Command Palette
Search for a command to run...
PhysForge: توليد أصول ثلاثية الأبعاد مستندة إلى الفيزياء للعالم الافتراضي التفاعلي
PhysForge: توليد أصول ثلاثية الأبعاد مستندة إلى الفيزياء للعالم الافتراضي التفاعلي
Yunhan Yang Chunshi Wang Junliang Ye Yang Li Zanxin Chen Zehuan Huang Yao Mu Zhuo Chen Chunchao Guo Xihui Liu
الملخص
يُعد توليد أصول ثلاثية الأبعاد مستندة إلى الفيزياء عائقاً حاسماً أمام تطوير العوالم الافتراضية التفاعلية ووكلاء الذكاء الجسدي (Embodied AI). تركز الأساليب الحالية في الغالب على الهندسة الساكنة، متغاضيةً عن الخصائص الوظيفية اللازمة للتفاعل. نطرح هنا فكرة يجب أن ينطلق توليد الأصول التفاعلية من المنطق الوظيفي والفيزياء الهرمية. لسد هذه الفجوة، نقدم إطار عمل "فيوزج فيزيك" (PhysForge)، وهو إطار عمل من مرحلتين مفككتين مدعوماً بـ "فيزيبي دي" (PhysDB)، وهو مجموعة بيانات واسعة النطاق تضم 150,000 أصل معAnnotations فيزيائية على أربع مستويات. أولاً، يعمل نموذج لغوي مرئي (VLM) كمهندس فيزيائي لوضع "مخطط فيزيائي هرمي" يحدد قيود المواد والوظائف والحركيات. ثانياً، يحقق نموذج انتشار مستند إلى الفيزياء هذا المخطط من خلال توليد هندسة عالية الدقة جنباً إلى جنب مع معاملات حركية دقيقة، وذلك بفضل آلية حقن حركي فيزيائي (KineVoxel Injection) المبتكرة. تُظهر التجارب أن "فيوزج فيزيك" ينتج أصولاً معقولة وظيفياً وجاهزة للمحاكاة، مما يوفر محركاً بياناتً قوياً لمحتوى ثلاثي الأبعاد تفاعلي ووكلاء ذكاء جسدي.
One-sentence Summary
PhysForge is a decoupled two-stage framework that utilizes a vision-language model to construct hierarchical physical blueprints and a physics-grounded diffusion model with a novel KineVoxel Injection mechanism to synthesize high-fidelity geometry and precise kinematic parameters, yielding functionally plausible, simulation-ready 3D assets for interactive virtual worlds and embodied AI.
Key Contributions
- This work introduces PhysForge, a decoupled two-stage framework for interactive 3D asset generation, supported by PhysDB, a dataset comprising 150,000 assets with four-tier physical annotations.
- A vision-language model operates as a physical architect to generate a Hierarchical Physical Blueprint that explicitly specifies material, functional, and kinematic constraints prior to geometric synthesis.
- A physics-grounded diffusion model leverages a novel KineVoxel Injection mechanism to realize these blueprints, producing high-fidelity geometry and precise kinematic parameters that yield functionally plausible and simulation-ready assets.
Introduction
The authors address a critical bottleneck in embodied AI and interactive virtual worlds, where the demand for 3D assets capable of realistic manipulation outpaces the capabilities of current generative models. Existing methods predominantly synthesize static geometry and textures, producing assets that function as non-interactive shells unable to be grasped, pushed, or simulated within physics engines. This gap stems from a reliance on holistic shape generation or part-aware techniques that define components based on visual boundaries rather than functional logic, leaving kinematic properties and physical consistency unaddressed. Furthermore, prior physics-grounded approaches often depend on external templates or predefined repositories, limiting their ability to generalize to novel object categories while a lack of fine-grained physical data hinders model training.
To overcome these challenges, the authors propose PhysForge, a decoupled two-stage framework that shifts focus from appearance-centric synthesis to physics-driven generation. They leverage a fine-tuned vision-language model as a physical architect to plan a hierarchical blueprint, which explicitly defines material properties, functional roles, and kinematic constraints for each part. This structured plan guides a diffusion-based generator that realizes the asset through a novel KineVoxel Injection mechanism, encoding precise articulation parameters such as joint axes and limits directly into the voxel representation alongside geometry. The framework is supported by PhysDB, a large-scale dataset of 150,000 assets annotated with four tiers of physical properties, enabling the creation of functionally plausible, simulation-ready 3D content for robotics and interactive environments.
