Command Palette
Search for a command to run...
الشطرح والتجزئة: إعداد الخلائط المثلى من الخبراء
الشطرح والتجزئة: إعداد الخلائط المثلى من الخبراء
Margaret Li Sneha Kudugunta Danielle Rothermel Luke Zettlemoyer
الملخص
لطالما أصبحت معماريات مزيج الخبراء (Mixture-of-Experts) المعيار المعتمد في نماذج اللغات الكبيرة (LLMs)، غير أن العديد من خيارات التصميم الأساسية فيها – مثل عدد الخبراء، ودقة التجميع (granularity)، والخبراء المشتركة، وآليات توازن الحمل، واستقطاع الرموز (token dropping) – لم تخضع إلا لدراسات تفحص واحداً أو اثنين منها في كل مرة، وعلى نطاقات تكوينية ضيقة. ولا يزال من المسائل المفتوحة ما إذا كان بإمكاننا تحسين هذه الخيارات بشكل مستقل، دون مراعاة التفاعلات فيما بينها.نقدم في هذه الورقة الدراسة المنهجية الأولى التي تشمل أكثر من 2000 عملية تدريب أولي (pretraining)، تغطي نماذج تصل إلى 6.6 مليار معلمة إجمالاً، حيث قمنا بتغيير شامل ومنهجي للعدد الكلي للخبراء، وأبعاد الخبراء، وعدم تجانس أحجام الخبراء داخل الطبقة الواحدة، وحجم الخبراء المشترك، وآليات موازنة الحمل.وأظهرت نتائجنا أنه عند كل نطاق للحجم الفعال للمعلمة (active-parameter scale) درسناه، تحسنت الأداء باستمرار مع زيادة إجمالي معاملات MoE، حتى عند النسب القصوى لمعاملات الخبراء الفعالة مثل 128. وعلاوة على ذلك، تبين أن الحجم الأمثل للخبير يكاد يكون مستقلاً عن العدد الكلي للمعاملات، ويعتمد فقط على عدد المعاملات الفعالة. وثالثاً، لاحظنا أن خيارات أخرى مثل الخبراء المشتركين، والخبراء غير المتجانسين، وإعدادات موازنة الحمل كان لها تأثير ضئيل نسبياً مقارنة بعدد الخبراء ودقة التجميع، على الرغم من أن التوجيه الخالي من الاستقطاع (dropless routing) يحقق ربحاً ثابتاً في الأداء.باختصار، تقترح نتائجنا وصفة أبسط تتمثل في التركيز على عدد الخبراء ودقة التجميع، نظراً لأن الخيارات الأخرى يكون لها تأثير ضئيل على الجودة النهائية.
One-sentence Summary
The authors present the first systematic study of over 2,000 pretraining runs spanning models up to 6.6B total parameters to configure optimal Mixtures of Experts, revealing that performance consistently improves with total MoE parameters while optimal expert size depends only on active parameter count, suggesting a simpler recipe focused on expert count and granularity.
Key Contributions
- The paper disentangles expert count from granularity by varying both separately under a fixed compute budget to measure the independent impact of expert size and count. Over 2,000 experiments ranging from 10 million to 6.6 billion total parameters show that performance improves monotonically with total MoE parameters.
- Tests on heterogeneous expert pools and shared generalist experts demonstrate that these flexibility options offer little improvement over a well-configured homogeneous MoE model. Results indicate that neither mixed granularities within a layer nor generalist experts improve performance, with generalists consistently hurting quality.
- Analysis of the routing design space reveals that MoE quality is robust to load-balancing hyperparameters within reasonable ranges. Experiments further show that dropless routing yields a small but consistent gain compared to other routing settings.
Introduction
Mixture of Experts architectures are now standard in large language models because they decouple computational overhead from model capacity, yet prior work has typically evaluated core design choices like expert count and granularity in isolation. This fragmented analysis leaves uncertainty about whether these parameters can be optimized independently without considering their interactions. The authors address this gap by conducting a systematic study of over 2,000 pretraining runs spanning models up to 6.6 billion parameters to disentangle the impact of expert count from granularity. Their results indicate that performance improves monotonically with total MoE parameters and that optimal expert size depends solely on active parameter count. Consequently, the authors recommend prioritizing expert count and granularity while noting that shared experts and complex routing adjustments yield minimal gains.
Dataset
- Training Data Composition: The authors utilize training data from Muennighoff et al. (2025), aggregating documents from DCLM-Baseline, StarCoder, peS2o, arXiv, OpenWebMath, Algebraic Stack, and English Wikipedia & Wikibooks.
