Command Palette
Search for a command to run...
Flow-OPD: تقطير على السياسة لنماذج مطابقة التدفق
Flow-OPD: تقطير على السياسة لنماذج مطابقة التدفق
الملخص
تعاني نماذج توليد الصور من النصوص الحالية المعتمدة على مطابقة التدفق (Flow Matching) من سدين حرجين اثنين في ظل محاذاة المهام المتعددة: ندالة المكافآت المستحثة من خلال المكافآت ذات القيم القياسية، والتداخل التدرجي الناشئ عن التحسين المشترك للأهداف غير المتجانسة، مما يؤدي مجتمعا إلى ظهور «تأثير التأرجح» بين المقاييس المتنافسة، وممارسة التلاعب بالمكافآت على نطاق واسع. مستوحاة من نجاح التلميح ضمن السياسة (On-Policy Distillation) في مجتمع نماذج اللغة الكبيرة، نقترح إطار العمل الموحد «Flow-OPD»، كأول إطار ما بعد التدريب يدمج التلميح ضمن السياسة في نماذج مطابقة التدفق. يعتمد Flow-OPD استراتيجية محاذاة على مرحلتين: فهو أولاً يربي نماذج معلمة متخصصة في المجال عبر ضبط دقيق لـ GRPO بمكافأة واحدة، مما يسمح لكل خبير بلوغ سقف أداؤه بشكل منعزل؛ ثم يُنشئ سياسة أولية قوية من خلال مخطط البداية الباردة المستند إلى التدفق (Flow-based Cold-Start)، ودمج الخبرات غير المتجانسة بسلاسة في نموذج طالب واحد عبر ترتيب من ثلاث خطوات يشمل أخذ العينات ضمن السياسة، وتسمية توجيه المهام، والإشراف الكثيف على مستوى المسارات. ونقدم أيضاً تنظيم المرساة المتعددة الأبعاد (Manifold Anchor Regularization)، الذي يستفيد من معلم غير معني بالمهمة لتقديم إشراف شامل على البيانات بأكملها، مما يثبت التوليد على متعدد الأبعاد عالي الجودة، مما يخفف بفعالية من التدهور الجمالي الملاحظ عادة في المحاذاة المعتمدة فقط على التعلم التعزيزي. مدعوماً بنموذج Stable Diffusion 3.5 Medium، يرفع Flow-OPD درجة GenEval من 63 إلى 92، ودقة التعرف الضوئي على الحروف (OCR) من 59 إلى 94، محققاً تحسناً شاملاً يقارب 10 نقاط مقارنة بـ GRPO الأساسي، مع الحفاظ على دقة الصور والمحاذاة مع تفضيلات الإنسان، وإظهار تأثير «تجاوز المعلم» الناشئ. ترسي هذه النتائج Flow-OPD كنموذج محاذاة قابل للتوسع لبناء نماذج شاملة لتوليد الصور من النصوص.
One-sentence Summary
To mitigate reward sparsity and gradient interference in multi-task text-to-image generation, the authors propose Flow-OPD, a unified post-training framework that integrates on-policy distillation into Flow Matching models via a two-stage alignment strategy that fine-tunes domain-specialized teachers through single-reward GRPO, consolidates heterogeneous expertise using task-routing labeling and dense trajectory-level supervision, and employs Manifold Anchor Regularization to preserve aesthetic quality during multi-objective optimization.
Key Contributions
- The paper introduces Flow-OPD, a unified post-training framework that integrates on-policy distillation into Flow Matching models to mitigate gradient interference and reward sparsity during multi-task alignment. The framework employs a two-stage strategy that first trains domain-specialized teacher models via single-reward GRPO fine-tuning before consolidating heterogeneous expertise into a single student through Flow-based cold-start initialization, on-policy sampling, task-routing labeling, and dense trajectory-level supervision.
- The work proposes Manifold Anchor Regularization to counteract aesthetic degradation inherent in reinforcement learning alignment. This mechanism utilizes a task-agnostic teacher to provide full-data supervision that anchors generation to a high-quality visual manifold, effectively stabilizing optimization across competing objectives.
- Comprehensive evaluations on the Pickscore, GenEval, and OCR benchmarks demonstrate that the proposed framework significantly improves layout coherence, text rendering accuracy, and overall functional reliability. Quantitative results confirm superior performance across multiple alignment metrics compared to existing Flow Matching baselines.
