Command Palette
Search for a command to run...
الإجبار السببي++: تبسيط الانتشار الذاتي الارتجاعي القليل الخطوات القابل للتوسع لتوليد الفيديو التفاعلي في الوقت الحقيقي
الإجبار السببي++: تبسيط الانتشار الذاتي الارتجاعي القليل الخطوات القابل للتوسع لتوليد الفيديو التفاعلي في الوقت الحقيقي
Min Zhao Hongzhou Zhu Kaiwen Zheng Zihan Zhou Bokai Yan Xinyuan Li Xiao Yang Chongxuan Li Jun Zhu
الملخص
تتطلب توليد الفيديو التفاعلي في الزمن الحقيقي زمن استجابة منخفضاً، وبثاً مستمراً، وإطلاقاً قابلاً للتحكم. حققت طرق التقريب التفاضلي الذاتي الانحداري (AR) القائمة على التقريب (distillation) نتائج قوية في نظام الكتل (chunk-wise) ذي الخطوات الأربع، من خلال تقريب النماذج الأساسية ثنائية الاتجاه إلى طلاب ذاتيين انحداريين قليلي الخطوات، إلا أنها لا تزال محدودة بدقة استجابة خشنة وزمن عينة غير مهمل. في هذه الورقة، ندرس إعداداً أكثر جرأة: الذاتية الانحدارية على مستوى الإطارات (frame-wise) بخطوات عينة واحدة أو اثنتين فقط. في هذا النظام، نحدد أن تهيئة الطالب الذاتي الانحداري قليل الخطوات هي عنق الزجاجة الرئيسي: فالاستراتيجيات الحالية إما غير متوافقة مع الهدف، أو غير قادرة على التوليد قليل الخطوات، أو مكلفة جداً للتوسع. نقترح Causal Forcing++، وهو مخطط مبدئي وقابل للتوسع يستخدم تقريب الاتساق السببي (causal CD) لتهيئة الطلاب الذاتيين الانحداريين قليلي الخطوات. الفكرة الأساسية هي أن تقريب الاتساق السببي يتعلم نفس خريطة تدفق الشرط الذاتي الانحداري (AR-conditional flow map) كما في تقريب ODE السببي، لكنه يحصل على الإشراف من خطوة ODE معلمة واحدة عبر الإنترنت بين أزمنة متجاورة، مما يتجنب الحاجة إلى حساب وتخزين مسبق لمسارات PF-ODE الكاملة. وهذا يجعل التهيئة أكثر كفاءة وأسهل في التحسين. يتفوق المخطط الناتج، وهو مخططنا، على أفضل النتائج الحالية (SOTA) لـ Causal Forcing ذي الكتل والخطوات الأربع تحت إعداد الإطارات بخطوتين بمقدار 0.1 في VBench Total، و0.3 في VBench Quality، و0.335 في VisionReward، مع تقليل زمن استجابة الإطار الأول بنسبة 50% وتكلفة تدريب المرحلة الثانية بمقدار 4 مرات. نمدد المخطط أيضاً إلى توليد نموذج عالمي مشروط بالإجراءات (action-conditioned world model generation) بروح Genie3. صفحة المشروع: https://github.com/thu-ml/Causal-Forcing و https://github.com/shengshu-ai/minWM .
One-sentence Summary
Causal Forcing++ enables real-time interactive video generation through frame-wise autoregressive synthesis in one to two sampling steps by employing causal consistency distillation to initialize few-step student models with a single online teacher ODE step between adjacent timesteps, thereby eliminating full trajectory storage while outperforming the 4-step chunk-wise Causal Forcing baseline under the frame-wise 2-step setting by 0.1 in VBench Total and 0.3 in VBench Quality.
Key Contributions
- This paper introduces Causal Forcing++, a scalable initialization pipeline for frame-wise autoregressive video generation with only one to two sampling steps. The method employs causal consistency distillation to learn the autoregressive conditional flow map using supervision from a single online teacher ODE step between adjacent timesteps, thereby eliminating the need to precompute and store full multi-step trajectories.