Dataset
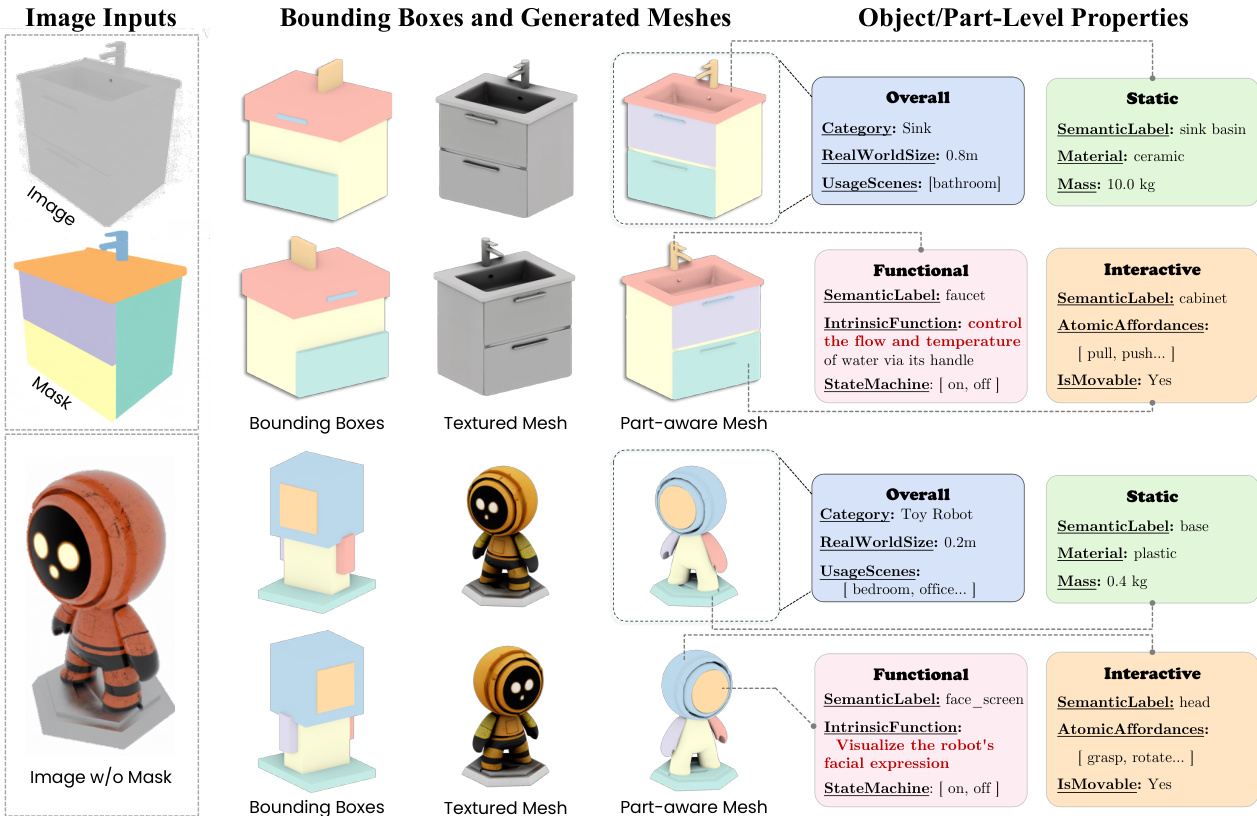
- Dataset Composition and Sources: The authors introduce PhysDB, a collection of 150,000 3D objects sourced from Objaverse. The dataset spans seven major categories, including household, industrial, weapons, personal, vehicles, tech and electronics, and cultural items.
- Key Details and Filtering Rules: The authors only retain objects that already possess a meaningful part structure and are compatible with their physics annotation pipeline. The dataset uses a multi-tier metadata framework that captures object-level attributes (real-world scale, category, and usage scene), part-level static and semantic properties (semantic label, material, mass), functional characteristics (intrinsic function and state machine), and interactive kinematic definitions (affordances, parent parts, joint types, and joint parameters).