- Training Scale: Each model adheres to a token-to-active-parameter ratio of roughly 20. This implies a 1 billion active parameter model trains on approximately 20 billion tokens.
- Evaluation Language Modeling: The evaluation suite includes held-out language modeling tasks sourced from Paloma. Specific subsets include C4, THE PILE, WIKITEXT-103, M2D2 S2ORC, ICE, and DOLMA.
- DOLMA Subdomains: The DOLMA component is divided into six domains: books, common-crawl, pes2o, reddit_uniform, stack_uniform, and wiki.
- Downstream Benchmarks: Downstream tasks consist of BoolQ, HellaSwag, and MMLU. MMLU is subdivided into humanities, STEM, social sciences, and other domains.
- Metrics: For language modeling tasks, the team computes and reports the macro-average cross-entropy loss.
Method
The authors leverage a Mixture of Experts (MoE) architecture where standard feed-forward network (FFN) modules within Transformer layers are replaced by conditionally activated submodules. In this design, each token first passes through a shared self-attention mechanism. Subsequently, router mechanisms activate specific experts based on affinity scores, and the outputs of these activated FFN modules are combined via a weighted sum.
Refer to the framework diagram below for a visual representation of this MoE layer structure.
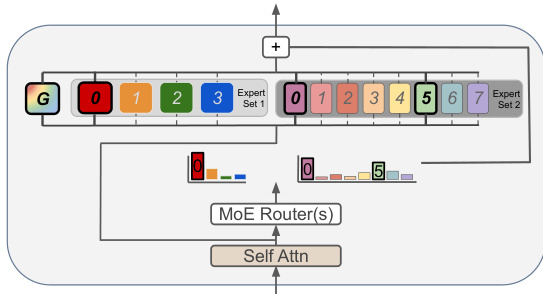
The architecture introduces flexible configurations that move beyond homogeneous expert sizing. A standard homogeneous MoE layer typically includes n experts of identical granularity g, where k experts are activated. Granularity is defined as the ratio of the intermediate dimension of the expert FFN to that of a dense FFN. However, this framework supports heterogeneous MoE layers consisting of experts with different granularities. As illustrated in the diagram, distinct Expert Sets (labeled Expert Set 1 and Expert Set 2) can contain experts of varying sizes, allowing the model to group learned functions more efficiently. Additionally, an always-active generalist expert (labeled 'G') can be included, which processes all inputs and has its output combined with the routed experts.
To ensure fair performance comparisons, the active expert count is often constrained to fix the number of activated parameters relative to a dense model. This relationship is maintained such that the number of active experts multiplied by the expert granularity equals 1. This ensures that FLOPs per step remain consistent across different configurations.
The routing mechanism typically employs token-choice routing, where the router selects the k experts with the highest affinity values for each token. To prevent the router from over-relying on a small subset of experts, load balancing mechanisms are employed. An auxiliary loss function can be added to the primary cross-entropy loss to penalize imbalanced loads. Alternatively, a loss-free mechanism adjusts per-expert biases during training to encourage balanced routing. Furthermore, dropless routing is utilized to handle capacity constraints. Instead of dropping overflow tokens or routing them to a default expert, block-sparsity ensures that all tokens are processed, maintaining computational efficiency without losing information.
Experiment
This research evaluates Mixture of Experts architectures by systematically varying expert granularity, total count, and activation sparsity while FLOP-matching active parameters against dense baselines across multiple model scales. Findings demonstrate that performance gains stem from maximizing total inactive expert parameters and utilizing dropless routing, whereas architectural heterogeneity and generalist experts yield no benefits or degrade performance. The study further identifies a compute threshold below which MoEs underperform dense models unless data budgets are increased, and notes that load balancing hyperparameters require tuning at high expert counts to prevent interference.
