Command Palette
Search for a command to run...
الاكتشاف الوكيل للبنى العصبية: AIRA-Compose وAIRA-Design
الاكتشاف الوكيل للبنى العصبية: AIRA-Compose وAIRA-Design
Alberto Pepe Chien-Yu Lin Despoina Magka Bilge Acun Yannan Nellie Wu Anton Protopopov Carole-Jean Wu Yoram Bachrach
الملخص
بخطىً نحو التحسين الذاتي المتكرر (recursive self-improvement)، نبحث في قدرة وكلاء نماذج اللغات الكبيرة (LLM agents) على تصميم نماذج أساسية (foundation models) بشكل مستقل، تتجاوز النموذج القياسي القائم على المحولات (Transformer paradigm). ونقدم نهجاً ذو إطارين مزدوجين: AIRA-Compose للبحث في المعمارية عالية المستوى، وAIRA-Design للتنفيذ الميكانيكي منخفض المستوى.يُوظّف AIRA-Compose مجموعة تضم 11 وعيلاً للبحث في فضاء تصميم توافقي يجمع بين الجمل الحسابية الأساسية (Attention، وMLP، وMamba)، وذلك ضمن ميزانية حسابية ثابتة قدرها 24 ساعة. يعمل الوكيلان على مرحلتين؛ حيث يصممان ويقيّمان مرشحين على مقياس المليون معلمة بشكل تكراري، وبعد ذلك، يتم استقراء أفضل التصاميم إلى مقاييس 350 مليون، و1 مليار، و3 مليارات معلمة. أسفر هذا البحث عن 14 عمارة جديدة تنتمي إلى عائلتين: AIRAformers (قائمة على Transformer) وAIRAhybrids (قائمة على Transformer-Mamba).عند إجراء التدريب المسبق على مقياس 1 مليار معلمة ضمن ميزانية محددة من الـ tokens، تفوق أداء أفضل المعماريات المكتشفة بواسطة الوكيلين باستمرار على كلٍ من Llama 3.2 والبدائل التي وجدها Composer. وفي المهام اللاحقة (downstream tasks)، حسنت AIRAformer-D وAIRAhybrid-D من الدقة بنسبة 2.4% و3.8% على التوالي مقارنة بـ Llama 3.2. كما وجد AIRA-Compose معماريات نماذج جديدة تحقق حدود قياس أمثل للحوسبة (compute-optimal scaling frontiers) أكثر انحداراً وكفاءة. حيث تتسارع سرعة القياس في AIRAformer-C بنسبة 54% و71% أسرع من Llama 3.2 وأفضل معمارية Transformer اكتشفها Composer، بينما تتسارع سرعة القياس في AIRAhybrid-C بنسبة 23% و37% أسرع من Nemotron-2 المعدل وأفضل معمارية هجينة اكتشفها Composer على التوالي.وكّلف إطار AIRA-Design حتى 20 وعيلاً بكتابة آليات انتباه (attention mechanisms) جديدة بشكل مباشر للتعامل مع التبعيات طويلة المدى (long-range dependencies)، وتنفيذ نصوص تدريب عالية الأداء. وعند تقييمها على معيار Long Range Arena (LRA)، حققت أفضل المعماريات المصممة بواسطة الوكلاء دقة تقارب حالة الفن البشرية (human state-of-the-art) بنسبة 2.3% في مطابقة المستندات، و2.6% في تصنيف النصوص. وعلى معيار Autoresearch، قام Greedy Opus 4.5 بتحسين التدريب ضمن ميزانية زمنية ثابتة ليحقق قيمة 0.968 بت/بايت للتحقق (validation bits-per-byte)، متجاوزاً الحد الأدنى المرجعي المنشور.معاً، تُظهر كل من AIRA-Compose وAIRA-Design أن وكلاء البحث في الذكاء الاصطناعي قادرون على اكتشاف هجين للعماريات والتحسينات الخوارزمية التي تقارن أو تتفوق على الأساسيات المصممة يدوياً. وهذا يرسخ نموذجاً مرناً وقوفاً لاكتشاف الجيل القادم من النماذج الأساسية، ويمثل خطوة نحو التحسين الذاتي المتكرر.
