Command Palette
Search for a command to run...
MCP-Cosmos: وكلاء معززون بنموذج عالمي لتنفيذ المهام المعقدة في بيئات MCP
MCP-Cosmos: وكلاء معززون بنموذج عالمي لتنفيذ المهام المعقدة في بيئات MCP
Giridhar Ganapavarapu Dhaval Patel
الملخص
لا يوجد عنوانالبروتوكول السياقي للنموذج (MCP) قد وحد الواجهة بين نماذج اللغات الكبيرة (LLMs) والأدوات الخارجية، ومع ذلك لا يزال هناك فجوة أساسية في كيفية تصور الوكلاء للبيئات التي يعملون ضمنها. النماذج الحالية منقسمة: التخطيط على مستوى المهمة غالباً ما يتجاهل ديناميكيات وقت التنفيذ، بينما يفتقر التنفيذ التفاعلي إلى البصيرة طويلة المدى. نقدم إطار عمل MCP-Cosmos، الذي يغذي نماذج العالم التوليدية (WM) في نظام MCP البيئي لتمكين الأتمتة التنبؤية للمهام. من خلال توحيد ثلاث تقنيات متباينة، وهي MCP، ونموذج العالم، والوكيل، نثبت أن استراتيجية "جلب نموذج العالم الخاص بك" (BYOWM) تتيح للوكلاء محاكاة انتقالات الحالة وتحسين الخطط في فضاء خفي قبل التنفيذ. أجرينا تجارب باستخدام استراتيجيتين، وهما ReAct وSPIRAL، مع نموذجين للتخطيط وثلاثة نماذج عالمية ممثلة عبر أكثر من 20 مهمة في مجموعة MCP-Bench. لاحظنا تحسناً في مؤشرات الأداء الرئيسية لتفاعل الوكيل مع البيئة، مثل معدل نجاح الأداة ودقة معاملات الأداة. يوفر الإطار أيضاً مقاييس جديدة مثل جودة التنفيذ لتوليد رؤى جديدة حول فعالية نماذج العالم مقارنةً بالنماذج الأساسية.
One-sentence Summary
MCP-Cosmos integrates generative world models into the Model Context Protocol to enable predictive task automation through a Bring Your Own World Model strategy that simulates state transitions and refines plans in a latent space, demonstrating improved tool success rates and parameter accuracy across over 20 MCP-Bench tasks evaluated with ReAct and SPIRAL strategies using two planning models and three world models.
Key Contributions
- MCP-Cosmos introduces a modular Bring Your Own World Model (BYOWM) architecture that integrates heterogeneous world models into the Model Context Protocol ecosystem. This framework enables predictive cognition by allowing agents to simulate environment state transitions in a latent space prior to committing to physical tool calls.
- Comparative experiments across ReAct and SPIRAL planning strategies with multiple world models over 300+ trajectories on MCP-Bench demonstrate measurable improvements in tool success rates and parameter accuracy relative to standard reactive baselines.
- The work proposes the Execution Quality metric to evaluate predictive efficiency by penalizing unnecessary tool invocations, accompanied by a systematic analysis of existing evaluation gaps for measuring world model effectiveness in agentic systems.
Introduction
The authors leverage the Model Context Protocol to standardize LLM-to-tool interactions, addressing a critical need for reliable agentic automation in dynamic software environments. Prior approaches remain divided between planning-centric systems that ignore execution-time stochasticity and reactive agents that suffer from horizon myopia, leading to redundant tool calls and irreversible state failures. To resolve these limitations, the authors introduce MCP-Cosmos, a framework that integrates generative world models into the MCP ecosystem via a modular Bring Your Own World Model strategy. This architecture allows agents to simulate state transitions and optimize trajectories in a latent space before committing to physical execution, which directly improves tool success rates and parameter accuracy. Additionally, the authors propose an Execution Quality metric to better quantify predictive efficiency and highlight gaps in current evaluation methodologies.
