Command Palette
Search for a command to run...
冯思远:Apache TVM 与机器学习编译发展

本文首发自 HyperAI 超神经微信公众号~
下午好,欢迎大家今天来参加 2023 Meet TVM 。作为 Apache TVM PMC,由我来给大家做关于 TVM 的发展以及 TVM 未来 Unity 框架的分享。
Apache TVM Evolution
首先为什么会有 MLC (Machine Learning Compilation)?随着 AI 模型的不断扩展,实际生产应用中会有涌现更多的需求,很多应用的第一层 AI Application(如图所示)是共用的,包括 ResNet 、 BERT 、 Stable Diffusion 等模型。

第二层 Scenario 就不一样了,开发者需要在不同的场景去部署这些模型,最开始是云计算、高性能计算,需要用 GPU 进行加速。随着 AI 领域的加速,最重要的任务就是把它带进千家万户,也就是 Personal PC 个人电脑、 Mobile 手机以及 Edge 设备。
然而不同的场景有不同的需求,包括降低成本、提升性能。像 Out of the Box 需要保证用户打开网页或者下载一个应用,可以立马使用,手机需要省电,Edge 需要在没有 OS 的硬件上运行起来,有些时候还需要在低功耗、低算力的芯片上把技术跑起来。这些就是大家在不同应用上遇到的困难,怎么解决?
MLC 领域对此是有共识的,即 Muli-Level IR Design 。核心有三层,第一层 Graph-Level IR,中间层 Tensor-Level IR 以及下一层 Hardware-Level IR 。这几层是必须的,因为模型是一个 Graph,中间层是 Tensor-Level IR,MLC 的核心就是优化 Tensor Computing 。底下这两层 Hardware-Level IR 和 Hardware 是相互绑定的,就是说 TVM 不会去涉及直接生成汇编指令这一层,因为中间会有一些更细的优化技巧,这一层交由厂商或者编译器去解决。

ML Compiler 在设计之初有一下目标:
- Dependency Minimization