Introduction
Flow matching has emerged as a superior generative modeling paradigm that outperforms diffusion models in sampling efficiency and synthesis quality, yet current post-training methods struggle to support the multi-dimensional alignment required for modern applications like precise text rendering and complex compositional reasoning. Prior approaches based on reinforcement learning algorithms such as Group Relative Policy Optimization (GRPO) face critical limitations in multi-task settings due to sparse scalar rewards that lack the granularity to harmonize conflicting objectives. This sparsity induces a zero-sum seesaw effect where optimizing specific features degrades aesthetics through reward hacking and gradient interference, causing existing methods to suffer from metric trade-offs, training instability, or reward-normalization collapse. The authors leverage On-Policy Distillation, a paradigm proven effective in large language models, to introduce Flow-OPD, the first framework to integrate OPD into the post-training pipeline of flow matching models. This two-stage strategy first cultivates specialized domain teachers via single-reward GRPO and then distills their dense, trajectory-level supervision into a unified student model using a flow-based cold-start initialization, task routing labeling, and Manifold Anchor Regularization. Experimental results demonstrate that Flow-OPD achieves a 10% improvement over vanilla GRPO, enabling the student model to match or surpass specialized experts while maintaining robust out-of-distribution generalization.
Method
The authors leverage a two-stage alignment framework, Flow-OPD, which integrates on-policy distillation into Flow Matching models to address the challenges of reward sparsity and gradient interference in multi-task text-to-image generation. The overall approach begins with the cultivation of domain-specialized teacher models through single-reward GRPO fine-tuning. Each teacher is optimized independently for a specific task, allowing it to reach its performance ceiling without interference from other objectives. This step ensures that each expert model possesses high competence in its respective domain.

Following the expert training, a robust initial policy for the student model is established via a Flow-based Cold-Start scheme. This initialization is critical for preventing trajectory divergence during early training. The authors explore two strategies: a Supervised Fine-Tuning (SFT) protocol that samples trajectories from the specialized teachers to inherit expert knowledge distributions, and a model-merging approach that superposes the anisotropic priors of the divergent teachers into a unified parameter state. This merging-as-initialization technique positions the student in a high-competence region of the loss landscape, providing a strong foundation for subsequent distillation.

The core of the method, Multi-Teacher On-Policy Distillation, operates in a three-step orchestration. First, on-policy sampling is performed by the student model, which generates trajectories from its own distribution. To facilitate sufficient exploration of the state space, the deterministic probability flow ODE is converted into an equivalent Stochastic Differential Equation (SDE), resulting in a local isotropic Gaussian policy for the student's transitions. Second, a task-specific teacher labeling mechanism is employed. At each state xt, the student's textual condition c is routed to a specific expert teacher k using a hard routing function R(c). This mechanism ensures that only one teacher provides supervision at a time, eliminating inter-domain gradient interference. The target velocity field for the student's policy is thus defined as vtarget(xt,t,c)=vϕk(xt,t,c).
The final step involves deriving a dense reward signal for policy optimization. The authors analytically derive the Reverse KL divergence between the student's and the target's transition policies. Because both policies share the same isotropic covariance, the divergence simplifies to a time-weighted L2 distance between their vector fields. This distance is used to construct a dense reward rt(i) for the i-th trajectory, which is then used in a clipped policy gradient update. The policy ratio ρt,i,j(θ) is computed, and a clipped surrogate objective is optimized to update the model parameters, ensuring stable training against high-frequency rewards. This process allows the student to seamlessly consolidate heterogeneous expertise from the ensemble of teachers into a single, unified model.
To further enhance the generative quality and prevent aesthetic degradation, the authors introduce Manifold Anchor Regularization (MAR). This mechanism decouples functional alignment from aesthetic preservation. It leverages a task-agnostic, frozen aesthetic teacher (e.g., optimized via DeQA) to provide a high-fidelity regularizing vector field vaesthetic. The optimization is formulated as a total loss that includes the policy loss and a dense KL penalty, which is a time-weighted L2 distance between the student's and the aesthetic teacher's vector fields. This regularization acts as a continuous elastic anchor, ensuring the student policy remains bounded to a high-quality visual manifold while absorbing functional intelligence from the multi-teacher ensemble.
