Command Palette
Search for a command to run...
تحسين نماذج اللغات الكبيرة (LLMs) لنماذج اللغات الكبيرة: اكتشاف وكيل للتوسع أثناء الاختبار
تحسين نماذج اللغات الكبيرة (LLMs) لنماذج اللغات الكبيرة: اكتشاف وكيل للتوسع أثناء الاختبار
الملخص
يُعد توسيع الزمن خلال الاختبار (Test-time scaling - TTS) نهجاً فعالاً لتحسين أداء النماذج اللغوية الكبيرة من خلال تخصيص موارد حوسبية إضافية أثناء عملية الاستدلال. ومع ذلك، لا تزال استراتيجيات الـ TTS الحالية تعتمد بشكل كبير على التصميم اليدوي؛ حيث يقوم الباحثون بتصميم أنماط الاستدلال يدوياً وضبط البديهيات (heuristics) بناءً على الحدس، مما يترك حيزاً كبيراً من فضاء تخصيص الحوسبة دون استكشاف. نقترح في هذا العمل إطاراً قائماً على البيئة، يُدعى AutoTTS، يغير من طبيعة ما يصممه الباحثون: الانتقال من ضبط بديهيات TTS الفردية إلى تصميم بيئات يمكن من خلالها اكتشاف استراتيجيات TTS آلياً. تكمن جوهرية إطار عمل AutoTTS في بناء البيئة؛ إذ يجب أن تكون بيئة الاكتشاف قابلةً للتدبير من حيث فضاء التحكم، وأن توفر ملاحظات (feedback) رخيصة ومتكررة لعملية البحث عن استراتيجيات TTS. وكحالة عملية لهذا الإطار، نصيغ مشكلة TTS من حيث العرض والعمق كمشكلة توليد وحدة تحكم (Controller Synthesis) تعتمد على مسارات استدلال تم جمعها مسبقاً وإشارات استكشافية (probe signals)، حيث تقرر وحدات التحكم متى يتم التفرع، أو الاستمرار، أو إجراء عملية استكشاف، أو التقليم، أو التوقف، ويمكن تقييمها بتكلفة منخفضة دون الحاجة إلى استدعاءات متكررة للنماذج اللغوية الكبيرة. كما نقدم معامل بيتا (beta parameterization) لجعل عملية البحث قابلةً للتدبير، وملاحظات حول تتبع التنفيذ بدقة عالية لتحسين كفاءة الاكتشاف، وذلك بمساعدة الـ agent على تشخيص أسباب فشل برنامج TTS. أظهرت التجارب على مقاييس الاستدلال الرياضي أن الاستراتيجيات المكتشفة تحسن التوازن العام بين الدقة والتكلفة مقارنة بالأسس القوية التي تم تصميمها يدوياً. كما تظهر الاستراتيجيات المكتشفة قدرة على التعميم على مقاييس واختبارات معزولة، في حين تكلف عملية الاكتشاف بأكملها 39.9 دولاراً و160 دقيقة فقط. سيتم نشر بياناتنا وشفرتنا البرمجية كمصدر مفتوح على الرابط https://github.com/zhengkid/AutoTTS.
One-sentence Summary
The authors propose AutoTTS, an environment-driven framework that automatically discovers test-time scaling strategies by formulating width–depth scaling as controller synthesis over pre-collected reasoning trajectories and probe signals, leveraging beta parameterization and fine-grained execution trace feedback to enable tractable search and cheap evaluation without repeated LLM calls.
Key Contributions
- This work introduces AutoTTS, an environment-driven framework that reframes test-time scaling strategy design from manual heuristic tuning to automatic controller synthesis over a structured control space.
- The approach constructs a replay Markov decision process from pre-collected reasoning trajectories and probe signals to enable cheap controller evaluation without repeated model calls. Beta parameterization and fine-grained execution trace feedback further streamline the search process by ensuring tractable control and targeted failure diagnosis.
- Empirical evaluations demonstrate that the automatically discovered controllers generalize across held-out benchmarks and multiple model scales. These results confirm that environment-driven discovery provides a computationally efficient alternative to hand-crafted inference strategies.
Introduction
Test-time scaling enhances large language model performance by dynamically allocating additional computation during inference, making efficient resource distribution essential for balancing accuracy and operational cost. Existing approaches depend on manual heuristics for branching, pruning, and stopping reasoning trajectories, which forces researchers to tune thresholds by intuition and leaves much of the computation-allocation space unexplored. The authors leverage an environment-driven paradigm called AutoTTS to automate this discovery process. By formulating strategy design as controller synthesis over collected reasoning trajectories, they enable an agent to evaluate and refine allocation policies without repeated LLM calls. The framework introduces beta parameterization to keep the search tractable and provides detailed execution trace feedback to help the agent diagnose failures, ultimately discovering strategies that outperform manual baselines at a fraction of the computational cost.
