Command Palette
Search for a command to run...
AI 卷到正经「挖矿」业,卡内基科学研究所另辟蹊径,靠关联分析法找到新矿床

内容一览:矿物为技术社会提供了重要的原材料,同时也是许多地质事件和古代环境的唯一证据。几个世纪以来,寻找矿产资源以及探寻其起源和分布的基本原理,一直是地质学的主要关注点。近期,美国国家科学院院刊子刊《PNAS Nexus》发布了一篇研究成果,利用机器学习模型,通过矿物关联分析来预测新矿床地址和矿物种类。
关键词:机器学习 关联分析 矿物勘探
本文首发自 HyperAI 超神经微信公众平台~
矿物在几十亿年前出现,并在生物进化过程中起到了至关重要的作用。目前的地质行业勘探技术虽然很多,但因矿产资源具有隐蔽性和不确定性等属性,矿产勘探过程非常曲折,同时面临风险高、投资周期长且找矿成功率低等多种挑战。
过去的研究中,科学家们发现,地球上超过 5,000 种矿物并非随机分布,很多都存在于共生关系 (paragenesis) 中。所谓的共生关系,是特定的物理化学规律下形成的矿物组合,例如矿物的形成与宿主岩石的化学成分和环境条件密切相关。
近期,华盛顿卡内基科学研究所 (Carnegie Institution for Science) 的 Morrison Shaunna M 联合来自亚利桑那大学 (University Of Arizona) 的 Prabhu Anirudh 等人,采用机器学习发现矿物组合规律,来预测矿物位置。目前研究成果已发布在《PNAS Nexus》期刊上,标题为「Predicting new mineral occurrences and planetary analog environments via mineral association analysis」。

该研究成果已发表在《PNAS Nexus》上
论文地址:
https://academic.oup.com/pnasnexus/article/2/5/pgad110/7163824?login=true
实验概述
研究人员开发了一个机器学习模型,使用矿物演化数据库的数据,根据关联规则预测矿物位置,并在特科帕盆地(一个著名的火星模拟环境)测试模型。实验结果显示,机器学习能有效预测出矿物位置、矿物种类及矿物量。
关联分析是一种机器学习方法,用于发现数据集中的关联规则和模式。它通过分析数据中项集之间的关联性,来揭示不同项集之间的相关性和依赖关系。
论文作者提出,如果有恰当的数据,矿物组合分析除了能够预测新矿产位置、矿物种类,还能够预测给定地点的矿物量。并且该模型不仅适用于地球,还适用于任何岩石行星体。
数据集
本研究数据集包含大型矿物演化数据库 (Mineral Evolution Database) 的 5,478 种矿物、 295,583 个矿物产地及 5,472 个矿物产地的年代信息 (associated age),这些信息包含了 810,907 个矿物-产地组合。由于数据规模维度较大,研究人员将其分为不同子集,并选择了其中的 3 个:
* 地理子集:研究人员选择了美国,该地矿物多样性高、地理覆盖范围广且记录齐全、地质环境广阔。该子集包含 2,622 种矿物种类、 93,419 个矿点和 8,139,004 条关联规则。
* 地球化学子集:研究人员选择了铀矿,通过分析一种或多种以 U 为基本元素的矿物种类来检查含铀的矿物相。该子集包含 5,439 种矿物、 11,729 个矿点和 60,589,982 条关联规则。
* 时间子集:研究人员选择了三个时间切片 (time slices),分别为太古代 (> 2.5 Ga) 、元古代 (2.5 – 0.54 Ga) 和新生代 (< 0.54 Ga) 。
模型开发
基于上述数据集,研究人员开始进行模型开发以及效果验证,整个过程分为 3 步:
1. 矿物关联规则生成
研究人员采用了关联分析中常见的 Apriori 算法。该算法采用自下而上的方式,通过测试和比较频繁共现 (cooccurrence) 的项目集(如矿物组合),来生成关联规则,这些规则可以用于矿物关联分析。
2. 矿物关联规则可能性度量
研究人员设置了可能性指标来筛选出符合要求的关联规则。可能性指标是指对矿物之间关联关系进行量化和评估的指标,常见的可能性指标包括支持度 (Support) 、置信度 (Confidence) 和提升度 (Lift) 等。
支持度是指在所有样本中同时包含两种或多种矿物的比例。支持度越高,表示这些矿物之间的关联关系越强。

