Command Palette
Search for a command to run...
上海交大余祥课题组发布可迁移深度学习模型,鉴定多类型 RNA 修饰、显著减少计算成本

2021 年,因中国科学院院士高福大声疾呼,mRNA 疫苗一夜之间名声鹊起,成为人们在新型冠状病毒肆虐期间的希望。如今,那段特殊过往已成历史,但 mRNA 疫苗背后的 RNA 修饰却仍在以日新月异的速度向前发展。
所谓 RNA 修饰,是一类重要转录后调控方式,能够广泛参与各种 RNA 转录后的加工代谢途径。
RNA 修饰之所以值得被关注,还因其在真核生物生长发育过程中发挥了至关重要的生物学功能。例如,近年研究发现,N⁶-甲基腺苷 (m⁶A) 在哺乳动物胚胎干细胞中的去稳定化作用与多种疾病相关,5-甲基胞嘧啶 (m⁵C) 与水稻对高温的耐受性有关。
不过,RNA 具有多种类型的修饰,迄今为止,自然界 RNA 中被发现的修饰类型已超过 160 种。此前,由牛津纳米孔科技有限公司 (Oxford Nanopore Technologies, ONT) 开发的纳米孔直接 RNA 测序 (Direct RNA Sequencing, DRS) 技术,结合深度学习方法,可以实现单个碱基的修饰识别,但该方法难以在单个样本中同时检测多种修饰类型。
针对以上问题,上海交通大学生命科学技术学院长聘教轨副教授余祥课题组,联合上海辰山植物园杨俊 / 王红霞团队,在「Nature Communications」发表了题为「Transfer learning enables identification of multiple types of RNA modifications using nanopore direct RNA sequencing」的研究论文,开发了可迁移深度学习模型 TandemMod,实现了在 DRS 中鉴定多种类型的 RNA 修饰。
研究亮点:
* 在保证同等性能的条件下,显著减少训练集数据量和模型训练时间等计算成本
* TandemMod 为动植物和微生物体内,多种类型的 RNA 修饰位点鉴定及表观转录组研究,提供重要技术支撑
* TandemMod 还可用于检测 RNA 疫苗等人工修饰的 RNA

