Command Palette
Search for a command to run...
تقرير تقني لـ PhysBrain 1.0
تقرير تقني لـ PhysBrain 1.0
الملخص
نماذج الرؤية واللغة والإجراء (Vision-language-action) قد شهدت تقدماً سريعاً، لكن مسارات الروبوتات وحدها توفر تغطية محدودة لتعلم الفهم الفيزيائي الواسع. تدرس دراسة PhysBrain 1.0 مساراً مكملاً: يتمثل في تحويل مقاطع الفيديو الذاتية المركز (egocentric) واسعة النطاق الخاصة بالبشر إلى إشراف قائم على الحدس الفيزيائي الشائع (physical commonsense supervision) قبل عملية تكييف الروبوت. تستخرج محرك البيانات لدينا عناصر المشهد، والديناميكيات المكانية، وتنفيذ الإجراءات، والعلاقات الواعية بالعمق، ثم تحولها إلى إشراف قائم على الأسئلة والأجوبة لتدريب نماذج PhysBrain للرؤية واللغة (VLMs). تُنقل بعد ذلك البديهيات الفيزيائية الناتجة إلى سياسات VLA من خلال تصميم تكيّف يحافظ على القدرات ويحسب حسابه الحساس للغة. وفي اختبارات الأسئلة والأجوبة متعددة الوسائط، واختبارات التحكم المتجسد، بما في ذلك ERQA، وPhysBench، وSimplerEnv-WidowX، وLIBERO، وRoboCasa، يحقق PhysBrain 1.0 نتائج متقدمة (SOTA) ويُظهر أداءً قوياً بشكل خاص خارج نطاق البيانات (out-of-domain) على SimplerEnv. تشير هذه النتائج إلى أن توسيع نطاق الحدس الفيزيائي الشائع من مقاطع فيديو التفاعل البشري يمكن أن يوفر جسراً فعالاً من الفهم متعدد الوسائط إلى إجراء الروبوت.
One-sentence Summary
PhysBrain 1.0 addresses the limited coverage of trajectory-only learning by converting large-scale human egocentric videos into structured physical commonsense supervision through a data engine that extracts scene elements, spatial dynamics, action execution, and depth-aware relations for question-answer supervision, subsequently transferring these priors to vision-language-action policies via a capability-preserving and language-sensitive adaptation framework to achieve state-of-the-art results across multimodal QA and embodied control benchmarks including ERQA, PhysBench, SimplerEnv-WidowX, LIBERO, and RoboCasa, with notably strong out-of-domain performance on SimplerEnv.
Key Contributions
- PhysBrain 1.0 introduces a schema-driven data annotation pipeline that converts large-scale human egocentric video into structured scene meta-information and physically grounded question-answer supervision. This pipeline explicitly extracts spatial dynamics, object states, and depth-aware relations to generate scalable physical commonsense priors.
- An integrated adaptation architecture transfers these physics-based priors to vision-language-action policies while preserving general multimodal understanding and language sensitivity. By restricting robot trajectories to a targeted adaptation role, the design prevents catastrophic forgetting during policy fine-tuning.
- Systematic evaluation demonstrates state-of-the-art performance across multimodal QA and embodied control benchmarks, including ERQA, PhysBench, SimplerEnv-WidowX, LIBERO, and RoboCasa. The model exhibits strong out-of-domain generalization on SimplerEnv, validating that human-derived physical priors effectively bridge multimodal understanding and robot action.
Introduction
Vision-language-action models are rapidly advancing robot control, yet scaling these systems typically relies on collecting expensive, platform-specific robot trajectories that offer limited physical coverage. Prior approaches that simply imitate these trajectories often fail to capture underlying physical regularities and frequently suffer from catastrophic forgetting of general multimodal capabilities during adaptation. The authors leverage large-scale human egocentric video as a scalable alternative, introducing a data engine that extracts structured scene elements, spatial dynamics, and depth-aware relations to generate physically grounded question-answer supervision. By training a base vision-language model on these physical commonsense priors and applying a capability-preserving adaptation pipeline, they successfully transfer robust reasoning to downstream robot control while minimizing reliance on limited trajectory data.
