Command Palette
Search for a command to run...
عرض توضيحي عبر الإنترنت لتوليف الصوت GPT-SoVITS
1. الوصف الوظيفي
ملاحظة: التدريب بنقرة واحدة الذي قمت بإنشائه يدعم اللغة الصينية فقط حاليًا. إذا كنت تريد تدريب اللغة اليابانية أو الإنجليزية، فأنت بحاجة إلى تمكين واجهة المستخدم الويب.
الطريقة هي تغيير python run_all.py في كود التشغيل run.ipynb إلى python webui.py
2. فيديو تعليمي
https://www.bilibili.com/video/BV1WC411W79t
3. طريقة التشغيل
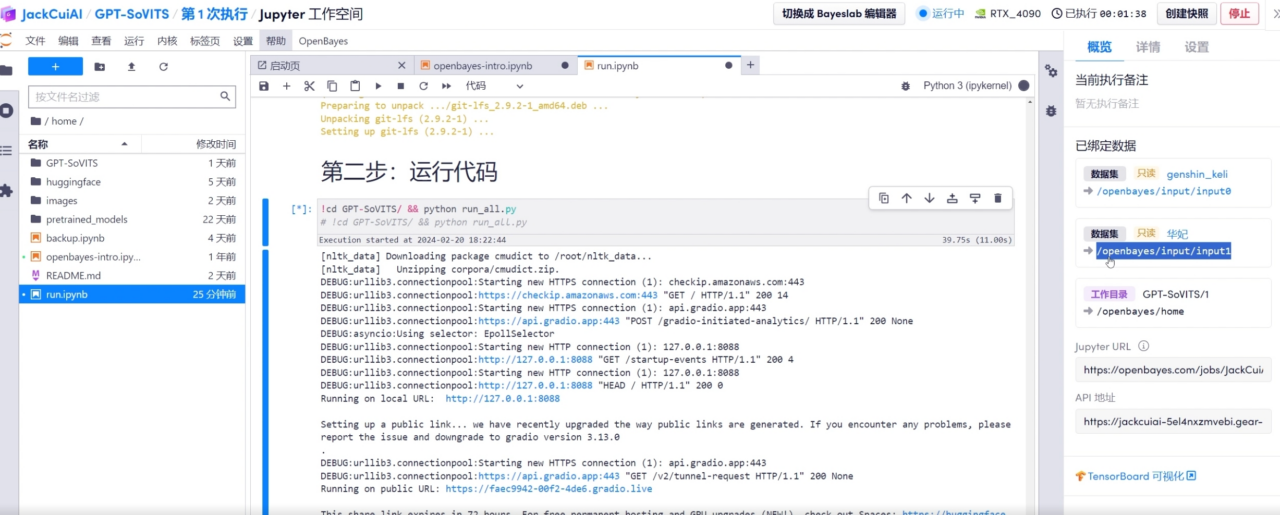
1. افتح run.ipynb
انقر فوق تشغيل -> تشغيل جميع الخلايا لبدء البرنامج وتكوين البيئة تلقائيًا وبدء الخدمة.

2. افتح عنوان URL العام للإخراج
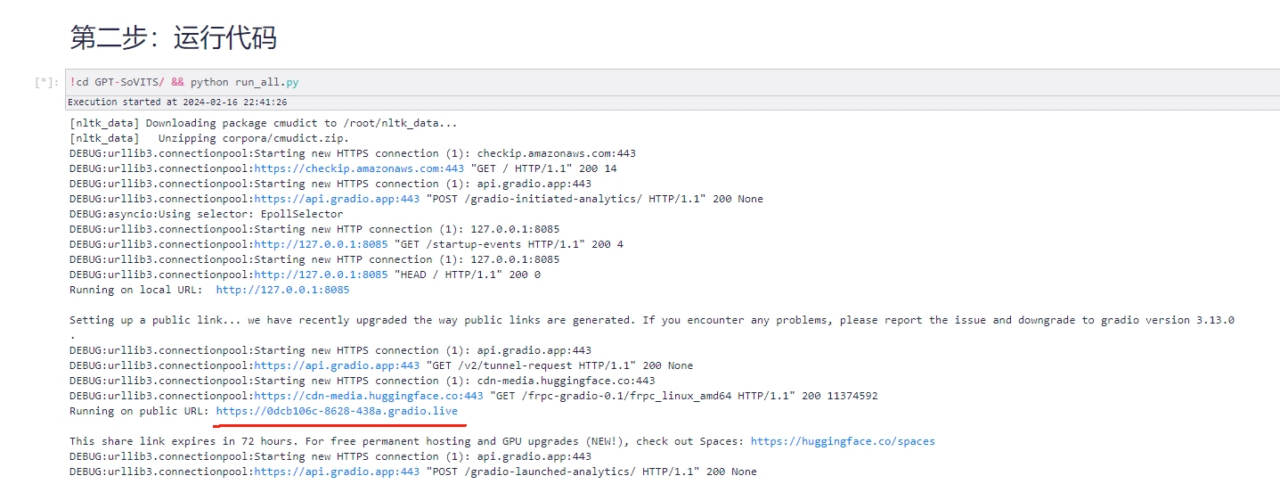
3. اختر نوع البيانات وفقًا للصوت الخاص بك

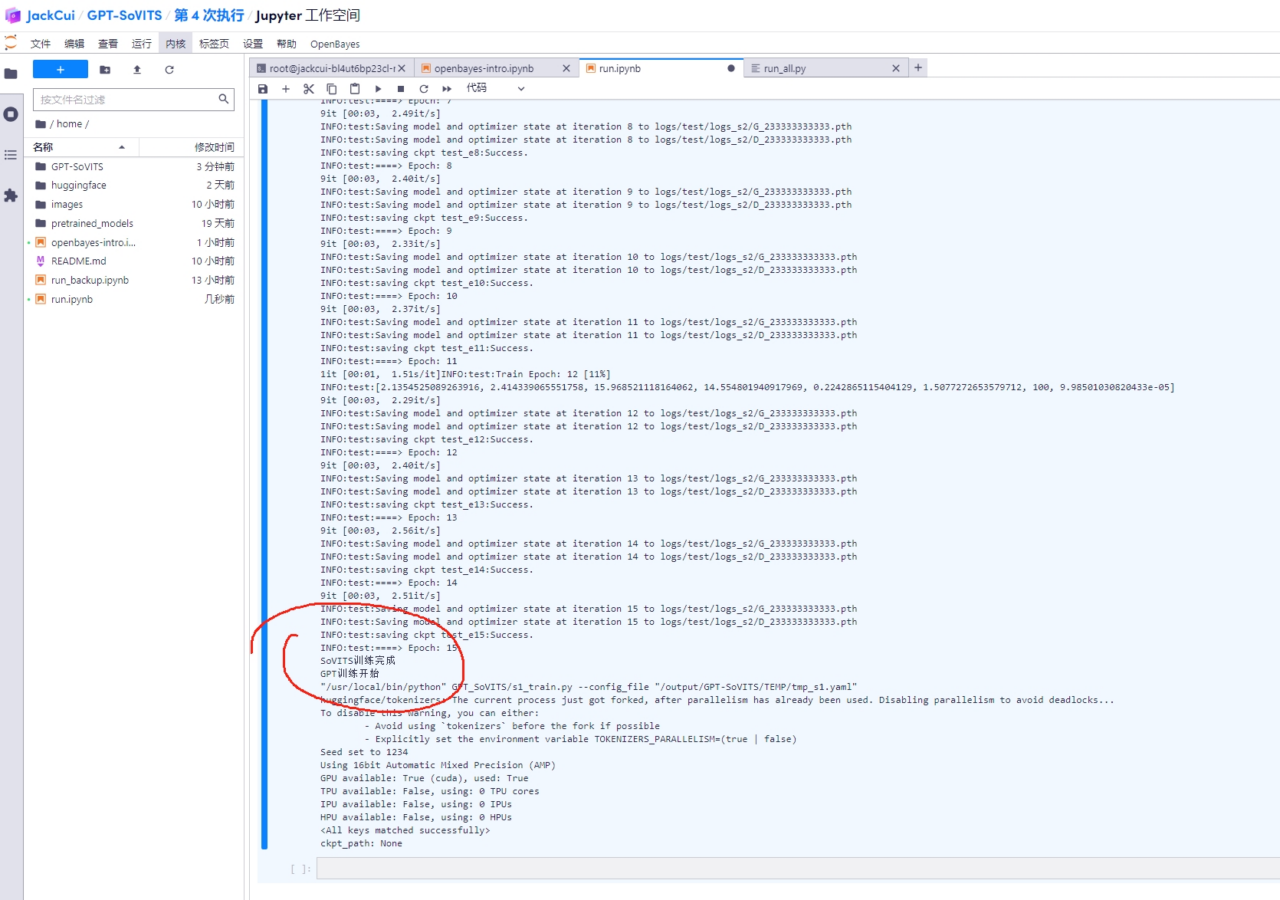
4. انقر لبدء التدريب
انقر هنا لمعرفة الخطوة التي وصلت إليها العملية في المقدمة، ويمكنك أيضًا رؤية إخراج السجل في الخلفية.

