Command Palette
Search for a command to run...
تمثيلات قائمة على النموذج خالية من التحيز للتحكم المستمر الفعال من حيث العينات
تمثيلات قائمة على النموذج خالية من التحيز للتحكم المستمر الفعال من حيث العينات
Jiafei Lyu Zichuan Lin Scott Fujimoto Kai Yang Yangkun Chen Saiyong Yang Zongqing Lu Deheng Ye
الملخص
العنوان:الاستنتاجات القائمة على النماذج: إطار عمل واعد للتعلم المعززالملخص:تبرز التمثيلات القائمة على النماذج (Model-based representations) مؤخرًا كإطار عمل واعد يدمج معلومات الديناميكيات الكامنة (latent dynamics) ضمن التمثيلات من أجل تعلم الممثل-الناقد (actor-critic) غير السياسي (off-policy) في المهام اللاحقة. يجمع هذا النهج بشكل ضمني بين مزاكل كل من الأساليب الخالية من النماذج (model-free) والأساليب القائمة على النماذج (model-based)، مع تجنب تكاليف التدريب المرتبطة بالطرق القائمة على النماذج. ومع ذلك، قد تفشل طرق التمثيل القائمة على النماذج الحالية في التقاط معلومات كافية حول المتغيرات ذات الصلة، وقد تعاني من الإفراط في التخصيص (overfitting) للتجارب المبكرة الموجودة في ذاكرة إعادة اللعب (replay buffer). وهذا يؤدي إلى تحيزات في التمثيل وفي تعلم الممثل-الناقد، مما ينتج عنه أداء دون المستوى المطلوب. ولمعالجة هذه المشكلة، نقترح تمثيلات قائمة على النماذج خالية من التحيز (Debiased) لتعلم Q، وهو خوارزمية تُعرف باسم DR.Q. تعمل خوارزمية DR.Q على تعظيم المعلومات المتبادلة (mutual information) بشكل صريح بين تمثيلات زوج الحالة-الإجراء الحالي والتمثيل للحالة التالية، بالإضافة إلى تقليل انحرافاتها، كما تقوم بأخذ عينات من الانتقالات باستخدام إعادة لعب الخبرة ذات الأولوية المتلاشية (faded prioritized experience replay). قمنا بتقييم خوارزمية DR.Q على مجموعة واسعة من معايير التحكم المستمر (continuous control benchmarks) باستخدام مجموعة واحدة من المعاملات الفائقة (hyperparameters)، وأظهرت النتائج أن DR.Q يمكنها مساواة أو تفوق الأسس القوية الحديثة، وأحيانًا تتفوق عليها بفارق كبير. يتوفر كودنا البرمجي على الرابط التالي: https://github.com/dmksjfl/DR.Q.
One-sentence Summary
DR.Q is a debiased model-based representation framework for sample-efficient continuous control that explicitly maximizes the mutual information between current state-action and next state representations while minimizing their deviations and employs faded prioritized experience replay to mitigate early-experience overfitting, ultimately matching or surpassing strong baselines across diverse continuous control benchmarks using a single hyperparameter configuration.
Key Contributions
- DR.Q is introduced as a debiased model-based representation framework for off-policy Q-learning that mitigates representation bias and early-experience overfitting inherent in existing dynamics-based methods.
- The algorithm explicitly maximizes the mutual information between current state-action and next-state representations while minimizing their deviations, and employs a faded prioritized experience replay mechanism to balance sample value and recency.
- Evaluations across multiple continuous control benchmarks demonstrate that the framework consistently matches or surpasses recent strong baselines using a single fixed hyperparameter configuration, with performance improvements sometimes exceeding them by a large margin.
Introduction
Model-based representation learning has emerged as a promising framework for off-policy reinforcement learning, embedding latent environmental dynamics into feature representations to boost sample efficiency while avoiding the steep training costs of full model-based planning. Prior approaches, however, typically minimize representation deviations and rely on standard experience replay, which fails to maximize mutual information between state-action and next-state features and introduces primacy bias by overfitting to early experiences. To overcome these challenges, the authors leverage DR.Q, an algorithm that explicitly maximizes mutual information alongside deviation minimization to ensure representations capture richer task-relevant information. They further introduce a faded prioritized experience replay strategy that downweights older transitions while prioritizing high-value new samples, ultimately enabling more stable and efficient actor-critic learning across continuous control benchmarks.
Dataset
The authors structure their evaluation around three continuous control benchmark suites, detailed below:
- Composition and Sources: The framework integrates Gym MuJoCo v4, the DMC suite, and HumanoidBench to cover standard locomotion, varied complexity manipulation, and high-dimensional humanoid tasks.
- Subset Specifications:
- Gym MuJoCo comprises five widely adopted locomotion environments with vector observations.
- The DMC suite contains 28 proprioceptive tasks categorized into DMC-Easy (21 tasks) and DMC-Hard (four dog and three humanoid tasks). Visual variants stack the previous three observations and resize them to 84 by 84 RGB frames.
- HumanoidBench includes 28 Unitree H1 locomotion tasks, divided into 14 environments without dexterous hands and 14 with integrated hands.
- Usage and Processing: The authors use these environments strictly for algorithm evaluation rather than training. All benchmarks are run for one million environment steps, with DMC and HumanoidBench achieving this through an action repeat of two. Return scores are normalized using random policy baselines combined with either TD3 reference scores or task success thresholds to ensure consistent cross-environment aggregation.
- Additional Processing Details: The authors construct metadata by recording random returns and reference success scores for each environment. Observation processing involves frame stacking and resizing for visual tasks, while proprioceptive tasks retain raw vector inputs. Action repetition is applied uniformly across DMC and HumanoidBench to align their effective rollout steps with the direct one million step evaluation used for MuJoCo.
Method
The DR.Q algorithm operates within a two-phase framework that decouples the learning of model-based representations from downstream policy and value function optimization. The overall architecture, as illustrated in the figure, begins with a replay buffer that stores transitions (s,a,r,s′,d). These transitions are sampled using a faded prioritized experience replay mechanism that combines prioritization based on TD error with an exponential decay of sampling probability for older transitions, ensuring a balance between focusing on recent, high-error experiences and avoiding overfitting to outdated ones.
The sampled transitions are processed through two primary encoders: a state encoder f and a state-action encoder g. The state encoder maps the raw state s to a latent state representation zs=f(s), while the state-action encoder takes the state representation zs and the action a to produce a state-action representation zsa=g(zs,a). This state-action representation is then used by a linear MDP predictor to forecast the next state representation z^s′ and the reward r^. The next state representation z~s′ is derived from the target state encoder network, which is periodically updated for stability. The encoder training objective is composed of three components: a reward loss, a latent dynamics consistency loss, and a mutual information loss. The reward loss is computed using cross entropy on a two-hot encoding of the reward. The latent dynamics consistency loss minimizes the MSE between the predicted z^s′ and the target z~s′. The mutual information loss, a key innovation, is implemented via the InfoNCE loss to maximize the mutual information between zsa and z~s′, ensuring the representations are not only numerically close but also informationally rich.
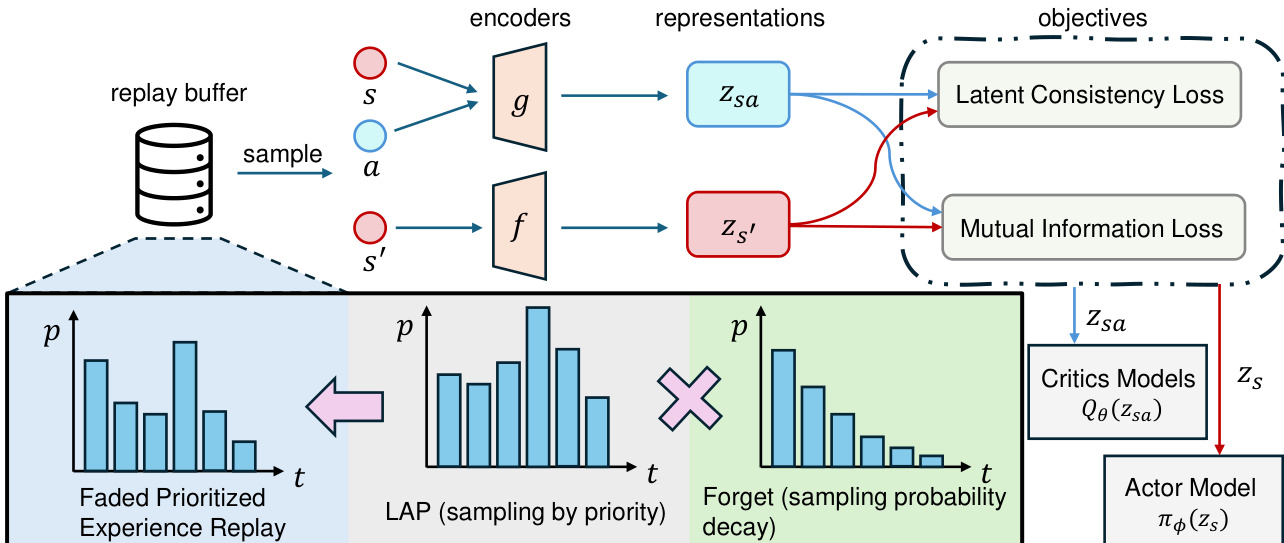
Experiment
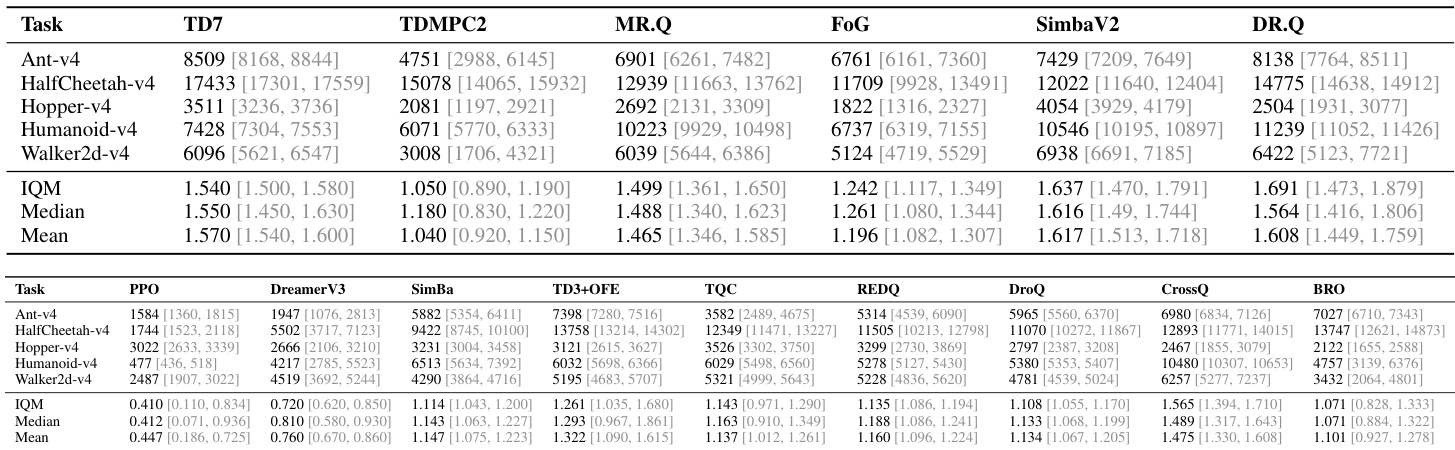
The evaluation of DR.Q spans 73 tasks across MuJoCo, DMC suite, and HumanoidBench benchmarks, employing a single fixed hyperparameter configuration to test its generalizability against leading model-free and model-based baselines. Main experiments demonstrate that the method consistently achieves superior sample efficiency and asymptotic performance across diverse continuous control domains, particularly excelling in high-dimensional and visual tasks. Ablation studies further validate its core architectural choices, revealing that the InfoNCE and latent dynamics objectives produce more structured and robust state representations, while the faded prioritized experience replay strategy effectively prioritizes recent high-error transitions without over-relying on outdated data. Collectively, these findings confirm that DR.Q provides a highly effective and general-purpose framework for representation learning in complex reinforcement learning environments.
The authors compare DR.Q against a range of strong baselines across multiple continuous control benchmarks, including MuJoCo, DMC, and HumanoidBench, using normalized performance metrics. Results show that DR.Q consistently outperforms or matches leading methods, particularly on challenging tasks, with notable improvements over MR.Q and SimBaV2. The analysis includes ablation studies that highlight the importance of key components such as the InfoNCE loss and faded prioritized experience replay. DR.Q achieves superior performance compared to strong baselines like MR.Q and SimBaV2 across diverse benchmarks, especially on complex tasks. The InfoNCE loss and faded PER sampling strategy are critical to DR.Q's performance, as removing either component leads to significant degradation. DR.Q learns more structured and informative representations than MR.Q, as evidenced by visualization results and improved robustness to redundant state inputs.
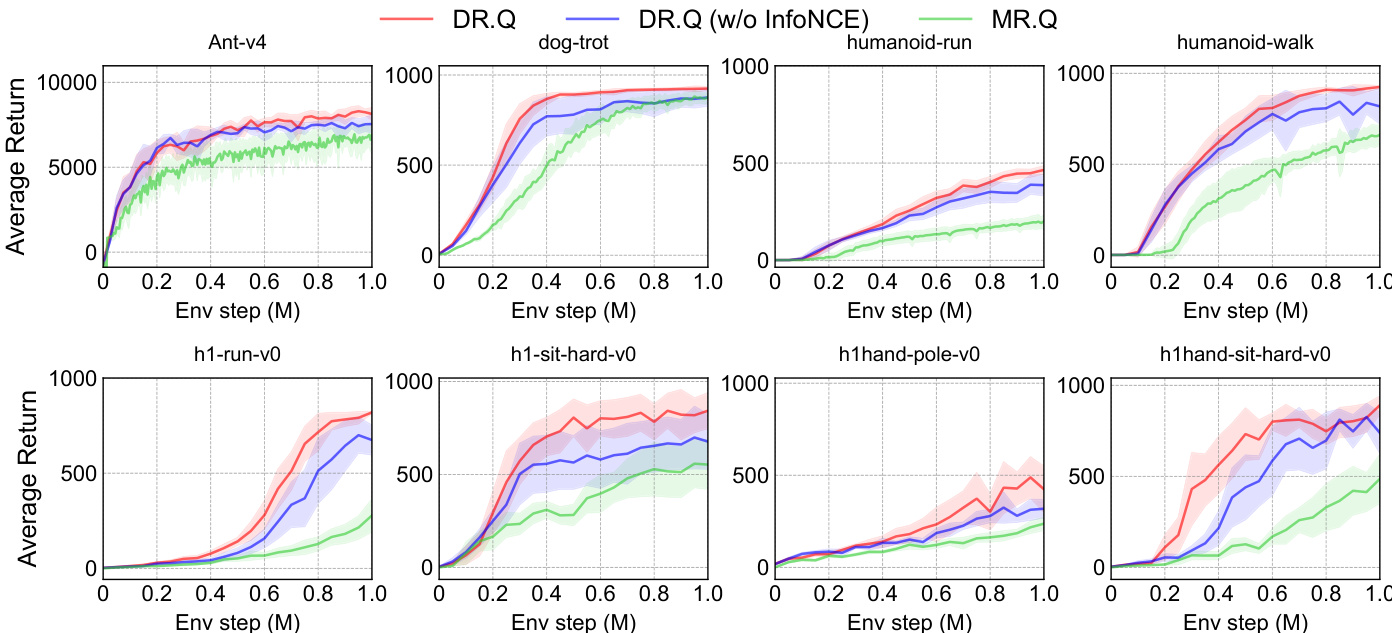
The authors compare DR.Q against variants and baselines across multiple continuous control tasks, demonstrating that DR.Q achieves higher average returns and better sample efficiency than its competitors, particularly on challenging tasks. The results show that removing key components like the InfoNCE loss or the faded PER sampling strategy leads to performance degradation, indicating their importance for robust learning. DR.Q consistently outperforms baselines like MR.Q and SimBaV2 across diverse tasks, especially on high-dimensional and complex environments. The InfoNCE loss is crucial for learning effective representations, particularly on tasks with redundant information such as those involving dexterous hands. Faded PER improves sample efficiency by prioritizing recent, high-impact experiences while reducing the influence of outdated data.
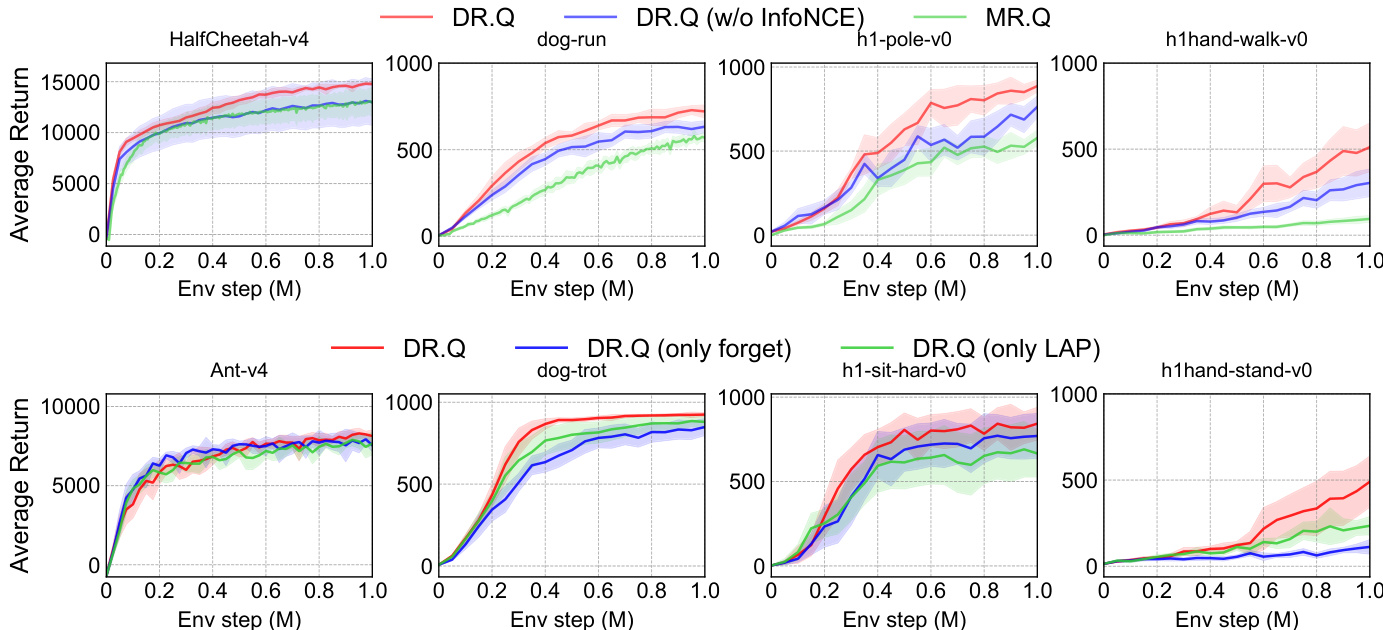
The authors conduct ablation studies to evaluate the impact of key design choices in DR.Q, including the InfoNCE loss and the faded prioritized experience replay (PER) mechanism. Results show that removing the InfoNCE loss leads to inferior performance, particularly on high-dimensional tasks, while omitting either the forget mechanism or the LAP component in faded PER degrades both performance and sample efficiency. The full DR.Q model consistently outperforms its variants across all tested environments. Removing the InfoNCE loss significantly reduces performance, especially on complex tasks with high-dimensional state spaces. The faded PER mechanism, combining both the forget mechanism and LAP, is essential for optimal performance and sample efficiency. DR.Q consistently outperforms its variants across all evaluated tasks, indicating the importance of both the InfoNCE loss and faded PER.
The authors compare DR.Q against several baselines, including MR.Q and TDMPC2, across multiple visual control tasks from the DMC suite. Results show that DR.Q achieves higher average returns and faster learning curves than the baselines on most tasks, particularly excelling in visual-dog-run and visual-hopper-stand. The performance of DR.Q is consistently superior to MR.Q and TDMPC2 in both sample efficiency and final performance, indicating the effectiveness of its design choices. DR.Q achieves higher average returns than MR.Q and TDMPC2 across most visual control tasks. DR.Q demonstrates faster learning and better sample efficiency, especially on challenging tasks like visual-dog-run and visual-hopper-stand. DR.Q consistently outperforms MR.Q, indicating the effectiveness of its additional design components.
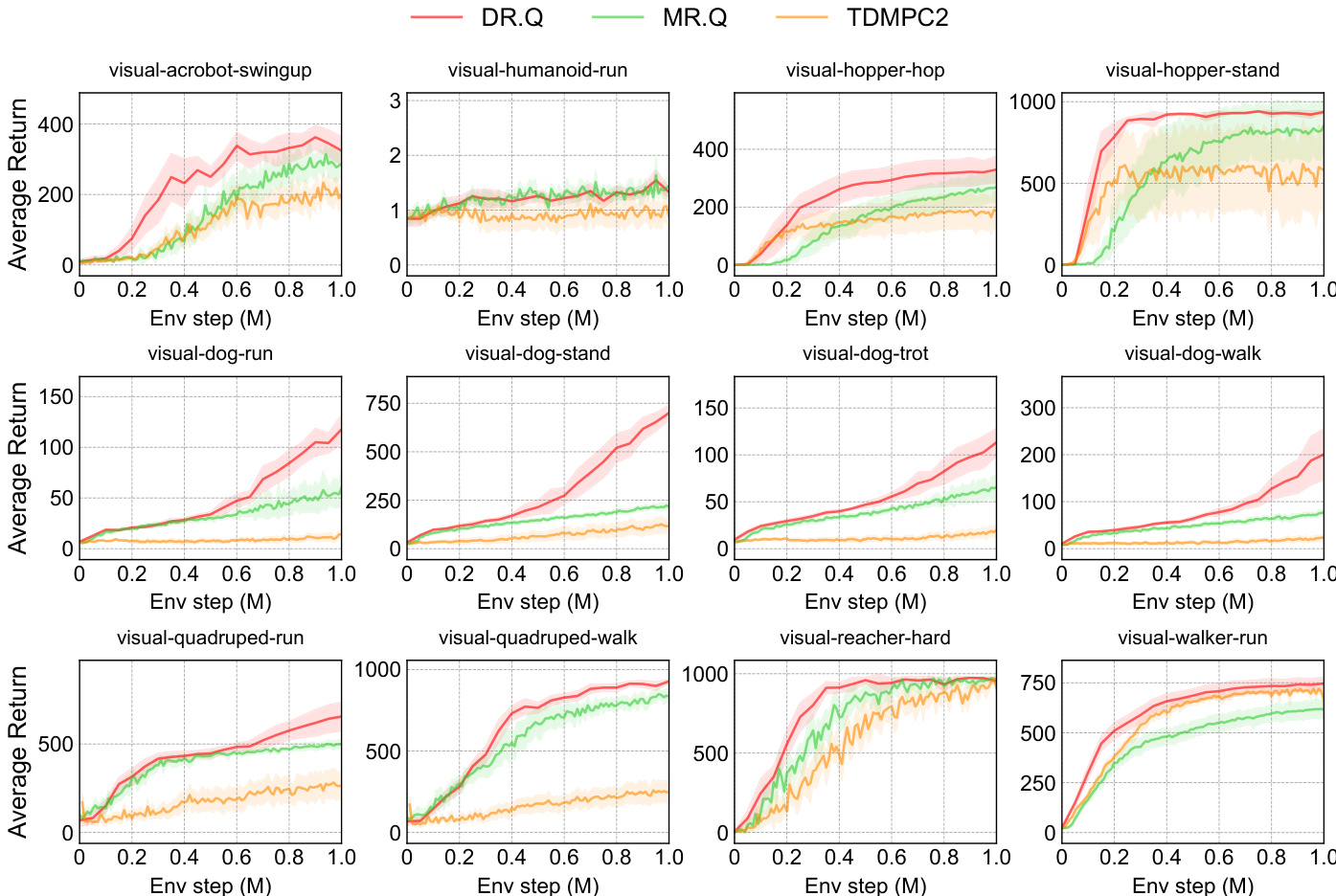
The authors evaluate DR.Q across multiple continuous control benchmarks, comparing its performance against a range of model-free and model-based baselines. Results show that DR.Q consistently matches or exceeds the performance of leading methods, particularly on challenging tasks, and demonstrates superior sample efficiency. The effectiveness of DR.Q's key components, including the InfoNCE loss and faded prioritized experience replay, is validated through ablation studies. DR.Q achieves competitive or superior performance compared to strong baselines across diverse continuous control tasks, including those with high-dimensional state spaces. The InfoNCE loss and faded prioritized experience replay are critical components, as their removal leads to significant performance degradation on challenging tasks. DR.Q demonstrates better sample efficiency than several baselines, often surpassing them by a large margin, especially in complex environments.
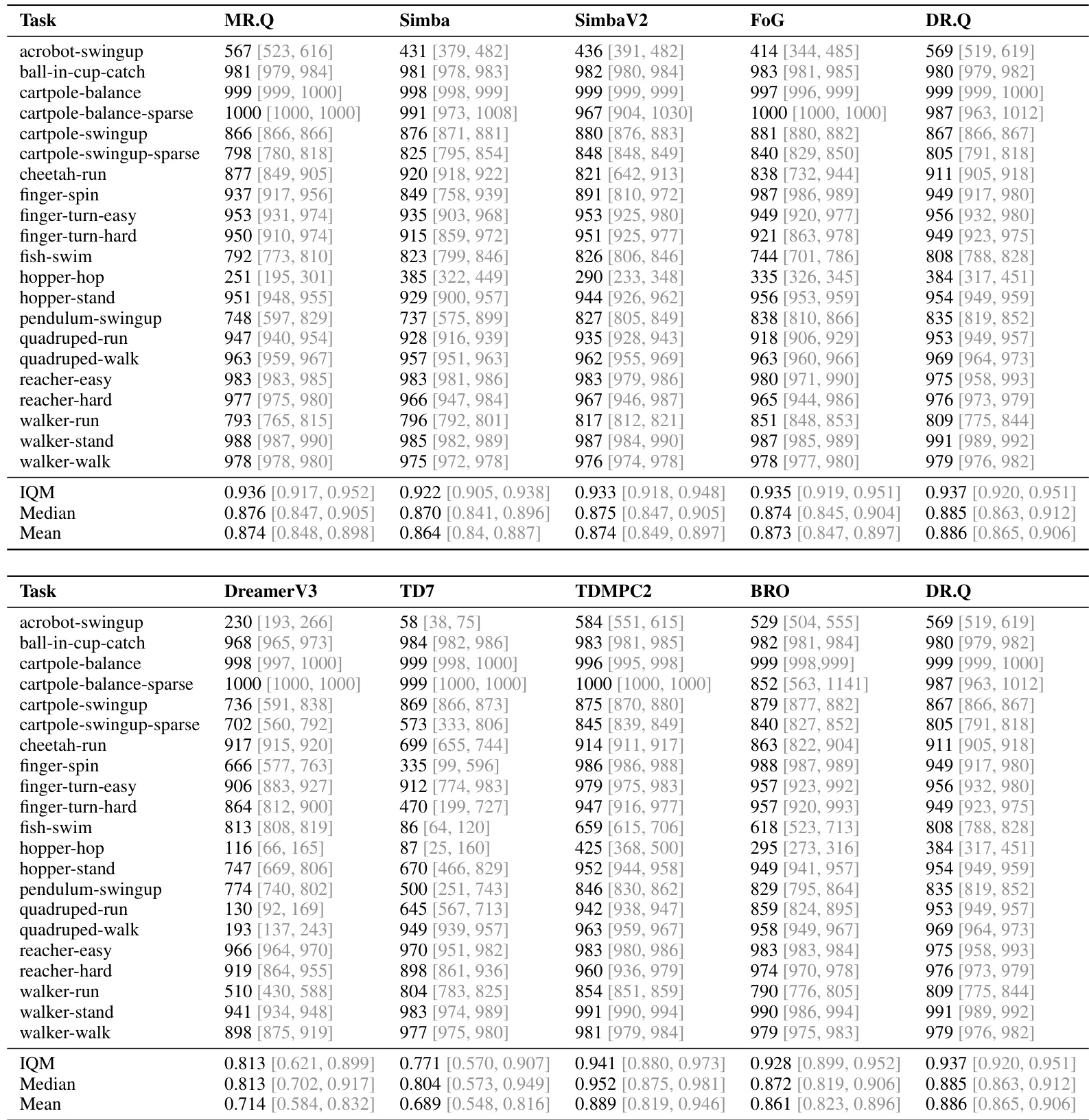
The authors evaluate DR.Q against a range of model-free and model-based baselines across multiple continuous and visual control benchmarks, including MuJoCo, DMC, and HumanoidBench. Main experiments demonstrate that the proposed method consistently matches or exceeds leading approaches in both task performance and sample efficiency, particularly on complex and high-dimensional environments. Ablation studies further validate that the InfoNCE loss and faded prioritized experience replay are critical design choices, as removing either component significantly impairs learning stability and representation quality. Overall, the findings confirm that DR.Q successfully learns structured state representations and maintains robust learning dynamics even when processing redundant environmental information.