Dataset
-
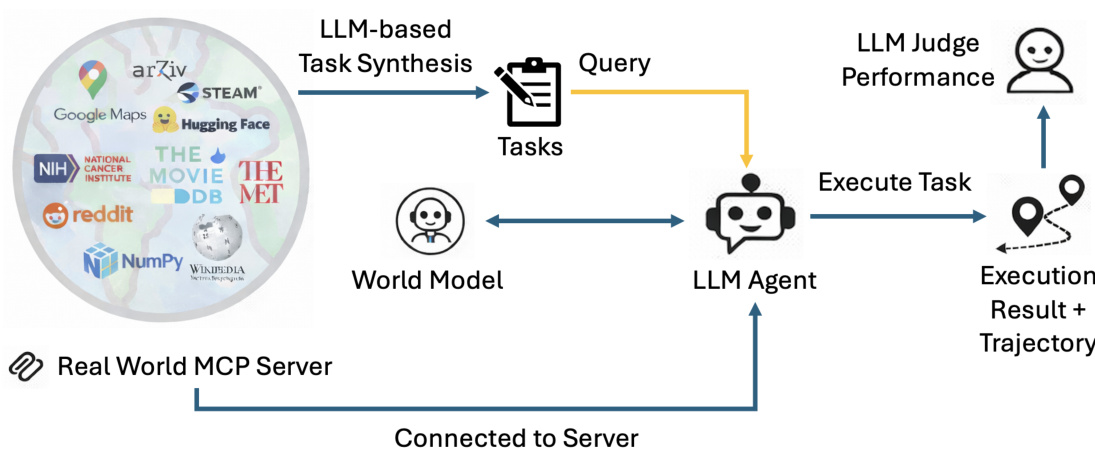
Dataset Composition and Sources: The authors select MCP-Bench as the primary evaluation framework, favoring its ecosystem-scale design over broader alternatives. The dataset draws from 28 live MCP servers and 257 cross-domain tools to simulate complex, real-world agent interactions.
-
Subset Details and Filtering Rules: A cost-effective subset of 24 tasks is curated, with a strong emphasis on 2-server and 3-server scenarios. This selection covers over 300 trajectories across 12 unique task types. The authors filter for tasks that require cross-domain tool dependencies, stratifying difficulty by server count and documenting specific task IDs and server mappings in the appendix.
-
Data Usage and Processing: The authors use this dataset exclusively for evaluation rather than training, and no training splits or mixture ratios are applied. Instead, they integrate the tasks with three agentic architectures and three World-Models to assess multi-tool output prediction and planning stability. Processing involves applying fuzzy instructions to challenge multi-step grounding and evaluating outcomes through rule-based and judge-based metrics validated by high human agreement.
-
Additional Processing and Metadata Construction: The evaluation pipeline prioritizes scenarios that stress-test agent state maintenance across disparate domains. The authors structure the data to highlight bilateral server interactions, explicitly tracking planning failure modes and tool coordination complexity to enable granular performance analysis. Full task distributions and server mappings are archived in the appendix for reproducibility.
Method
The authors present a two-phase framework for integrating world models into multi-turn planning and execution within the Model Context Protocol (MCP) environment. The overall process consists of a simulation-based planning phase followed by real-world execution, as illustrated in the workflow diagram. In the initial phase, the agent leverages a world model to simulate potential action sequences without engaging with actual tools or environments, thereby avoiding execution costs. The agent planner generates tool calls and iteratively revises the plan using simulated observations until a viable plan is formed or a termination condition is met. These action and simulated observation pairs are accumulated in a world model trajectory, enabling efficient exploration of multiple paths. The world model operates in latent space, simulating the environment and returning a simulated tool response as an observation for a given tool call and user request. This abstraction allows for diverse simulation implementations, with specific models such as AWM 4B being developed to support synthetic environment generation.