图 2:支持度计算公式
置信度是指当一个矿物出现时,另一个矿物也出现的概率。置信度高表示两种矿物质之间存在较强的关联性。

图 3:置信度计算公式
提升度是指两种矿物质同时出现的概率与它们各自独立出现的概率之比。提升度大于 1 表示两种矿物质之间存在正向关联,小于 1 表示存在负向关联,等于 1 表示两者之间没有关联性。

图 4:提升度计算公式
3. 矿物关联规则预测矿物
在本研究中,研究人员通过挖掘和分析已有的矿物数据,为上述 3 个数据子集(地理、地球化学和时间)都生成了关联规则。他们将待预测地点的矿物出现情况与关联规则作分析比较,可预测任意地点的矿物种类、矿物组合和成矿环境等等。
实验结果
实验选择在美国加利福尼亚州的特科帕盆地进行结果验证,因为这里含有火山灰和钙华沉积物,而且附近有玄武岩熔岩流,可模拟火星环境。研究人员预测了将会出现在该地的矿物种类,如下表所示:
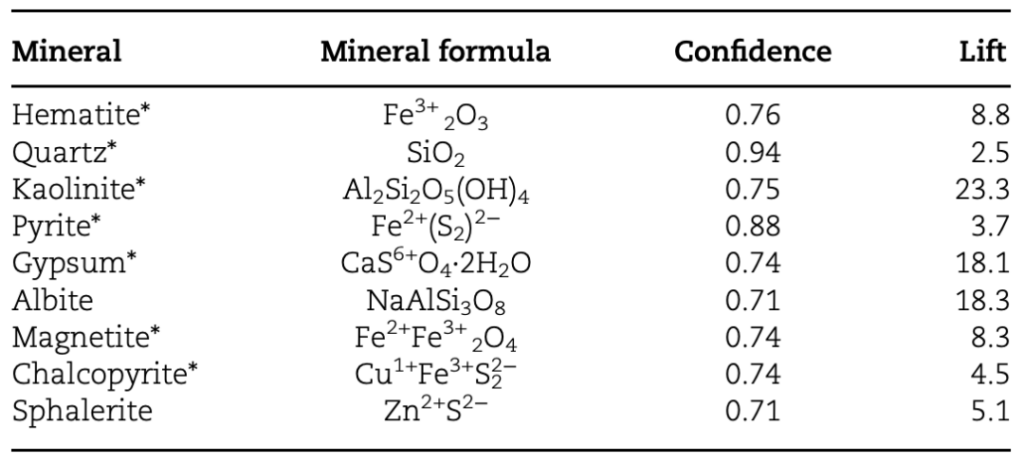
表 1:预测将会出现在特科帕盆地的矿物种类
表中显示了预测所依据的关联规则的相关置信度和提升度指标。
研究人员还预测了铀矿和其他几种关键矿物可能会出现的位置,并将预测结果在地图中作了标记。铀矿预测位置结果如下图所示。其中,2020 年 10 月至今,一些预测已得到证实,佐证了矿物关联分析的预测能力。

