Command Palette
Search for a command to run...
绝!OpenAI 年底上新,单卡 1 分钟生成 3D 点云,text-to 3D 告别高算力消耗时代
内容一览:继 DALL-E 、 ChatGPT 之后,OpenAI 再发力,于近日发布 Point·E,可以依据文本提示直接生成 3D 点云。 关键词:OpenAI 3D 点云 Point·E
OpenAI 年底冲业绩,半个多月前发布的 ChatGPT 广大网友还没玩明白,近日又悄么发布了另一利器– 可以依据文本提示,直接生成 3D 点云的 Point·E 。
text-to-3D:用对方法,一个顶俩
3D 建模想必大家都不陌生,近年来,在电影制作、视频游戏、工业设计、 VR 及 AR 等领域中,都可以看到 3D 建模的影子。
然而,借助人工智能创建逼真的 3D 图像,仍然是一个耗时耗力的过程,以 Google DreamFusion 为例,给定文本生成 3D 图像通常需要多个 GPU 、运行数小时。

通常意义上,文本到 3D 合成的方法分为两类:
方法 1:直接在成对的 (text, 3D) 数据或无标签的 3D 数据上训练生成模型。
此类方法虽然可以利用现有的生成模型方法,有效地生成样本,但由于缺乏大规模 3D 数据集,因此很难扩展到复杂的文本提示。
方法 2:利用预先训练好的 text-to-image 模型,优化可区分的 3D 表征。
此类方法通常能够处理复杂多样的文本提示,但每个样本的优化过程都代价高昂。此外,由于缺乏强大的 3D prior,此类方法可能会陷入 local minima(无法与有意义或连贯的 3D 目标一一对应)。
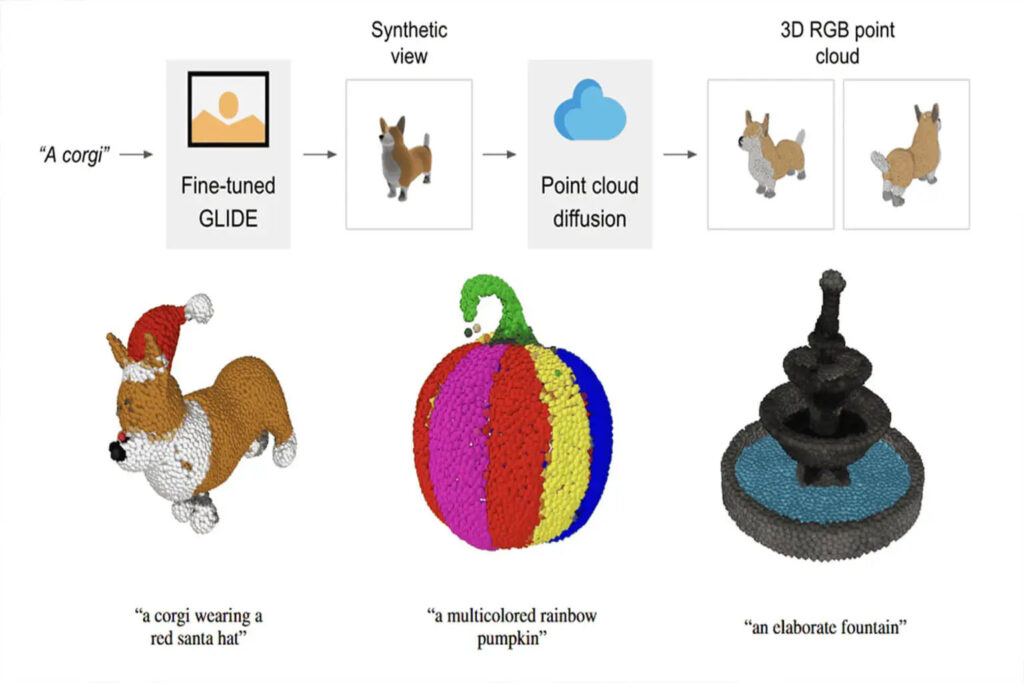
Point·E 结合了 text-to-image 模型以及 image-to-3D 模型,综合以上两种方法的优势,进一步提升了 3D 建模的效率,只需要一个 GPU 、一两分钟即可完成文本到 3D 点云的转换。
原理解析:3 步生成 3D 点云
Point·E 中,text-to-image 模型利用了大型语料库(text, image pair),使其对复杂的文本提示也能处理得当;image-to-3D 模型则是在一个较小的数据集 (image, 3D pair) 上训练的。
用 Point·E 依据文本提示生成 3D 点云的过程分为三个步骤:
1 、依据文本提示,生成一个合成视图 (synthetic view)
2 、依据合成视图,生成 coarse point cloud (1024 point)
3 、基于低分辨率点云和合成视图,生成 fine point cloud (4096 Point)