第一点,最小化依赖部署。为什么现在 AI 应用没有真正落地,正是因为部署的门槛太高。运行过 ChatGPT 的人比 Stable Diffusion 多并不是因为 Stable Diffusion 不够厉害,而是因为 ChatGPT 提供了一个开箱可用的环境。在我看来,使用 Stable Diffusion,你需要先从 GitHub 上下载一个模型,然后开一个 GPU 服务器把它部署起来,但是 ChatGPT 则是开箱即用。开箱即用关键的一点就是最小化依赖,所有人、所有环境上都可以用。
- Various Hardware Support
第二点,能够支持不同硬件。多样化硬件部署在发展早期不是一个最重要的题,但随着国内外 AI 芯片的发展,它会变得越来越重要,尤其是国内目前的环境以及国内芯片公司的现状,需要我们对各个硬件都有一个很好的支持。
- Compilation Optimization
第三点,通用编译优化。通过上几层 IR 的编译可以优化性能,包括提升运行效率、减少内存的占用等。
现在大家大多将边编译边优化作为最重要的点,但对整个社区来说,前两点是关键的。因为这是从编译器角度来看的,并且这两点都是从零到一的突破,优化性能往往是锦上添花。
回到演讲主题,我将 TVM 的发展划分为四个阶段,仅代表个人观点。
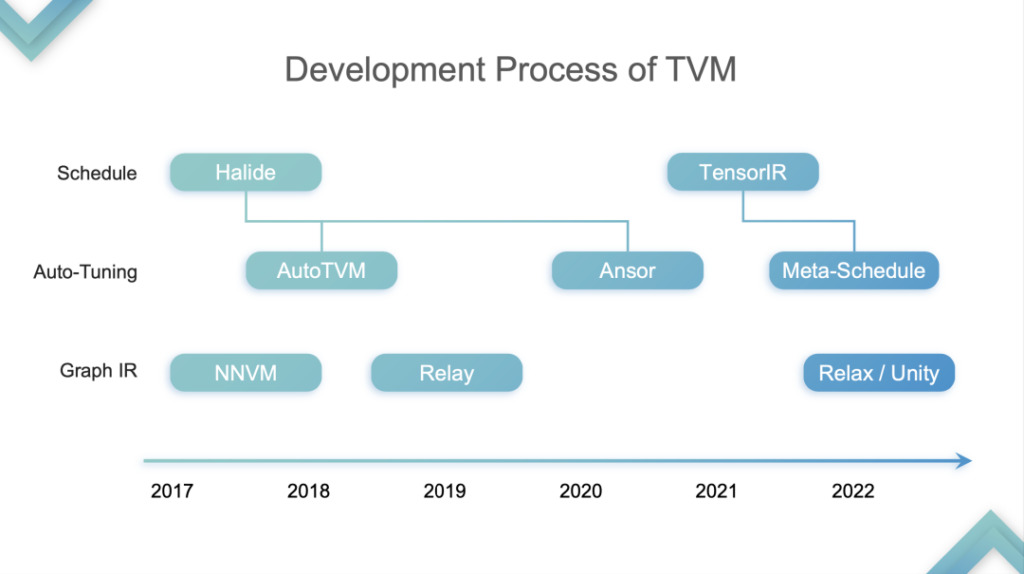
TensorIR Abstraction
Stage 1:在这个阶段,TVM 在 CPU 、 GPU 上做推理的优化及加速,GPU 特指 SIMT 的硬件部分。这个阶段很多云计算厂商因为发现在 CPU 和 GPU 上都能加速开始用 TVM 。为什么?我前面讲到 CPU 和 GPU 没有 Tensorization Support 。 TVM 初代 TE Schedule 基于 Halide,没有良好的 Tensorization Support ,所以 TVM 后续发展以 Halide 发展的技术路线,包括 Auto TVM 和 Ansor,都对 Tensorization 的支持不友好。
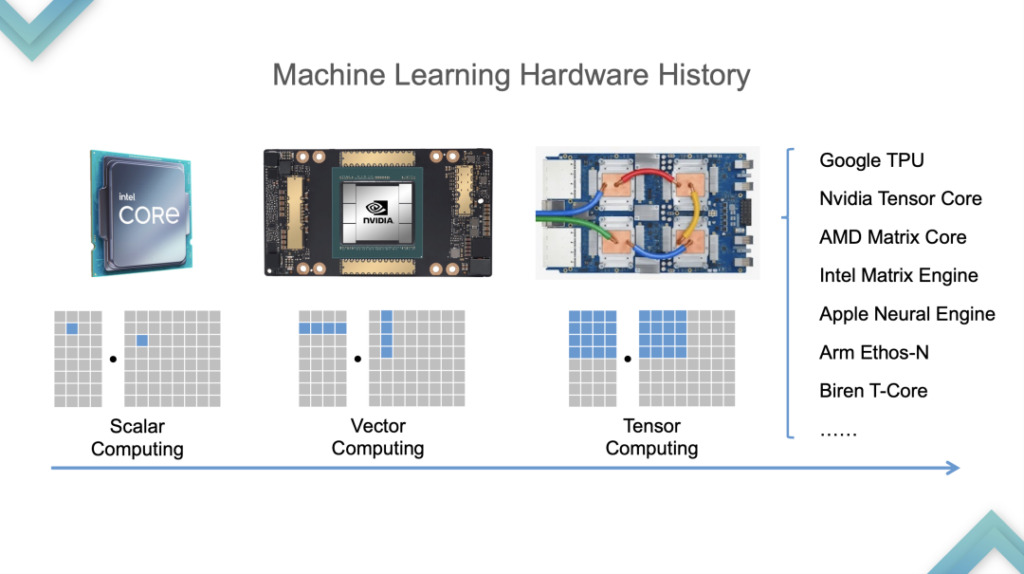
首先来看硬件发展过程,从 CPU 到 GPU 是 2015 、 2016 年左右,从 GPU 到 TPU 是 2019 年左右。为了做 Tensorization 支持,TVM 先分析了 Tensorized Programs 特征。
