Command Palette
Search for a command to run...
CiteVQA: تقييم نسب الأدلة للذكاء الوثائقي الموثوق
CiteVQA: تقييم نسب الأدلة للذكاء الوثائقي الموثوق
الملخص
العنوان: [غير محدد]الملخص: حققت النماذج اللغوية الكبيرة متعددة الوسائط (MLLMs) تقدماً كبيراً في فهم المستندات، ومع ذلك، تقتصر تقييمات Doc-VQA الحالية على تقييم الإجابة النهائية فقط، تاركةً الأدلة الداعمة دون فحص. يخفي نهج الإجابة وحده نمط فشل حرجاً: حيث يمكن للنموذج أن يصل إلى الإجابة الصحيحة بينما يستند إلى مقطع خاطئ، وهو خطر جسيم في المجالات عالية المخاطر مثل القانون والمالية والطب، حيث يجب أن تكون كل استنتاجات قابلة للتتبع إلى منطقة مصدر محددة. لمعالجة هذه المشكلة، نقدم CiteVQA، وهو معيار يتطلب من النماذج إرجاع اقتباسات بصيغة صناديق حدودية على مستوى العناصر (element-level bounding-box citations) جنباً إلى جنب مع كل إجابة، مما يقيّم كليهما معاً. يتألف CiteVQA من 1,897 سؤالاً عبر 711 ملف PDF تغطي سبع مجالات لغتين، بمتوسط 40.6 صفحة لكل مستند. ولضمان الدقة والقابلية للتوسع، يتم توليد اقتباسات الحقيقة الأرضية (ground-truth citations) عبر خط أنابيب آلي يحدد الأدلة الحاسمة من خلال حذف القناع (masking ablation)، ويتم التحقق منها لاحقاً من خلال مراجعة الخبراء. في صلب تقييمنا تكمن دقة النسب الصارمة (Strict Attributed Accuracy - SAA)، والتي تُنسب فيها النتيجة الصحيحة فقط عندما تكون كل من الإجابة والمنطقة المقتبسة صحيحة. يكشف تدقيق 20 نموذج MLLM عن ظاهرة "هلوسة النسب" (Attribution Hallucination) المنتشرة: حيث تنتج النماذج الإجابة الصحيحة في كثير من الأحيان بينما تستشهد بالمنطقة الخاطئة. يحقق أقوى نظام (Gemini-3.1-Pro-Preview) دقة SAA تبلغ 76.0 فقط، بينما يصل أقوى نموذج MLLM مفتوح المصدر إلى 22.5 فقط. وأخيراً، ومن أجل ذكاء موثوق به في المستندات، يكشف CiteVQA عن فجوة في الموثوقية تتجاهلها التقييمات القائمة على الإجابة فقط، مقدماً الأدوات اللازمة لسدها. يمكن الوصول إلى مستودعنا على الرابط https://github.com/opendatalab/CiteVQA.
One-sentence Summary
Contrasting with prior answer-only evaluations, CiteVQA advances trustworthy document intelligence by jointly assessing final answers and element-level bounding-box citations via Strict Attributed Accuracy, thereby exposing pervasive attribution hallucinations and providing rigorous instrumentation for high-stakes domains.
Key Contributions
- The paper introduces CiteVQA, a benchmark requiring multimodal models to return element-level bounding-box citations alongside final answers. The dataset comprises 1,897 questions across 711 multi-page PDFs spanning seven domains and two languages, with ground-truth citations generated via an automated masking ablation pipeline and validated by expert review.
- The work establishes Strict Attributed Accuracy (SAA), a metric that credits a prediction only when both the textual answer and the cited visual region are correct. This evaluation protocol enforces joint verification to overcome the reliability gaps inherent in conventional answer-only scoring.
- An audit of 20 multimodal large language models identifies a pervasive Attribution Hallucination phenomenon where systems frequently cite incorrect document regions despite producing correct answers. The baseline results show that the strongest closed-source system achieves an SAA of 76.0, while the top open-source model reaches 22.5.