- Processing and Metadata Construction: The annotation workflow follows a human-in-the-loop pipeline. The team first renders full objects and per-part images, which are processed by a multimodal large language model to generate initial annotations. These outputs then undergo manual screening and correction to ensure accuracy and consistency. Because scaling precise numerical axis annotation to 150,000 objects is impractical, the authors prioritize identifying joint types and rich physical properties over exact kinematic values.
- Training Usage and Data Mixture: PhysDB serves as the core foundation for the model. To compensate for the simplified kinematic annotations, the authors supplement the training process with PartNet-Mobility and Infinite-Mobility. These external datasets provide ground-truth articulation parameters that are specifically integrated during the diffusion training stage to bridge the kinematic gap.
Method
The authors present PhysForge, a two-stage framework for generating physics-grounded, part-aware 3D assets. The overall architecture is composed of a VLM-based planning stage followed by a diffusion-based realization stage, as shown in the framework diagram. In the first stage, a vision-language model (VLM) acts as a physical blueprint planner, generating a hierarchical description of an object's structure and physical properties. This planner leverages a multimodal input consisting of a 2D image, its corresponding 3D voxel representation, and an optional 2D part mask. The image and mask are processed by the VLM's image encoder, while the 3D voxel data is encoded using a Part-Field encoder followed by a position-aware 3D convolutional network to produce a 512-dimensional voxel embedding. The model is fine-tuned to autoregressively generate a hierarchical physical blueprint, which includes per-part bounding boxes, parent-child relationships, and joint types. To efficiently represent the 3D structure, the model utilizes a set of discrete tokens for quantized coordinates, enabling compact and effective structural planning.
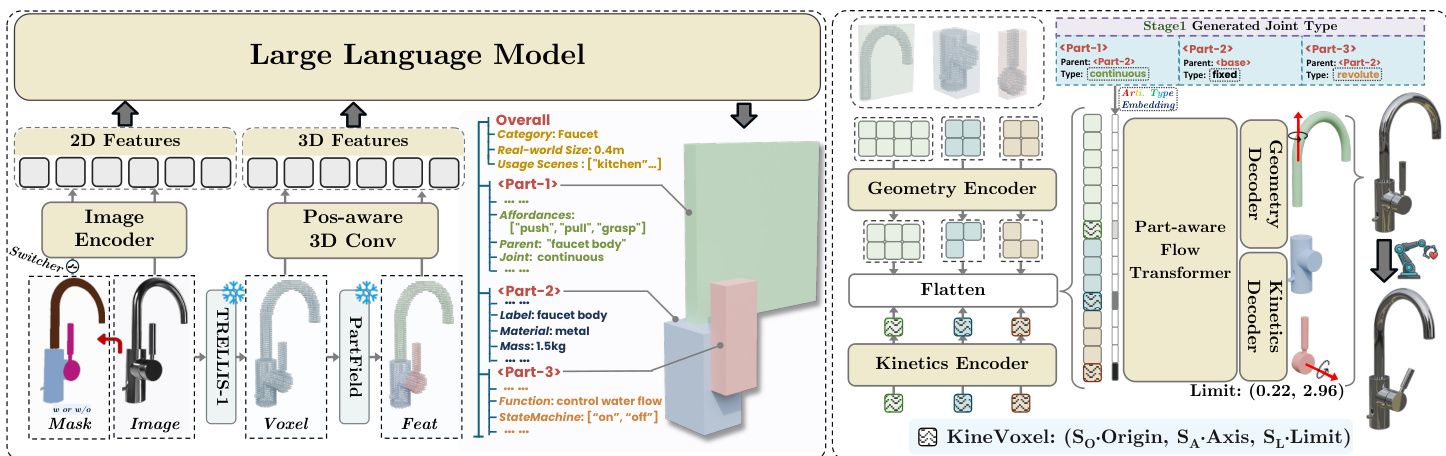
In the second stage, the diffusion-based generation process synthesizes the final 3D asset from the blueprint. The diffusion model is responsible for generating the high-fidelity geometry, texture, and precise kinematic parameters, a task it performs more effectively than the VLM for continuous values. The key innovation enabling this is the KineVoxel Injection mechanism. This mechanism represents the articulation parameters for a single part as an 8-dimensional vector, which is then transformed into a "KineVoxel" using a kinematic encoder. This KineVoxel, along with the standard geometry latents, is injected into the diffusion network's middle transformer. To ensure the model can differentiate between the two types of latents, a joint type embedding derived from the VLM's planned joint type is added to the KineVoxel. The diffusion network, composed of down-sample blocks, a middle transformer, and up-sample blocks, denoises both the geometry and kinematic latents in a unified framework. The entire model is trained using a composite Conditional Flow Matching objective that separately minimizes the L2 loss for geometry and kinematic latents, with a higher weight given to the kinematic loss to prioritize accurate articulation.
