Command Palette
Search for a command to run...
PaperFit: تحسين تنسيق المستندات العلمية باستخدام الرؤية ضمن الحلقة
PaperFit: تحسين تنسيق المستندات العلمية باستخدام الرؤية ضمن الحلقة
Bihui Yu Xinglong Xu Junjie Jiang Jiabei Cheng Caijun Jia Siyuan Li Conghui He Jingxuan Wei Cheng Tan
الملخص
إن مخطوطة لاتك التي تُجمع دون حدوث أخطاء ليست بالضرورة جاهزة للنشر. غالباً ما تعاني ملفات الـ PDF الناتجة عن وجود عناصر مرسومة (floats) غير موضعها، ومعادلات تفيض عن الحواشي، وعدم اتساق في مقياس الجداول، وخطوطٍ متروكة (widow/orphan lines)، وتوازنٍ ضعيف للصفحات، مما يضطر المؤلفين إلى الدخول في دورات متكررة من التجميع، والفحص، والتعديل. تعتمد الأدوات القائمة على القواعد (Rule-based tools) على شفرة المصدر وملفات السجل فقط، وهي عمياء عن التصور المرئي النهائي. كما تقوم نماذج اللغات الكبيرة النصية (LLMs) بإجراء تعديلات نصية مفتوحة الحلقة (open-loop)، دون القدرة على التنبؤ أو التحقق من التداعيات ثنائية الأبعاد لتخطيط الصفحة الناتجة عن تغييراتها. لذلك، يتطلب التحسين الموثوق للتصميم الطباعي حلقة مغلقة بصرية مع التحقق من الصحة بعد كل عملية تعديل.نصيغ هذه المشكلة تحت مسمى "التحسين الطباعي البصري" (Visual Typesetting Optimization - VTO)، وهي مهمة تحويل ورقة لاتك قابلة للتجميع إلى ملف PDF متقن بصرياً ومتوافق مع ميزانية الصفحات، من خلال التحقق البصري التكراري والتعديل على مستوى المصدر. كما نقدم تصنيفاً مكوناً من خمس فئات لعيوب الطباعة يهدف إلى توجيه عملية التشخيص. نقدم أيضاً "PaperFit"، وهو وكيل (agent) يعتمد على الرؤية ضمن الحلقة (vision-in-the-loop)، يقوم بشكل تكراري برصف الصفحات، وتشخيص العيوب، وتطبيق إصلاحات مقيدة.ولتقييم VTO، قمنا ببناء "PaperFit-Bench"، وهو مجموعة تقييم تتضمن 200 ورقة بحثية موزعة على 10 قوالب لفعاليات نشر مختلفة و13 نوعاً من العيوب بمستويات صعوبة متباينة. تظهر التجارب الواسعة أن "PaperFit" يتفوق بوضوح كبير على جميع الطرق الأساسية (baselines)، مما يؤكد أن سد الفجوة بين المصدر القابل للتجميع وملف PDF الجاهز للنشر يتطلب تحسيناً يعتمد على الرؤية ضمن الحلقة (vision-in-the-loop)، وأن VTO يمثل مرحلة حرجة مفقودة في سلسلة أتمتة المستندات.
One-sentence Summary
PaperFit is a vision-in-the-loop agent that iteratively renders LaTeX manuscripts to diagnose and repair layout defects, outperforming all baselines on PaperFit-Bench, a benchmark of 200 papers across 10 templates and 13 defect types, by formalizing Visual Typesetting Optimization as a visually verified pipeline stage that transforms compilable source code into publication-ready PDFs.
Key Contributions
- Formalizes Visual Typesetting Optimization (VTO) as a dedicated task and introduces a five-category taxonomy of typesetting defects to guide layout diagnosis.
- Introduces PaperFit, a vision-in-the-loop agent that iteratively renders pages, diagnoses defects, and applies constrained source-level repairs to generate publication-ready PDFs.