Dataset
- Dataset composition and sources: The provided text does not describe a dataset, data sources, or subset compositions.
- Key details for each subset: No subset sizes, filtering rules, or source metadata are included.
- How the paper uses the data: The snippet implements a control flow mechanism rather than a training or inference pipeline.
- Processing details: The authors use a boolean evaluation to verify that all branches are either finished or abandoned, then break the execution loop when that condition is met.
Method
The authors frame test-time scaling (TTS) as an algorithmic search problem, where the goal is to discover an optimal policy for allocating a finite inference budget across multiple reasoning branches. This policy, or controller, dynamically manages the creation, extension, probing, pruning, and aggregation of branches to maximize accuracy while respecting the computational constraint. The overall framework, as illustrated in the figure below, consists of a discovery loop that iteratively evaluates candidate controllers against pre-collected offline data. This loop operates in a two-phase process: an offline replay environment enables fast and deterministic evaluation of any candidate controller without invoking the base language model (LLM), and a feedback mechanism provides detailed execution traces to guide the discovery agent. The agent, an LLM acting as a controller designer, analyzes the accumulated history of prior proposals, their performance, and their execution behaviors to propose improved controller implementations. This process continues over multiple rounds, with the best-performing controller and its associated hyperparameter selection ultimately chosen.
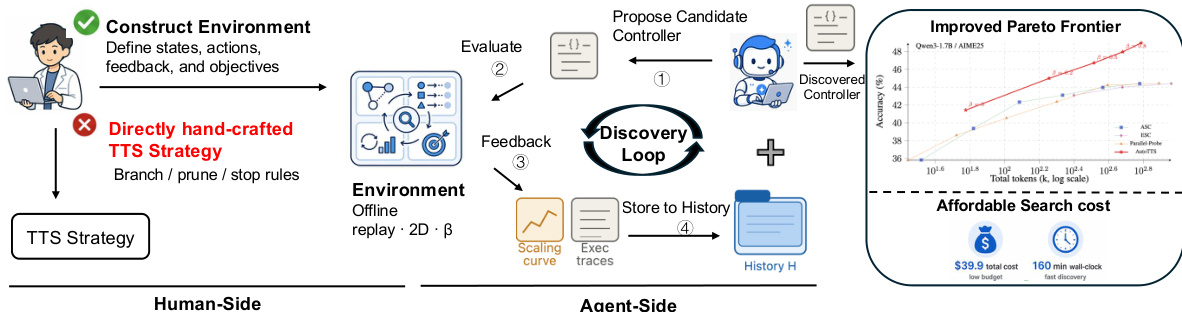
The core of the method is the controller's state representation and action space. The state st at decision step t encapsulates the entire history of the inference process for a given question q. It includes the number of instantiated branches mt, the set of currently active branches It, the depth (measured in fixed-length token intervals) of each branch ℓt, and the set of probe feedback Ωt that has been revealed so far. The controller's actions are defined by a set of atomic operations: BRANCH to create a new reasoning path, CONTINUE(i) to extend an active branch i, PROBE(i) to read the intermediate answer from branch i, PRUNE(i) to remove a branch, and ANSWER to terminate and produce a final answer. The controller's policy π(⋅∣s,β) maps the current state s and a single hyperparameter β to a distribution over these admissible actions. The parameter β acts as a high-level knob that controls the overall aggressiveness of the budget allocation strategy.
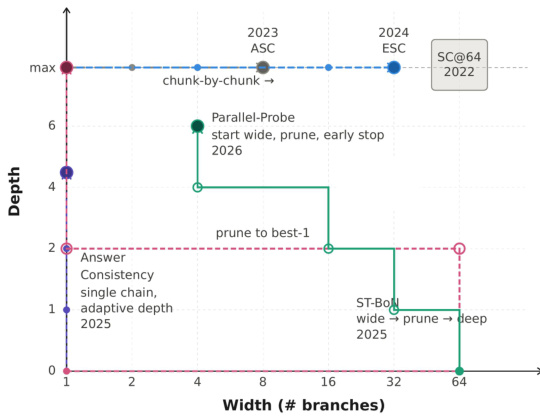
A key design choice is the use of a single hyperparameter β to control all internal decision-making thresholds, a concept known as beta parameterization. This simplifies the search space from a high-dimensional one to a one-dimensional sweep, preventing the agent from discovering brittle, overfit solutions. The controller's internal hyperparameters, such as the number of initial branches, pruning patience, and confidence thresholds, are all determined by smooth, monotonic functions of β. This ensures that as β increases, the controller becomes more aggressive, spending more budget on exploration and deeper reasoning, while maintaining a coherent and interpretable behavior. The discovered controller, termed the Confidence Momentum Controller (CMC), leverages this framework to implement four key mechanisms: a momentum-aware stopping gate that uses an Exponential Moving Average (EMA) of confidence to avoid premature termination on transient spikes; coupled width-depth control that links the decision to spawn new branches with the trend of confidence gain; alignment-aware depth allocation that prioritizes probing branches whose answers align with the current consensus; and a conservative branch abandonment policy that only discards branches after persistent deviation, ensuring at least two active branches are always preserved.