- Evaluations on the Wan2.1-1.3B model demonstrate that this approach surpasses prior chunk-wise methods in the frame-wise 2-step setting, improving VBench Total and Quality scores while reducing first-frame latency by 50%. The pipeline also reduces Stage 2 training costs by approximately 4x and maintains consistent performance across 1, 2, and 4-step configurations.
- The framework extends to interactive world model generation by distilling a camera-pose-conditioned generator into an autoregressive model, demonstrating direct compatibility with action-conditioned video rollout.
Introduction
Real-time interactive video generation demands low-latency, streaming outputs that respond instantly to user inputs, making autoregressive diffusion models a highly attractive architecture for sequential frame synthesis. However, prior distillation methods typically rely on chunk-wise generation with four sampling steps, which introduces unacceptable latency and coarse granularity for interactive applications. Attempting to push these models to frame-wise generation with only one or two steps exposes a critical initialization bottleneck, as existing strategies either leak future frame information, suffer from severe approximation errors during self-rollout, or demand computationally prohibitive offline trajectory storage. To resolve this, the authors leverage causal consistency distillation to efficiently initialize few-step autoregressive students. By learning the conditional flow map through a single online teacher step between adjacent timesteps, their pipeline eliminates expensive precomputed trajectories while delivering state-of-the-art video quality in a frame-wise two-step regime, halving first-frame latency and reducing training costs by approximately four times.
Method