Introduction
Document Visual Question Answering and evidence-based reasoning have become essential for high-stakes domains like healthcare and law, where preventing LLM hallucinations and ensuring verifiable information extraction are critical. Prior benchmarks, however, remain largely answer-centric and rely on coarse page-level annotations or inconsistent bounding box granularity without standardized evaluation protocols. Existing document intelligence systems also struggle with precise element-level grounding, while current metrics fail to verify reasoning paths or visual traceability in complex, multi-domain layouts. To address these gaps, the authors introduce CiteVQA, a cross-page framework that standardizes element-level bounding box citations and implements joint evaluation metrics. This approach uniquely measures both answer accuracy and structural traceability, enabling rigorous auditing of model reasoning against precise visual evidence in real-world documents.
Dataset

Dataset Composition and Sources
- The authors introduce CiteVQA, a benchmark comprising 1,897 questions derived from 711 PDF documents spanning seven domains and 30 sub-categories across two languages.
- Documents average 40.6 pages each and are sourced from Common Crawl, selected through a stratified sampling pipeline that filters over 100 million raw PDFs based on domain and language distribution.
- The dataset balances single-document tasks (52.0%) with multi-document scenarios, including cases with one gold document (25.7%) and multiple gold documents (22.3%).
- Each question requires an average of 2.57 evidence elements, with approximately 30% of evidence consisting of non-textual content such as tables, images, or equations.
Key Details and Subsets
- The benchmark covers diverse reasoning types ranging from complex synthesis to multimodal parsing, ensuring broad domain representation.
- Evidence is uniformly distributed across document positions and frequently spans multiple pages, requiring robust long-context aggregation capabilities.
- The dataset includes questions distilled from various open-source sources, processed through template generation to simulate real-world business scenarios.
- Human expert audits validate a subset of 200 instances, confirming appropriate question difficulty and high annotation quality.
Data Processing and Construction
- Construction relies on an automated pipeline that performs multi-document linking via semantic alignment and LLM-based metadata integration.
- Deep parsing utilizes MinerU2.5 to extract bounding box coordinates and OCR content, while MLLM agents navigate the parsed space to aggregate supporting facts into evidence packages.
- QA pairs are synthesized using template-driven distillation, where MLLMs select logical templates and generate questions based on evidence characteristics.
- Quality control includes answerability verification to ensure evidence sufficiency, paraphrasing for linguistic diversity, and a zero-document self-test to discard common-knowledge questions.
- Crucial evidence is identified through ablation-based masking, where elements are individually masked to verify their necessity for deriving the correct answer.
Usage and Evaluation Strategy
- The authors use CiteVQA as a rigorous evaluation benchmark rather than a training set, auditing 20 mainstream multimodal models.
- Evaluation centers on Strict Attributed Accuracy, which credits predictions only when both the answer and the cited region are correct.
- Additional metrics assess evidence coverage via Recall and logical alignment via Relevance to diagnose model behavior.
- The benchmark exposes a pervasive attribution hallucination phenomenon, where models produce correct answers grounded in incorrect evidence, with state-of-the-art models capping at 76.0 SAA.
Metadata and Cropping Specifications
- Metadata includes structured spatial coordinates and document identifiers, with bounding box coordinates provided as relative values ranging from 0 to 1000 on the page image.
- Page numbers in the metadata are indexed from 1, ignoring original page numbers from the source documents.
- Citation rules enforce element-level granularity, requiring evidence to correspond to complete paragraphs, tables, images, or notes rather than partial text or rows.
- Captions and footnotes for tables and images are annotated as separate evidence elements with distinct bounding boxes to ensure precise visual grounding.
- The output format requires bounding box tags to accompany cited evidence, enabling direct verification of the visual source for every claim.
