Command Palette
Search for a command to run...
MinT: بنية تحتية مُدارة للتدريب وتقديم ملايين نماذج اللغات الكبيرة
MinT: بنية تحتية مُدارة للتدريب وتقديم ملايين نماذج اللغات الكبيرة
الملخص
نقدم مجموعة أدوات MindLab (MinT)، وهي نظام بنية تحتية مُدارة لتدريب ما بعد التدريب باستخدام التكيف منخفض الرتبة (LoRA) والتقديم عبر الإنترنت. يستهدف MinT سيناريوً يتم فيه إنتاج العديد من السياسات المدربة عبر عدد قليل من نشرات النماذج الأساسية باهظة الثمن. بدلاً من تجسيد كل سياسة كحالة كاملة مُدمجة، يحتفظ MinT بالنموذج الأساسي في الذاكرة وينقل إصدارات محولات LoRA المُصدرة عبر مراحل التقييم، والتحديث، والتصدير، والتقييم، والتقديم، والتراجع، مخفياًً وراء واجهة الخدمة عمليات التدريب الموزع، والتقديم، وجدولة المهام، ونقل البيانات. يوسع MinT هذه المسار عبر ثلاثة محاور. يوسع "Scale Up" نطاق التعلم المعزز باستخدام LoRA ليشمل البنى الكثيفة والمختلطة من الخبراء (MoE) على مستوى الطليعة، بما في ذلك مسارات الانتباه MLA وDSA، مع التحقق من صحة التدريب والتقديم لما يتجاوز 1 تريليون معلمة إجمالاً. ويقلل "Scale Down" الحجم بنقل محول LoRA المُصدّر فقط، والذي يمكن أن يقل عن 1% من حجم النموذج الأساسي في إعدادات الرتبة-1؛ حيث يقلل تسليم المحول فقط من الخطوة المقاسة بنسبة 18.3 مرة على نموذج كثيف بحجم 4 مليارات معلمة، و2.85 مرة على نموذج MoE بحجم 30 مليار معلمة، بينما يختصر وقت الجدار الزمني بنسبة 1.77 مرة و1.45 مرة عبر التنفيذ المتزامن لسياسات متعددة باستخدام GRPO دون رفع الذاكرة الذروية. ويفصل "Scale Out" قابلية الوصول الدائمة للسياسة عن مجموعات العمل في وحدة المعالجة المركزية ووحدة معالجة الرسومات: حيث يدعم النشر بالتوازي الوتيري فهارس قابلة للوصول بحجم 10^6 (تم قياس مسوحات محرك واحد عبر 100 ألف) وموجات نشطة من آلاف المحولات على مستوى العنقود، مع معالجة التحميل البارد كعملية خدمة مجدولة، وتحسين تحميل المحركات الحية بمقدار 8.5-8.7 مرة عبر ضغط موترات LoRA في نماذج MoE. وبالتالي، تدير MinT فهارس للسياسات القائمة على LoRA بمليون سياسة، بينما تقوم بتدريب وتقديم إصدارات محددة من المحولات عبر نماذج أساسية مشتركة بحجم 1 تريليون معلمة.
One-sentence Summary
The authors introduce MinT, a managed infrastructure that streamlines LoRA-based LLM post-training and serving by keeping base models resident and cycling lightweight adapter revisions to eliminate full checkpoint materialization, reducing adapter handoff time by up to 18.3× and accelerating cold-loading by 8.5–8.7× while managing million-scale policy catalogs over shared 1T-class base models.
Key Contributions
- MinT is a managed infrastructure system that maintains a shared base model in memory while routing exported LoRA adapter revisions through a complete lifecycle of rollout, evaluation, serving, and rollback. This adapter-revision architecture abstracts distributed training, scheduling, and data movement complexities to enable reproducible large-scale LoRA reinforcement learning workflows.
- The system scales LoRA reinforcement learning across dense and Mixture-of-Experts architectures exceeding one trillion parameters through LoRA target mapping, rollout correction, and packed MoE LoRA tensor loading. These mechanisms eliminate full-checkpoint materialization and reframe cold adapter ingestion as scheduled service work to accelerate live engine loading by 8.5× to 8.7×.
- Evaluations on four billion and thirty billion parameter models demonstrate that adapter-only handoffs reduce transfer latency by 18.3× and 2.85× respectively, while concurrent Group Relative Policy Optimization shortens wall time by up to 1.77× without increasing peak memory. The infrastructure manages million-scale policy catalogs with single-engine sweeps through 100,000 entries and supports thousand-adapter active waves at cluster scale.
Introduction
The provided text only lists contributors, which means the technical context, prior work limitations, and core contributions are not available for analysis. To deliver the requested summary, please share the abstract or relevant methodology sections. Once provided, I will outline the application background, existing challenges, and the authors' key innovations in a concise, technically accurate format.