The authors leverage autoregressive diffusion models to enable interactive video generation with low latency, addressing the limitations of conventional bidirectional diffusion models that generate entire videos in a single pass. This approach operates on smaller generation units—typically frames or chunks—allowing for incremental output and user feedback during generation. The framework integrates diffusion modeling with autoregressive inference, where each frame is generated conditioned on previously generated frames, facilitated by causal attention mechanisms and key-value (KV) cache during self-rollout.
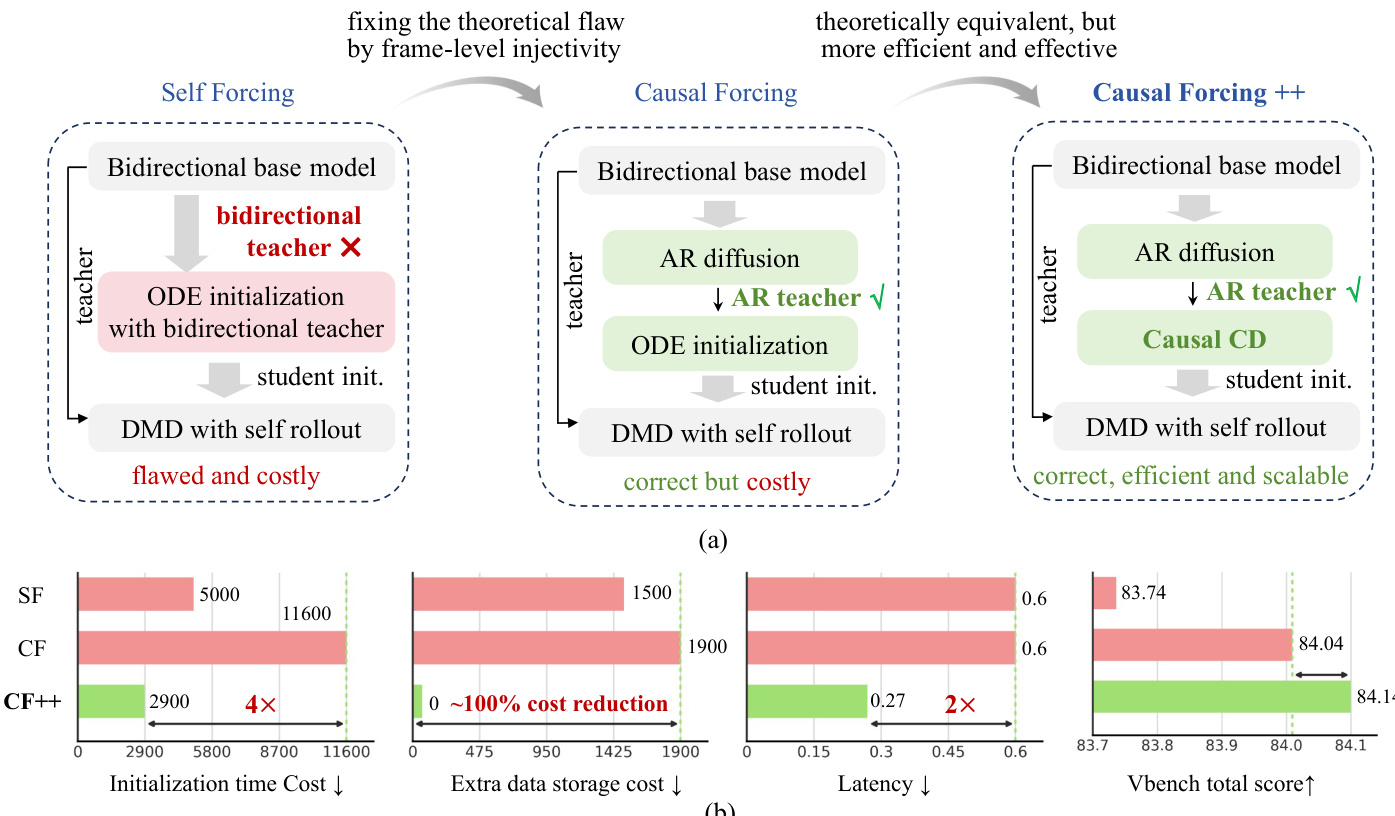
The method builds upon existing autoregressive diffusion distillation pipelines, which typically involve three stages: (1) multi-step autoregressive diffusion training via teacher forcing, (2) causal ODE initialization using an AR teacher, and (3) asymmetric diffusion matching distillation (DMD) with student self-rollout. However, the authors identify critical shortcomings in existing initialization strategies when applied to aggressive low-latency regimes—specifically frame-wise generation with one or two sampling steps. They find that ODE initialization using a bidirectional teacher is architecturally misaligned due to a violation of frame-level injectivity, leading to blurred and poorly aligned outputs. Direct use of multi-step AR diffusion models as initialization lacks few-step capability, resulting in degraded performance under self-rollout. Causal ODE initialization with an AR teacher, while theoretically sound, is computationally prohibitive due to the need to generate and store full multi-step trajectories for each training sample, creating a significant scaling bottleneck.