Experiment
The experiments evaluate a discovered reasoning controller across multiple Qwen3 models using offline replay environments, benchmarking it against established handcrafted scaling methods on both in-distribution and held-out mathematical and non-mathematical reasoning tasks. Main results and scaling analyses validate that the controller dynamically allocates computation to productive branches rather than merely cutting costs, while generalization tests confirm its robustness across different model families and task domains. Ablation studies further verify that parameterized budget control and detailed execution traces are critical for preventing search overfitting, ultimately demonstrating that the automated framework uncovers complex, coordinated decision-making strategies that consistently outperform manual design in balancing inference efficiency and accuracy.
The authors evaluate the performance of discovered controllers against handcrafted baselines on held-out benchmarks, demonstrating that the discovered controllers achieve a better accuracy-cost tradeoff across multiple models and tasks. The results show that the discovered controllers generalize well beyond the training set and outperform handcrafted methods in most settings, with significant reductions in token usage while maintaining competitive accuracy. The discovered controllers achieve a better accuracy-cost tradeoff compared to handcrafted baselines on held-out benchmarks. The discovered controllers generalize well to different models and non-math tasks, maintaining competitive performance with reduced token usage. The discovered controllers outperform handcrafted methods in most settings, with notable reductions in token consumption while preserving accuracy.
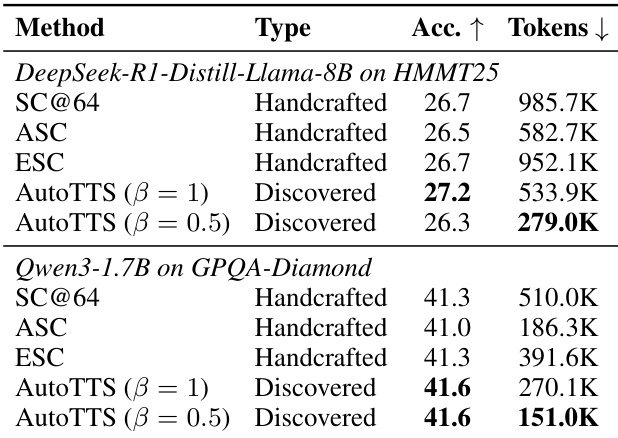
The authors evaluate a discovered controller against handcrafted baselines on multiple benchmarks, demonstrating that the discovered controller achieves a better accuracy-cost tradeoff across various models and datasets. The results show that the controller generalizes well to held-out environments and outperforms baselines in most settings, while also being robust to changes in model and task domains. Ablation studies indicate that key design choices, such as beta parameterization and execution traces, are critical for effective discovery and generalization. The discovered controller achieves a better accuracy-cost tradeoff compared to handcrafted baselines across multiple benchmarks and models. The controller generalizes well to held-out benchmarks and different model families, indicating robustness beyond the training setup. Beta parameterization and execution traces are essential for effective discovery, with their removal leading to significant performance degradation.
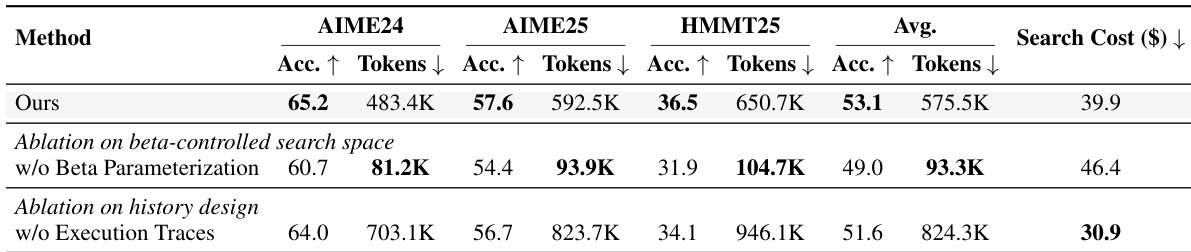
The authors evaluate a discovered controller against handcrafted baselines across multiple models and benchmarks, showing that the discovered controller achieves a better accuracy-cost tradeoff in most settings. The controller generalizes well to held-out benchmarks and outperforms handcrafted methods in terms of both accuracy and inference efficiency, particularly on smaller models. The results indicate that the discovered controller can effectively balance computation allocation to improve performance without excessive token usage. The discovered controller achieves superior accuracy-cost tradeoffs compared to handcrafted baselines across multiple models and benchmarks. The controller generalizes well to held-out datasets, outperforming baselines in most settings and maintaining strong performance on larger models. The discovered controller reduces token consumption significantly while preserving or improving accuracy, indicating efficient computation allocation.