One-sentence Summary
This work introduces AIRA-Compose and AIRA-Design, a dual-framework where LLM agents autonomously design foundation models beyond standard Transformers, with AIRA-Compose deploying 11 agents to generate AIRAformer and AIRAhybrid architectures that surpass Llama 3.2 by 2.4% and 3.8% in accuracy and scale up to 54% faster than Llama 3.2, while AIRA-Design employs up to 20 agents to implement novel mechanisms that reach within 2.6% of human state-of-the-art on the Long Range Arena benchmark and achieve 0.968 validation bits-per-byte on the Autoresearch benchmark, establishing a flexible paradigm for recursive self-improvement.
Key Contributions
- This work introduces a dual-framework approach comprising AIRA-Compose for high-level architecture search and AIRA-Design for low-level mechanistic implementation. The system deploys agent ensembles to navigate combinatorial design spaces of computational primitives under fixed compute budgets.
- Agent-discovered architectures consistently outperform Llama 3.2 and Composer-found alternatives when pre-trained at the 1B scale under a fixed token budget. Specific models improve downstream accuracy by up to 3.8% and scale significantly faster than standard baselines.
- The AIRA-Design component tasks agents with writing novel attention mechanisms and implementing high-performing training scripts for evaluation. On the Long Range Arena and Autoresearch benchmarks, these agent-designed systems achieve near state-of-the-art accuracy and surpass published minimum reference bits per byte respectively.
Introduction
Current foundation models predominantly rely on Transformer architectures, yet their quadratic complexity creates bottlenecks for long-context processing and inference efficiency. While the community is shifting toward hybrid models that combine diverse computational primitives, manual exploration cannot effectively navigate the vast combinatorial space and traditional search methods remain computationally prohibitive. The authors leverage a dual-framework approach comprising AIRA-Compose and AIRA-Design to enable LLM agents to autonomously discover and implement these next-generation architectures. Their system successfully identifies novel hybrid designs that outperform human-engineered baselines like Llama 3.2 while establishing more efficient compute-optimal scaling frontiers.
Dataset
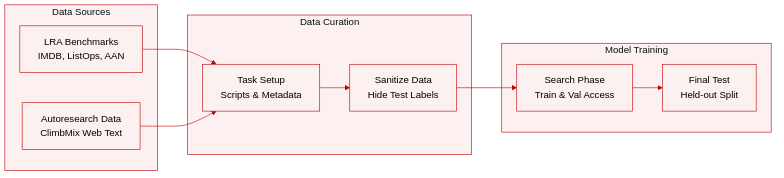
-
Dataset Composition and Sources
- The authors introduce 12 RSI tasks divided into AIRA-Compose and AIRA-Design categories, building on the AIRS-BENCH framework where tasks are defined by problem, dataset, and metric triplets.
- Two primary benchmarks drive the evaluation: Long Range Arena (LRA) for low-level mechanistic design and Autoresearch for optimizing training scripts.
-
Key Details for Each Subset
- LRA tasks employ three text-based datasets: IMDB for sentiment classification, ListOps for hierarchical math expressions, and the ACL Anthology Network for document retrieval.
- Autoresearch utilizes pre-tokenized web text from the ClimbMix corpus paired with a pre-trained BPE tokenizer containing approximately 8192 vocabulary items.
- A literature-enhanced version of Autoresearch includes structured summaries from 41 research papers and 14 reference code repositories organized by topic.
-
Model Usage and Training Splits
- Agents access training and validation splits during the search phase to evaluate hypotheses using greedy or one-shot scaffolds.
- Final performance is assessed on a held-out test split that remains inaccessible during the search process to ensure fairness.
- The Autoresearch metric is validation bits per byte calculated within a fixed 5-minute wall-clock training budget on a single GPU.
-
Processing and Metadata Construction
- Standardized task directories include preparation scripts for data sanitization and isolated scoring scripts that encapsulate full training pipelines.
- Metadata files define task constraints and evaluation metrics while ensuring test labels are hidden during solution construction.
- The literature variant organizes resources into Architecture Improvements, Training Strategies, and Optimizers within a dedicated pwc/ folder.