To address these challenges, the authors propose Causal Forcing++ as a principled and scalable alternative. The core innovation lies in replacing the costly ODE trajectory generation with a novel initialization mechanism called causal consistency distillation (Causal CD). This approach ensures that the initialization is both AR-compatible and efficient, avoiding the need for extensive data curation while maintaining theoretical correctness. The overall framework, as illustrated in the figure below, demonstrates the evolution from Self Forcing to Causal Forcing and finally to Causal Forcing++, highlighting improvements in efficiency, scalability, and performance.
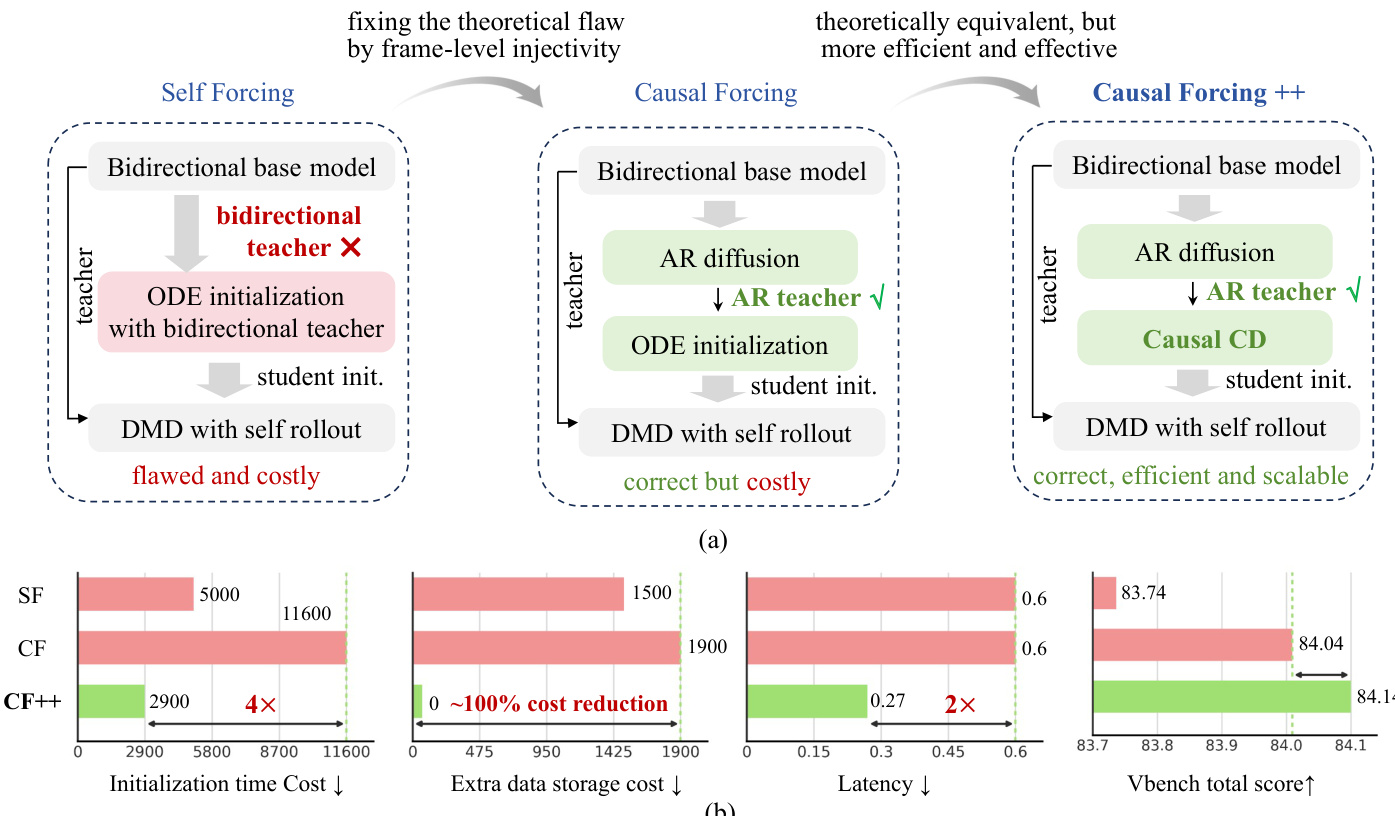
The method is further extended to action-conditioned world model generation, where the model is conditioned on camera poses to simulate camera movements and interactions. This is achieved by first constructing a camera-pose-annotated dataset, fine-tuning a bidirectional diffusion model with pose conditioning, and then distilling it into an interactive action-conditioned model using the Causal Forcing++ pipeline. The framework enables realistic generation of dynamic scenes with user-specified actions, demonstrating its applicability to real-time interactive systems.

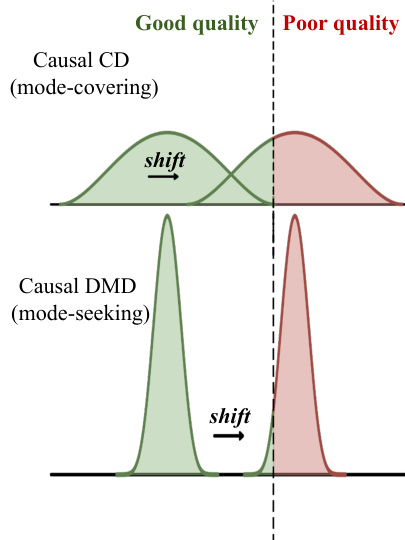
A key aspect of the method is the distinction between mode-covering and mode-seeking behavior in the distillation process. As shown in the figure below, traditional causal DMD tends to produce mode-seeking distributions, which can result in poor quality due to overfitting to specific modes. In contrast, causal consistency distillation promotes mode-covering, leading to more diverse and high-quality outputs.
The effectiveness of the proposed method is demonstrated through qualitative comparisons, where Causal Forcing++ achieves superior results in both frame-wise 1-step and 4-step settings compared to prior approaches. The framework enables real-time interaction by reducing latency and maintaining high generation quality, making it suitable for applications requiring rapid user feedback and dynamic content generation.