- Optimized loop nests with thread binding
第一,需要一个 loop testing,这是所有 Tensorized Program 必需的,底下有 Multi-dimensional data load,这和 CMT 、 CPU 不一样,它以张量而不是以标量为单位储存和计算的。
- Multi-dimensional data load/store into specialized memory buffer
第二,它储存在一个特殊 memory buffer 里。
- Opaque tensorized computation body 16×16 matrix multiplication
第三,会有一个硬件池允许计算。以下的 Tensor Primitive 为例子,计算 16* 16 的矩阵乘法,这个计算不再会表达成以标量组合的计算模式,而是会以一个指令去计算成账号单元。

依据以上三点 Tensorized Program 的定性分析,TVM 引入了 Computational Block 。 Block 是一个计算单元,其最外层有 nesting,中间有 iteration iterator 、 dependency relations,最底下是 body,其概念就是把内外层的计算分离,即 Isolate the internal computation tensorized computation 。
Stage 2:在这个阶段,TVM 做 Auto-Tensorrization 。具体如何实现的,这里一个例子详细展开。

Auto-Tensorization
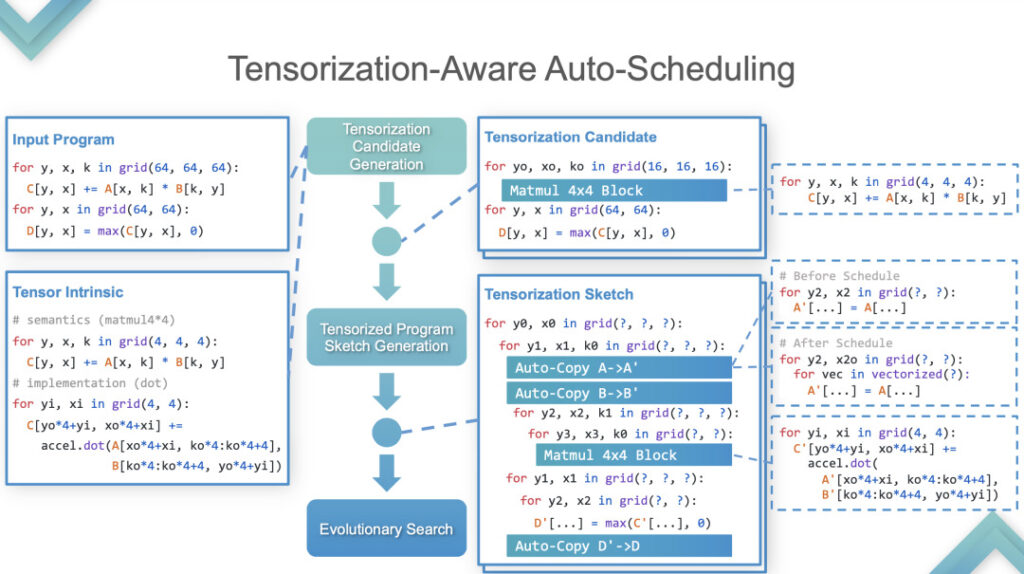
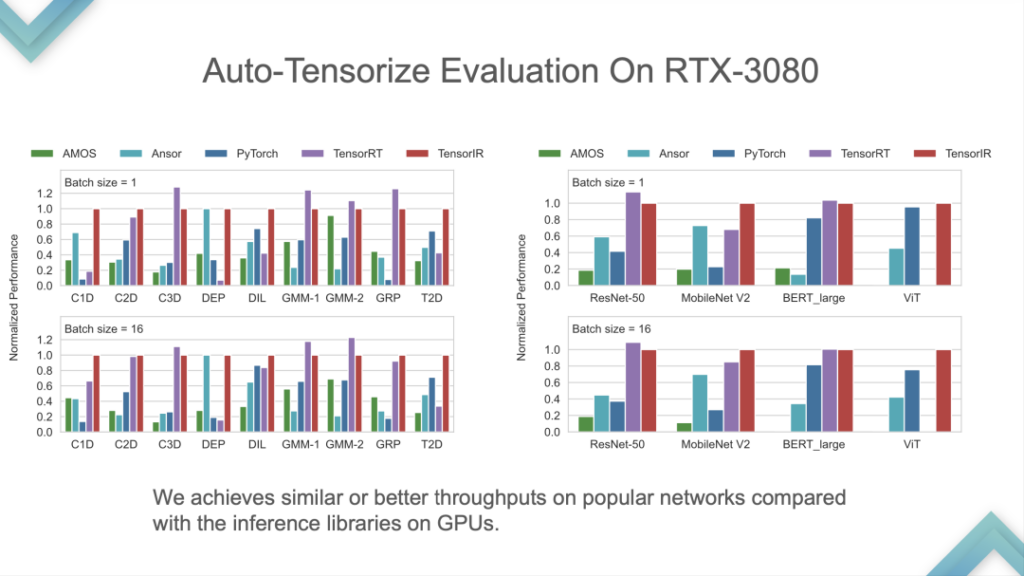
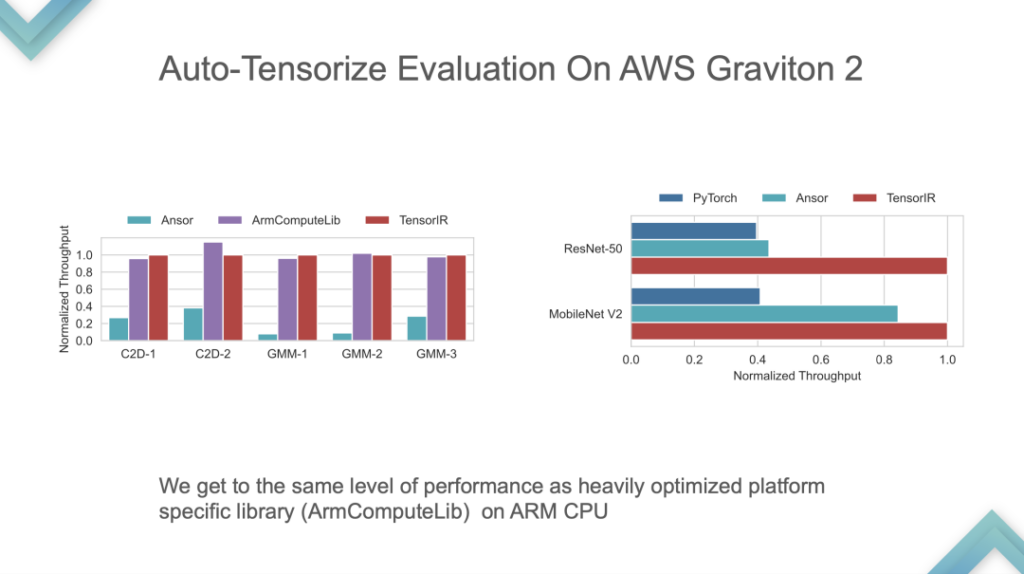
输入 Input Program 和 Tensor Intrinsic,结果表明:TensorIR 和 TensorRT 在 GPU 上基本上打平,而在一些标准模型性能并不是很好。因为标准模型是 ML Perf 的标准指标,NVIDIA 工程师会花很多时间去做。在标准模型上表现优于 TensorRT 是比较少见的,这也是相当于打赢了业界最先进的技术。