Method
The framework for the CiteVQA system is composed of four primary stages: multi-document linking, evidence package extraction, QA construction, and quality control. The overall process begins with multi-document linking, where a filtered document pool undergoes semantic aggregation to form a linked document group. This stage leverages a semantic profiling mechanism to generate high-level descriptors for each document, which are then encoded into normalized vectors. For an anchor document, the top-K candidate documents are selected based on cosine similarity, forming a candidate pool that ensures only contextually relevant documents proceed to fine-grained analysis.

As shown in the figure below, the fine-grained alignment process employs a large language model (LLM) to perform chain-of-thought reasoning across section units from both the anchor and candidate documents. The model identifies logical bridges between documents by analyzing their structural hierarchy and outputs structured association groups, each containing an anchor section, a candidate section, a similarity score, and a rationale. The system retains the top matches based on scores and filters out unreliable associations, ensuring high information density and reducing noise.

The second stage, evidence package extraction, involves parsing documents to collect high-quality, verifiable evidence bundles. This is achieved through a multi-step process that includes document parsing and agent exploration. The system extracts OCR text, bounding boxes, and logical relations to form evidence packages. Each package must satisfy specific criteria: it must span at least two pages, include at least two element types (such as text, tables, figures, or layout), and provide complete context for any extracted elements. The output is a list of evidence bundles, each containing a description and a collection of relevant elements.
In the QA construction phase, question collection and template distillation are performed to synthesize QA pairs. The system uses templates derived from the collected questions to generate structured QA pairs, ensuring that the generated answers are grounded in the extracted evidence. The final stage, quality control, involves QA verification and paraphrasing to ensure the accuracy and coherence of the generated responses. This includes evidence ablation to assess the impact of crucial evidence and to ensure that the generated answers are not overly reliant on non-essential information.
The framework is designed to maintain a balance between preserving fine-grained document details and adhering to the architectural limits of diverse model families. The input resolution is standardized to 1024×1024 pixels, which represents a critical saturation point for most current multimodal large language models (MLLMs). This resolution ensures that precise localization is maintained while avoiding the limitations imposed by context constraints. The inference settings are unified across experiments, with a maximum output length of 4,096 tokens and the use of specific model configurations to maximize reasoning capability. The deployment infrastructure utilizes 8×NVIDIA H200 GPUs to ensure consistent latency and sufficient VRAM for high-resolution document processing.
Experiment
The evaluation assesses twenty advanced multimodal language models on the CiteVQA benchmark to validate their capacity for accurate question answering alongside trustworthy spatial grounding and evidence attribution across diverse document formats. The experiments reveal a pervasive attribution hallucination where models frequently produce correct answers but fail to precisely locate or cite the supporting evidence, with proprietary systems significantly outperforming open alternatives that struggle with basic page navigation. Performance deteriorates sharply in cross-document and complex layout scenarios, yet the strong positive correlation between evidence quality and answer accuracy indicates that enhancing autonomous spatial localization is fundamental to improving both reasoning capabilities and reliability in professional applications.
The authors evaluate evidence attribution in multimodal language models using a set of metrics that assess both answer correctness and grounding quality. Results show a significant gap between answer accuracy and strict attributed accuracy across all models, indicating a pervasive issue where models can generate correct answers without correctly linking them to supporting evidence. Performance varies widely by model type, with closed-source models outperforming open-source ones, and the difficulty of attribution increases substantially in multi-document settings. Models often achieve high answer accuracy but fail to properly ground their responses in specific evidence, a phenomenon referred to as 'Attribution Hallucination'. Closed-source models significantly outperform open-source models in evidence attribution, with a substantial performance gap observed across all metrics. Attribution becomes markedly harder in multi-document scenarios, where even top models show significant drops in localization and recall performance.