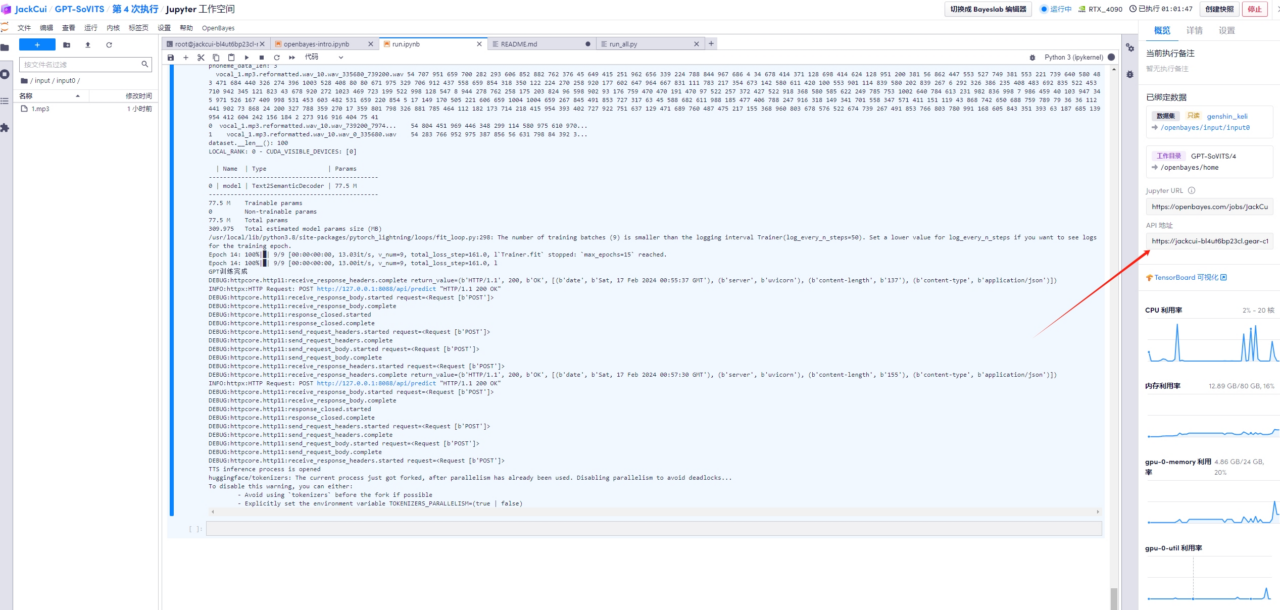
5. افتح عنوان API
عندما يظهر الواجهة الأمامية أن التنبؤ قيد التشغيل

عنوان API المفتوح:
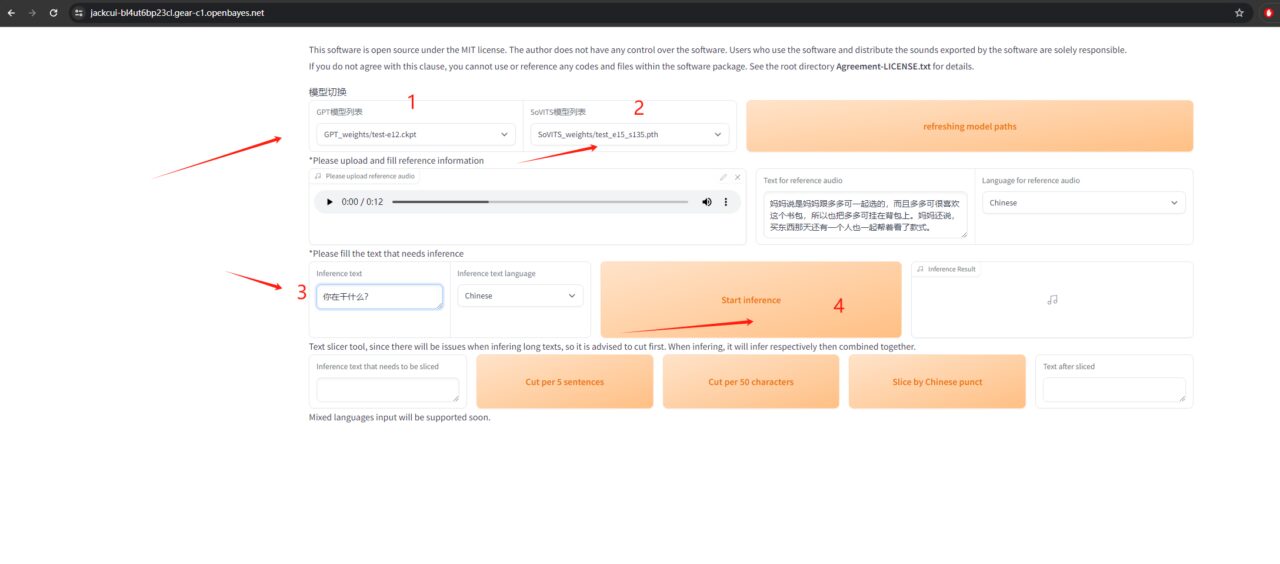
6. استنساخ الصوت
حدد النموذج المدرب، وأدخل النص الخاص بك، واستمتع.