Method
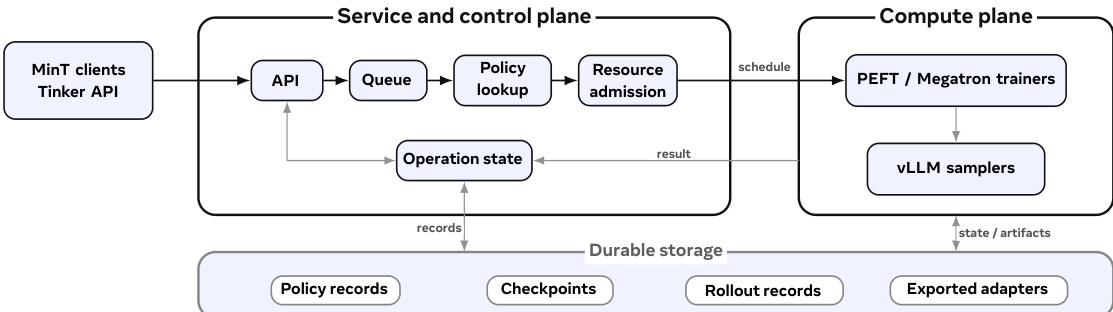
The MinT framework is designed to manage Low-Rank Adaptation (LoRA) post-training and online serving at scale, operating under a model where a small number of expensive base models are shared across many trained policy variants. The system's core architecture separates service control from compute, with a service plane handling client interactions and a compute plane executing training and inference tasks. As shown in the framework diagram, user intent—comprising a base model, data and reward signals, a LoRA reinforcement learning recipe, and evaluation or serving targets—is submitted via an API. This input is processed by MinT, which queues the operation, maintains policy state, and tracks exported revisions. The system then manages a population of policies over shared base model deployments, where the base model remains resident in memory while policy-specific behaviors are encapsulated in LoRA adapters. The underlying infrastructure complexity, including scheduling, fault tolerance, and data movement, is abstracted away behind the service interface.
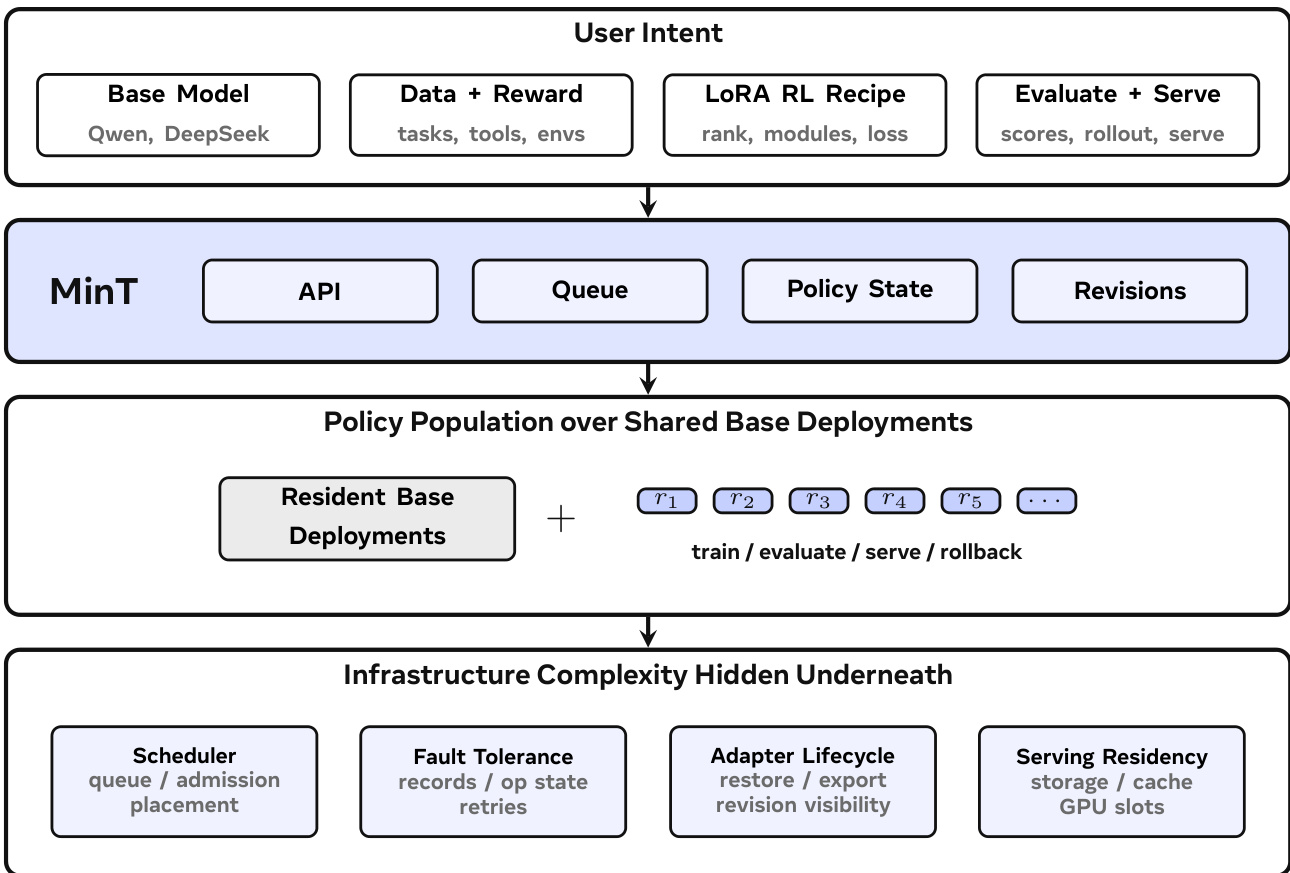
The MinT runtime organization, illustrated in the diagram below, further clarifies this separation. MinT clients interact with the service via a Tinker-compatible API, which validates requests and enqueues them into a queue. The service plane resolves the policy record, admits work onto a compatible worker, and records the operation result. The compute plane consists of PEFT or Megatron trainers for LoRA updates and vLLM samplers or serving actors for inference, all of which operate on resident base models. The service plane maintains durable storage for policy records, checkpoints, rollout records, and exported adapters, ensuring that all state is recoverable and operations are idempotent. This design allows MinT to manage a large number of policy variants without materializing full model checkpoints for each one.