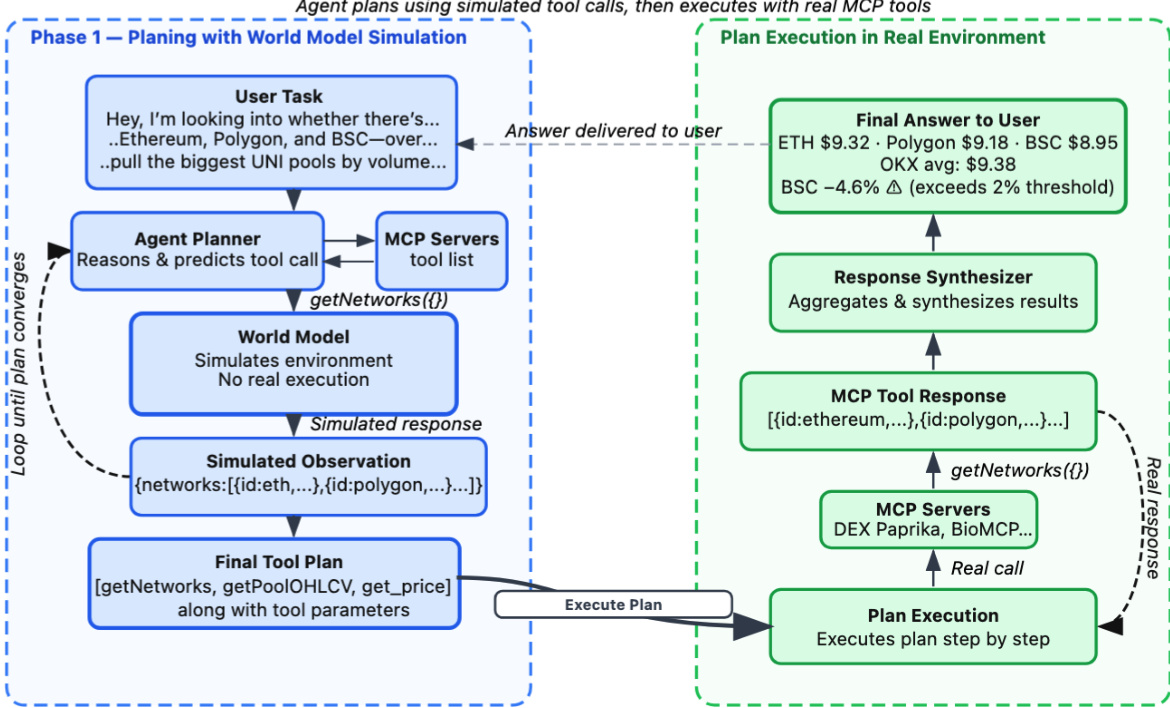
The planning process is formalized in Algorithm 1, where the agent begins with an initial state derived from the task instruction and iteratively generates actions using a planning policy. For each action, the world model predicts a simulated pseudo-observation, which is used to update the state and continue the planning loop. This simulation allows the agent to reason about future states and make informed decisions without real-world interaction. The accumulated world model trajectory serves as the basis for selecting an optimal plan, which can be achieved using non-deterministic policy models such as LLMs or deterministic algorithms like reward-based MCTS.
In the second phase, the selected plan is executed in the actual environment. The agent executes each tool call in sequence, receiving real observations from the MCP servers. If an action fails, the algorithm may optionally invoke a plan adjustment mechanism to modify the remaining plan, although this step is excluded from benchmarking due to its computational cost. Successfully executed action-observation pairs are recorded in the execution trajectory. After completing the plan, the agent synthesizes a final answer using summarization techniques, and the algorithm returns three key outputs: the final answer, the execution plan, and the complete execution trajectory, providing transparency into both planning and execution.
Experiment
The evaluation framework assessed multiple agent-world model configurations using hierarchical metrics and a novel Execution Quality measure to validate how explicit world models influence proactive planning and execution efficiency. The primary experiments demonstrate that world model augmentation significantly improves tool selection and parameter accuracy compared to baseline ReAct agents, while ablation studies validate that explicit models effectively constrain the costly, aggressive exploration triggered by more capable planners. Ultimately, the findings establish that integrating dedicated world models is essential for guiding targeted agent behavior, providing a structured foundation for future agentic planning research despite current computational and environmental limitations.
The authors evaluate the impact of world model integration on agent performance using a hierarchical framework that assesses task completion, tool selection, planning effectiveness, and execution quality. Results show that world model-augmented agents outperform the baseline in tool selection and parameter accuracy, while the baseline remains superior in task fulfillment and dependency awareness, highlighting a trade-off between efficiency and success. The proposed execution quality metric better captures the efficiency of tool usage, revealing that stronger planners can lead to excessive exploration without world model constraints. World model integration improves tool selection and parameter accuracy but does not enhance task completion or dependency awareness compared to the baseline. The proposed execution quality metric reveals that stronger planners without world models generate excessive tool calls and execution overhead. World models constrain powerful planners, reducing exploration and improving efficiency by focusing execution on vetted plans.