- Constructs PaperFit-Bench, a benchmark of 200 papers across 10 venue templates and 13 defect types, and demonstrates through extensive experiments that the agent outperforms all baseline methods by a large margin.
Introduction
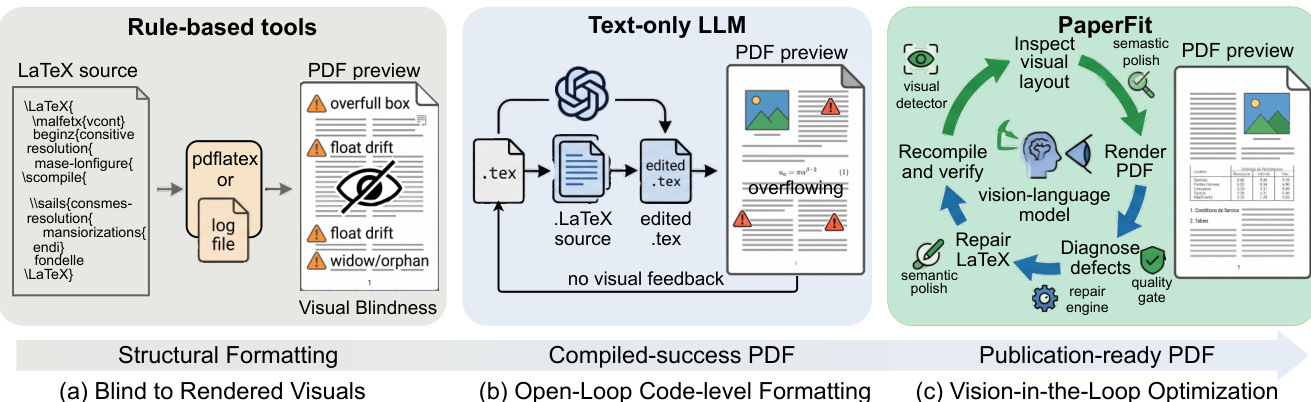
Generating publication-ready PDFs from LaTeX remains a persistent bottleneck in academic publishing, as compilable source code frequently produces layout defects like overflowing equations, misaligned floats, and uneven page balance. Prior automation efforts fall short because rule-based tools remain blind to rendered visuals, text-only language models operate in an open loop without predicting spatial consequences, and existing document understanding systems treat successful compilation as the final milestone rather than a starting point. To close this gap, the authors formalize Visual Typesetting Optimization and introduce PaperFit, a vision-in-the-loop agent that iteratively renders pages, diagnoses defects against a structured taxonomy, and applies constrained source-level repairs. By establishing a closed-loop verification pipeline and a comprehensive benchmark, the authors demonstrate that continuous visual feedback is essential for reliably transforming raw LaTeX manuscripts into polished, publication-ready documents.
Dataset
Dataset Composition and Sources
- The authors introduced PaperFit-Bench, a benchmark containing 200 LaTeX instances sourced from arXiv across artificial intelligence subfields including natural language processing, computer vision, and reinforcement learning.
- The collection spans 10 academic venue templates, covering both single- and double-column formats with page limits ranging from 7 to 14 pages.
- Each paper averages 6.3 figures and 5.3 tables, providing high floating-element density to thoroughly exercise layout repair capabilities.
Subset Details and Difficulty Tiers
- Instances are organized into three empirical difficulty levels based on co-occurring perturbations: Easy (1 to 2), Medium (3 to 4), and Hard (5 to 8), distributed in a 3:4:3 ratio.
- Perturbations are grouped into five defect categories aligned with visual typesetting failure modes: space utilization (Class A), float placement (Class B), table width (Class C), overflow (Class D), and cross-template migration (Class E).
- The authors note that harder instances increasingly combine cross-template migration with other layout stressors, while easier cases may still present nontrivial local table or float issues.
Data Processing and Usage
- The preprocessing pipeline removes appendices and filters out samples that fail compilation or depend on private macro packages.