Experiment
The experiments evaluate a frame-wise autoregressive video generation pipeline using standard visual quality and instruction-following benchmarks alongside latency and throughput measurements on a single GPU. Comparisons with prior distillation methods demonstrate that the proposed approach significantly reduces generation latency and boosts throughput while preserving or enhancing visual fidelity, motion dynamics, and semantic consistency. Ablation studies further validate the necessity of robust few-step initialization, revealing that traditional ODE and direct AR diffusion strategies yield poor results, whereas the introduced causal CD initialization dramatically cuts computational and storage costs while outperforming alternatives across all step settings. Ultimately, the findings confirm that replacing causal ODE with causal CD enables highly efficient, high-quality video synthesis with superior dynamic behavior and artifact reduction.
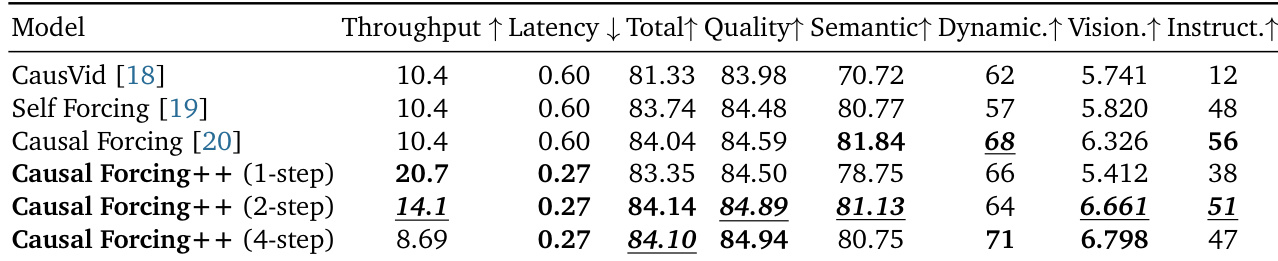
The authors evaluate different initialization methods for asymmetric DMD across 1-step, 2-step, and 4-step settings, comparing their impact on generation quality, dynamics, and efficiency. Results show that causal CD initialization achieves the best overall performance, surpassing other methods in quality and dynamics while significantly reducing computational and storage costs compared to causal ODE. Causal CD initialization achieves the highest quality and dynamics across all step settings while reducing training time and storage requirements compared to causal ODE. Causal ODE initialization is outperformed by Causal CD in all metrics and settings, with significantly higher computational and storage costs. AR diffusion initialization performs poorly in low-step settings, particularly in dynamics and instruction following, indicating the need for explicit few-step adaptation.
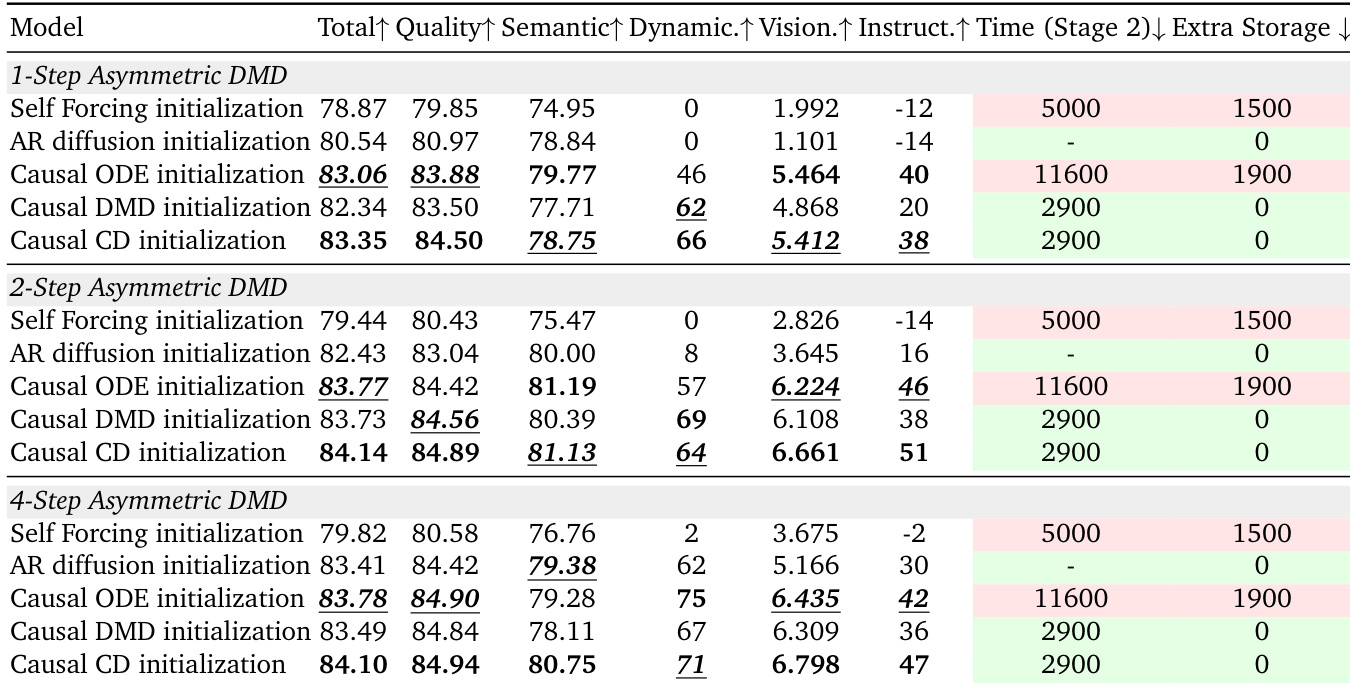
The authors compare different initialization methods for few-step video generation, focusing on their efficiency and performance. Results show that Causal CD outperforms Causal ODE in terms of both time cost and storage requirements while achieving comparable or better generation quality. Causal CD reduces time cost significantly compared to Causal ODE Causal CD eliminates the need for extra storage required by Causal ODE Causal CD achieves comparable or better performance than Causal ODE with lower computational overhead
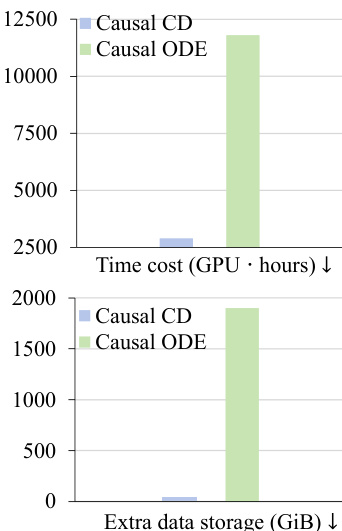