论文地址:
https://www.nature.com/articles/s41467-024-48437-4
开源项目「awesome-ai4s」汇集了百余篇 AI4S 论文解读,并提供海量数据集与工具:
https://github.com/hyperai/awesome-ai4s
数据集:多重数据集针对性训练
为了训练、评估 TandemMod 模型性能,研究团队采用了多组数据集进行实验。
首先,研究团队利用 Nookaew 实验室生成的体外转录数据集 ELIGOS,计算了 6 种修饰碱基 (m¹A 、 m⁶A 、 m⁵C 、 hm⁵C 、 m⁷G 、Ψ) 的 5 个基级特征(均值、中位数、标准差、信号长度和碱基质量),并与未修饰的碱基进行了比较。
其次,研究团队选择基于真核 mRNA 中最常见的两种修饰 m⁵C 和 m⁶A,研究 TandemMod 的性能。研究人员在 Curlcake 数据集上训练了 TandemMod m⁵C 模型,该数据集来自包含所有可能的 5-mers 的体外转录序列,并按 4:1 的比例分为训练集和测试集。
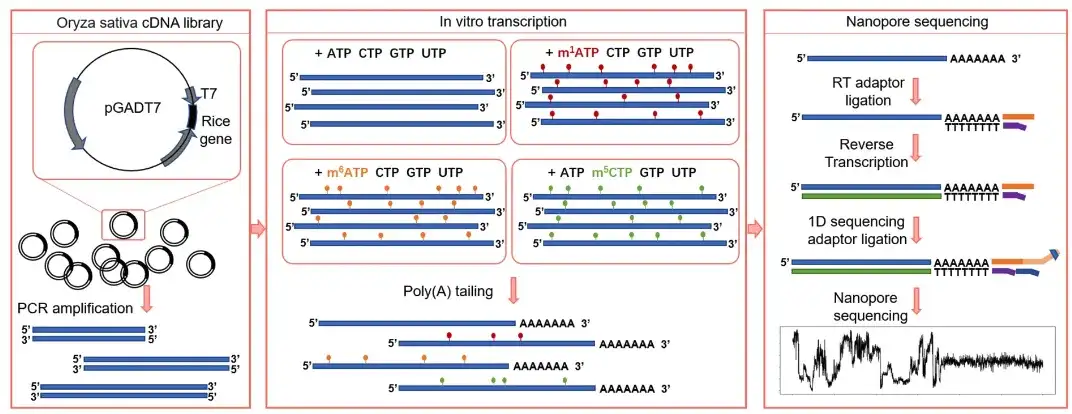
同时,为解决体外合成序列转录的 RNA 无法覆盖自然序列全部范围的问题,研究团队对含有 T7 启动子的水稻 cDNA 文库进行体外转录,得到了具备不同修饰标签的数千个转录本,加 polyA 尾后通过 DRS 构建了 4 个训练集 (m¹A 、 m⁶A 、 m⁵C 和未修饰碱基),称为体外表观转录组数据集 (IVET) 。
模型架构:一种深度学习框架
以此为基础,研究团队以每 5 个碱基分配到的电信号及其统计特征作为输入,训练可同时检测多种 RNA 修饰类型的迁移学习模型 TandemMod 。
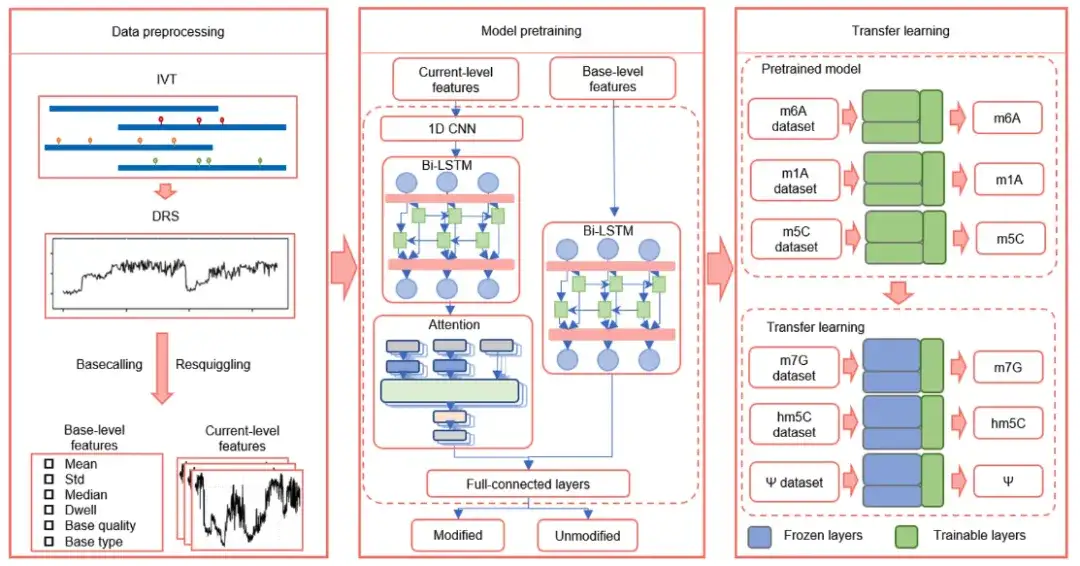
如上图所示,TandemMod 由数据预处理 (Data preprocessing) 、模型预训练 (Model pretraining) 和迁移学习 (Transfer learning) 组成。
其中,模型预训练由 4 个主要组件构成:
* 一维卷积神经网络 (1D-CNN),用于提取原始电流强度信号的局部特征;
* 双向长短期记忆模块 (Bi-LSTM),用于捕获相邻信号之间的长期相关性,提升更长过程中上下文的理解能力;
* 注意力机制 (Attention),用于加权每个特征在不同时间不长的重要性,提升模型对于重要信号的捕捉能力;
* 全连接层 (full-connected layers) 的分类器,负责根据所有特征的组合信息进行预测。
此外,为了验证迁移学习能否应用于 DRS 数据,以实现对多种类型 RNA 修饰的检测,研究人员在 IVET m5C 数据集上训练了 TandemMod,得到了一个预训练模型 (Pretrained model) 。在 TandemMod 模型中,顶层充当特征提取器,底层充当分类器。研究人员冻结 (froze) 了预训练模型的顶层,并在 ELIGOS 训练集 (hm5C 、 m7G 、Ψ 和 I) 上重新训练了底层,以尽量减少分类误差。