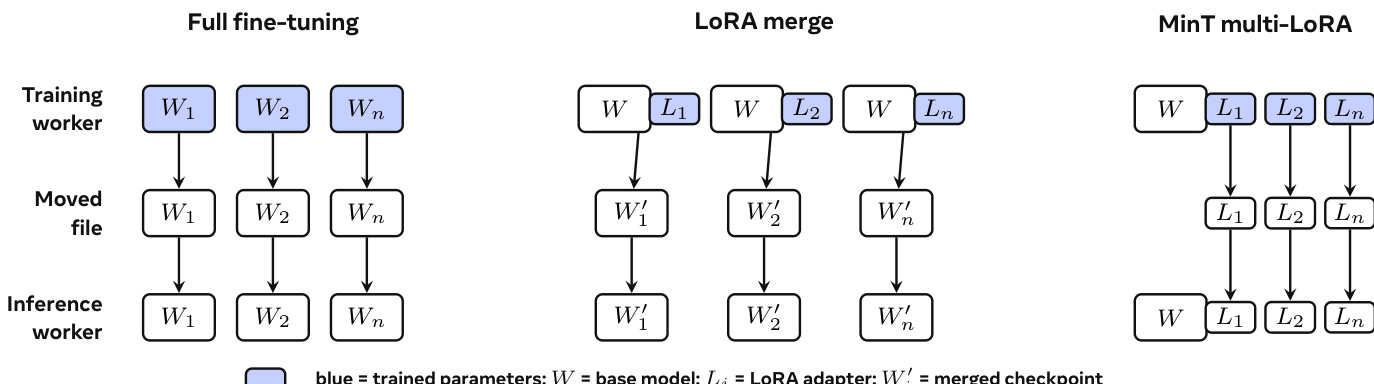
The primary innovation lies in the adapter-centric workflow, which redefines the training-to-serving boundary. As depicted in the comparison of three adaptation paths, MinT moves only the exported LoRA adapter revision from training to serving, rather than a full model checkpoint. This adapter revision is a fixed, exported snapshot of the LoRA adapter, frozen at a specific training step and stored in a serving tensor layout. It is the executable payload that crosses the boundary, while the policy record, which contains the durable lifecycle state, remains separate. The policy record includes the base version, LoRA rank and target modules, the latest training checkpoint, rollout records, and available exported revisions. This separation enables a shared base to support many LoRA policies without creating a full model server for each one.
The system's ability to scale is achieved through three axes: Scale Up, Scale Down, and Scale Out. Scale Up extends LoRA RL to large-scale dense and Mixture-of-Experts (MoE) architectures. This is supported by model-parallel training and serving paths validated beyond 1T total parameters. The system handles model-parallel placement by ensuring that LoRA tensors follow the sharding rules of the base model, whether through tensor parallelism for dense weights or expert parallelism for MoE experts. For MoE models, MinT records the expert routing during rollout and replays this path during training when possible, mitigating instability from router mismatches. For dynamic sparse attention (DSA), it uses IcePop-style rollout correction to filter tokens where the training/rollout probability ratio falls outside a trusted band.
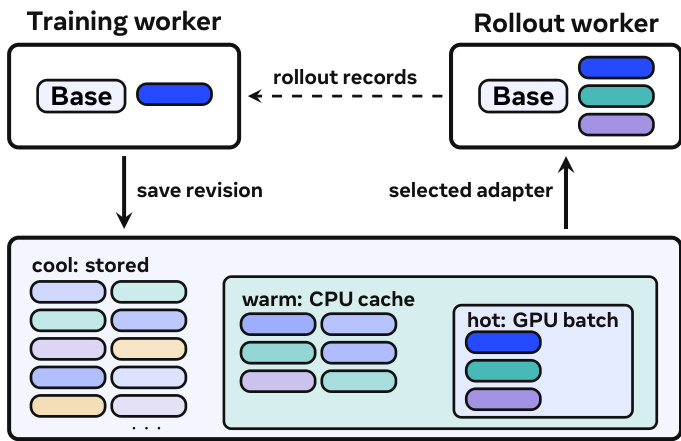
Scale Down minimizes the training-serving handoff by moving only the exported LoRA adapter, which can be less than 1% of the base model size in compact rank-1 settings. This eliminates the need to materialize full checkpoints, significantly reducing the data transfer and storage overhead. In measurements, this adapter-only handoff reduces the handoff step by 18.3× on a 4B dense model and by 2.85× on a 30B MoE model. Scale Out expands the policy namespace while keeping engine-local execution bounded. MinT separates durable policy addressability from CPU/GPU hot working sets, allowing a tensor-parallel serving deployment to support a 106-scale addressable policy catalog. The policy revision can occupy any subset of three cache tiers: the catalog (shared storage), the CPU cache (warm), and the GPU batch (hot). This separation allows the system to manage a vast number of policies while bounding the memory footprint of any single engine.