Method
The AIRA-Compose pipeline recasts the Composer framework into equivalent AIRS-Bench tasks to automate the discovery of hybrid foundation models. The process follows a four-step methodology: Search, Evaluation, Aggregation, and Extrapolation. Rather than relying on rigid Bayesian Optimization, the system employs agents to freely formulate structural hypotheses and propose novel primitive arrangements.
Refer to the framework diagram for the overall workflow where data, computational primitives, and codebases feed into the AIRS-Bench Task.

The search engine is driven by Large Language Models (LLMs) acting as agents within a harness that includes a scaffold for one-shot or greedy execution. Agents are tasked with assembling 16-layer small-scale architectures using predefined computational primitives such as MLPs (M), multi-head Attention (mA), and Mamba SSM (Mb). The search space for two-primitive configurations spans 216=65,536 possible arrangements, while three-primitive spaces expand to approximately 43 million combinations.
The authors leverage a greedy tree search approach where agents iteratively explore the architecture space. As shown in the figure below, the agent drafts initial solutions and refines them based on validation scores.
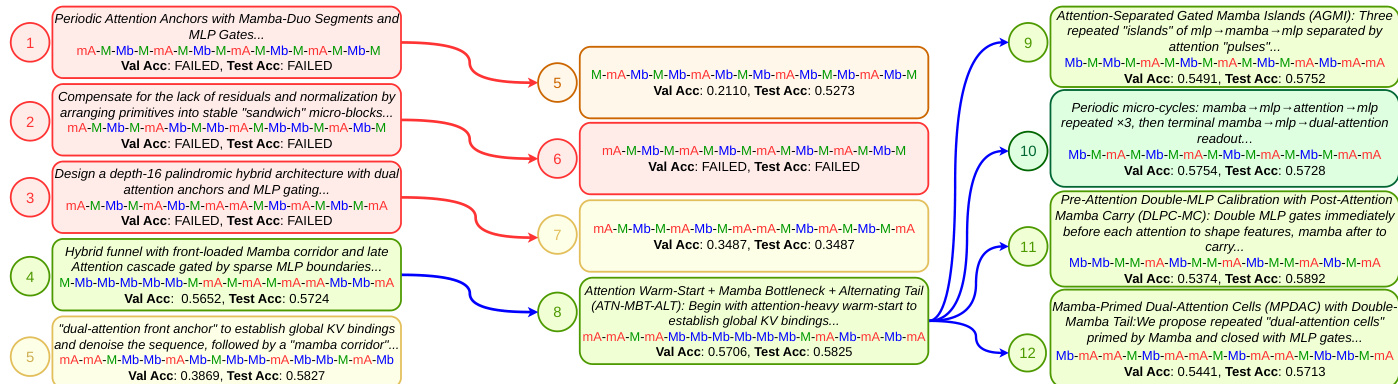
At each node of the search tree, the agent articulates design choices, produces a candidate architecture file, and writes an evaluation script. The submitted architecture is trained from scratch on proxy datasets including MAD, BabiStories, and DCLM. The node with the highest validation score is selected for further exploration via improve operations, allowing the agent to leverage domain knowledge to navigate the combinatorial space meaningfully. Red arrows in the diagram indicate debug operations, while blue arrows denote improve operations that propose new architectures informed by the parent's reasoning and score.
Once the agentic exploration concludes, the pipeline moves to aggregation and extrapolation. The Aggregator collects submitted architectures and their test scores across all agents. It employs layer-wise clustering techniques, such as k-means, to select the most frequent computational primitives within clusters. This process smooths out noise and overfitting from proxy training to obtain a robust small-scale architecture. Different aggregation strategies are applied, including N0, N1, and N2 aggregation, which weight architectures based on rank or cluster membership.
Finally, the Extrapolator scales the aggregated small-scale architecture to target parameter counts of 350M, 1B, or 3B. This scaling is achieved through stretching, which proportionally expands contiguous blocks, or stacking, which repeats the entire discovered architecture sequentially. At small scale, all primitives share a model dimension d=128, while large-scale configurations adjust the model dimension, number of attention heads, and hidden dimensions according to IsoFLOP methodologies. The resulting architectures utilize SwiGLU variants for MLPs and grouped-query attention for attention blocks to ensure efficiency at scale.