这是 ARM 自研 CPU 上的性能比较,TensorIR 和 ArmComputeLib 在 End-to-End 上可以比 Ansor 和 PyTorch 快约 2 倍。性能不是最关键的,Auto-Tensorization 思想才最为核心。
Stage 3:An End-to-End ML Compiler for Tensorized Hardware 。这个阶段可以将它扔到 GPU 或者已经支持的加速器芯片上,接下来有自动调优、模型导入,是一套自洽的系统。这个阶段 TVM 的核心是 End-to-End,可以开发一个直接使用的模型,但自定义难度很高。
接下来,关于 Relax 、 Unity 的发展和思考我会讲得慢一点,原因是:
- 个人认为 Relax 、 Unity 比较重要;
- 尚处于实验阶段,很多东西只有思想,缺少 End-to-End demo 及完整代码。
Apache TVM Stack 的局限性:
- Huge Gap between Relay and TIR 。 TVM 最大问题是 relay 到 TIR 的编译范式太陡峭;
- Fixed Pipeline for Most Hardware 。 TVM 标准的流程是 Relay 到 TIR 到?编译下去,实际上很多硬件要么只支持 BYOC,要么想通过 BYOC+TIR,Relay 支持的并不好,Either TIR or Library 。以 GPU 加速为例,给 Relay 底层是固定的东西,要么写 CUDA 做 Auto Tuning,要么给 TensorRT 走 BYOC,要不走 cuBLAS 调第三方库。虽然有诸多选择,但都是一个二选一的问题。这个问题影响比较大,而且在 Relay 上不好解决。
解决方案:TVM Unity 。
Apache TVM Unity
把 Relax 和 TIR 这两层 IR 当成一个整体,融合成了 Graph-TIR 编程范式。融合的形式:以最简单的 Linear 模型为例,这种情况下整个 lR 是可控可编程的,用 Graph-TIR 这一层的语言解决了 lower 过于陡峭的问题,高层算子可以逐步修改,甚至可以自行改成任何 BYOC 或 Function Calls 。

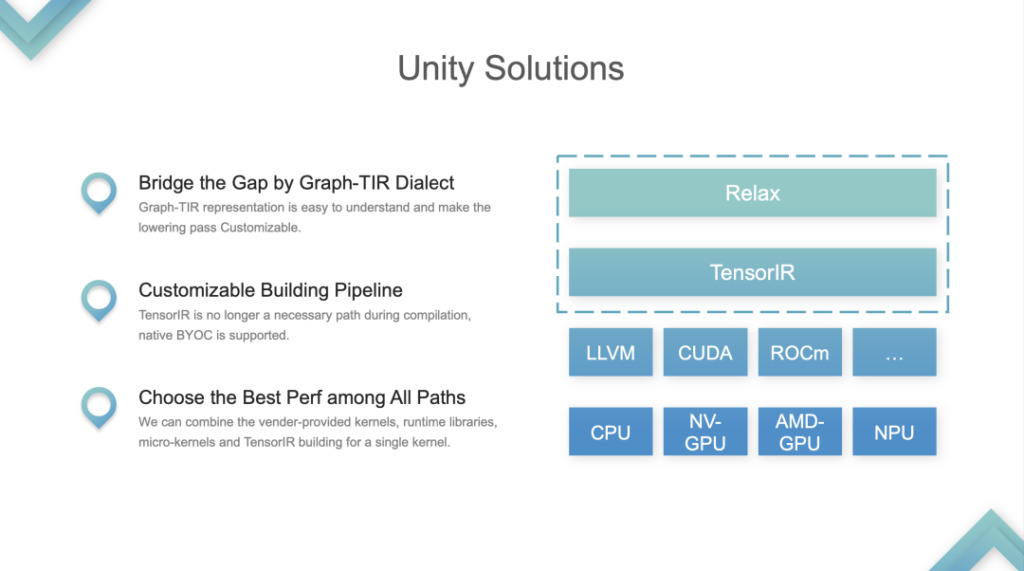