Dataset

Dataset Composition and Sources
- The authors assemble the training corpus in stages rather than relying on a single static dataset
- Primary video sources include egocentric interaction datasets like Ego4D, BuildAI, and EgoDex, followed by re-annotated physical reasoning sources such as EPIC and SEA-Small
- General multimodal data like FineVision is mixed in as auxiliary retention material to preserve broad vision-language competence
Subset Details and Filtering
- Stage one clips are pre-filtered using visual-quality and camera-motion scores derived from VGGT, discarding unstable or low-information segments before annotation
- Stage two subsets shift focus from simple action identification to structured physical reasoning, organizing clips into objects, material properties, spatial relations, depth cues, and state changes
- Stage three converts these structured records into free-form VQA supervision covering spatial intelligence, temporal understanding, embodied planning, and general multimodal reasoning
- Exact dataset sizes and training mixture ratios are not specified, but the authors treat the subsets as a curriculum where each stage serves a distinct physical grounding role
Metadata Construction and Processing
- Each video segment is represented by uniformly sampled frames and parsed into a constrained JSON schema containing three core fields: scene elements, spatial dynamics, and action execution
- Scene elements capture static objects, surrounding environments, and explicit physical attributes like material cues, geometry, and state
- Spatial dynamics track initial layouts and temporal changes such as approach, contact progression, separation, or reorientation
- Action execution provides both a compact task brief and a detailed imperative sequence emphasizing trajectory, velocity profiles, and contact physics
- A multi-model annotation pool including GPT-5, Gemini 3.1 Pro, and several Qwen-VL variants cross-checks all records to reduce single-model bias and expose the base model to diverse physically grounded descriptions
Depth Augmentation and Quality Control
- Object grounding is paired with point-wise depth estimates from Depth Anything v3, mapping object centers to depth maps to generate both relative and metric spatial questions
- Quality checks run at every pipeline interface to catch invalid JSON, missing frames, unreadable depth files, or failed object grounding
- Malformed records receive explicit status flags and sentinel values rather than passing silently into training
- Downstream QA generation automatically skips depth-dependent questions for flagged examples while preserving other valid scene information for those samples
Method