Experiment
This research evaluates AI agents on architecture search and training design tasks using one-shot and greedy scaffolds across benchmarks including MAD, Long Range Arena, and Autoresearch. Experiments in AIRA-Compose demonstrate that agents can discover novel neural architectures that outperform established baselines in validation loss and downstream performance, with balanced designs showing better compute efficiency. In AIRA-Design tasks, greedy agents achieved peak accuracy near leading human performance levels on mechanistic challenges and optimized training loops to surpass reference baselines, though they primarily recombined existing techniques rather than generating fundamental scientific innovations. Overall, the results indicate that agent-driven search is a viable approach for generating competitive foundation model components, highlighting strengths in engineering synthesis while identifying limitations in genuine algorithmic discovery.
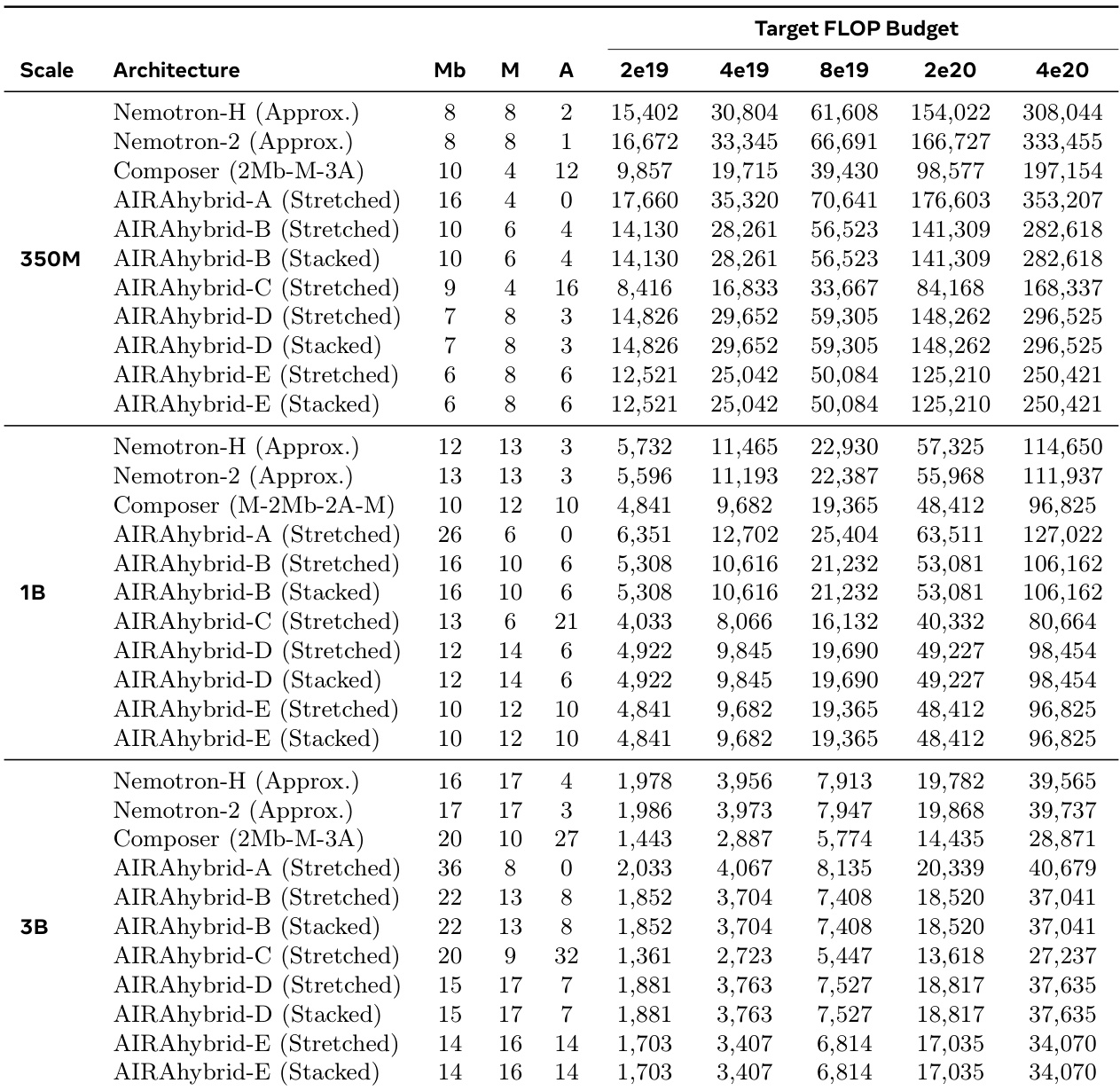
The the the table presents the number of training steps achievable for various hybrid architectures across three parameter scales under five distinct FLOP budgets. The data demonstrates that as model scale increases, the number of feasible training steps decreases for a fixed compute budget. Furthermore, architectural composition significantly impacts compute efficiency, where designs with higher attention layer counts result in fewer training steps compared to Mamba-heavy or balanced alternatives. Increasing model scale reduces the total number of training steps available under a fixed FLOP budget. Architectures with a higher proportion of attention layers allow for fewer training iterations than those dominated by Mamba or MLP layers. Stacked and Stretched variants of the same base architecture configuration yield identical training step counts across all tested budgets.