1. 支持自定义解决 building Pipeline 的问题。原本 TVM Pipeline 是 Relay 额外的 TIR,然后 TIR 做 Tuning,Tuning 完成后传递给 LLVM 或 CUDA,这是一套 fix 的 building Pipeline,现在 Pipeline 发生了改变,
2. Choose the Best Perf among All Paths 。开发者可以在 library 或 TIR 里做选择,调任意东西。这是 Unity 解决的最重要的问题,社区认为这是 unified ML compilation solution 。
Misunderstanding
- TVM 和 MLIR 是竞争关系
实际上,TVM 和 MLIR 没有明确的、同层次的竞争关系,TVM 专注于 MLC 机器学习编译,MLIR 强调 Multi-Level,也可以利用其特性来做 ML 编译。开发者使用 MLIR 做机器学习编译,一方面是因为 MLIR 与 PyTorch 等框架有原生对接,另一方面是因为在 Unity 之前, TVM 的定制化能力比较弱。
- TVM = Inference Engine for CPU/GPU
TVM 从来不是一个 inference engine,它能够做编译, 开发者可以用其来做推理加速。 TVM 是 compiler infrastructure,但不是 inference engine,「TVM 只能用来加速」这种想法是错误的。 TVM 之所以能用来加速,本质原因是 Compiler,比 PyTorch 等 Eager Mode 的执行方式要快。
- TVM = Auto Tuning
Relax 出现之前,大家对 TVM 的第一反应是,能够通过 Auto Tuning 获得更好的性能。 TVM 接下来的发展方向是淡化这个概念。 TVM 提供了各种途径以达到更好的性能、定制化整套编译流程。 TVM Unity 要做的就是提供一套架构,把各种优势组合起来。
Next Step
下一步 TVM 要做 Cross-Layer Machine Learning Compiler Infrastructure 以及致力于成为 customizable Building Pipeline for Different Backends,在不同的硬件上支持可定制化,这一点需要结合各种方式、集各家所长。
Q & A
Q 1:TVM 有没有计划优化大模型?