Experiment
The evaluation compares Flow-OPD against monolithic and hybrid-reward GRPO baselines across compositional generation, text rendering, and quality benchmarks to validate the fundamental limitations of scalar reward mixing and the necessity of dense multi-expert supervision. Controlled ablation and cold-start experiments confirm that conventional scalar alignment induces catastrophic forgetting and gradient interference, whereas the proposed framework successfully consolidates diverse expert capabilities without degradation. Generalization tests on out-of-domain benchmarks further demonstrate that dense supervision effectively mitigates cross-task regression and yields robust multi-task trade-offs. Ultimately, comparative analyses against alternative reinforcement learning frameworks highlight the method's ability to circumvent reward hacking and hallucination artifacts while achieving superior aesthetic and functional coherence.
{"summary": "The authors evaluate a multi-task training approach on a foundation model, comparing it against baselines that use scalar reward mixing and single-reward optimization. Results show that their method achieves consistent performance across multiple tasks, surpassing or matching specialized teachers while avoiding the degradation seen in other approaches. The method leverages dense multi-expert supervision to resolve gradient interference and maintain capability stability.", "highlights": ["The proposed method outperforms scalar reward mixing and single-reward baselines across all evaluated tasks, achieving superior or comparable performance to specialized teachers.", "The method effectively mitigates catastrophic forgetting and capability degradation observed in other multi-task approaches, maintaining stable performance on all metrics.", "By using dense multi-expert supervision, the approach enables robust learning that surpasses individual teacher models in certain edge cases, demonstrating emergent superiority."]
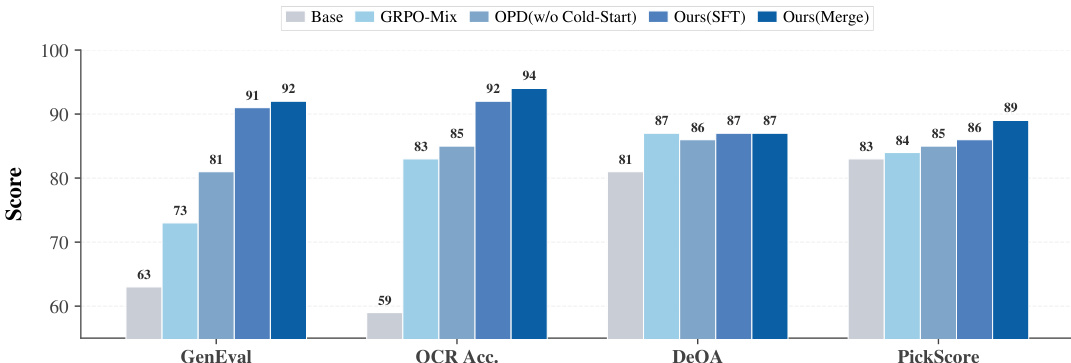
The authors conduct experiments to evaluate the effectiveness of different training approaches for multi-reward optimization in a foundation model. Results show that scalar reward mixing leads to capability degradation across tasks, while their proposed method achieves superior performance by leveraging dense multi-expert supervision. The proposed method matches or exceeds the performance of individual specialized teachers across all benchmarks without suffering from cross-domain interference. Scalar reward mixing causes significant capability degradation and fails to maintain performance across multiple tasks. The proposed method achieves consistent and superior performance across all benchmarks by using dense multi-expert supervision. The method matches or surpasses the performance of specialized teacher models without suffering from cross-domain interference.