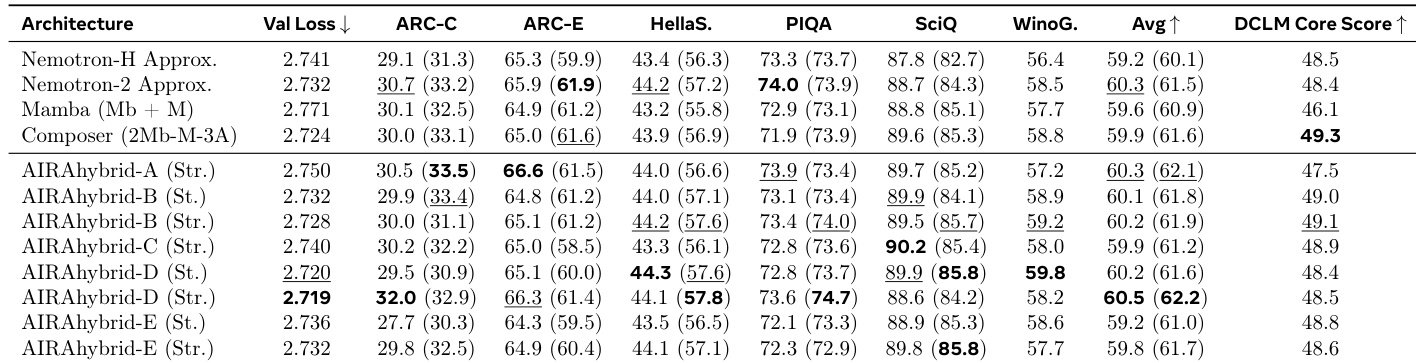
The authors evaluate 3-primitive hybrid architectures at a 1B parameter scale against established baselines including Mamba and Composer. The agent-discovered AIRAhybrid-D (Stretched) variant demonstrates the strongest overall performance, achieving the lowest validation loss and highest average accuracy across downstream tasks. While the Composer baseline secures the highest DCLM Core Score, the AIRAhybrid models generally outperform the Mamba and Nemotron baselines across linguistic and reasoning benchmarks. AIRAhybrid-D (Stretched) achieves the lowest validation loss and highest average 0-shot accuracy among all tested architectures. The Composer baseline secures the highest DCLM Core Score, outperforming the agent-discovered variants on this specific metric. AIRAhybrid models generally maintain superior average accuracy compared to baselines like Mamba and approximated Nemotron-2.