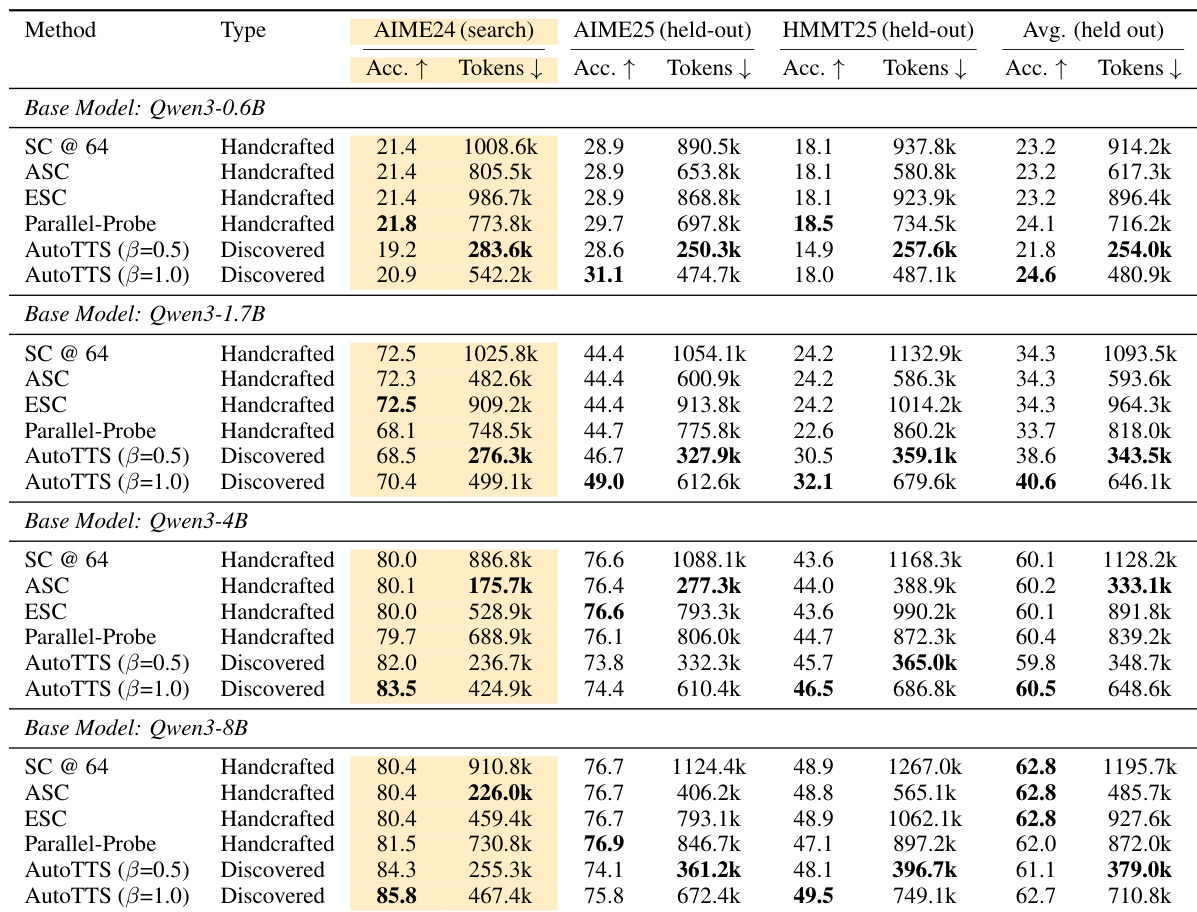
The experiments evaluate discovered controllers against handcrafted baselines across diverse models and held-out benchmarks to validate their generalization capabilities and computational efficiency. Qualitative results demonstrate that the discovered controllers consistently achieve a superior accuracy-cost tradeoff by significantly reducing token consumption while maintaining or improving performance across various domains. Ablation studies further confirm that specific design choices, particularly beta parameterization and execution traces, are critical for driving effective discovery and robust cross-task adaptation. Overall, the findings establish that automated controller discovery provides a more efficient and adaptable alternative to traditional handcrafted methods.