The PhysBrain 1.0 framework is structured around a two-stage training process that first establishes a robust physical understanding in a general multimodal model before adapting it to embodied control. The overall pipeline begins with human egocentric videos, which are processed to extract structured scene meta-information. This includes identifying scene elements such as the main object and environment, analyzing spatial dynamics like initial layout and changes, detailing action execution steps, and estimating depth-aware relations. 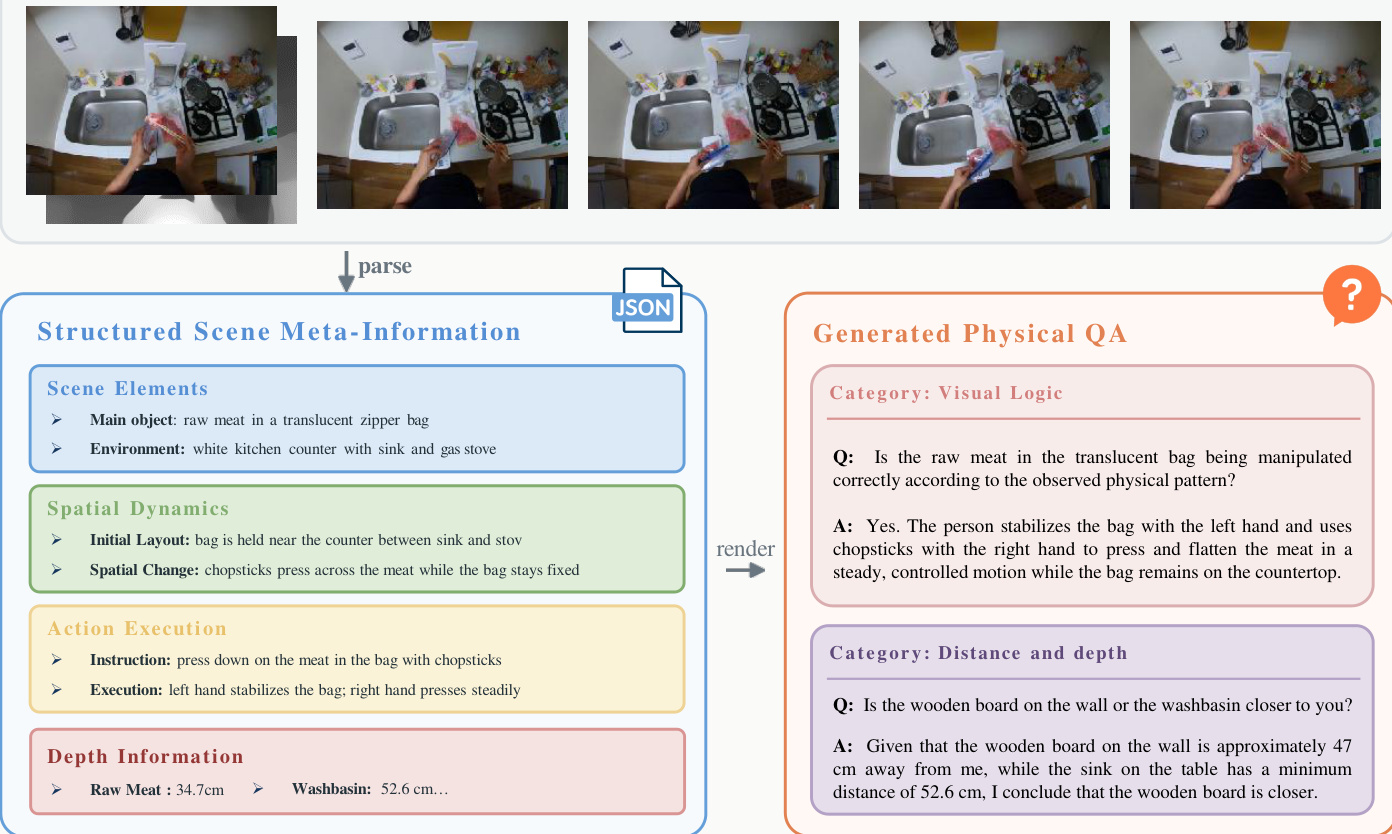 As shown in the figure below, this structured data is rendered into physically grounded question-answer pairs across categories such as visual logic, distance and depth, and embodied reasoning, which are used to train a physically informed base vision-language model (VLM). The goal of this stage is to strengthen the model's first-person physical reasoning, including object state, spatial layout, metric depth, temporal dynamics, and multi-step task structure, without relying on robot demonstrations for physical priors.
As shown in the figure below, this structured data is rendered into physically grounded question-answer pairs across categories such as visual logic, distance and depth, and embodied reasoning, which are used to train a physically informed base vision-language model (VLM). The goal of this stage is to strengthen the model's first-person physical reasoning, including object state, spatial layout, metric depth, temporal dynamics, and multi-step task structure, without relying on robot demonstrations for physical priors.
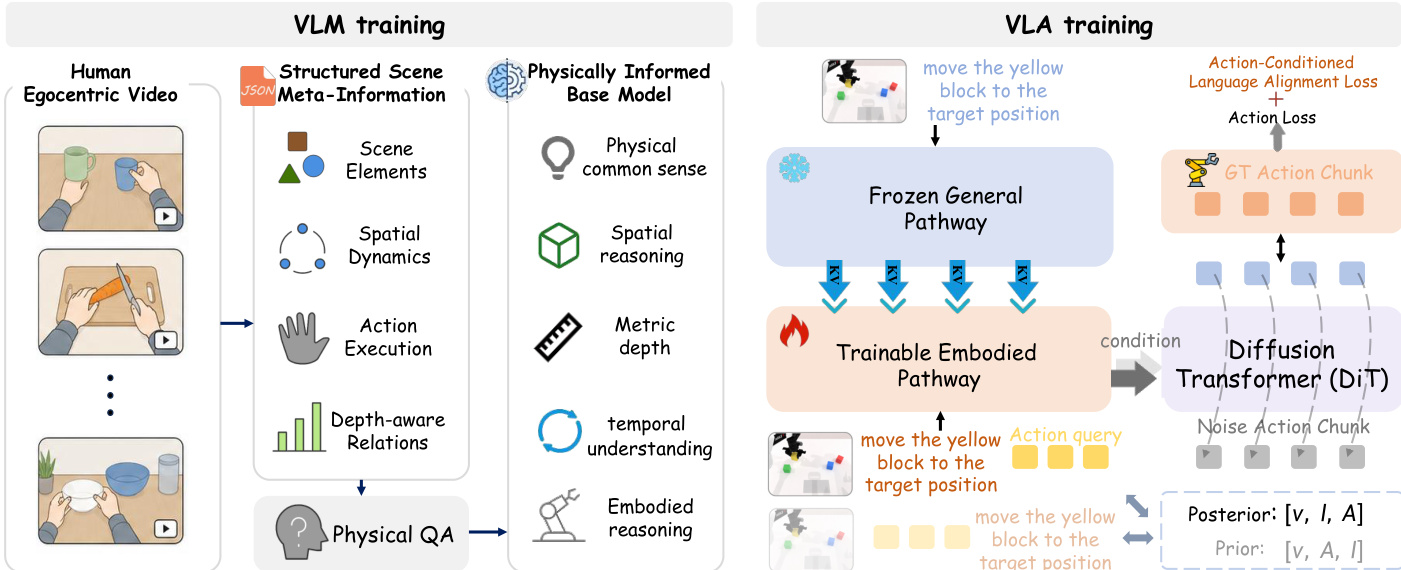 Refer to the framework diagram. The base model is then adapted to a vision-language-action (VLA) policy through a dual-pathway architecture designed to preserve general multimodal capabilities while learning continuous robot control. The architecture consists of a frozen general pathway and a trainable embodied pathway. The general pathway, initialized from the physically informed base model, remains frozen and processes visual observations and language instructions as a stable semantic reference. The embodied pathway, initialized from the same model family, is optimized on robot demonstrations for action prediction. The two pathways communicate via asymmetric layer-wise fusion, where the embodied pathway's query is derived from its own hidden states, but its key-value context combines its states with stop-gradient features from the general pathway. This allows the control pathway to condition on preserved semantic information while preventing the general representations from being overwritten during adaptation.
Refer to the framework diagram. The base model is then adapted to a vision-language-action (VLA) policy through a dual-pathway architecture designed to preserve general multimodal capabilities while learning continuous robot control. The architecture consists of a frozen general pathway and a trainable embodied pathway. The general pathway, initialized from the physically informed base model, remains frozen and processes visual observations and language instructions as a stable semantic reference. The embodied