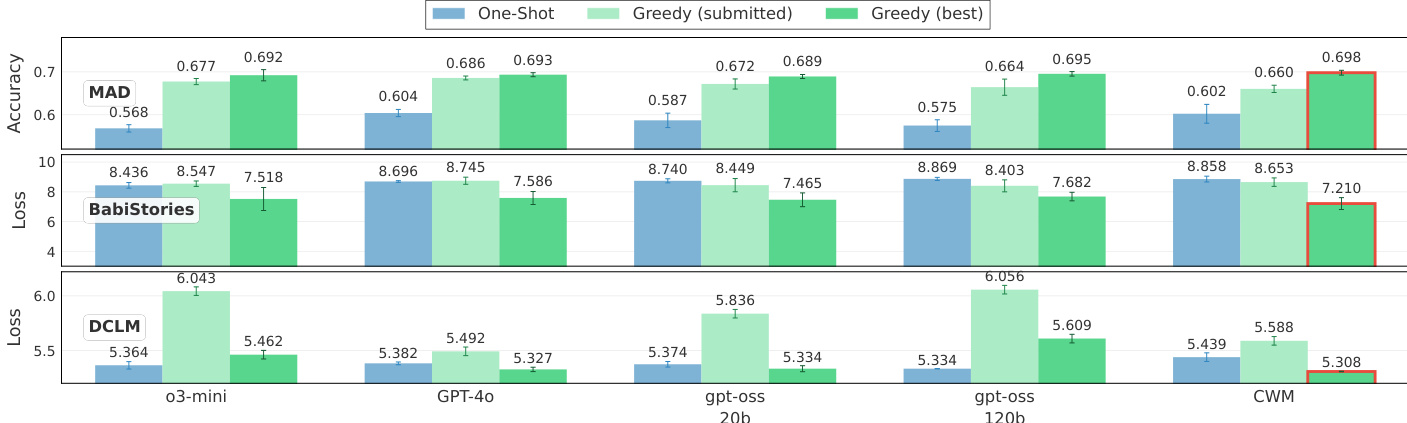
The authors evaluate LLM agents on a 2-primitive architecture search task using the MAD, BabiStories, and DCLM datasets. The results compare One-Shot generation against Greedy search, distinguishing between the final submitted solution and the best solution found during exploration. Across all datasets, Greedy search consistently outperforms One-Shot generation, and the best-found solutions generally surpass the submitted solutions in terms of accuracy or loss. Greedy search scaffolds consistently yield better performance than One-Shot generation across all three datasets. The best solutions discovered during the search process typically outperform the final solutions submitted by the agents. The CWM agent achieved the highest accuracy on the MAD dataset and lowest loss on BabiStories and DCLM among the evaluated models.
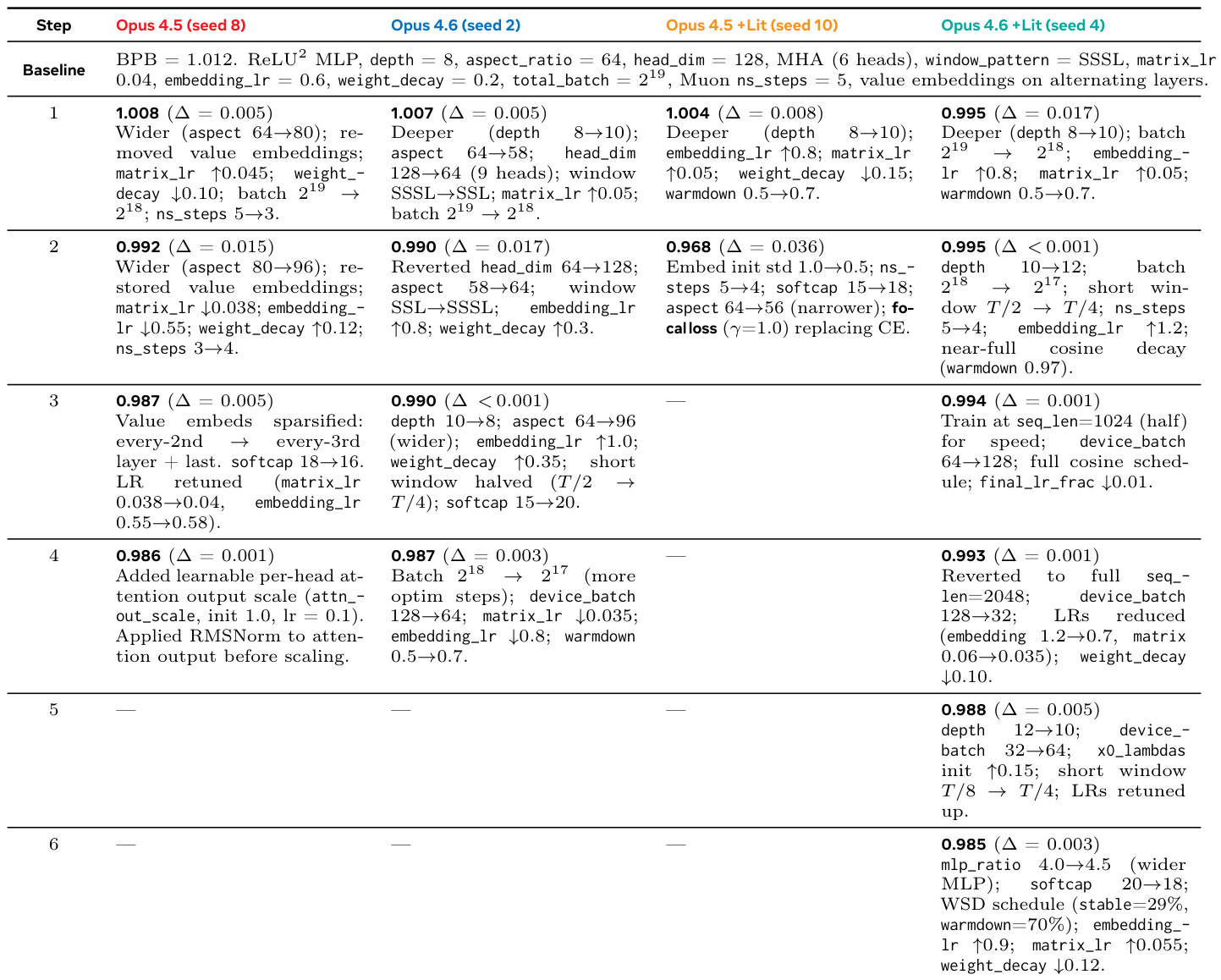
The the the table details the iterative optimization steps taken by different agent variants on the Autoresearch task, tracking improvements in validation loss relative to a baseline. The authors show that agents successfully reduce loss through a sequence of architectural changes and hyperparameter adjustments, with performance varying based on model capability and access to literature. The Opus 4.6 variant with literature access achieves the best final validation performance after multiple iterative steps of tuning depth, batch size, and learning rates. The literature-enhanced Opus 4.5 agent achieves the most significant single-step gain by introducing focal loss to replace the standard cross-entropy objective. Optimization strategies diverge between model families, with Opus 4.5 focusing on architectural widening and value embedding sparsification while Opus 4.6 emphasizes depth changes and increased optimizer steps.