The experiment evaluates multimodal large language models on evidence attribution tasks using a dataset with diverse document types, question types, and evidence sources. Results show significant performance gaps between models, particularly in linking answers to correct document locations, with many models failing to locate relevant pages or accurately cite evidence despite generating correct answers. Models often fail to locate the correct document pages, indicating a fundamental challenge in coarse-grained attribution. A discrepancy exists between answer correctness and evidence attribution, with many models achieving high answer accuracy but low attribution scores. Performance varies significantly by question type, with quantitative reasoning tasks being easier than multimodal parsing, which requires precise evidence localization.
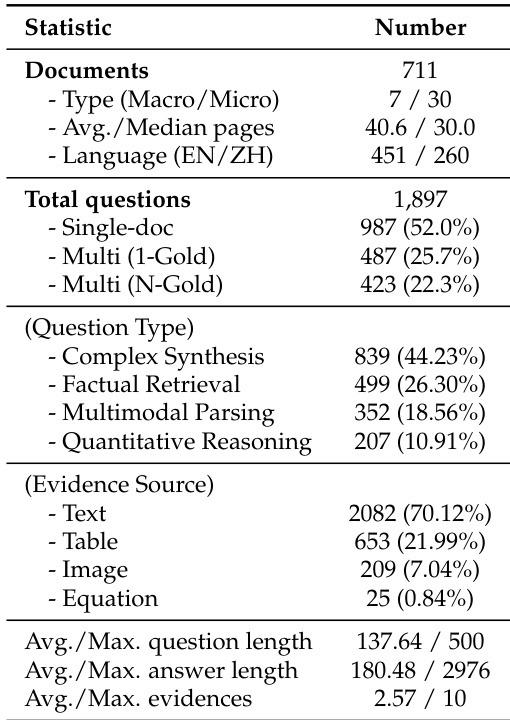
The the the table presents a comprehensive evaluation of various multimodal large language models across different document scenarios, highlighting significant performance disparities between closed-source and open-source models. Results show that closed-source models generally outperform open-source models in evidence attribution, with a notable gap in strict attributed accuracy, indicating a common issue of attribution hallucination where models provide correct answers but fail to ground them properly. Performance degrades substantially in multi-document settings compared to single-document tasks, particularly for open-source models, and the ability to locate the correct page is a major bottleneck across all model categories. Closed-source models significantly outperform open-source models in evidence attribution, especially in multi-document scenarios. A widespread gap exists between answer correctness and strict attributed accuracy, indicating a common issue of attribution hallucination. Locating the correct document page is a major challenge, with performance dropping sharply in multi-document settings across all models.
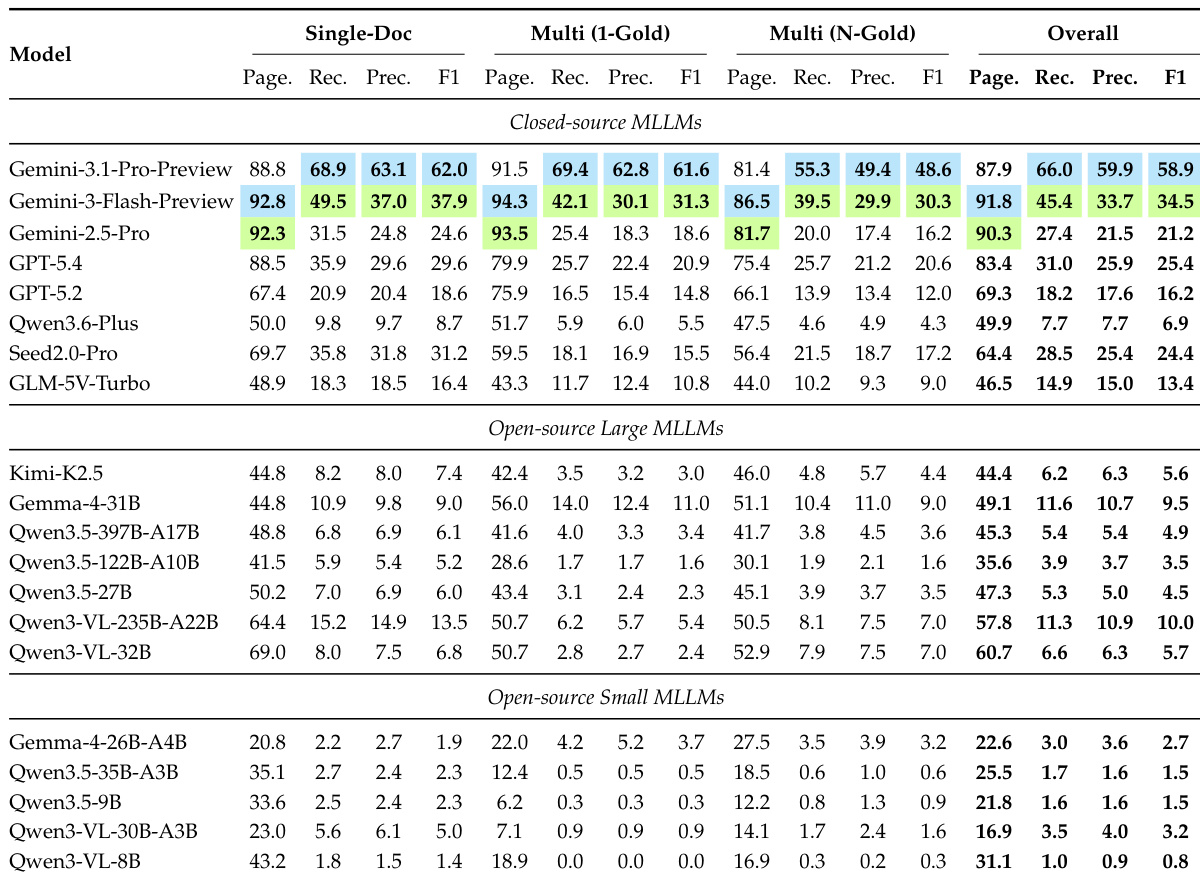
The authors evaluate the performance of models on evidence attribution tasks using automated judges and compare their scores against human expert ratings. Results show that automated judges produce scores that are statistically indistinguishable from human evaluations across both relevance and answer correctness metrics, indicating the reliability of the automated evaluation pipeline. The analysis further reveals that models exhibit varying levels of performance, with some achieving high answer correctness but lower relevance scores, suggesting a discrepancy between accurate answers and faithful evidence grounding. Automated judges produce scores that are not statistically different from human expert ratings, validating the reliability of the evaluation method. Models show a performance gap between answer correctness and relevance, indicating a disconnect between generating correct answers and providing well-grounded evidence. GPT-5.4 and Gemini-3.1-Pro achieve high answer correctness scores but differ in relevance, highlighting varying strengths in evidence attribution.
The authors evaluate evidence attribution in multimodal large language models using a comprehensive set of metrics that assess both answer correctness and grounding quality. Results show a significant gap between answer accuracy and strict attributed accuracy across all models, indicating a pervasive issue where models can generate correct answers without properly linking them to the supporting evidence. Performance varies widely by model type, with closed-source models outperforming open-source ones, and the task becomes substantially harder in multi-document settings due to challenges in both page-level navigation and precise evidence localization. Models often achieve high answer correctness but fail to attribute evidence correctly, indicating a widespread attribution hallucination problem. Closed-source models significantly outperform open-source models in evidence attribution, with a notable performance gap in strict attributed accuracy. Multi-document scenarios drastically reduce performance, particularly in page-level recall and evidence localization, highlighting challenges in cross-document reasoning.

The experiments evaluate multimodal large language models on evidence attribution tasks using diverse document types and question formats, with automated scoring validated against human expert ratings to ensure reliability. Results consistently reveal a pronounced disconnect between answer correctness and strict evidence grounding, highlighting a widespread phenomenon where models generate accurate responses without properly citing supporting material. While closed-source architectures generally surpass open-source counterparts, performance degrades substantially in multi-document environments, underscoring significant challenges in cross-document navigation and precise localization.