由于数据格式和数据质量对训练结果影响巨大,Point·E 借助 Blender,将所有训练数据都转换为了通用格式。
Blender 支持多种 3D 格式,并配有优化的渲染 engine 。 Blender 脚本将模型统一为一个 bounding cube,配置一个标准的 lighting 设置,最后使用 Blender 内置的实时渲染 engine 导出 RGBAD 图像。
"""
Script to run within Blender to render a 3D model as RGBAD images.
Example usage
blender -b -P blender_script.py -- \
--input_path ../../examples/example_data/corgi.ply \
--output_path render_out
Pass `--camera_pose z-circular-elevated` for the rendering used to compute
CLIP R-Precision results.
The output directory will include metadata json files for each rendered view,
as well as a global metadata file for the render. Each image will be saved as
a collection of 16-bit PNG files for each channel (rgbad), as well as a full
grayscale render of the view.
"""
Blender 脚本部分代码
通过运行脚本,将 3D 模型统一渲染为 RGBAD 图像
完整脚本详见:
过往 text-to-3D AI 横向对比
近两年来,涌现了众多关于 text-to-3D 模型生成的相关探索,Google 、 NVIDIA 等大厂也纷纷推出了自己的 AI 。
我们收集汇总了 3 个 text-to-3D 合成的 AI,供大家横向对比差异。
DreamFields
发布机构:Google
发布时间:2021 年 12 月
项目地址:https://ajayj.com/dreamfields
DreamFields 结合了神经渲染 (neural rendering) 与多模态图像及文本表征,仅依据文本描述,就可以可以在没有 3D 监督的情况下,生成各种各样 3D 物体的形状和颜色。

DreamFields 生成 3D 物体的过程中,借鉴了在大型文本图像数据集上预训练过的 image-text model,并对源自多视角的 Neural Radiance Field 进行了优化,这使得预训练 CLIP 模型渲染的图像,在目标文本下取得了良好的效果。
DreamFusion
发布机构:Google
发布时间:2022 年 9 月
项目地址:https://dreamfusion3d.github.io/
DreamFusion 可以借助预训练 2D text-to-image diffusion model,实现 text-to-3D synthesis 。
DreamFusion 引入了一个基于概率分布蒸馏 (probability density distillation) 的 loss,使 2D diffusion model 能够作为参数图像生成器 (parametric image generator) 优化的 prior 。

通过在与 DeepDream 类似的程序中应用该 loss,Dreamfusion 优化了一个随机初始化的 3D 模型(一个 Neural Radiance Field 或者 NeRF),通过梯度下降法使其从随机角度的 2D 渲染达到一个相对较低的 loss 。
Dreamfusion 不需要 3D 训练数据,也无需修改 image diffusion model,证明了预训练 image diffusion model 作为 prior 的有效性。
Magic3D
发布机构:NVIDIA
发布时间:2022 年 11 月
项目地址:deepimagination.cc/Magic3D/
Magic3D 是一个 text-to-3D 内容的创建工具,可用于创建高质量的 3D mesh model 。利用 image conditioning 技术以及基于文本提示的编辑方法,Magic3D 提供了控制 3D 合成的新方法,为各种创意应用开辟了新的途径。
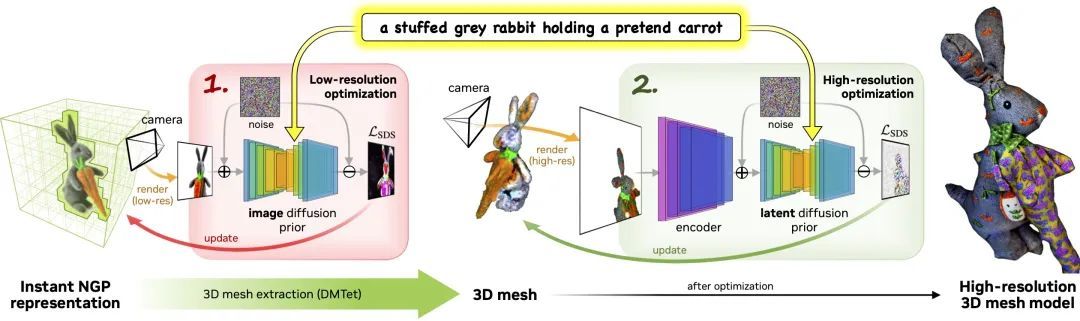
过程包括两个阶段:
阶段 1:使用低分辨率的 diffusion prior 获得一个 coarse model,并用 hash grid 和 sparse acceleration structure 进行加速。
阶段 2:使用从粗略神经表征 (coarse neural representation) 初始化的 textured mesh model,通过高效的可微分渲染器与高分辨率的 latent diffusion 模型交互进行优化。
技术进步仍需突破局限
text-to 3D 的 AI 陆续面世,但基于文本生成 3D 合成尚处于早期发展阶段,业内还没有一套公认的 Benchmark,能用来更公正地评估相关任务。
Point·E 对于 fast text-to 3D 合成而言,具有重大意义,它极大提升了处理效率,降低了算力消耗。
但不可否认,Point·E 仍然具有一定的局限性,比如 pipeline 需要合成渲染,生成的 3D 点云分辨率较低,不足以捕捉细粒度的形状或纹理等。
关于 text-to 3D 合成的未来,你怎么看?未来的发展趋势又会怎样?欢迎评论区留言讨论。