A 1:在大模型方面,我们有一些初步的想法。目前 TVM 已经开始做分布式推理以及一些简单训练,但距离真正落地还需要一段时间。
Q 2:Relax 后续在 Dynamic Shape 方面会有哪些支持和演进?
A 2:Relay vm 支持 Dynamic shape,但没有生成 Symbolic Deduction,例如 nmk 的矩阵乘法其输出是 n 和 m,但在 Relay 的表达方式是 3 个 nmk 统称为 Any,即未知 dimension,其输出也是未知 dimension 。 Relay VM 能运行这些 tasks,但是在编译阶段会丢失一些信息,所以 Relax 解决了这些问题,这就是 Relax 针对 Relay 在 Dynamic Shape 上的改进。
Q 3:TVM 的优化和 Device 的优化的结合问题。用 Graph 直接生成指令 的话,Device 的优化中 TE 、 TIR 好像不太用到。用 BYOC 的话,好像也是跳过 TE 、 TIR 。分享中提到 Relax 可能会有一些定制化,好像可以解决这一问题。
A 3:实际上已经有很多硬件厂商走通了 TIR 这条路,还有一些厂商没有关注相关的技术,选择的还是 BYOC 方法。 BYOC 不是严格意义上的 Compilation,在 Building Pattern 上是有限制的。综合来说,不是企业用不上社区技术,而是依据自身情况做出了不一样的选择。
Q 4:TVM Unity 的出现是否会涉及到较高的迁移成本?从 TVM PMC 的角度来看,如何帮助用户顺畅过渡到 TVM Unity?
A 4:TVM 社区并没有放弃 Relay,只是新增了 Relax 这个选项,因此老版本会持续演进,但是为了使用一些新功能,可能需要做一些代码及版本的迁移。
在 Relax 完整发布后,社区会提供的迁移教程和一定的工具支持,支持 Relay 模型直接导入到 Relax 。但是,基于 Relay 开发的定制版本迁移到 Relax,还是需要一定的工作量,这种工作量对于公司十几人的团队,大概需要一个月。
Q 5:TensorIR 在 Tensor 这块相比之前有很大的进展,但我注意到 TensorIR 主要还是针对编程模型如 SIMT 、 SIMD 这些成熟的编程方式做的,TensorIR 在现在很多的新的 AI 芯片、编程模型这里有没有一些进展?
A 5:从社区角度来说,TensorIR 之所以做 SIMT 模型,是因为现在只能利用到 SIMT 硬件,很多厂商的硬件和指令集都不开源,能够接触到大厂的硬件基本只有 CPU 、 GPU 和部分手机 SoC,其他的厂商社区基本接触不到,所以不能根据它们的编程模型做。此外,即使社区和企业合作做出来了类似层级的 TIR ,也无法开源,这是出于商业运营的考量。
以上为冯思远在 2023 Meet TVM 上海站的演讲整理内容。接下来,本次活动其他嘉宾分享的详细内容也将陆续在本公众号中发布推出,欢迎持续关注!
获取 PPT:关注微信公众号「HyperAI 超神经」,后台回复关键字 TVM 上海,获取完整 PPT 。
TVM 中文文档:https://tvm.hyper.ai/
GitHub 地址:https://github.com/apache/tvm