- A dual quality-control mechanism ensures every retained instance contains at least three figures and two tables.
- The authors use this dataset strictly for evaluation rather than model training. Each benchmark entry pairs a systematically perturbed LaTeX source with its original compilable version as ground truth, enabling deterministic visual layout restoration testing.
- The benchmark emphasizes mixed-disturbance scenarios over isolated single-defect examples to better reflect real-world typesetting optimization challenges.
Metadata Construction and Finalization
- The authors generate comprehensive metadata for each instance, including a disturbance manifest that records both the intended perturbation and its exact source-level implementation.
- This documentation layer captures how identical high-level defects can arise from different LaTeX code structures, allowing the evaluation to treat the manifest as the source of intent and the rendered output as evidence of failure.
- Final instances undergo standardized compilation testing and visual verification to confirm that perturbations successfully materialize in the layout before the benchmark is finalized.
Method
The authors leverage a vision-in-the-loop optimization framework for visual typesetting, structured as an iterative, evidence-driven search that integrates multiple sources of diagnostic information to guide constrained repairs. The overall pipeline begins with an input LaTeX project xt, a target template τ, and an optional page budget b. The system first compiles and renders the document to produce a PDF Pt and rendered page images It, along with a compilation log ℓt. From this output, four complementary evidence layers are extracted: the source layer (.tex) provides structural information including document hierarchy, macro definitions, and protected objects; the log layer (.log) captures compile-time errors, warnings, and unresolved references; the PDF layer (.pdf) delivers document-level outcomes such as final page count and float placement; and the page-image layer reveals two-dimensional visual defects that are not detectable from source or log data alone.
As shown in the figure below, these evidence sources are fused into a unified defect report Dt, where each defect d is represented as a structured record (c,o,r,e), specifying its category c, location o, severity r, and supporting evidence e. This defect report serves as the interface for the repair phase, with severity determining repair priority. The repair policy is governed by a preference profile π that enforces a tiered hierarchy of repair actions. Layout-native actions—such as float re-anchoring, equation splitting, and table restructuring using width-aware environments—are preferred as they address root causes without introducing side effects. Spacing-manipulative actions, like local \vspace adjustments, are restricted and require explicit justification. Pseudo-fixes, including \resizebox or \pagebreak, are forbidden as primary repair strategies due to their potential to distort typography or shift defects.
The repair selection process is defect-aware, prioritizing actions based on the severity and category of unresolved defects. For instance, compile errors are addressed first, followed by overflow, float placement, table consistency, space utilization, and cross-template mismatches. At each iteration, the highest-priority unresolved defect is selected, and the top-ranked layout-native strategy for its category is applied. If no layout-native options remain, restricted spacing-manipulative actions may be attempted under controlled conditions. Before any repair, the system snapshots the count and location of protected content—figures, tables, captions, labels, citations, and bibliography entries—and verifies that none are deleted, displaced, or altered during the repair. This content preservation guard ensures scientific integrity.