The authors present Causal Forcing++ as an improved version of Causal Forcing, focusing on enhancing efficiency and performance through a new few-step initialization method called Causal CD. Results show that Causal Forcing++ achieves higher generation quality and better efficiency compared to prior methods, with Causal CD significantly reducing initialization time and storage requirements while maintaining or improving performance. Causal Forcing++ achieves higher generation quality and better efficiency compared to previous methods. Causal CD initialization reduces initialization time and storage costs while maintaining or improving performance. Causal Forcing++ outperforms Causal Forcing and other baselines in both quality and efficiency metrics.
The authors compare their method, Causal Forcing++, with existing approaches in terms of generation quality, efficiency, and dynamics. Results show that Causal Forcing++ achieves superior or comparable performance across metrics while significantly reducing latency and improving throughput, especially in 2-step and 4-step settings. Ablation studies further demonstrate that causal CD initialization outperforms other methods in both quality and efficiency, particularly in low-step generation scenarios. Causal Forcing++ achieves higher throughput and lower latency compared to prior methods while maintaining or improving generation quality. Causal Forcing++ with 2-step and 4-step generation surpasses previous state-of-the-art methods in total score, quality, and dynamic degree. Causal CD initialization consistently outperforms other initialization methods in quality and efficiency, especially in low-step settings.
The experiments evaluate different initialization strategies for few-step video generation across one, two, and four-step settings, validating their impact on output quality, temporal dynamics, and computational efficiency. Results consistently demonstrate that the proposed Causal CD initialization outperforms both Causal ODE and AR diffusion baselines by delivering superior generation quality and smoother dynamics while drastically reducing training time and storage requirements. This advantage is particularly pronounced in low-step configurations where alternative methods struggle with performance degradation. Ultimately, the findings confirm that integrating Causal CD into the Causal Forcing++ framework establishes a highly efficient and effective standard for rapid video synthesis.