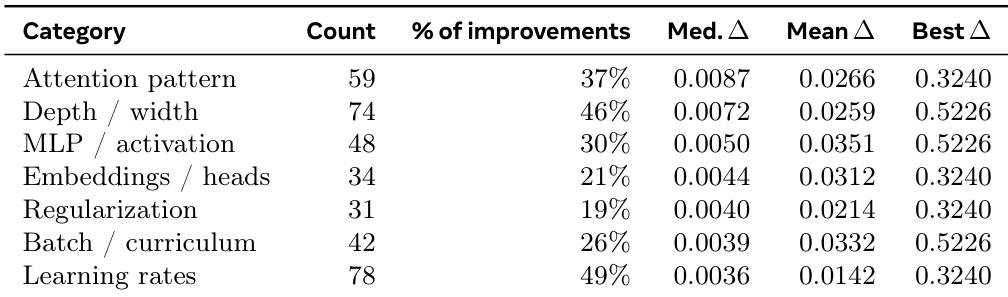
The the the table categorizes the architectural and hyperparameter modifications that led to performance gains during the Autoresearch task. It indicates that while learning rate and depth adjustments were the most common sources of improvement, changes to attention patterns yielded the highest median gains per step. Learning rate modifications were the most frequent driver of improvement, occurring in nearly half of the successful optimization steps. Adjustments to attention patterns produced the highest median performance gain, outperforming other categories in typical step-by-step progress. Changes to model depth, width, and MLP activations achieved the largest single-step performance jumps, sharing the highest maximum improvement value.
The experiments evaluate hybrid architectures and LLM agents across various parameter scales, FLOP budgets, and search tasks to assess compute efficiency and model performance. Results indicate that while larger models require fewer training steps under fixed budgets, agent-discovered hybrid variants generally outperform established baselines like Mamba and Composer across downstream tasks. Furthermore, iterative optimization by agents demonstrates that greedy search strategies yield superior solutions compared to one-shot generation, with attention pattern modifications providing the highest median performance gains during the search process.