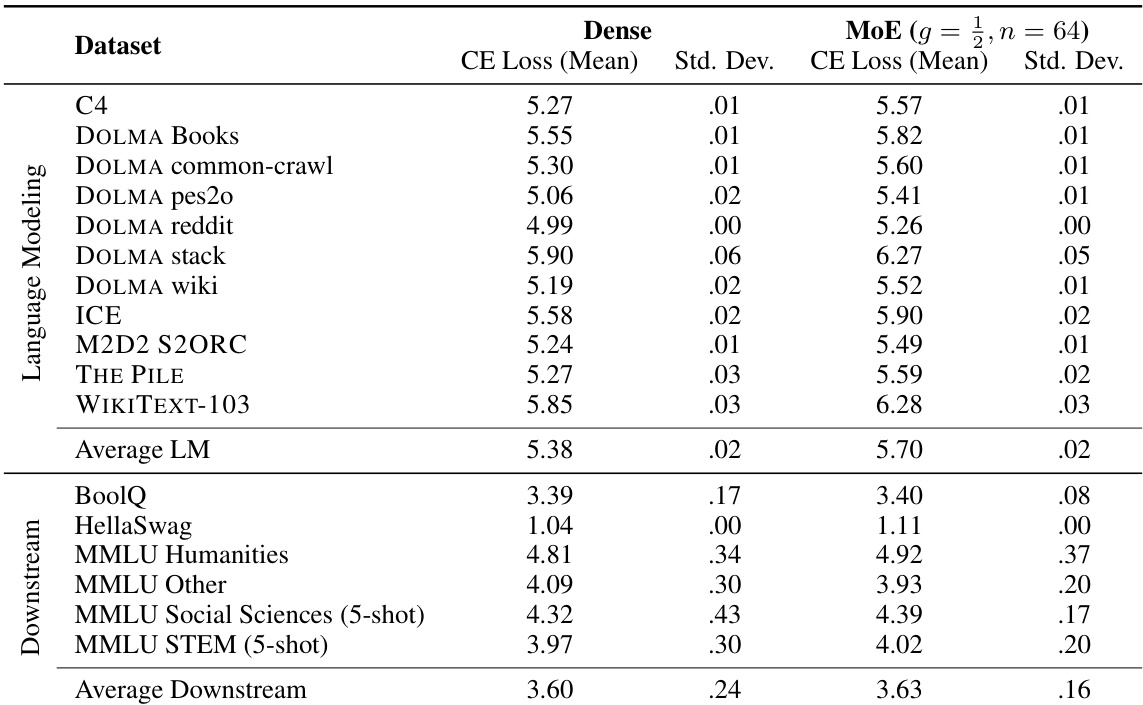
The experiment evaluates a Mixture of Experts configuration against a Dense baseline across multiple language modeling and downstream datasets. In this specific setup, the Dense model demonstrates superior performance with lower average cross-entropy loss compared to the MoE variant. These results align with findings that MoE architectures may not outperform dense baselines at smaller model scales or specific configurations. The Dense model achieves a lower average cross-entropy loss on language modeling tasks than the MoE configuration. Downstream task evaluation indicates the Dense model outperforms the MoE variant in terms of average loss. The MoE configuration generally produces higher loss values across individual datasets, with few exceptions.
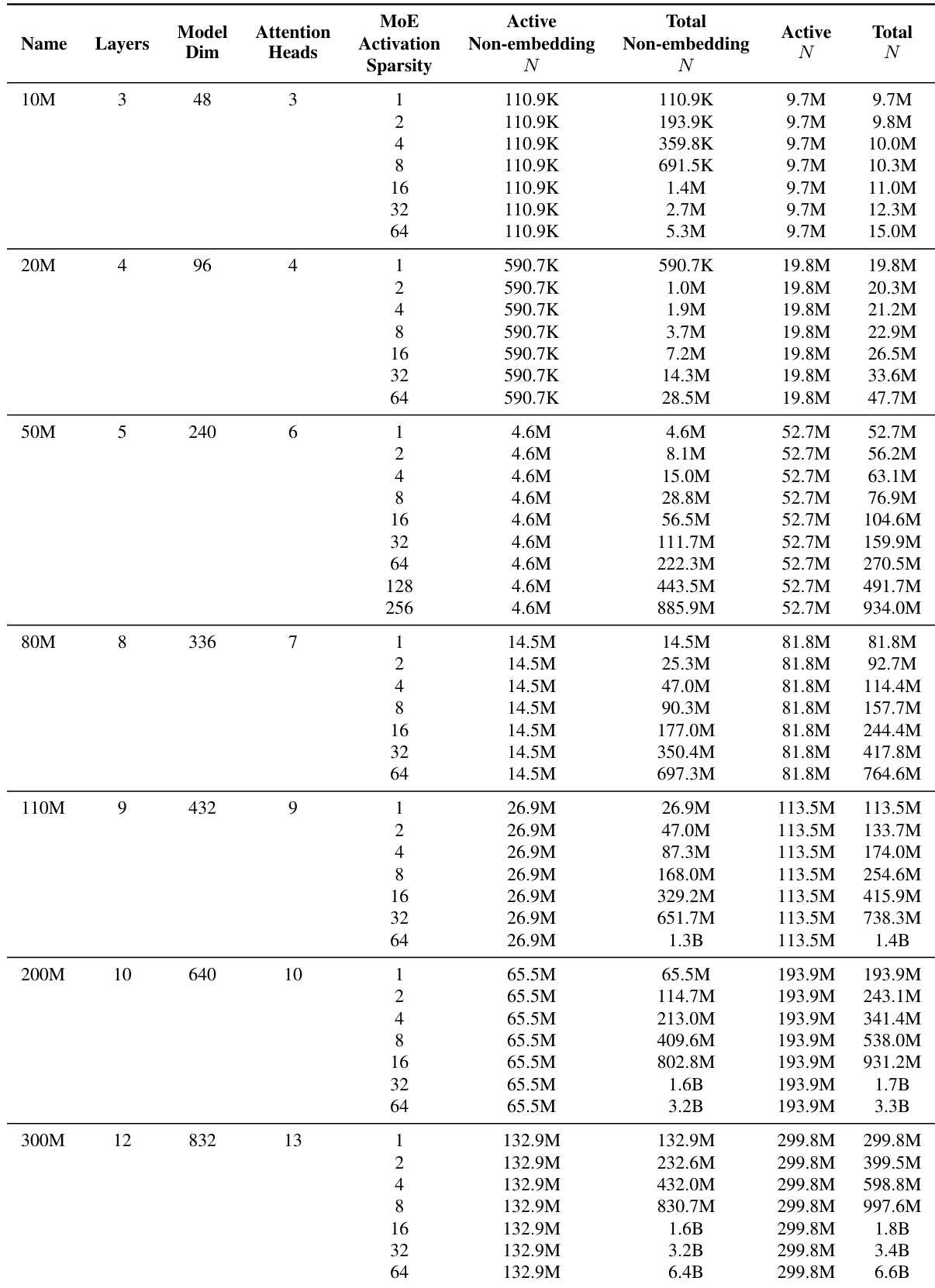
The the the table details the architectural specifications for Mixture of Experts models across several active parameter scales. It demonstrates that while active parameter counts remain fixed for FLOP matching, total parameter counts expand as MoE activation sparsity increases. This variation allows for the analysis of how total expert capacity influences model performance. Active parameter counts remain consistent within each model group regardless of the MoE activation sparsity setting. Total parameter counts grow substantially as MoE activation sparsity increases, indicating a larger pool of inactive experts. Larger model scales are associated with increased model dimensions, attention heads, and layer counts.
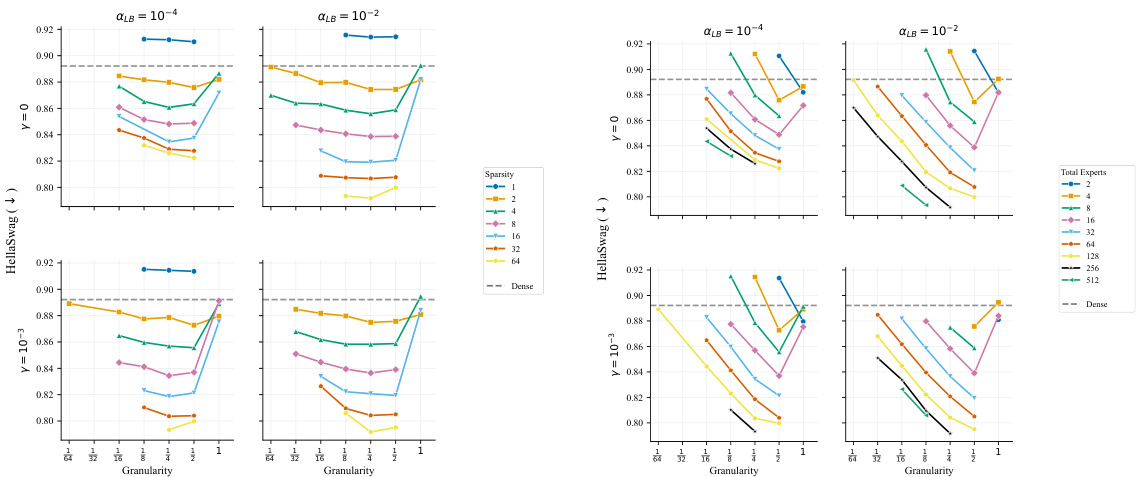
The authors investigate load balancing mechanisms and expert configurations in Mixture of Experts models. Results indicate that load balancing settings have minimal impact for models with up to 512 experts, although high bias values can impair performance at larger scales. Performance varies with granularity and total expert count, with MoE configurations generally matching or exceeding dense baseline performance. Load balancing hyperparameters show minimal impact for up to 512 experts, but high bias can impair performance at larger scales. Performance varies with granularity and total expert count, with optimal configurations depending on model size. Mixture of Experts configurations generally match or exceed dense baseline performance across the tested settings.