4. الصوت المخصص
1. البحث عن مجموعات البيانات وإنشاء مجموعات بيانات جديدة
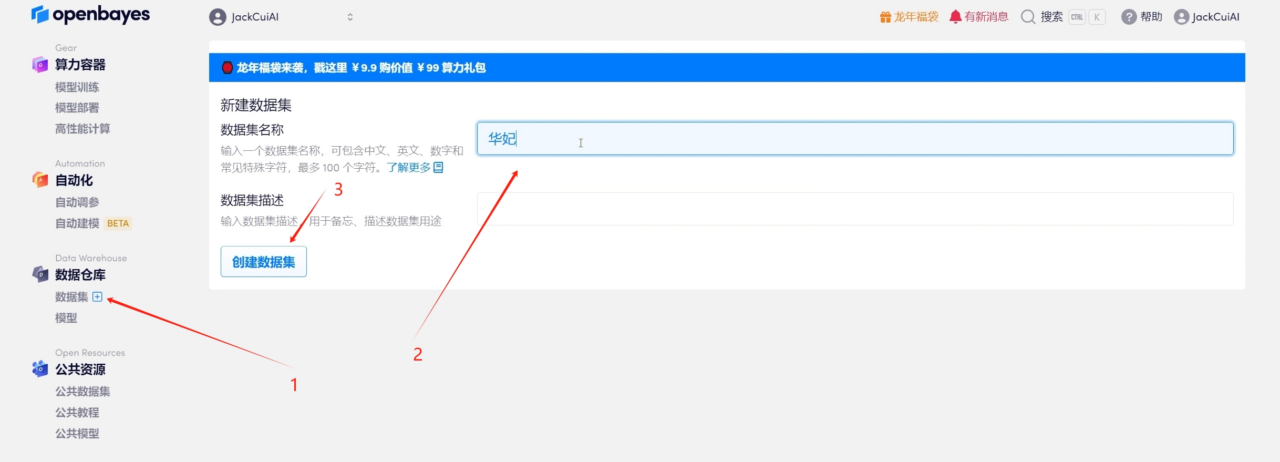
2. تحميل البيانات الصوتية
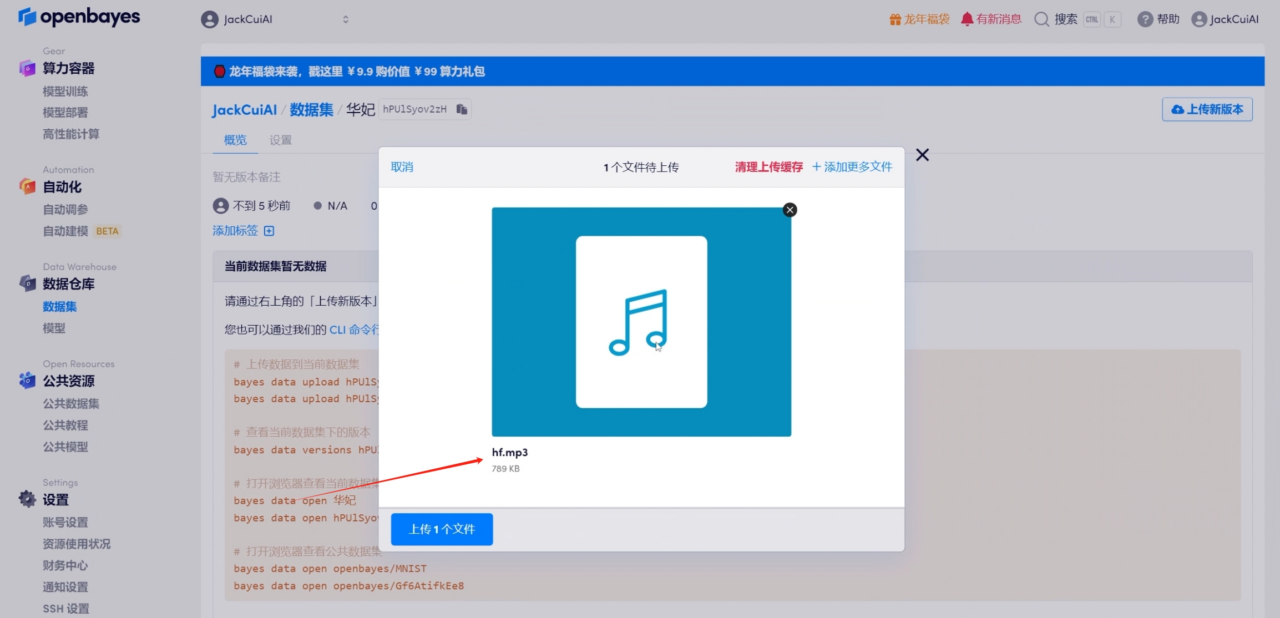
3. تعديل التكوين والبدء
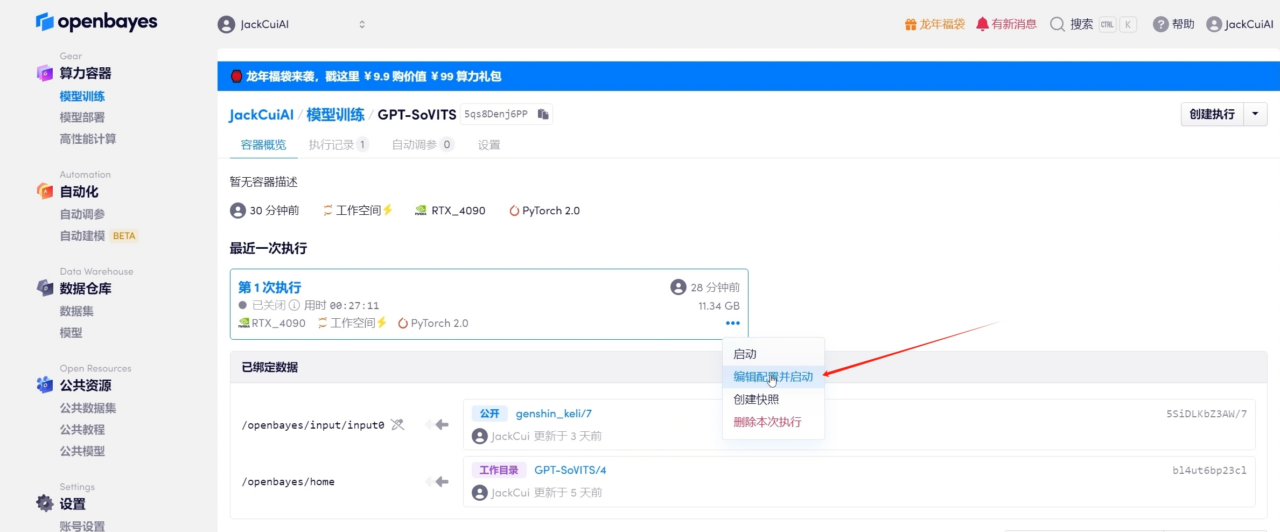
