经典及流行在线教程
* 解读 200+ AI4Science 论文案例
* 支持 600+ 相关词条查询
* 托管国内首个完整的 Apache TVM 中文文档
访问官网开启学习之旅:








