Command Palette
Search for a command to run...
ديلتا-ميم: ذاكرة فعالة في الوقت الحقيقي لنماذج اللغة الكبيرة
ديلتا-ميم: ذاكرة فعالة في الوقت الحقيقي لنماذج اللغة الكبيرة
Jingdi Lei Di Zhang Junxian Li Weida Wang Kaixuan Fan Xiang Liu Qihan Liu Xiaoteng Ma Baian Chen Soujanya Poria
الملخص
تزداد الحاجة إلى نماذج اللغة الكبيرة (LLMs) إلى تجميع المعلومات التاريخية وإعادة استخدامها في أنظمة الوكلاء والمساعدين طويلة الأمد. إن التوسيع البسيط لنافذة السياق مكلف وغير كافٍ غالباً لضمان الاستفادة الفعّالة من السياق. نقترح هنا δ-mem، وهي آلية ذاكرة خفيفة الوزن تعزّز الهياكل الأساسية (backbones) الكاملة الانتباه (full-attention) والمجمّدة، من خلال حالة عبر الإنترنت مصغّرة للذاكرة الارتباطية (associative memory). يضغط δ-mem المعلومات السابقة في مصفوفة حالة ذات حجم ثابت، يتم تحديثها عبر تعلّم قاعدة دلتا (delta-rule learning)، ويستخدم إخراج القراءة من هذه المصفوفة لتوليد تصحيحات ذات رتبة منخفضة (low-rank corrections) تُطبَّق على عملية حساب الانتباه في الهيكل الأساسي أثناء التوليد. وبفضل وجود حالة ذاكرة عبر الإنترنت ذات حجم 8×8 فقط، يحقق δ-mem متوسط درجات يساوي 1.10× مقارنة بالهيكل الأساسي المجمّد، و1.15× مقارنة بأقوى أساس لآليات الذاكرة من النوع غير δ-mem. وتسجّل المكتسبات نتائج أكبر على الاختبارات ذات الاعتماد العالي على الذاكرة، حيث تصل إلى 1.31× على MEMORYAGENTBENCH و1.20× على LCoMo، مع الحفاظ بشكل كبير على القدرات العامة للنموذج. تظهر هذه النتائج أنه يمكن تحقيق ذاكرة فعّالة من خلال حالة عبر الإنترنت مصغّرة مربوطة مباشرة بحساب الانتباه، دون الحاجة إلى الضبط الدقيق الكامل (full fine-tuning) أو استبدال الهيكل الأساسي أو التوسيع الصريح للسياق (explicit context extension).
One-sentence Summary
The authors propose δ-mem, a lightweight memory mechanism augmenting a frozen full-attention backbone with an 8 × 8 online associative state updated by delta-rule learning to generate low-rank corrections to attention computation, improving the average score to 1.10× that of the frozen backbone and 1.15× that of the strongest non-δ-mem memory baseline while reaching 1.31× on MEMORYAGENTBENCH and 1.20× on LCoMo without full fine-tuning, backbone replacement, or explicit context extension, largely preserving general capabilities.
Key Contributions
- δ-mem augments a frozen full-attention backbone with a compact online state of associative memory that compresses past information into a fixed-size state matrix. This state is updated by delta-rule learning to maintain historical information without full fine-tuning, backbone replacement, or explicit context extension.
- During generation, the method queries the online state to extract context-relevant signals that transform into low-rank corrections for the backbone's attention components. This configuration allows associative memory to directly participate in forward computation while leaving the backbone frozen.
- Evaluation on memory-heavy benchmarks shows an 8 × 8 online memory state improves the average score to 1.10× that of the frozen backbone and reaches 1.31× on MEMORYAGENTBENCH. These results demonstrate effective memory realization without relying on extending explicit context or heavy external retrieval modules.
Introduction
Large language models face significant challenges in long-term assistant and agent systems where they must accumulate and reuse historical information over extended interactions. Simply expanding context windows is computationally expensive and often leads to context degradation, while existing memory mechanisms suffer from retrieval noise, integration complexity, or static representations. To address these issues, the authors propose delta-mem, a lightweight mechanism that augments a frozen full-attention backbone with a compact online state of associative memory. This system compresses past information into a fixed-size matrix updated via delta-rule learning and applies low-rank corrections directly to the backbone's attention computation. This approach achieves superior performance on memory-heavy benchmarks without requiring full fine-tuning or explicit context extension.
Method
The authors introduce δ-mem, a memory mechanism designed to augment a frozen full-attention backbone with a compact online state of associative memory. This approach enables the dynamic maintenance of historical information that is directly coupled with the backbone's attention computation. The overall framework operates by reading associative memory signals from a previous state, using these signals to steer attention, and subsequently writing current information into the state. This allows the model to compress history into an evolving state without updating the backbone parameters. Refer to the framework diagram for a visual overview of this design, which highlights the interaction between the LLM Backbone and the δ-Mem module.
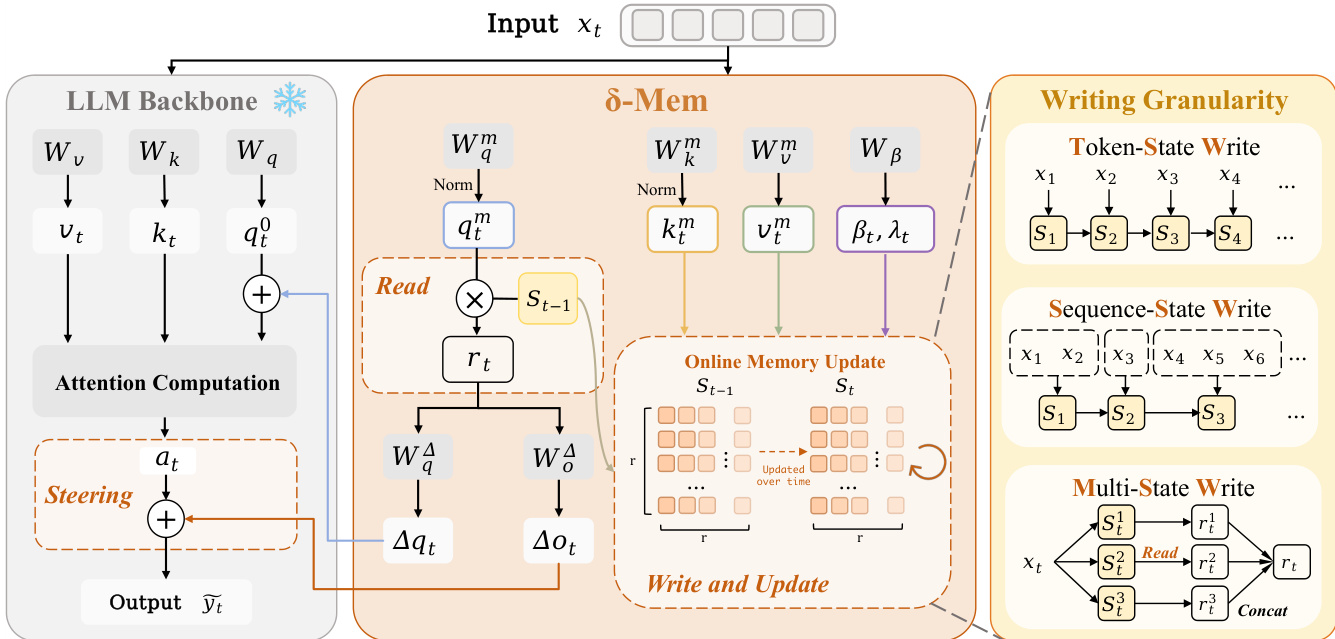
To form the online state, the method projects the hidden state xt at the current position into a low-dimensional associative memory space. This yields query, key, and value vectors qtm,ktm,vtm∈Rr. The query and key vectors undergo L2 normalization to mitigate state instability caused by scale drift during long-sequence recurrence. Additionally, write and retention gates, βt and λt, are determined by the current hidden state to allow dimension-wise adjustment of the state update.
Before writing new information, the system reads from the previous state St−1. The read vector rt=St−1qtm provides continuous associative memory signals that are complementary to standard attention. These signals steer the attention computation through two lightweight linear mappings. The read signal is projected into a query-side correction Δqt and an output-side correction Δot. The query-side correction is added to the original query of the frozen backbone, and the output-side correction is added after the attention operation. This low-rank correction allows the same set of parameters to produce different steering effects under different histories.
After the attention computation, the method writes the current information into the online state using a dimension-wise gated delta-rule. The update process involves retaining the previous state, removing the old prediction component along the current key direction, and writing the new value into the same direction. This ensures the memory state is updated by error correction with controlled forgetting rather than unselectively accumulating new outer products.
The framework also explores different writing granularities to suit various interaction patterns. The authors examine three strategies: Token-State Write (TSW), which updates the state at every token position for fine-grained information; Sequence-State Write (SSW), which averages hidden states within message segments to reduce redundant writes; and Multi-State Write (MSW), which decomposes memory into multiple parallel sub-states to reduce mutual interference between different types of information like facts and task progress.
Finally, δ-mem is trained using the standard supervised fine-tuning (SFT) loss. During training, context tokens are first written into the online state to produce SC. The frozen backbone then receives only the query and response tokens, while the stored state steers the attention. The loss is calculated as the autoregressive cross-entropy over the response tokens, optimizing the trainable δ-mem parameters while keeping the backbone parameters frozen.
Experiment
The evaluation assesses delta-mem against textual, parametric, and outside-channel memory baselines across general reasoning and memory-intensive benchmarks using various LLM backbones. Results demonstrate that delta-mem consistently outperforms competing methods by leveraging an online state to robustly retain historical information, effectively recovering context even without explicit replay. Ablation studies further confirm that injecting memory signals across all layers and into query and output branches yields optimal performance, while efficiency tests reveal negligible memory and parameter overhead compared to heavier alternatives.
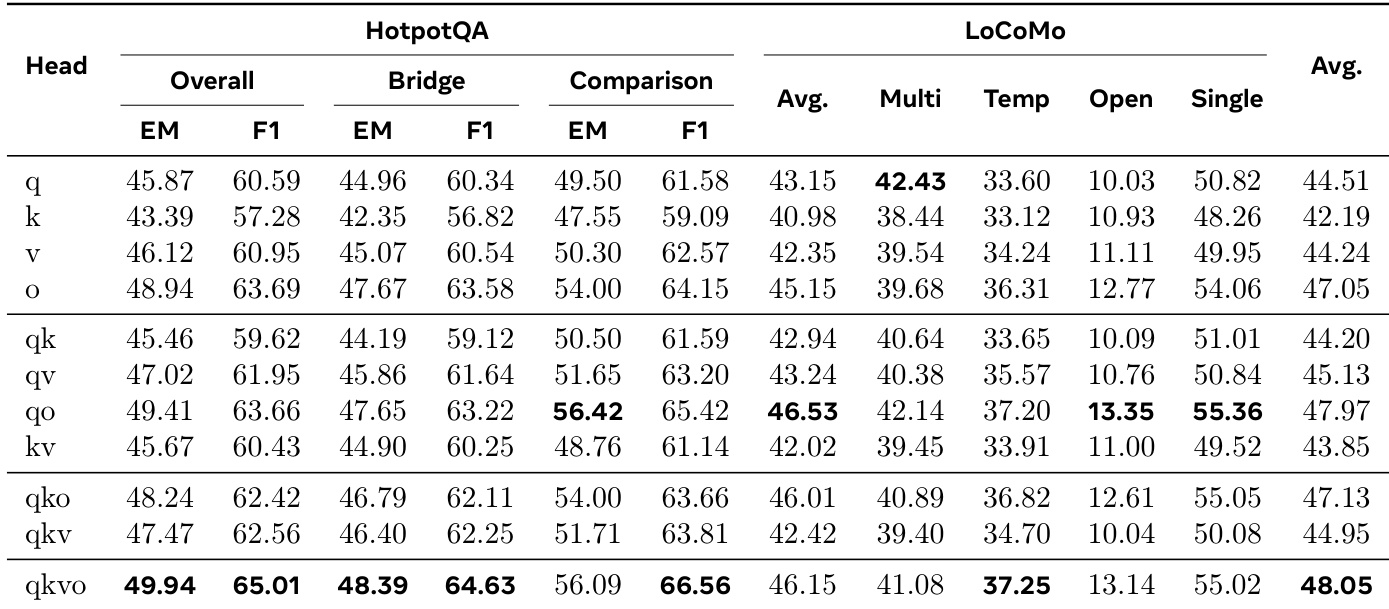
The authors analyze the impact of injecting memory corrections into different attention heads to determine the optimal interface for memory integration. Results indicate that while the output branch alone is the most effective single configuration, combining multiple heads yields superior performance, with the full set achieving the highest overall scores. The output branch performs best among single-head variants, significantly outperforming the key branch. The full configuration combining all heads achieves the highest overall average score and best performance on HotpotQA. Combining query and output heads provides strong results on memory-heavy benchmarks, offering a competitive alternative to the full configuration.
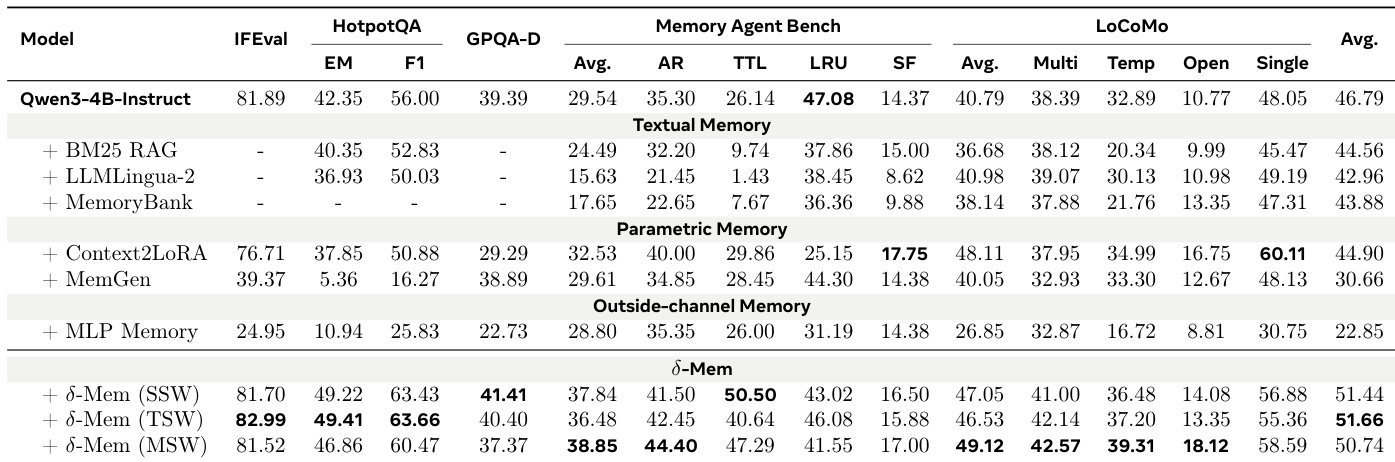
The authors evaluate a proposed memory mechanism against various baselines including textual retrieval and parametric adaptation methods on a Qwen3-4B-Instruct backbone. The results indicate that the proposed method consistently outperforms all other methods across general reasoning and memory-heavy benchmarks, particularly in tasks requiring long-term retention and retrieval. While baseline methods show inconsistent improvements or limitations in specific categories, the proposed approach demonstrates robust gains in overall average performance. The proposed method achieves the highest average performance scores compared to textual, parametric, and outside-channel memory baselines. Significant improvements are observed on memory-heavy benchmarks like LoCoMo and Memory Agent Bench where the model retains and utilizes information better. Variants of the proposed method generally outperform the base model and other memory mechanisms across instruction following and multi-hop reasoning tasks.
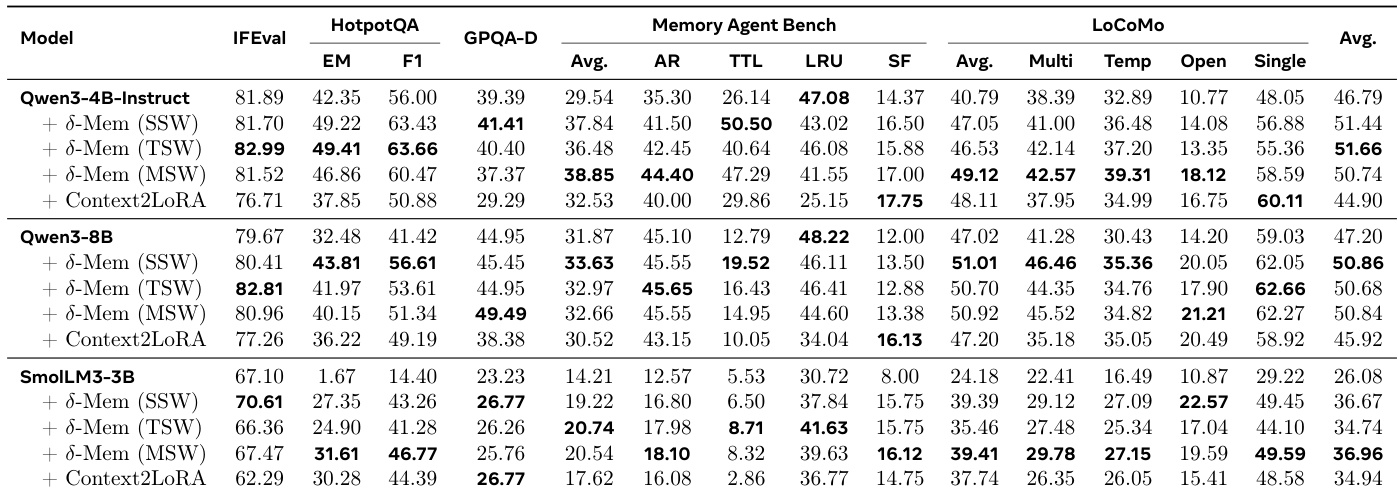
The authors evaluate their method, delta-mem, against baselines like Context2LoRA across three backbone models. Results indicate that delta-mem consistently outperforms the base models and the Context2LoRA baseline, with the most significant gains observed on memory-heavy benchmarks such as MemoryAgentBench and LoCoMo. Different writing strategies within delta-mem show varying effectiveness depending on model capacity, with TSW performing best on the 4B model and MSW driving substantial improvements on the smaller 3B model. delta-mem achieves the highest average scores across all tested backbone models compared to the base and Context2LoRA baselines. Performance gains are most pronounced on memory-heavy benchmarks like MemoryAgentBench and LoCoMo compared to general reasoning tasks. The optimal writing strategy varies by model size, with TSW leading on Qwen3-4B-Instruct and MSW providing the largest boost for SmolLM3-3B.
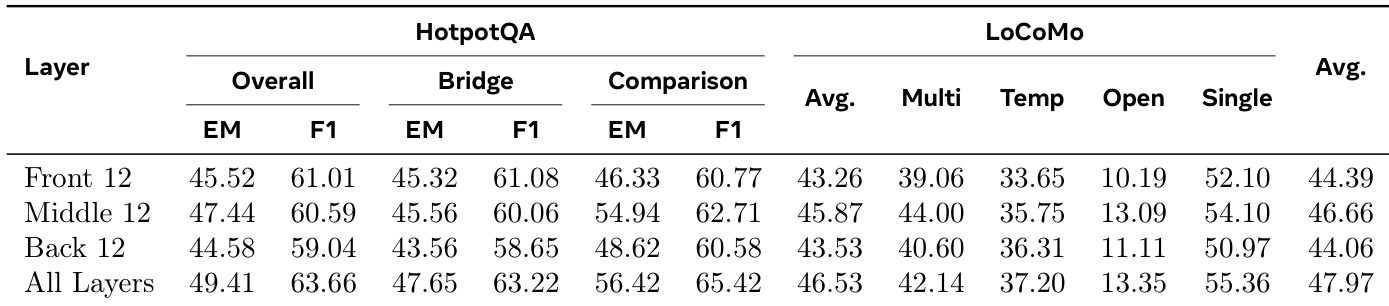
The authors evaluate the insertion depth of memory correction across different model layers to determine optimal placement. Results show that applying the mechanism to all layers achieves the strongest performance on both HotpotQA and LoCoMo benchmarks. Among partial configurations, the middle layers provide a more effective interface for memory injection than front or back layers. Applying memory correction to all layers achieves the best overall average and HotpotQA scores. The middle-layer configuration outperforms both front and back layer variants in average performance. Front and back layer injections result in lower scores compared to full-depth or middle-layer strategies.
The authors evaluate the optimal interface for memory integration by analyzing injection points across attention heads and model layers, finding that utilizing all components yields the strongest performance. Comparative studies against textual and parametric baselines show the proposed method consistently outperforms existing approaches, particularly in tasks requiring long-term retention. Furthermore, tests across different backbone models confirm robust improvements, with specific writing strategies proving more effective depending on model capacity.