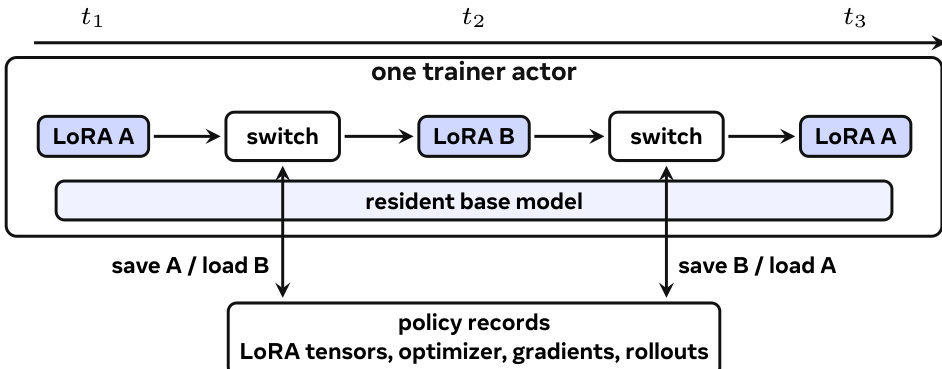
The adapter lifecycle is managed through a series of stages. After a training update, the trainer exports the current training state into a fixed adapter revision. This revision is then stored in durable storage. During rollout or serving, a request resolves a user-facing policy name to an exported revision and an engine-local adapter id. If the adapter is already active in the GPU batch, inference proceeds immediately. If it is cached in CPU memory, the engine promotes it. If it is only in shared storage, the serving actor fetches and loads it before decoding. This process treats cold loading as scheduled service work, with deduplication and backpressure to manage the load staircase when many unique policies arrive together. MinT further improves live engine loading by packing MoE LoRA tensors, reducing the number of small objects and improving performance by 8.5–8.7×. The system's design ensures that the base model remains resident throughout these operations, with only the LoRA tensors and training state changing, enabling efficient time-sliced multi-LoRA training and serving.
Experiment
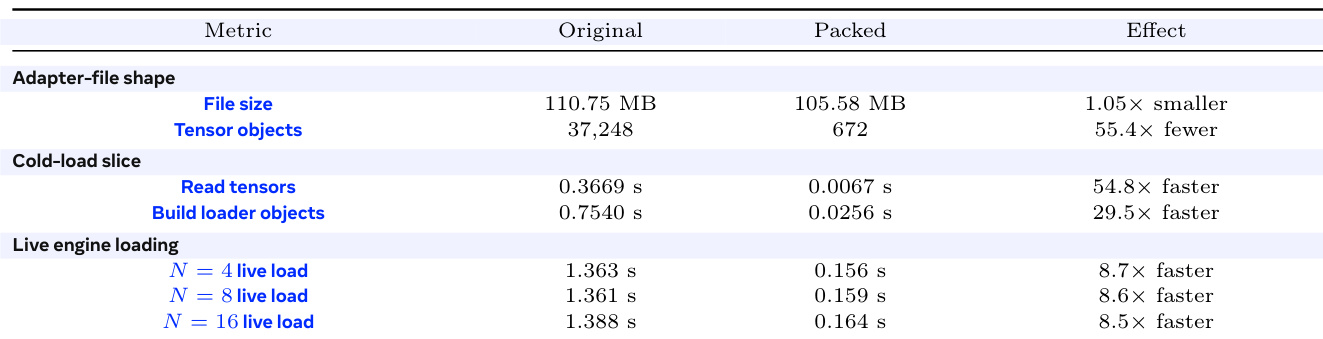
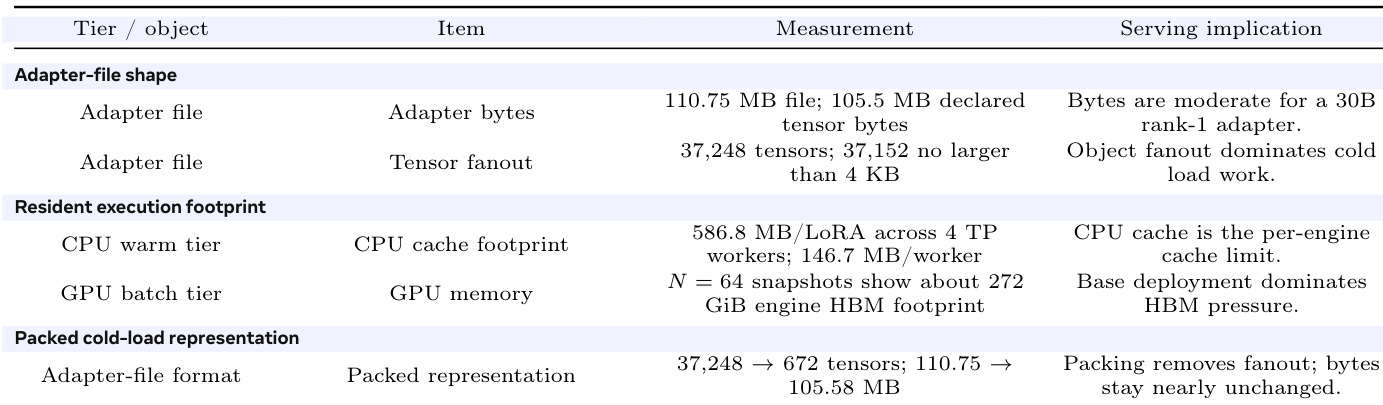
The measured adapter is moderate in byte size and fragmented into tens of thousands of small tensors, most of them no larger than 4 KB. Cold loading therefore pays object and registration overhead even when the total bytes are small.
the table Memory and representation accounting for the measured 30B MoE LoRA adapter files. The rows separate byte size from object fanout and cache pressure.