pathway, initialized from the same model family, is optimized on robot demonstrations for action prediction. The two pathways communicate via asymmetric layer-wise fusion, where the embodied pathway's query is derived from its own hidden states, but its key-value context combines its states with stop-gradient features from the general pathway. This allows the control pathway to condition on preserved semantic information while preventing the general representations from being overwritten during adaptation.
To ensure instruction sensitivity during data-efficient robot adaptation, PhysBrain 1.0 employs a language-aware action objective. This objective uses paired branches to compare a vision-only action context with a language-conditioned action context. The prior branch arranges the input as [v, A, l], where the action query tokens attend to vision but not to language, while the posterior branch arranges the input as [v, l, A], allowing the action queries to attend to both vision and language. The hidden states of these query tokens provide the conditions for action prediction, and a log-likelihood-ratio style objective encourages the action representation to retain information relevant to the instruction. This objective is optimized together with the action loss for the diffusion-transformer action decoder.
The action decoder generates continuous robot actions by predicting the velocity field for a flow-matching objective. Given a ground-truth action trajectory and Gaussian noise, the decoder predicts the velocity field to minimize the difference between the predicted and actual action changes. The predicted trajectory is represented in an end-effector-frame action space, consistent with the metric depth understanding acquired during base model training. During inference, the posterior branch conditions the action decoder on the language-aware action query states to generate continuous control commands. The final stage adapts PhysBrain 1.0 to concrete robot benchmarks using benchmark-specific robot trajectories, leveraging the prior physical understanding to achieve data efficiency by requiring fewer robot demonstrations.
Experiment
The evaluation spans visual language model testing across physical and general reasoning benchmarks, vision-language-action simulation trials across diverse robot embodiments, and real-world manipulation comparisons against established baselines. These experiments validate that physically grounded pretraining on human egocentric data strengthens both multimodal comprehension and embodied control capabilities. Results consistently demonstrate superior out-of-domain generalization, robust dexterous manipulation, and improved task execution across heterogeneous robotic platforms. Ultimately, the findings confirm that integrating structured physical priors prior to robot adaptation establishes a more capable and transferable foundation for downstream vision-language-action policies.