经过 2 个周期,所有模型都达到了高准确度,hm⁵C 、 m⁷G 、Ψ 和 I 的 ROC-AUC 分别达到了 0.98 、 0.95 、 0.96 和 0.97 。如上图 a 、 b 、 c 、 d 所示。
实验结果:TandemMod 显著减少训练集数据量和模型训练时间
实验阶段,研究团队将 TandemMod 模型与经典机器学习算法进行了比较来评估其性能,比较对象分别为 XGBoost 、 support vector machine (SVM) 和 k-nearest neighbor (KNN) 。在 Curlcake 测试数据集 m⁶A 识别的情况下,TandemMod 以 0.90 的准确率优于其他算法。同样,对于 m⁵C 的识别,TandemMod 准确率达到 0.95,这一比较突出了 TandemMod 在使用 DRS 数据识别修改方面的有效性。
在识别体内不同修饰率水平的样本方面,TandemMod 相较 tombo 和 xPore 也显示出了更好的优越性。这表明 TandemMod 不需要阴性对照样本就可以准确预测不同修饰率的样本。
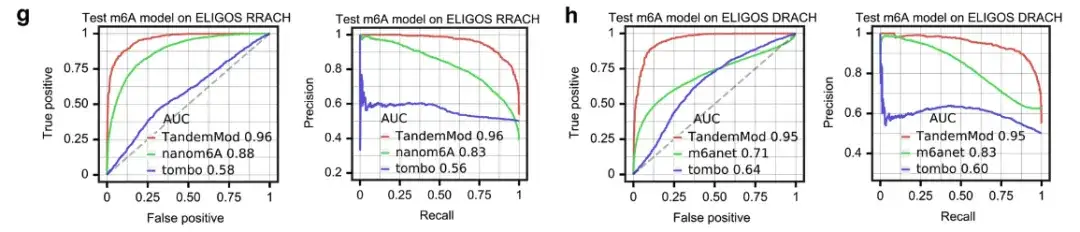
此外,研究团队还将 TandemMod m⁶A 模型与 tombo 、 nanom6A 和 m6Anet 进行了比较,如上图所示。
在 ELIGOS rash (R-A 或 G, H-A, 或 C 或 U) 基序上,TandemMod 、 nanom6A 和 tombo 的 ROC-AUC 分别为 0.96 、 0.88 和 0.52 。在 ELIGOS DRACH (D-A, G,或 U) 基序上,TandemMod 、 m6Anet 和 tombo 的 ROC-AUC 分别为 0.95 、 0.71 和 0.64 。
这些结果表明,使用体外 DRS 数据集进行训练,TandemMod 在现有工具中提供了最准确的读取水平预测。
研究团队验证了 TandemMod m⁵C 模型在 m⁶A 检测中,迁移学习的分类性能、所需训练数据和计算资源利用率,并与标准实例的 TandemMod m⁶A 模型进行了比较。结果表明,迁移学习可在保证同等性能的条件下,显著减少训练集数据量和模型训练时间等成本。
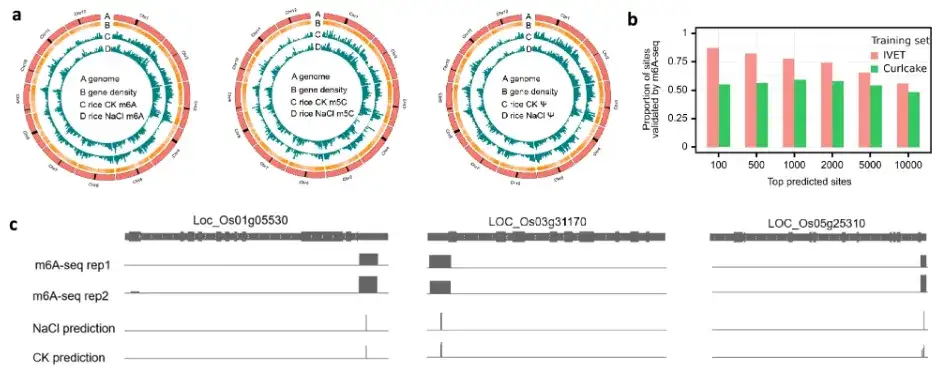
最后,研究团队检验了 TandemMod 模型推广到新物种进行 DRS 数据测序的能力,使用人类细胞系(2 个修饰酶敲除样本和 5 个野生型样本)进一步验证了 TandemMod 的可靠性。同时,研究团队还通过 TandemMod 绘制了水稻幼苗在高盐胁迫下 m⁶A 、 m⁵C 和 Ψ 的表观修饰图谱,并揭示了 mRNA 中 m⁶A 和 m⁵C 的共修饰及其在高盐环境下的修饰率变化。如上图所示。
RNA 修饰开启生命探索的新大门
古往今来,人们对于生命的探索从未停止。而在 RNA 世界假说提出后,RNA 作为生命起源的论调无疑成为当前最让人信服的答案之一。自 1960 年第一个 RNA 修饰被发现以来,其就早已成为科研界探索的重中之重,在近年的研究中仍保持着极高的关注度。
除了本论文余祥课题组以及杨俊 / 王红霞团队,以及文中所提到的 ONT 公司外,还有更多的团队和企业也在进行 RNA 修饰研究。

例如,在 2021 年,西交利物浦大学孟佳教授团队在「Nature Communications」期刊上发表了题为「Attention-based multi-label neural networks for integratedprediction and interpretation of twelve widely occurring RNA modifications」的文章。
论文地址:https://www.nature.com/articles/s41467-021-24313-3
文中提到了一种基于注意力机制的多标签深度学习框架的模型 MultiRM,不仅可以同时预测 12 个广泛存在的转录组位点,而且对预测过程中的关键序列进行了提取分析,揭示了不同类型的 RNA 修饰之间有很强的关联,有助于更好的综合分析和理解基于序列的 RNA 修饰机制。

无独有偶,「Nature Biotechnology」于 2021 年收录的一篇名为「Identification of differential RNA modifications from nanopore direct RNA sequencing with xPore」的论文中,研究团队利用 xPore 从 Direct RNA-seq 数据中高精度鉴定 RNA 修饰,并从单次高通量实验中分析差异修饰和表达。
论文地址:https://www.nature.com/articles/s41587-021-00949-w
这些研究正在帮助我们进一步推开 RNA 世界的大门,从而让我们进一步探索「生命的真谛」。虽然目前各项研究的进展仍有大量的瓶颈需要突破,但「先驱者」不断地挑战早已让 RNA 研究的大门越发敞亮。
参考资料:
1. https://news.sjtu.edu.cn/jdzh/2