Experiment
The evaluation employs a multi-stage protocol across standard and custom datasets to systematically validate part structure planning, physics property generation, and kinematic parameter prediction. Results indicate that physics-guided planning substantially improves semantic understanding and structural accuracy, enabling robust part segmentation even without explicit mask inputs. By leveraging vision-language priors, the model accurately synthesizes consistent geometry and precise articulation parameters, significantly outperforming baseline methods in physical attribute prediction and joint alignment. These high-fidelity assets demonstrate strong downstream utility, seamlessly supporting complex robotic manipulation, physics-based virtual environments, and natural language-driven agent interactions.
The authors evaluate their model's performance in generating physics-grounded 3D assets, focusing on part structure planning and physical property generation. Results show that their method outperforms baselines in both geometric accuracy and the prediction of physical attributes, with improvements particularly evident in the integration of physics-guided planning and kinematic parameter estimation. The model achieves superior performance in generating accurate physical properties and geometry compared to baseline methods. Physics-guided planning significantly enhances part structure accuracy, enabling semantically reasonable results even without mask input. The integration of joint type embedding and kinematic sub-network improves the precision of articulated object generation.

The authors evaluate their model's performance in generating articulated objects, comparing it against several baselines on metrics related to mesh quality and kinematic parameter accuracy. Results show that their method achieves superior performance in both geometric fidelity and joint parameter prediction, with ablation studies indicating the importance of joint type embeddings and dedicated kinematic sub-networks for accurate results. the method outperforms baselines in both mesh generation quality and joint parameter accuracy. The model achieves better results than baselines even when evaluated on a broader range of categories. Ablation studies show that joint type embeddings and dedicated kinematic sub-networks are crucial for accurate joint parameter prediction.

The authors evaluate their model's performance in generating physics-grounded 3D assets, focusing on part structure planning and physical property generation. Results show that their method outperforms baselines in both geometric accuracy and the prediction of physical attributes, with significant improvements observed even without mask input. The model's ability to generate semantically meaningful and kinematically accurate articulated objects is demonstrated across multiple evaluation metrics. The proposed method achieves superior performance in generating accurate physical properties and geometric structures compared to baseline models. The model demonstrates strong capability in part structure planning without requiring a 2D mask input, indicating robustness and semantic understanding. Results show significant improvements in kinematic parameter prediction, highlighting the effectiveness of the physics-guided generation framework.

The authors evaluate their model's performance in part structure planning and physics-grounded generation, comparing it against baseline methods on multiple datasets. Results show that their approach achieves superior performance in both bounding box and voxel-level accuracy, with significant improvements when physics-guided planning is integrated. The model demonstrates robustness even without mask input and outperforms baselines in generating accurate physical properties and kinematic parameters. The proposed method achieves state-of-the-art results in part structure planning, outperforming baselines in both bounding box and voxel-level metrics. Physics-guided planning significantly enhances semantic understanding and enables accurate results even without mask input. The model demonstrates superior performance in generating accurate physical properties and kinematic parameters compared to existing methods.
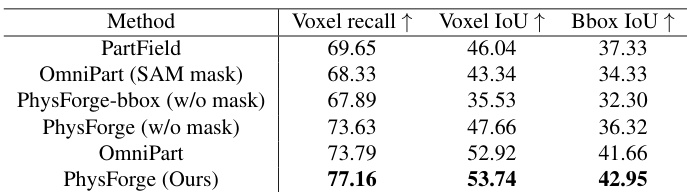
The authors evaluate their approach across multiple datasets against baseline methods, validating its capability to generate physically grounded 3D assets through part structure planning, geometric fidelity, and kinematic parameter prediction. The results demonstrate that integrating physics-guided planning with dedicated kinematic sub-networks substantially enhances semantic coherence and structural accuracy, allowing the model to produce reliable outputs even without 2D mask inputs. Overall, the method consistently outperforms existing baselines by delivering more realistic geometries and accurate physical properties, highlighting its robust generalization across diverse articulated object categories.