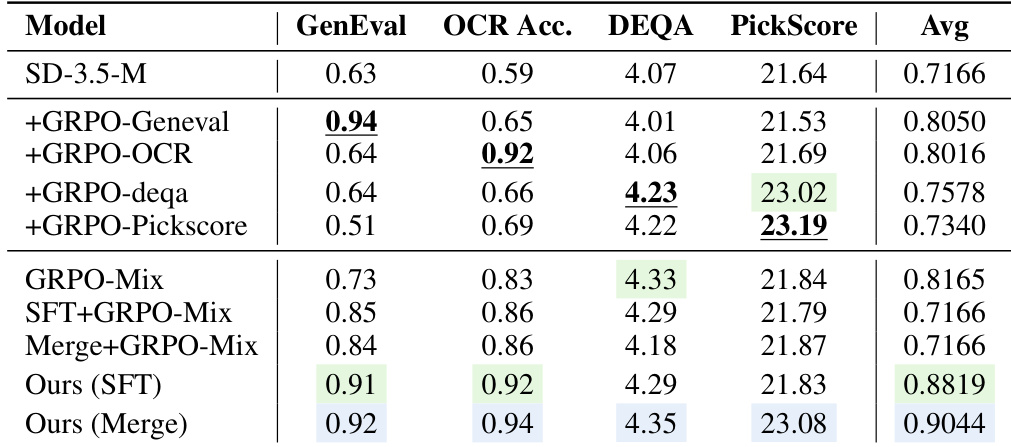
The authors compare their proposed method against baseline models in a multi-reward optimization setting, focusing on performance across various evaluation metrics. Results show that their approach achieves higher scores in aesthetic and overall quality measures while maintaining competitive performance in other dimensions. The method demonstrates improvements in key areas such as image quality and alignment, outperforming existing baselines in several benchmarks. The proposed method achieves higher aesthetic and overall quality scores compared to baseline models. It consistently outperforms other approaches in key metrics such as image quality and alignment. The method shows superior performance in balancing multiple reward objectives without significant degradation in individual capabilities.
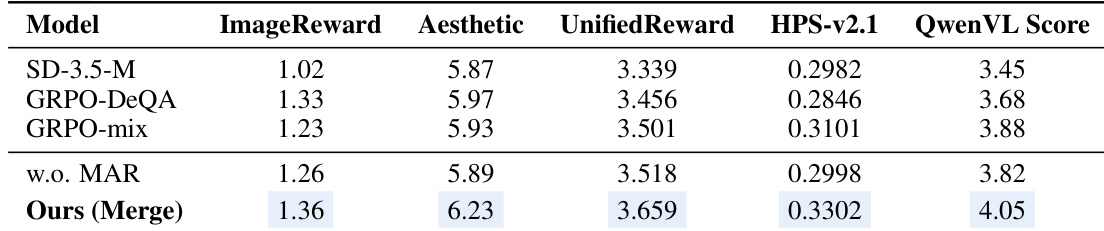
The authors investigate the limitations of scalar reward mixing in multi-reward optimization, showing that adding subsequent rewards leads to significant degradation in previously learned capabilities. Their proposed method, Flow-OPD, successfully avoids this degradation by using dense multi-expert supervision, achieving performance comparable to or exceeding that of individual specialized teachers across multiple tasks. Adding subsequent rewards to a model trained on a single reward leads to significant performance degradation in previously learned capabilities. Scalar reward mixing fails to maintain performance across multiple tasks due to gradient interference and catastrophic forgetting. The proposed method achieves performance comparable to or exceeding individual specialized teachers by leveraging dense multi-expert supervision.
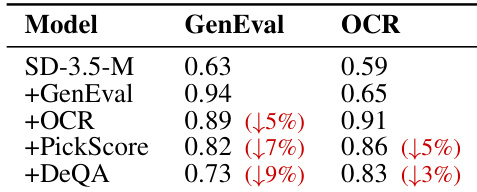
The authors compare their proposed method against baseline models in a multi-reward optimization setup, focusing on performance across various visual generation tasks. Results show that their approach achieves consistent improvements over baselines, particularly in complex and spatial reasoning tasks, while maintaining strong performance across diverse capabilities. The proposed method outperforms baselines in multiple visual generation tasks, including complex and 3D-spatial reasoning. Cold-start initialization combined with the proposed method yields better results than standard training approaches. The method achieves significant gains in texture and shape generation, demonstrating robust multi-task capability.

The authors evaluate a multi-reward optimization framework against standard baselines like scalar reward mixing and single-reward training across diverse visual generation and reasoning benchmarks. These experiments validate that conventional mixing strategies cause severe capability degradation and gradient interference, whereas the proposed method leverages dense multi-expert supervision to maintain stable performance across all tasks. Qualitatively, the approach successfully mitigates catastrophic forgetting and cross-domain interference, consistently matching or exceeding specialized teacher models in aesthetic quality, alignment, and complex spatial reasoning without sacrificing individual capabilities.