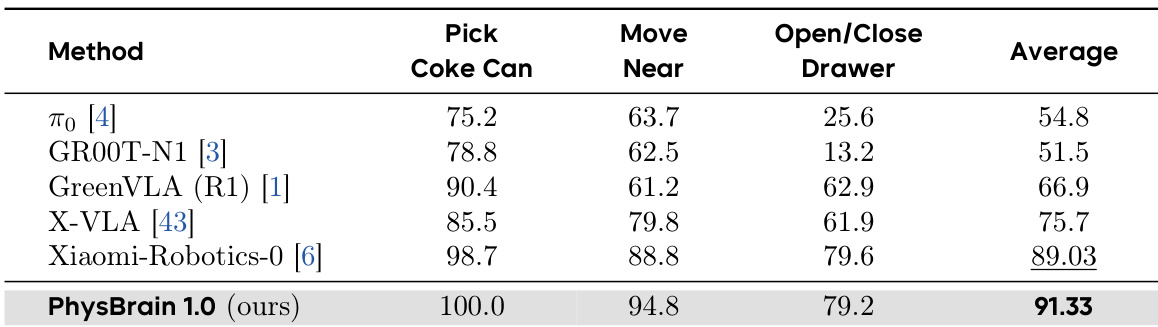
The authors evaluate the PhysBrain 1.0 model in a simulation setting using the SimplerEnv-GoogleRobot benchmark, comparing its performance against several prior methods. Results show that PhysBrain 1.0 achieves the highest average success rate across the evaluated tasks, outperforming all other methods on the majority of individual tasks and demonstrating strong performance on both single-object manipulation and long-horizon tasks. PhysBrain 1.0 achieves the highest average success rate on the SimplerEnv-GoogleRobot benchmark compared to all other methods. PhysBrain 1.0 obtains the best performance on the Pick Coke Can task and shows strong results on Move Near and Open/Close Drawer. PhysBrain 1.0 outperforms the second-best method across all individual tasks, indicating consistent improvement over existing approaches.
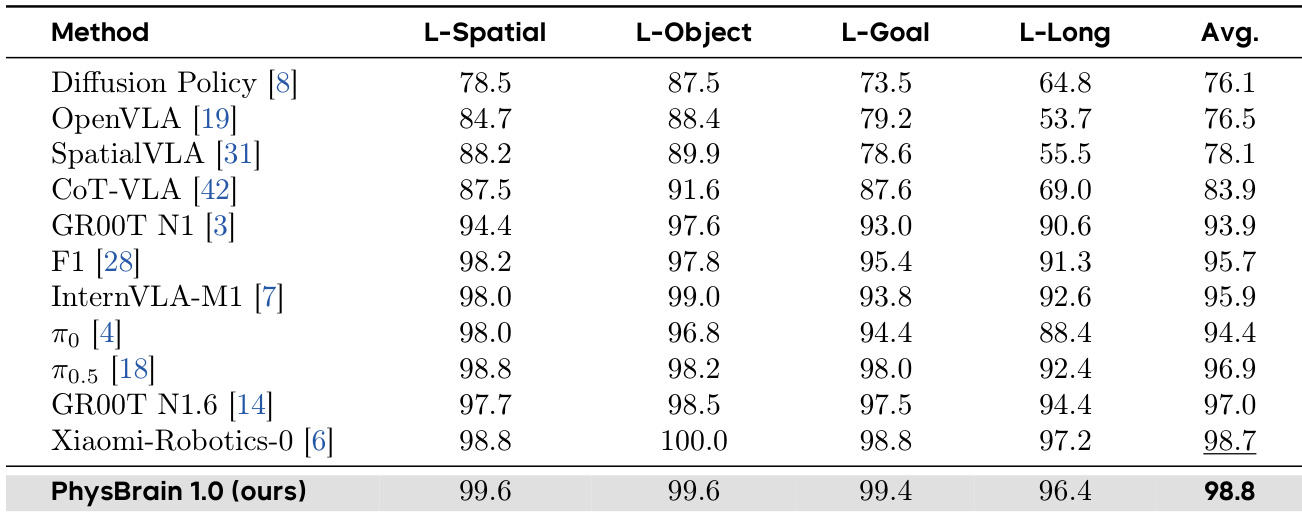
The authors evaluate the performance of PhysBrain 1.0 on the LIBERO benchmark, comparing it against several state-of-the-art VLA models across four task suites. Results show that PhysBrain 1.0 achieves the highest average success rate, outperforming all listed baselines and demonstrating strong performance across all individual task categories. PhysBrain 1.0 achieves the best average success rate on the LIBERO benchmark, surpassing all other methods. PhysBrain 1.0 maintains high performance across all four task suites, including L-Spatial and L-Goal. PhysBrain 1.0 shows consistent improvements over prior methods in both single-object and long-horizon tasks.