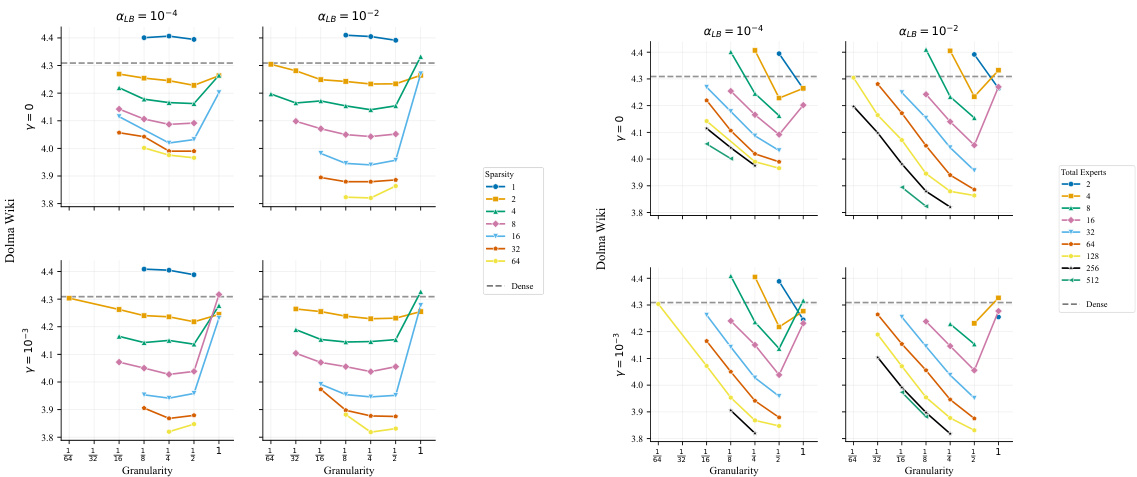
The authors investigate the impact of load balancing loss weights and loss-free bias on Mixture of Experts performance across various expert configurations. They find that while a wide range of hyperparameter settings achieve near-optimal results, specific combinations involving high bias and a large number of experts significantly degrade performance. This indicates that load balancing mechanisms must be tuned carefully to avoid interference with the language modeling objective. Most load balancing settings yield comparable performance for models with up to 512 experts. High bias settings impair performance when the total number of experts is large. Low loss weights without bias result in higher load imbalance and worse performance.
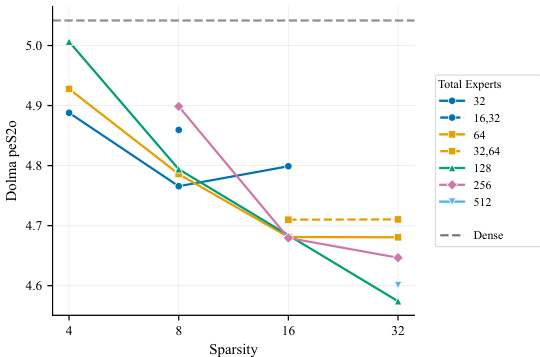
The chart displays the performance of Mixture of Experts models on the Dolma ps2o dataset across varying sparsity levels and total expert counts. Results indicate that MoE configurations generally outperform the dense baseline, with performance improving as sparsity increases and the total number of experts grows. Increasing the total count of experts consistently leads to better outcomes, supporting the finding that maximizing inactive expert parameters is beneficial. MoE models outperform the dense baseline at higher sparsity levels. Configurations with a larger total number of experts achieve better performance than those with fewer experts. Heterogeneous expert setups do not provide significant advantages over homogeneous configurations.
This evaluation compares Mixture of Experts configurations against Dense baselines across language modeling and downstream datasets to assess the impact of architectural scaling and sparsity. Results indicate that while Dense models demonstrate superior performance at smaller scales, MoE architectures match or exceed baseline results when total parameter counts increase through higher sparsity and larger expert pools. Additionally, load balancing mechanisms generally show minimal impact for models with moderate expert counts, though high bias settings can significantly degrade performance in configurations with a large number of experts.