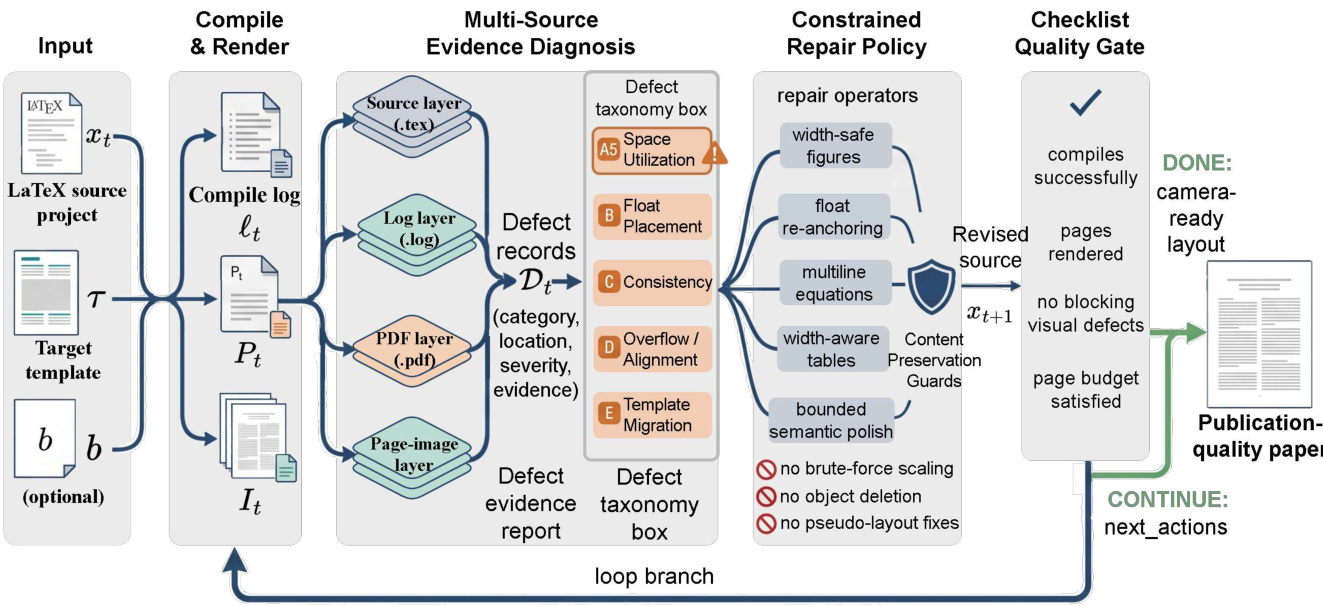
When layout-native repairs are exhausted and minor issues persist, such as widows/orphans or sparse final pages, the system permits bounded semantic polishing—minimal wording adjustments that do not alter factual claims or results. This fallback is invoked only after layout-native options fail and remains subject to content preservation guards. After each repair, the system recompiles and re-renders the entire document to re-inspect all pages, as LATEX edits can trigger non-local layout cascades. The state after each round is represented as St=(xt,ℓt,Pt,It,Dt,Ht,at), where Ht signals hard-constraint satisfaction. The process follows a six-step loop: compile and collect logs; parse deterministic signals; render pages; build defect records; apply constrained repairs; and recompile/rerender. A checklist-gated validation module then evaluates the outcome, producing one of three decisions: DONE (all constraints satisfied), CONTINUE (safe but issues remain), or BLOCKED (repair is unsafe or infeasible). The DONE condition requires successful compilation, rendering, absence of blocking defects, page-budget satisfaction, and preserved protected content. This structured, closed-loop system enables precise, auditable, and minimally invasive visual typesetting optimization for scientific documents.
Experiment
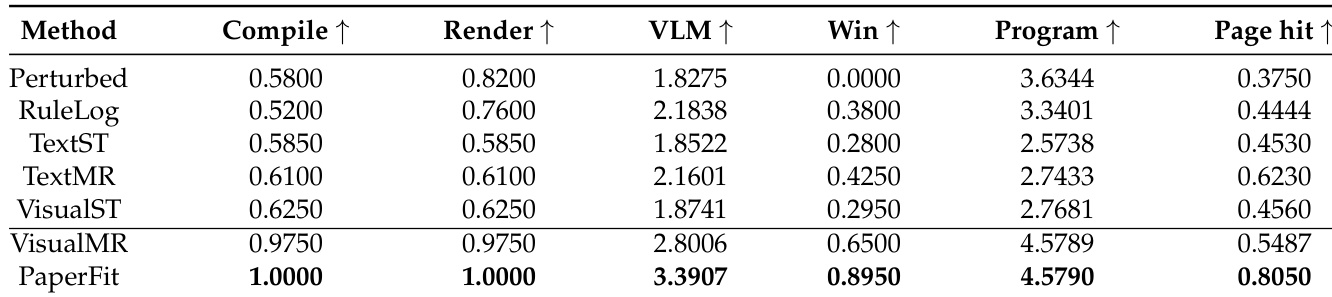
The evaluation setup tests PaperFit against six baselines spanning rule-based, text-only, and visual feedback paradigms using programmatic checks and VLM-based visual assessment on a curated benchmark. The comparative experiments validate that while text and log feedback cannot resolve two-dimensional layout failures, and single-turn visual editing struggles with non-local cascades, naive multi-round visual repair still lacks the structural planning required for precise page control. Additional backend and correlation studies demonstrate that the agent's architectural design drives performance gains more than the underlying language model, with automated scores closely aligning with human judgments. Qualitative case analyses and error examinations ultimately confirm that reliable typesetting optimization depends on a closed-loop system with explicit defect tracking and acceptance gates, though complex multi-defect scenarios and strict global page constraints remain notable challenges.