The authors evaluate the PhysBrain models on multimodal reasoning and embodied control tasks, showing improvements over baseline models across multiple benchmarks. The results indicate that physically grounded visual understanding enhances both general multimodal performance and downstream robot adaptation, with consistent gains across different embodiments and task types. PhysBrain models achieve the best performance on most visual question-answering benchmarks, demonstrating improved physical reasoning and multimodal understanding. The models show strong out-of-domain generalization and consistent improvement across different robot embodiments and manipulation tasks. PhysBrain 1.0 outperforms strong baselines on all evaluated VLA benchmarks, including those with dexterous hands and complex manipulation tasks.
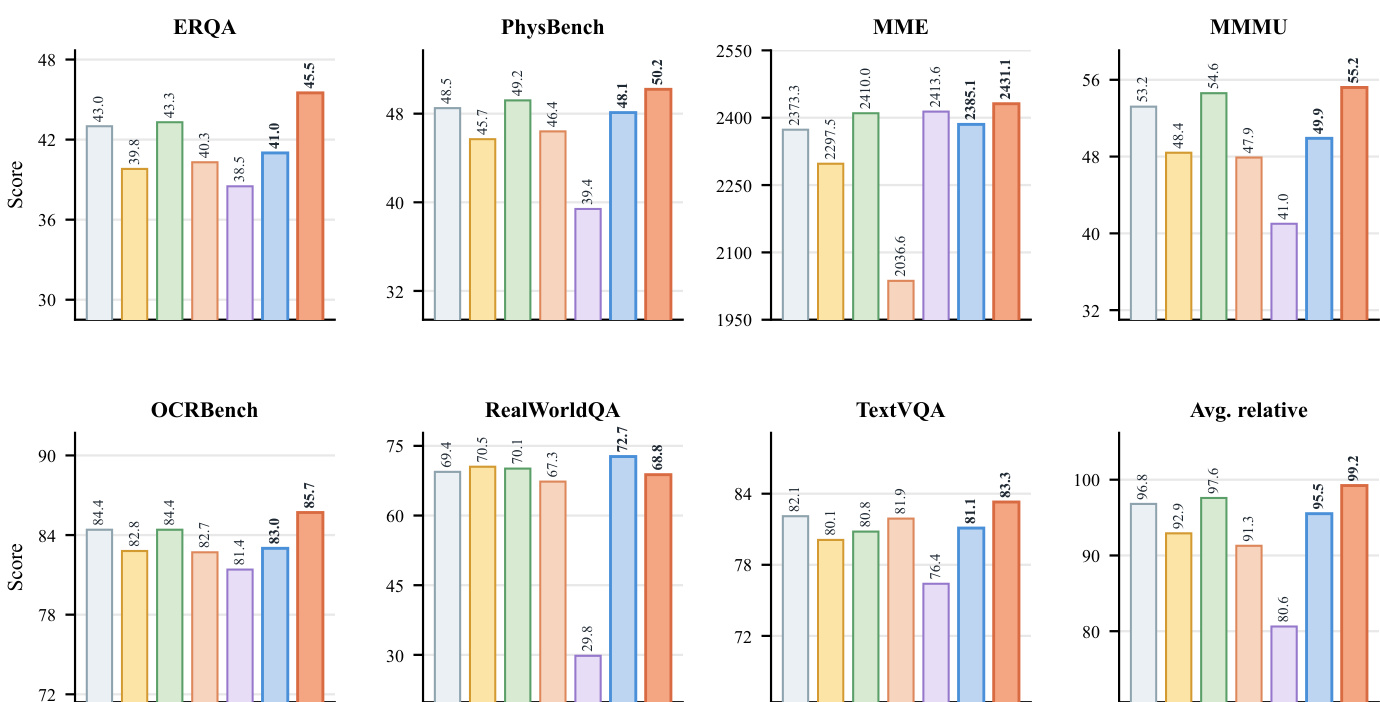
The authors evaluate the performance of PhysBrain 1.0 in embodied control tasks across multiple simulation benchmarks, demonstrating its effectiveness in adapting to different robot embodiments and manipulation scenarios. The results show that PhysBrain 1.0 achieves the highest average success rate across all evaluated benchmarks, indicating strong generalization and transferability of its physically grounded priors. PhysBrain 1.0 achieves the highest average success rate across all benchmark tasks, outperforming all other methods. PhysBrain 1.0 shows consistent improvements over baselines on both single-object and long-horizon manipulation tasks. The model achieves strong performance across diverse robot embodiments and task distributions, indicating robust transferability of its physical priors.