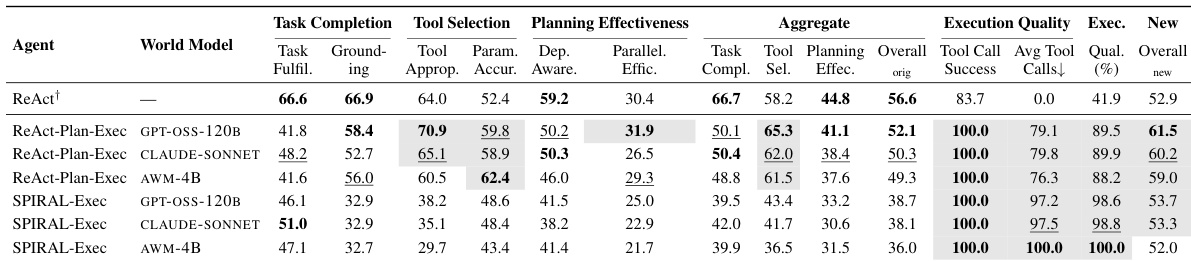
The authors evaluate the impact of world model infusion on agent performance using a hierarchical framework that assesses task completion, tool selection, and planning effectiveness. Results show that world model-augmented agents achieve better tool selection and parameter accuracy compared to the ReAct baseline, but the baseline remains superior in task fulfillment and dependency awareness. The integration of world models also leads to increased computational costs, with some configurations consuming significantly more tokens than others. World model-augmented agents improve tool selection and parameter accuracy but do not match the baseline in task fulfillment and dependency awareness. The integration of world models increases computational overhead, with some configurations consuming substantially more tokens than the baseline. A new metric, Execution Quality, better distinguishes agents that solve tasks efficiently from those that succeed through repeated retries and excessive tool calls.
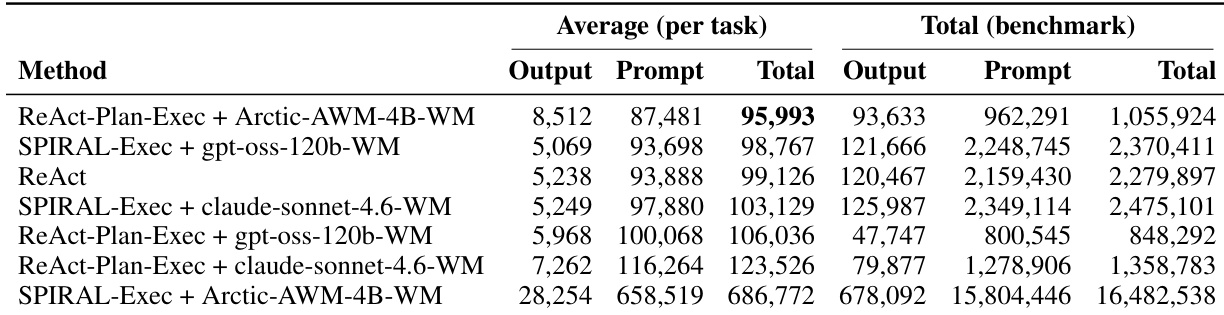
The authors compare different agent configurations with and without world models, focusing on efficiency and performance metrics. Results show that world model-augmented agents reduce the number of tool calls and execution time compared to the baseline, with some configurations achieving significant improvements in efficiency. The stronger planner leads to higher tool call counts and longer execution times, but world models help constrain this behavior, improving overall execution quality. World model-augmented agents reduce the number of tool calls and execution time compared to the baseline. The stronger planner increases tool calls and execution time, but world models help constrain this exploratory behavior. SPIRAL-Exec configurations show the lowest tool calls and execution time, indicating higher efficiency.
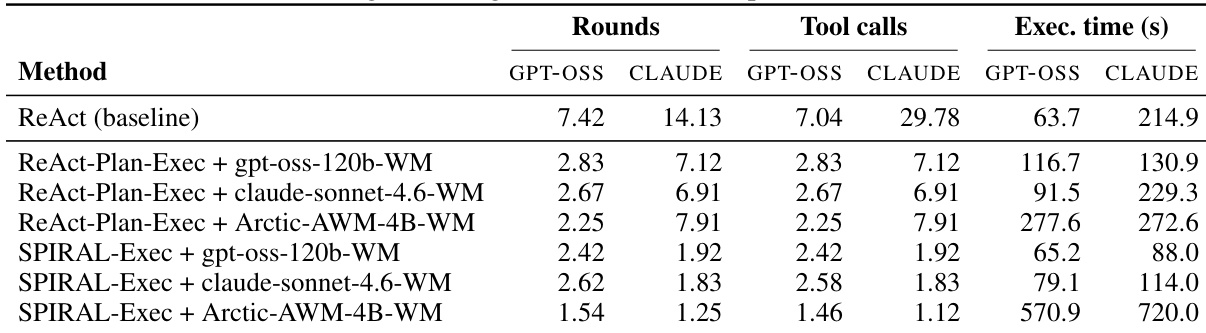
The authors evaluate the impact of world model infusion on agent performance using a structured planning framework, comparing different configurations of planners and world models. Results show that world model-augmented agents achieve better tool selection and parameter accuracy, but the effectiveness varies depending on the world model type and planner capabilities, with general-purpose LLMs outperforming a purpose-built model in most cases. The study also highlights trade-offs between task completion, execution efficiency, and computational cost, suggesting that world models can guide more efficient planning by constraining exploratory behavior in powerful planners. World model augmentation improves tool selection and parameter accuracy but does not consistently enhance task completion compared to baseline methods. General-purpose LLM-based world models outperform a purpose-built model in most configurations, despite the latter being trained on relevant environments. A stronger planner increases tool call frequency and execution time, but world model integration reduces unnecessary exploration, improving execution efficiency.