The authors evaluate multiple methods on a LaTeX typesetting optimization benchmark, comparing their performance across technical correctness and visual quality metrics. PaperFit achieves the highest scores in visual quality and page-budget adherence while maintaining perfect compile and render success, outperforming baselines that rely on single-turn feedback or naive multi-round visual editing without structured repair processes. PaperFit achieves the highest visual quality and page-budget hit rate while maintaining perfect compile and render success. Methods using only text or single-turn visual feedback show limited improvement in visual quality and page control. VisualMR improves on technical reliability but still struggles with page-budget adherence and visual defect resolution compared to PaperFit.
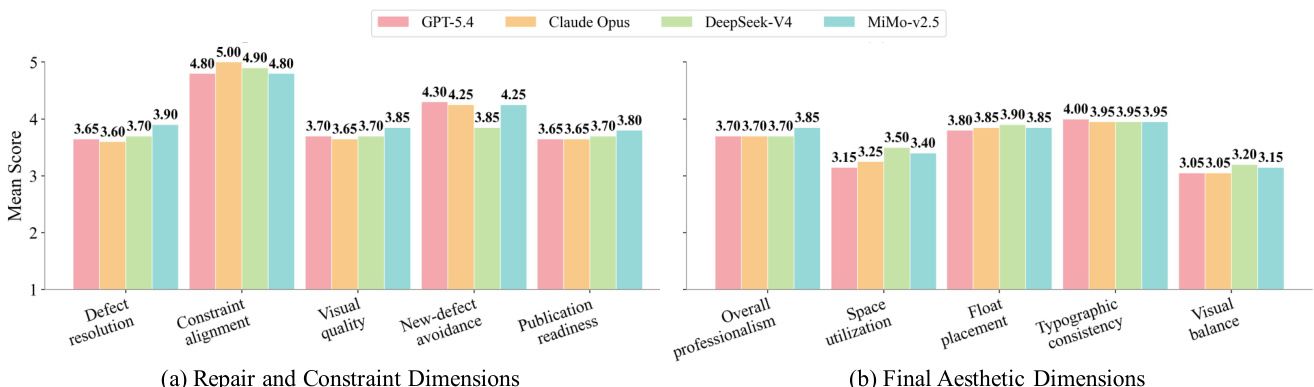
The experiment evaluates different language model backends within the PaperFit framework using a set of metrics including compile success, render success, VLM score, win rate, and page hit rate. Results show that all backends achieve high compile and render success, with minimal variation in VLM scores and win rates across models. The highest win rate is observed with one backend, while another achieves perfect page hit rate, indicating consistent performance across diverse models. All backends achieve high compile and render success rates, with no significant differences in overall performance. The win rate varies slightly among backends, with one achieving the highest score. Page hit rates are consistently high, with one backend achieving perfect compliance with the target page budget.