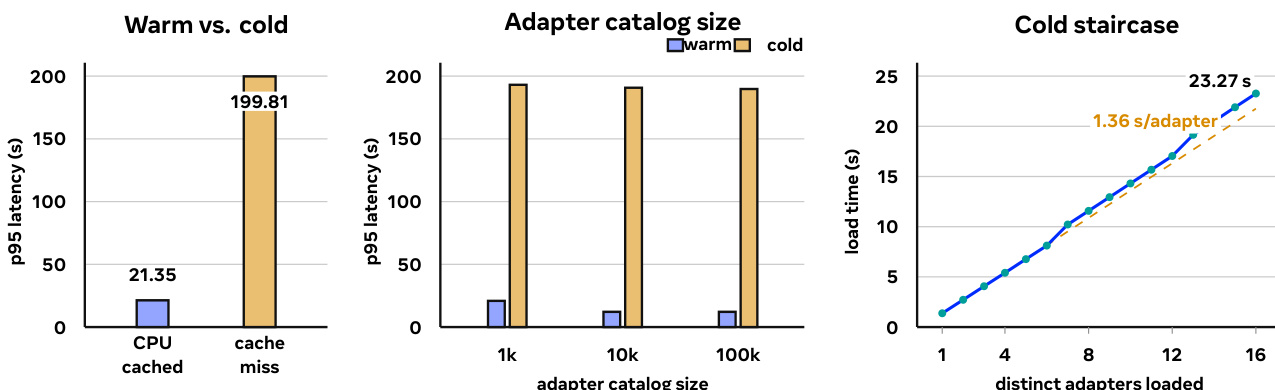
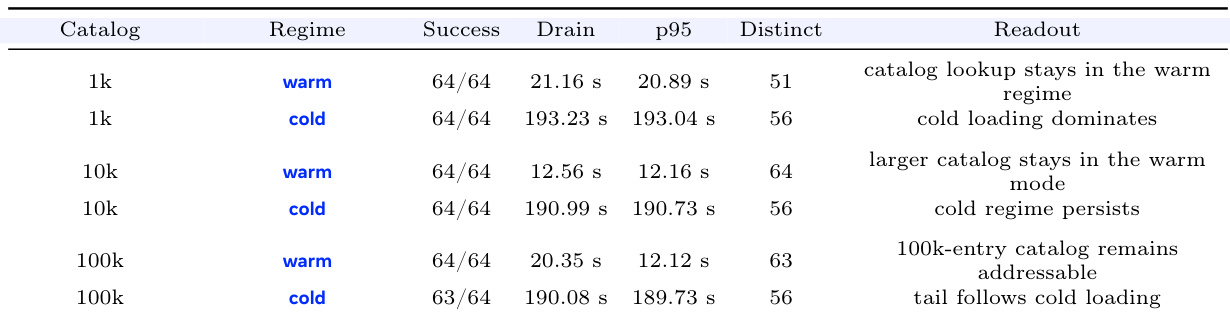
Adapter catalog size. the table varies the adapter catalog from 1k to 100k entries. The warm/cold split persists across the sweep and the measured tail appears when many distinct cold adapters enter cold loading
These rows support the main-text claim that MinT should keep catalog resolution in the control plane and manage cache state and cold loading in the serving plane.
the table Adapter catalog sweep for N=64 serving. Warm and cold rows are split so the stable regime gap is visible at each catalog size.
Cached working sets. the table gives the ordered data behind the warm-cache claim in the figure. The repeated-hotset rows model adapter locality after routing has found a useful engine placement. The unique-adapter rows remove this locality and measure how many distinct adapters can become cached near one engine before the run stops being a clean warm-path claim. These measurements define the CPU-side tier between the durable adapter catalog and the same-batch adapter window.
the table Cached-working-set ladder on one 4-GPU Qwen3-30B rank-1 serving actor. Shaded group rows separate routed locality from unique-adapter load pressure.