4. يتم ربط عنوان إدخال جديد
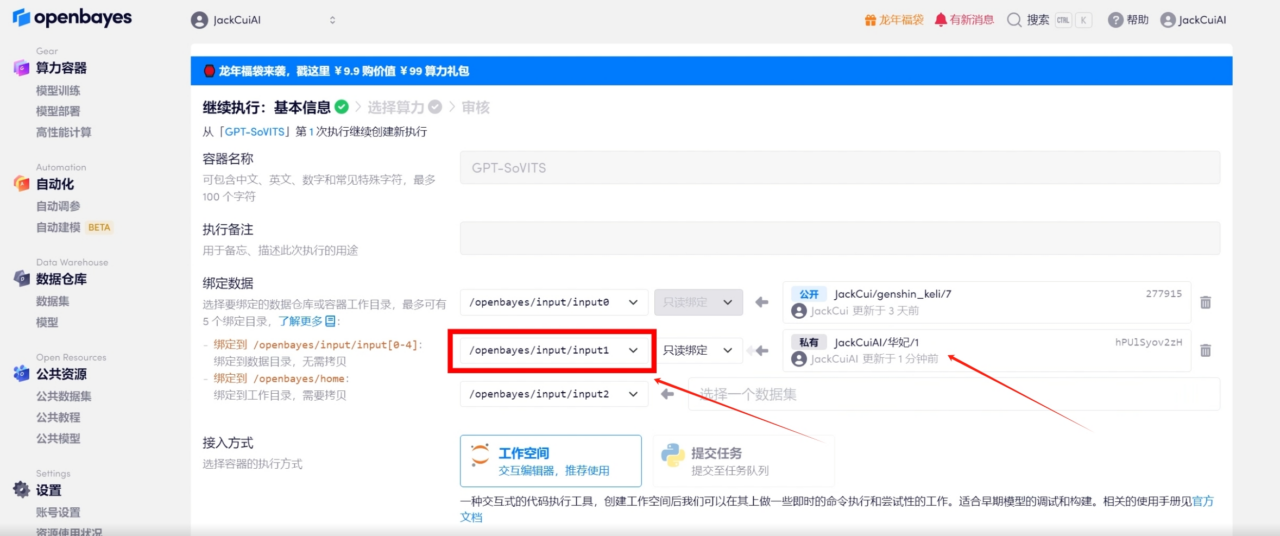
5. افتح مساحة العمل
بهذه الطريقة، يمكنك رؤية مجموعة البيانات المرتبطة حديثًا في الشريط الجانبي على اليمين.
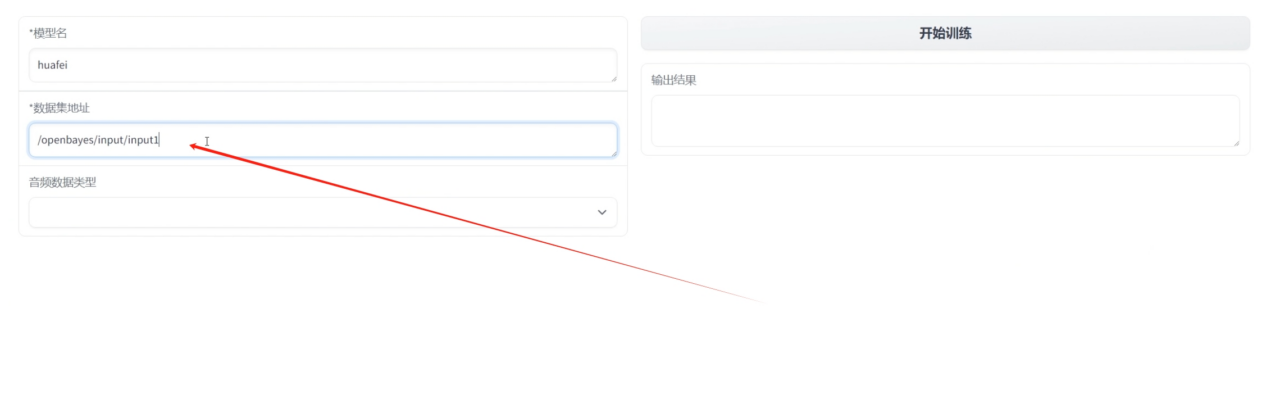
6. التدريب على ملء العنوان المرتبط حديثًا
بناء الذكاء الاصطناعي بالذكاء الاصطناعي
من الفكرة إلى الإطلاق — سرّع تطوير الذكاء الاصطناعي الخاص بك مع المساعدة البرمجية المجانية بالذكاء الاصطناعي، وبيئة جاهزة للاستخدام، وأفضل أسعار لوحدات معالجة الرسومات.