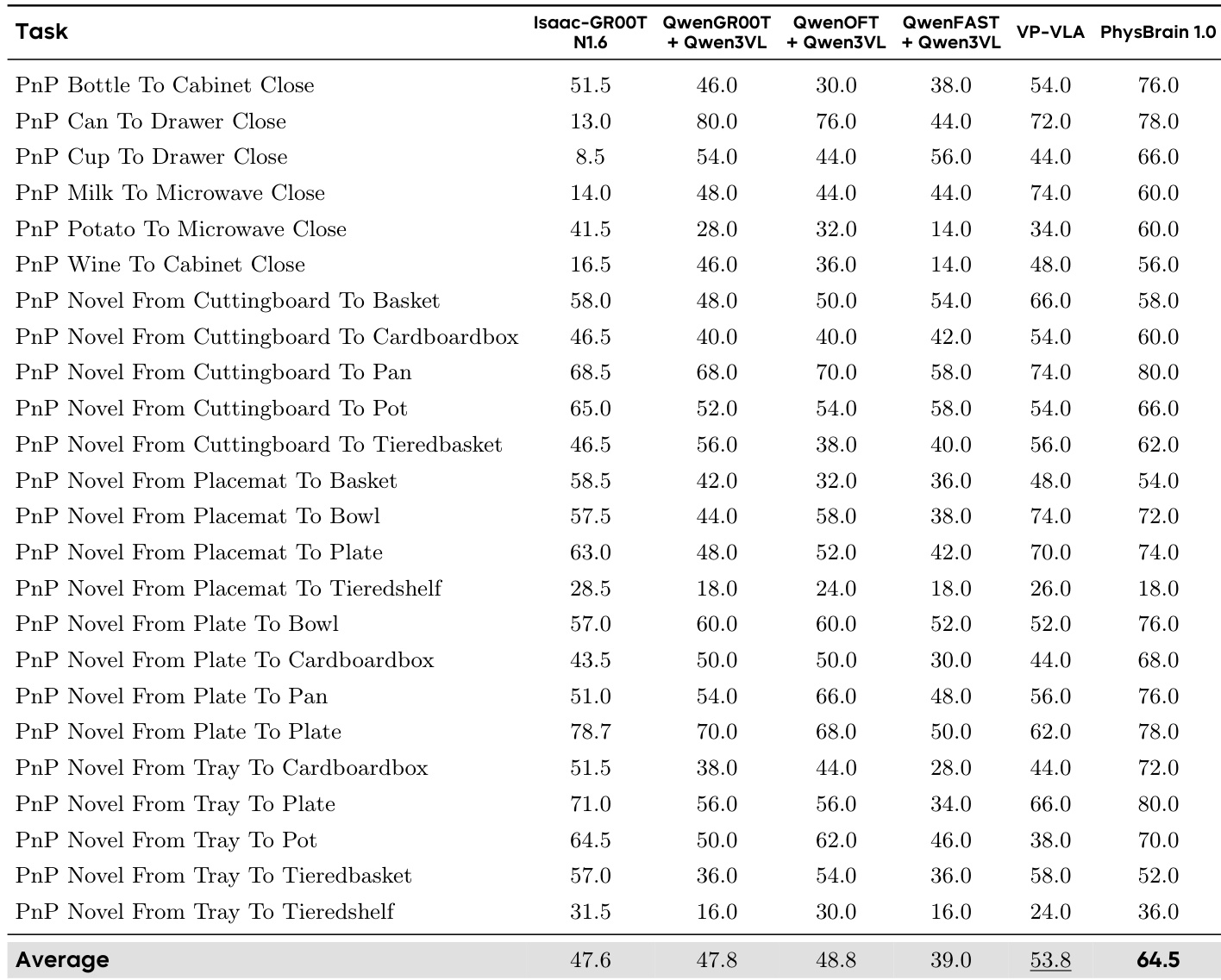
The authors evaluate the performance of PhysBrain 1.0 on the SimplerEnv-WidowX simulation benchmark, comparing it against several state-of-the-art VLA models across multiple manipulation tasks. Results show that PhysBrain 1.0 achieves the highest average success rate, outperforming all other methods on the majority of individual tasks and demonstrating strong generalization across different task types. PhysBrain 1.0 achieves the highest average success rate on the SimplerEnv-WidowX benchmark, outperforming all other methods. PhysBrain 1.0 achieves top performance on multiple individual tasks, including reaching 100% success on Put Eggplant in Yellow Basket. PhysBrain 1.0 significantly outperforms prior methods on several key tasks, indicating improved generalization and robustness in manipulation policies.