图 5:预测铀矿地理位置图
其他几种关键矿物预测位置结果如下图所示。

图 6:预测其他几种关键矿物地理位置图
截止 2021 年 10 月,经过证实的地点均标有 Mindat 徽标。 Mindat 是全球矿物数据库网站,当一个矿物在某地被发现时,会发表在该网站。
除此之外,为了进一步了解地球历史上矿物出现的变化,研究人员还研究了选定时间段内矿物关联规则,具体包括太古代 (>2.5 Ga) 、元古代 (2.5-0.54 Ga) 和新生代 (<0.54 Ga) 。 3 个时间段里矿物组合提升度如下图所示。
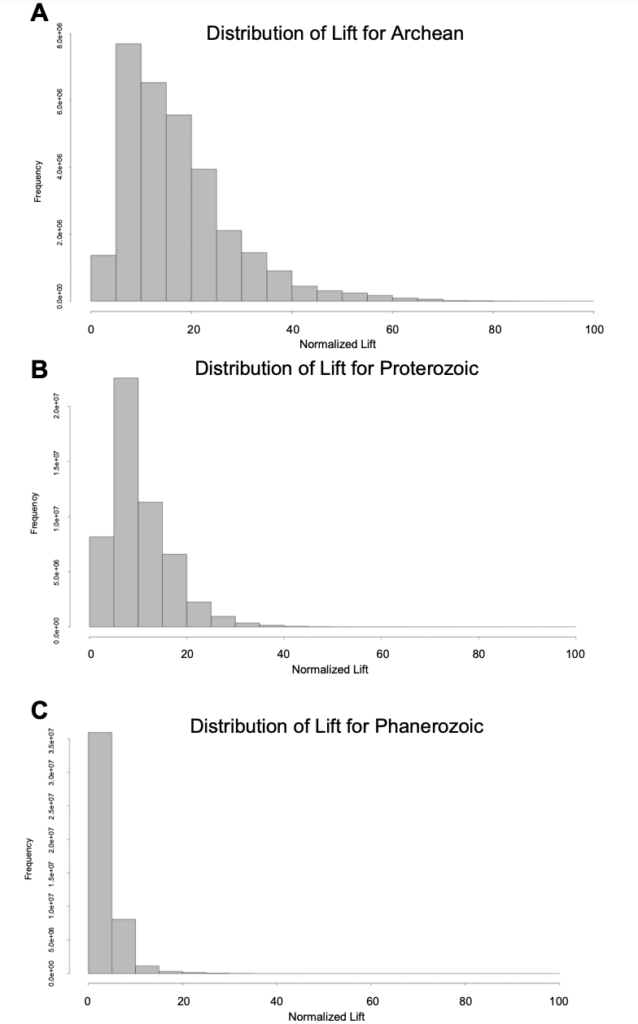
图 7:太古代 (a) 、元古代 (b) 、新生代 (c) 矿物组合提升度
提升度代表矿物组合之间的关联强度,可以看到在太古代、元古代和新生代中,矿物组合分布存在明显差异。此规律可用在未来的研究中,进一步探索环境、气候等多种因素对矿物组合的影响。
综合以上,矿物关联分析可应用于预测新的矿物种类及目标矿物位置等。
关联分析:信息挖掘领域最活跃方法之一
关联分析又称关联挖掘,是数据信息挖掘领域最活跃的研究方法之一,最早在 1993 年被提出。本论文作者在讨论部分提出,关联分析应用不应局限于矿物组合,还可以进一步应用在分析共生化石、微生物、分子和地质环境等其他属性。这是因为这一方法具有可扩展性和可转移性,能适用于众多领域,发挥重要意义。
除了本论文中讨论的关联分析在矿物勘探方向的应用,其在人类和动植物遗传学研究上的进展同样值得关注。目前,该领域的研究者已提出了一系列基于关联分析的新方法与软件。例如,较早开放使用的 PLINK 软件,可用于数据管理、群体结构评价、复杂性状和 case – control 数据的关联分析,也可处理基因型和表型大数据;浙江大学朱军教授实验室开发的 QTXNetwork 则是基于 GPU 计算的、可以处理大规模复杂性状组学数据的关联分析软件包。
随着数据量持续增多、计算机科学技术和统计学算法的不断更新,关联分析在各领域应用会进一步发展,新的高效、快速和海量标记的关联分析技术平台也会涌现。在此背景下,团队及个人选择工具时,需要根据业务实际需求进行评估对比。
参考链接:
[1]https://www.doc88.com/p-9788189626622.html?
[2]https://zwxb.chinacrops.org/article/2016/0496-3490-42-7-945.html
本文首发自 HyperAI 超神经微信公众平台~