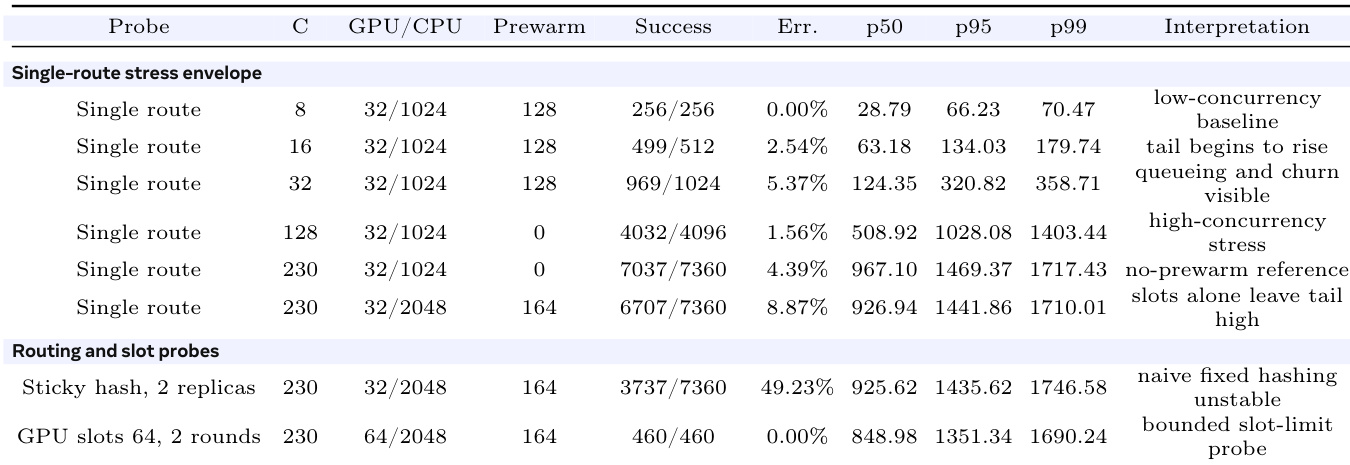
Mixed online-length stress traffic. the table intentionally leaves the clean warm-path setting. These rows combine mixed output lengths, high concurrency, weak locality, prewarm changes, and different slot limits to show where simple routing choices stop being enough. The sticky-hash row is a negative probe; fixed hashing alone fails to provide cache-aware routing under this stress shape. The GPU-slots-64 row is a bounded probe; it verifies a slot-limit setting over two rounds, with long-run stability left outside this claim
the table Mixed online-length traffic on a 2048-adapter catalog. The GPU/CPU column gives the GPU-batch LoRA slot limit and the CPU-cache LoRA limit.
the table Cold-load accounting and service protection.

the table Capacity-planning sketch from measured per-engine limits to a 1M-entry accumulated adapter catalog and a 2300-distinct-adapter active-wave stress envelope.
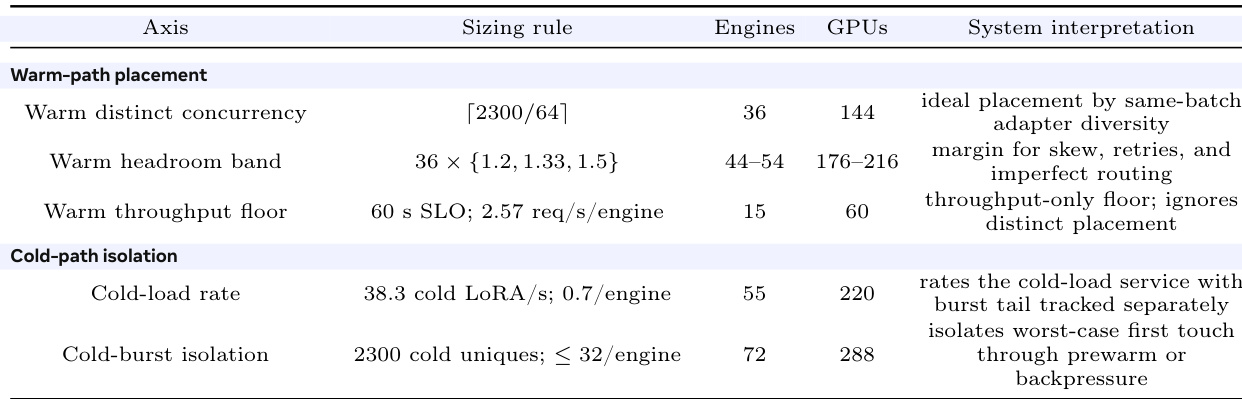
Cold-load accounting. the table decomposes the cold path into API queueing, shared loads for repeated cache-miss requests, unique-adapter loading, and bounded backpressure. The probes show that the bottleneck is unique cold adapter loading into one engine. Requests wait before generation on LoRA loading; the measured API queue wait is small. Deduplicating identical missing adapters avoids repeated load work while distinct cold adapters remain separate load jobs. This supports the main-text claim that cold loading is scheduled service work before ordinary sampling latency.
Fleet-level sizing sketch. the table uses measured single-engine limits as sizing inputs for a larger MinT deployment. This the table a 106-adapter capacity model under a 2300-distinct-adapter active-wave assumption.
The main serving experiments sweep adapter catalogs up to 100k entries. The extrapolation asks how many engines would be needed if a larger accumulated adapter catalog produced that active wave before routing or prewarming restored locality. The 60 s service-level objective is the warm-response target used for the throughput floor, and 2.57 req/s/engine is the observed warm-throughput input for that row. The cold-load rows size the separate case in which many selected adapters are cold at first touch.