The authors evaluate their method, PaperFit, on a benchmark designed for visual typesetting optimization, which involves repairing LaTeX documents to meet publication standards. The benchmark requires multi-modal inputs including rendered page images and supports iterative repair processes, distinguishing it from prior work that focuses on formula reconstruction or code generation. PaperFit achieves superior performance by integrating structured diagnosis, constrained repair policies, and checklist-gated validation, outperforming baselines that lack these features. PaperFit-Bench is designed for visual typesetting repair and requires both multi-modal inputs and iterative repair processes. Prior benchmarks focus on tasks like formula reconstruction or code generation, while PaperFit-Bench targets publication-ready document repair. PaperFit outperforms baselines by using structured diagnosis and constrained repair policies, which are not present in other methods.
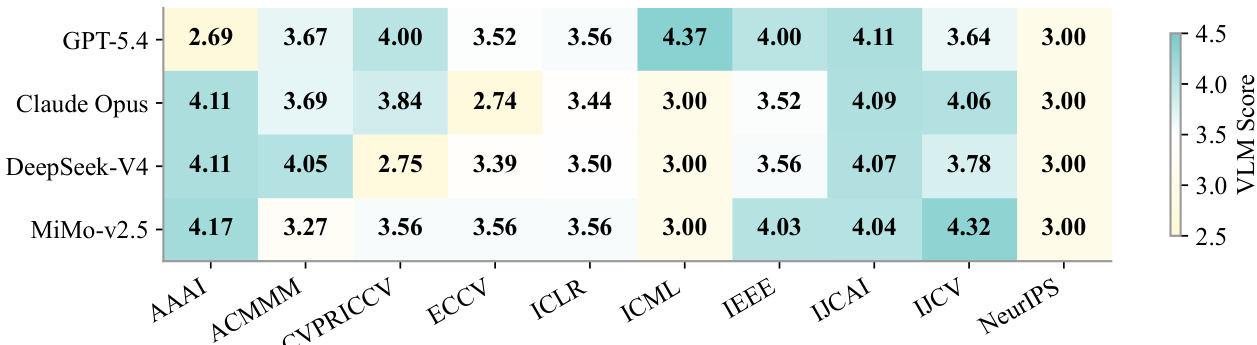
The authors evaluate the performance of different language model backends in the PaperFit framework across various academic venues. Results show that all models achieve high visual quality scores, with minimal variation between them, indicating that the framework's design rather than the specific model drives performance improvements. The VLM scores are consistently strong across all venues and models, demonstrating robustness and effectiveness of the approach. All language models achieve high and consistent visual quality scores across different venues, indicating framework robustness. Performance differences between models are minimal, suggesting the improvement is primarily due to the PaperFit framework rather than the specific backend. The VLM scores remain stable across venues, showing that the approach generalizes well across different academic templates and formatting requirements.
The authors evaluate various methods for visual typesetting optimization using a benchmark that assesses both technical correctness and visual quality. They compare different approaches based on their ability to handle multi-source feedback, iterative repair, and structured validation, with PaperFit achieving the best balance of visual quality and constraint satisfaction. The results highlight that while visual feedback improves outcomes, systematic repair processes with explicit defect tracking and validation gates are essential for reliable publication-ready outputs. PaperFit achieves the best visual quality and constraint satisfaction by integrating structured diagnosis and validation gates. Visual feedback alone is insufficient for reliable typesetting optimization without systematic repair processes. All methods maintain high content fidelity, indicating that improvements stem from layout repair rather than semantic changes.

The authors evaluate multiple methods and language model backends on a LaTeX typesetting benchmark that requires iterative, multi-modal repair to achieve publication-ready layouts. These experiments validate the effectiveness of structured diagnosis and checklist-gated validation, demonstrating that PaperFit consistently outperforms baselines which rely on unstructured editing or single-turn feedback and consequently struggle with visual quality and page constraints. Additionally, cross-backend and cross-venue tests confirm that performance improvements derive from the framework's systematic architecture rather than the specific underlying model, highlighting the approach's robustness and generalizability for reliable document optimization.