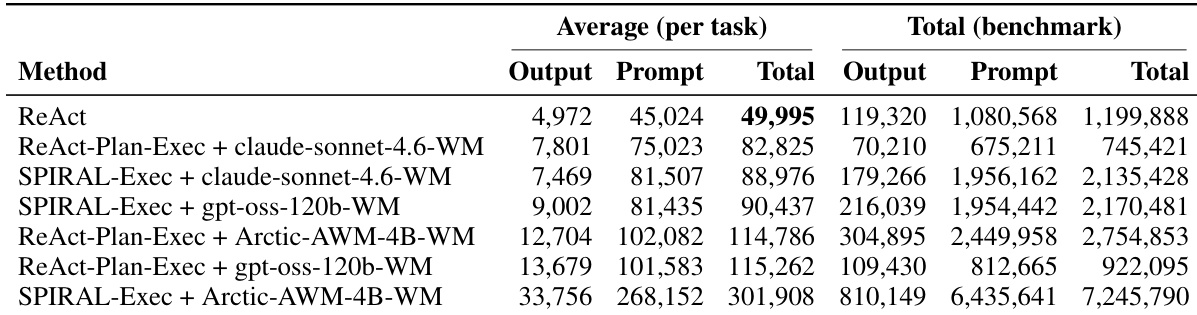
The authors evaluate the impact of world model infusion on agent performance using a hierarchical framework that assesses task completion, tool selection, and planning effectiveness. Results show that world model-augmented agents outperform the ReAct baseline in tool selection and parameter accuracy, while ReAct remains stronger in task fulfillment and dependency awareness, indicating a trade-off between efficiency and completion. A new metric, Execution Quality, highlights that agents with world models achieve better execution efficiency by reducing unnecessary tool calls despite lower task completion rates. The ablation study reveals that a stronger planner does not compensate for the lack of a world model, as it leads to increased exploration and higher computational costs, emphasizing the importance of world models in constraining planner behavior. World model-augmented agents improve tool selection and parameter accuracy compared to the ReAct baseline. ReAct achieves higher task completion and dependency awareness but at the cost of inefficient tool usage. A stronger planner increases tool calls and execution time, highlighting the need for world models to constrain exploration.
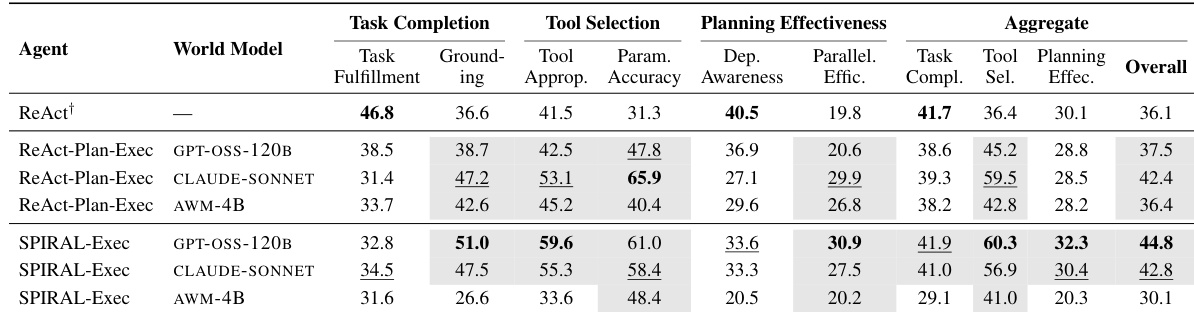
The experiments employ a hierarchical evaluation framework to assess how integrating world models influences agent performance across task completion, tool selection, and planning efficiency. Results validate that world model integration significantly improves tool selection accuracy and execution efficiency by constraining exploratory behavior and reducing unnecessary computational overhead. However, this enhancement reveals a clear trade-off, as baseline agents without world models consistently maintain superior task fulfillment and dependency awareness. Ultimately, the findings demonstrate that while world models effectively guide powerful planners toward more efficient execution, they do not universally surpass traditional baselines in overall task completion.