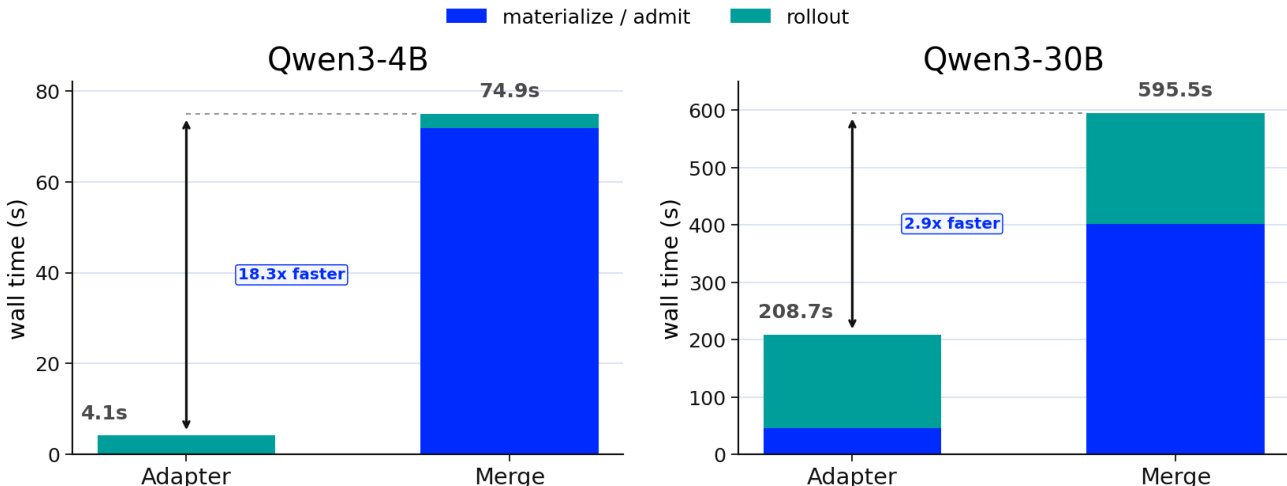
The authors compare two methods for deploying trained policies: loading a LoRA adapter directly versus merging the adapter into a full checkpoint. Results show that the adapter-based method reduces total step time significantly compared to the merge path, with the speedup being more pronounced in larger models. The bar chart illustrates that materialization and loading time dominate the merge path, while the adapter path minimizes this overhead, resulting in faster end-to-end execution. The adapter-based deployment method reduces total step time significantly compared to the merge path, with the speedup being more pronounced in larger models. Materialization and loading time dominate the merge path, while the adapter path minimizes this overhead. The adapter method achieves faster end-to-end execution by reducing the time spent on checkpoint materialization and loading.
The the the table outlines key aspects of adapter management in a serving system, focusing on file shape, execution footprint, and cold-load representation. It highlights that adapter files are moderately sized but contain a large number of small tensors, leading to significant object fanout during cold loads. The CPU cache size is identified as the limiting factor for warm serving, while the base model's HBM footprint dominates memory usage. Packing the adapter file reduces tensor fanout without changing the total bytes, significantly improving cold-load performance by minimizing the number of individual tensor objects that need to be processed. Adapter cold-load performance is dominated by the number of small tensor objects rather than file size. The CPU cache size limits the number of adapters that can be kept warm for fast access. Packing the adapter file reduces tensor fanout, leading to faster cold loads without changing the total file size.
The experiment evaluates the performance of a multi-LoRA serving system under varying catalog sizes and request regimes. Results show that warm requests maintain low latency and high success rates regardless of catalog size, while cold requests exhibit significantly higher latency and are affected by catalog growth. The system maintains a clear separation between warm and cold regimes, with the cold path becoming dominant as the catalog size increases. Warm requests maintain consistent low latency and high success rates across different catalog sizes. Cold requests show significantly higher latency and are dominated by the cold loading regime as catalog size increases. The system exhibits a clear separation between warm and cold regimes, with cold loading becoming the primary bottleneck at larger catalog sizes.
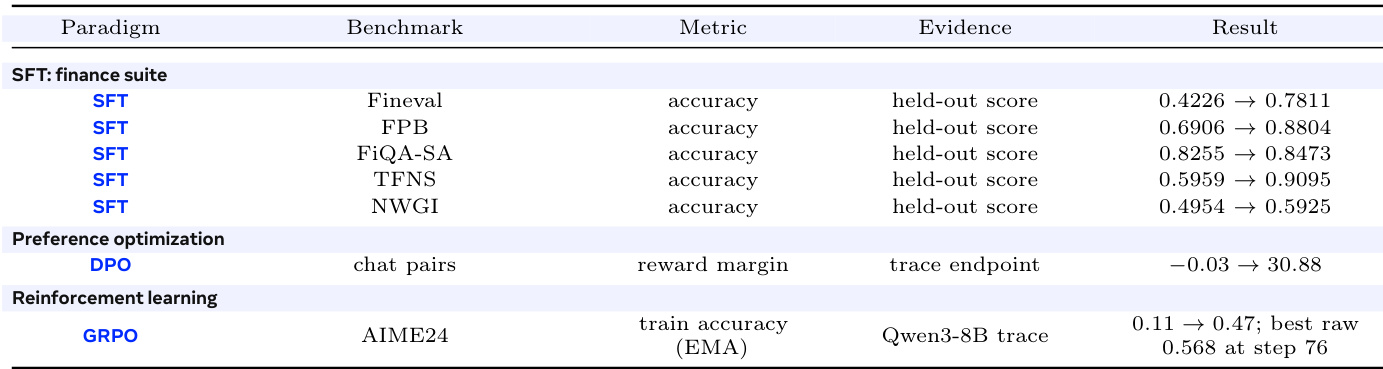
The authors evaluate the performance of different training paradigms—supervised fine-tuning, preference optimization, and reinforcement learning—using a consistent adapter lifecycle across multiple benchmarks. Results show significant improvements in accuracy and reward metrics across all paradigms, demonstrating that the same adapter format supports diverse training objectives without requiring per-paradigm tooling changes. The reinforcement learning results highlight a substantial increase in training accuracy, while the preference optimization shows a large improvement in reward margin. The same adapter lifecycle supports supervised, preference-based, and reinforcement learning paradigms with consistent improvements across benchmarks. Supervised fine-tuning achieves large gains in accuracy across multiple finance-related benchmarks. Reinforcement learning shows a significant increase in train accuracy, with the best raw score reaching 0.568 at step 76.