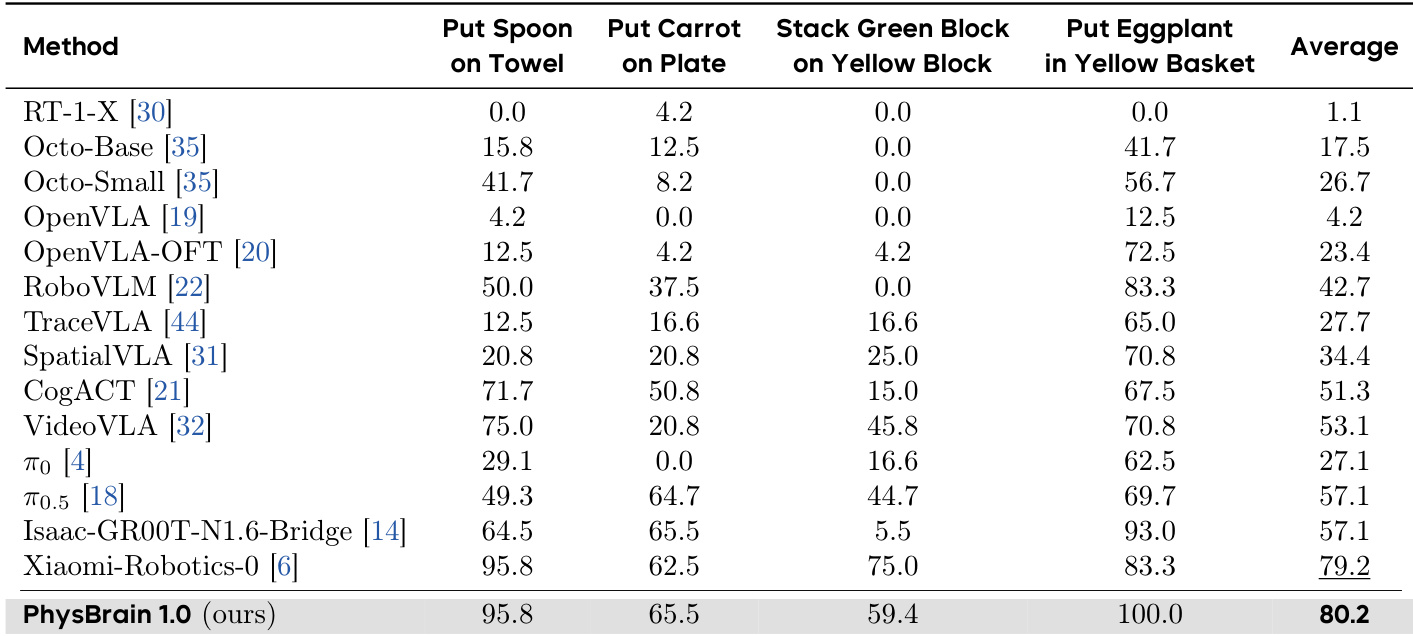
The PhysBrain 1.0 model undergoes comprehensive evaluation across multiple simulation environments and multimodal reasoning benchmarks, validating its effectiveness in single-object manipulation, long-horizon control, and cross-embodiment generalization. Across all tested scenarios, the model consistently surpasses state-of-the-art vision-language-action baselines, demonstrating superior physical reasoning and robust policy execution in complex manipulation settings. These results collectively indicate that embedding physically grounded visual priors substantially improves downstream robot adaptation, enabling reliable transferability across diverse hardware configurations and task distributions.