The authors compare sequential and concurrent training schedules for multiple models, showing that concurrent execution significantly reduces wall time while maintaining peak memory usage. The results demonstrate that concurrent training keeps GPU utilization higher by overlapping idle periods across policies, leading to substantial time savings. The experiments confirm that the same adapter lifecycle supports various training paradigms and model scales without performance degradation. Concurrent training reduces wall time significantly while keeping peak memory usage unchanged compared to sequential execution. GPU utilization is higher in concurrent runs due to overlapping idle periods across policies. The same adapter lifecycle supports different training paradigms and model scales without performance degradation.
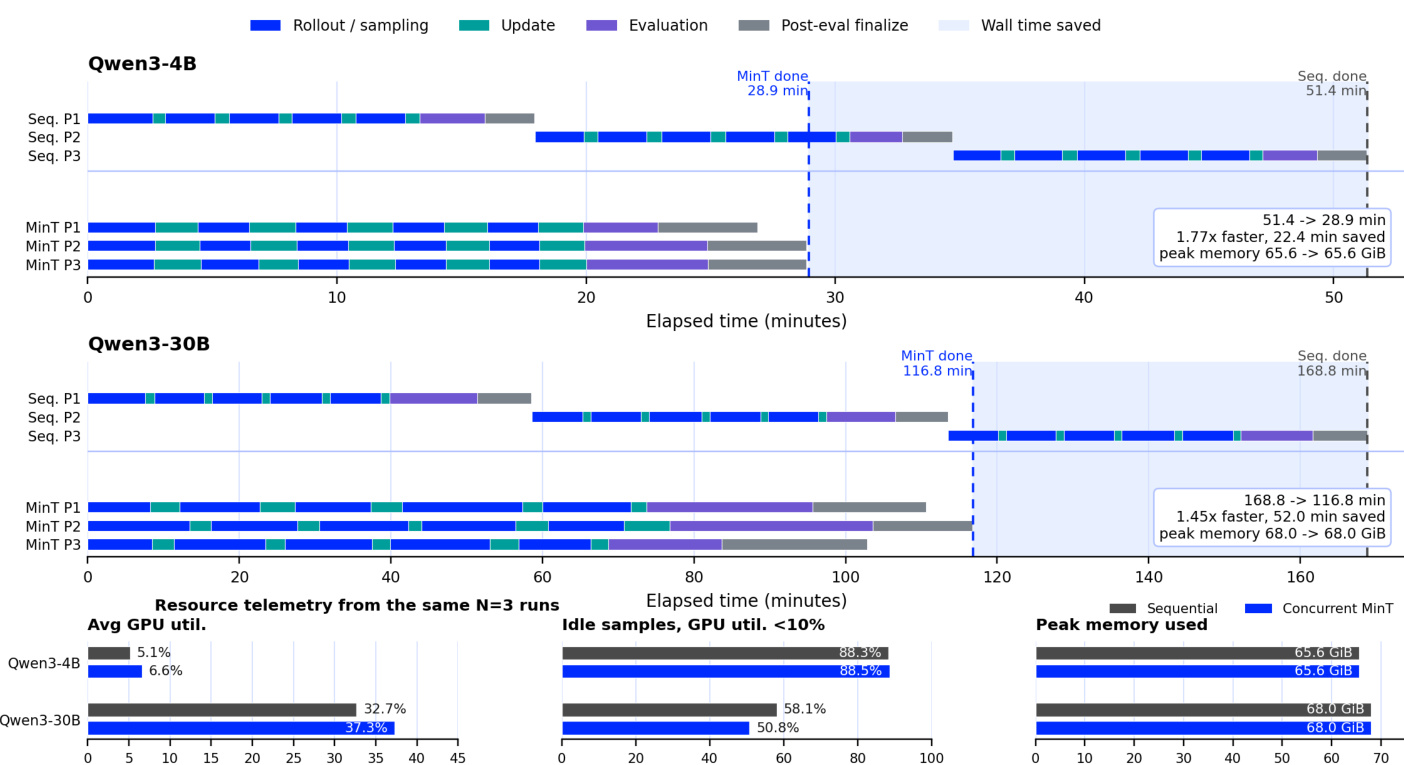
The evaluation examines a unified LoRA adapter framework across deployment, serving, and training phases under varying model scales, catalog sizes, and execution schedules. Deployment tests validate that directly loading adapters rather than merging them significantly accelerates end-to-end execution by minimizing materialization overhead. Serving experiments confirm that while cached requests maintain consistently low latency, cold loads become the primary bottleneck as catalog size grows, a limitation effectively addressed by reducing tensor fanout through file packing. Finally, training evaluations demonstrate that the consistent adapter lifecycle supports diverse optimization paradigms and enables concurrent execution to substantially reduce wall time without increasing peak memory usage.